Giải quyết bài toán Vision-Language với BLIP-2 và InstructBLIP
Bài đăng này đã không được cập nhật trong 2 năm
Giới thiệu
Với sự phát triển của AI (Artificial Intelligence) hiện nay, các mô hình Computer Vision (CV) hay Natural Language Processing (NLP) đang ngày càng dễ học, dễ làm và dễ ứng dụng hơn bao giờ hết. Không dừng ở đó, ta còn có thể kết hợp những mô hình kể trên để giải quyết bài toán multimodal như Vision-Language. Tuy nhiên, việc huấn luyện end-to-end sẽ vô cùng tốn kém do phải huấn luyện cùng lúc nhiều loại mô hình khác nhau, hệ quả là hiệu suất ứng dụng sẽ không đạt kỳ vọng.
Vậy, liệu có cách nào để chúng ta có thể tận dụng những mô hình có sẵn mà không cần huấn luyện lại hay không? Làm sao để tận dụng sức mạnh xử lý hình ảnh của Vision Transformer hay khả năng tạo sinh văn bản của Large Language Models mà không cần “học” lại? Để trả lời cho câu hỏi đó, chúng ta sẽ cùng tìm hiểu về BLIP-2 và cách mô hình này đã dùng ViT và LLM để giải quyết bài toán Vision-Language như nào nhé!

BLIP-2: Tận dụng sức mạnh của những ông lớn
Sơ lược về mô hình họ BLIP
Thông thường, các phương pháp VLP sẽ tận dụng bộ dữ liệu cào được trên mạng theo dạng ảnh kèm alt-text làm cặp dữ liệu hình ảnh - văn bản để huấn luyện mô hình. Tuy nhiên, dữ liệu như vậy sẽ chứa rất nhiều nhiễu, khiến cho mô hình đầu ra không đạt hiệu quả mong muốn. Để giải quyết điều này, nhóm nghiên cứu [1] đã đề xuất một framework VLP mới mang mang tên Bootstrapping Language-Image Pre-training (BLIP).
Về mặt kiến trúc, mô hình BLIP kết hợp 3 khối Image Encoder, Text Encoder và Text Decoder để thực hiện những tác vụ xử lý đồng thời hình ảnh và ngôn ngữ (Fig1). Hiểu đơn giản thì các khối sẽ chia sẻ “kiến thức” với nhau, cho phép mô hình có thể hiểu được dữ liệu (do Image Encoder và Text Encoder đảm nhiệm) và trả lại đầu ra tương ứng (do Text Decoder đảm nhiệm).
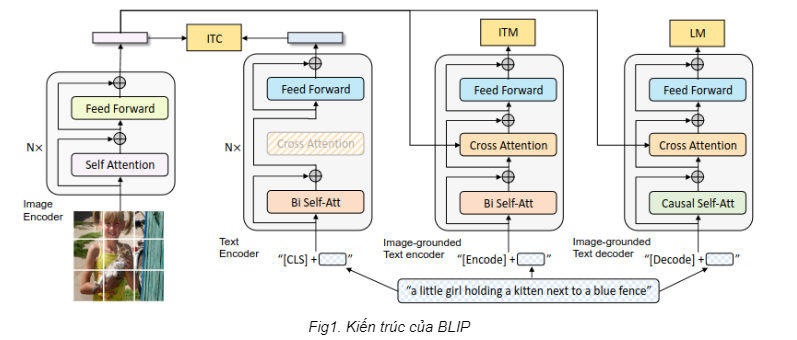
Về mặt dữ liệu, BLIP sẽ sử dụng chính các khối kể trên để làm 2 mô hình Captioner và Filter nhằm xử lý nhiễu trong bộ dữ liệu cào được trên mạng. Một mô hình thì chuyên miêu tả trong ảnh có gì (Captioner) và một mô hình thì chuyên kiểm tra xem ảnh và caption có liên quan không (Filter). Lấy ví dụ như trong Fig2, alt-text thu thập được từ web không hề liên quan đến ảnh (bầu trời với bánh kem). Lúc này, Filter sẽ từ chối alt-text trên và nhiệm vụ của Captioner sẽ tạo ra một alt-text khác phù hợp hơn.
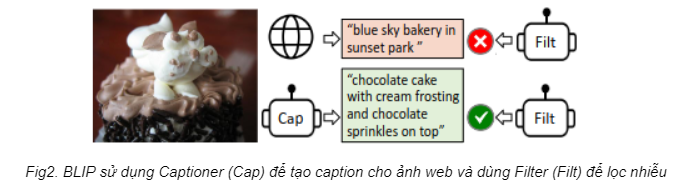
Tóm lại, BLIP đặc biệt ở chỗ có khả năng tận dụng bộ dữ liệu khổng lồ và kết hợp các kiến trúc chuyên môn trong việc “hiểu” hình ảnh-văn bản và tạo sinh. Kết quả là mô hình đầu ra sẽ có khả năng xử lý những tác vụ Vision-Language.
BLIP-2 có gì khác biệt?
Đột phá là vậy nhưng để đem lại hiệu suất mong muốn, mô hình huấn luyện theo phương pháp BLIP sẽ cần học end-to-end, tức mọi khối đều sẽ trải qua quá trình huấn luyện. Việc huấn luyện end-to-end như vậy thực sự rất “đau ví”, đặc biệt khi ta muốn scale mô hình lớn hơn. Ở thời điểm bấy giờ, những mô hình chuyên xử lí hình ảnh (các mô hình ViT) và chuyên xử lí văn bản (các mô hình LLM) đã trở nên vô cùng mạnh mẽ. Lúc này, nhóm nghiên cứu tại Salesforce nảy ra ý tưởng dùng luôn 2 ông kể trên, còn mục tiêu của mình chỉ là làm sao để chúng hiểu nhau thôi. Và thế là BLIP-2 ra đời. Khác với BLIP, BLIP-2 sử dụng Frozen Image Encoders và Frozen LLMs, tức là 2 ông này sẽ “nằm im", không “học" gì cả trong toàn bộ quá trình huấn luyện. Thay vào đó, nhóm nghiên cứu sẽ sử dụng kiến trúc mới “Query Transformer" như là cầu nối giữa Image Encoder và LLM.
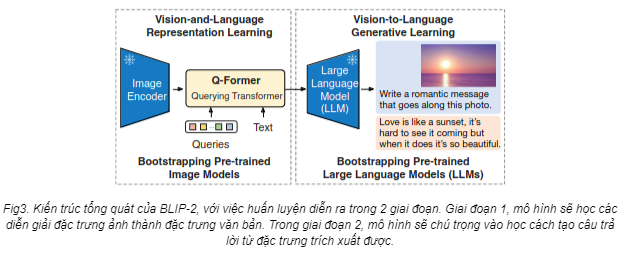
Cấu trúc của Query Transformer
Query Transformer (gọi tắt là Q-Former) có cấu tạo bao gồm 2 khối Image Transformer (để tương tác với Frozen Image Encoder) và Text Transformer (tương đương với 2 khối Text Encoder và Text Decoder). Text Transformer sẽ tiếp nhận văn bản làm đầu vào còn Image Transformer sẽ tiếp nhận bộ queries. Hiểu nôm na thì bộ queries này sẽ tương tự như loạt câu hỏi “Ai? Cái gì? Chuyện gì?” vậy. Qua quá trình huấn luyện thì dần dần bộ queries sẽ “biết” nhặt những đặc trưng cần thiết và liên quan đến văn bản. Một điểm đặc biệt khác là Image Transformer và Text Transformer sẽ dùng chung lớp self-attention, và nhóm nghiên cứu sẽ sử dụng attention masks để kiểm soát tương tác giữa queries và văn bản thông qua lớp self-attention kể trên. Q-Former được huấn luyện trong 2 giai đoạn: Representation Learning và Generative Learning.
Giai đoạn 1: Representation Learning
Ở giai đoạn 1, Q-Former sẽ học liên kết giữa đặc trưng hình ảnh và ngôn ngữ, sao cho phần “Query" hiểu được đặc trưng nào của ảnh sẽ tương đương với đặc trưng của văn bản. Lấy ví dụ như thế này: cho một cặp ảnh chú mèo và văn bản “mèo đang đeo kính râm" (Fig4), Image Encoder sẽ trả về một lượng đặc trưng đa dạng và có kích thước lớn. Nhiệm vụ của Queries lúc này là chỉ nhặt ra đặc trưng tương ứng với đặc trưng của văn bản (đặc trưng nào tương ứng “mèo” và đặc trưng nào tương ứng với “kính râm”).
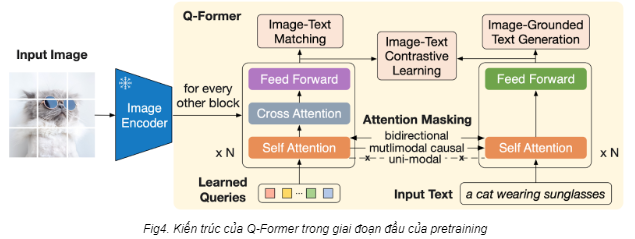
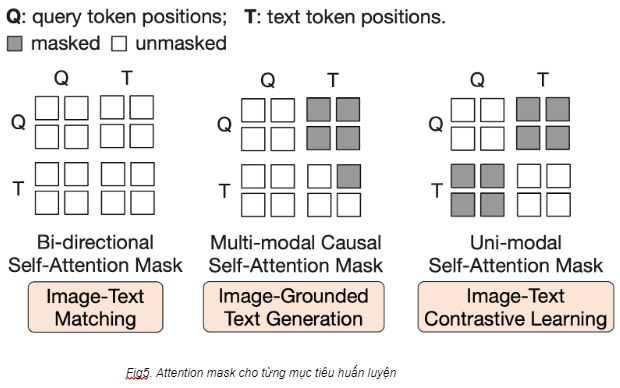
Trong giai đoạn 1, BLIP-2 có 3 mục tiêu huấn luyện, mỗi mục tiêu sẽ áp dụng một attention masking khác nhau cho lớp self-attention. Cụ thể là:
-
Image-Text Contrastive Learning (ITC): Mục tiêu của ITC là để mô hình học được sự liên kết giữa ảnh và văn bản, sao cho với cặp ảnh và văn bản tương đồng thì phải cho ra Embedding tương đồng, và cặp khác nhau thì phải cho ra Embedding khác nhau. Trong trường hợp này, ta sẽ tính chỉ số tương đồng dựa trên đầu ra của khối Image Transformer (query embedding) và của khối Text Transformer (text embedding). Cặp nào càng giống thì chỉ số càng cao và ngược lại. Ví dụ: ảnh một chú mèo đeo kính với văn bản “mèo đeo kính râm” sẽ phải cho ra 2 embedding có chỉ số tương đồng cao. Mặt khác, với văn bản “bãi biển mùa hè” thì chỉ số tương đồng giữa 2 embedding bắt buộc phải thấp. Để tránh rò rỉ thông tin, nhóm nghiên cứu sử dụng uni-modal self-attention mask, tức không cho phép tương tác giữa queries và văn bản.
-
Image-Grounded Text Generation (ITG): Mục tiêu của ITG là tạo văn bản (caption) dựa trên ảnh cho trước. Để làm được vậy thì Text Transformer sẽ cần thông tin từ bức ảnh, nhưng Q-Former lại không cho phép khối này dùng trực tiếp thông tin của ảnh mà phải thông qua queries. Hệ quả là queries sẽ bắt buộc chỉ nhặt thông tin hữu ích nhất cho Text Transformer mà thôi. Ở đây nhóm nghiên cứu áp dụng multimodal causal self-attention mask, tức chỉ cho phép text được tương tác một chiều với queries (để lấy thông tin).
-
Image-Text Matching (ITM): Mục tiêu của ITM là làm sao để mô hình học được sự liên kết giữa ảnh và caption tương ứng (tương tự với ITC nhưng học chi tiết hơn). Nói cách khác, đây là bài toán phân loại nhị phân mà mô hình sẽ phải đoán xem ảnh và văn bản có liên quan đến nhau không. Để làm được điều đó thì khối Image Encoder sẽ cần thông tin từ cả bức ảnh và văn bản. Ở đây, nhóm nghiên cứu sử dụng Bi-directional self-attention mask, tức cho phép queries và text tương tác với nhau hoàn toàn. Hệ quả là đầu ra Query Embedding sẽ chứa thông tin của cả bức ảnh và văn bản, từ đó sẽ chạy qua một lớp phân loại nhị phân để phân loại.
![]()
Giai đoạn 2: Generative Learning
Sau giai đoạn 1, ta sẽ thu được một Q-Former có khả năng “mô tả bức ảnh". Hiểu nôm na là bây giờ ông Q-Former đã “hiểu” và sẵn sàng “dịch" cho ông LLM những gì ông Image Encoder “nói”. Tất nhiên là đầu ra của Q-Former không dùng trực tiếp cho LLM được (vì khác biệt trong chiều của data). Thay vào đó, query embedding sẽ phải chạy qua một khối Fully Connected (FC) để biến đổi tuyến tính, sao cho phù hợp làm đầu vào của LLM. Nói cách khác thì query embedding sau khi chạy qua lớp FC sẽ hoạt động tương tự như mô tả của bức ảnh (soft visual prompt) để đưa vào LLM. Ở giai đoạn 2 này, việc “học" sẽ diễn ra chủ yếu với khối FC, mục tiêu là để LLM tạo ra câu trả lời mong muốn dựa trên query embeddings thu được từ Q-Former (vì LLM đã frozen nên chỉ có thể huấn luyện lớp FC). Ở trong Fig6, nhóm tác giả có thử nghiệm với 2 loại LLM: decoder-based và encoder-decoder-based. Đối với decoder-based, đầu ra của khối FC sẽ làm đầu vào của LLM. Đối với encoder-decoder-based, nhóm nghiên cứu “cắt" phần đầu của output mong muốn (prefix) và kết hợp với query embeddings để làm đầu vào của LLM (đầu ra tất nhiên là phần còn lại của output).
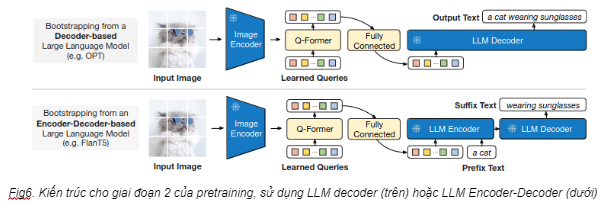
Tóm lại, việc pre-train của Q-Former diễn ra thành 2 giai đoạn và có thể hiểu như sau: Trong giai đoạn 1, Q-Former sẽ học cách trích xuất từ bộ đặc trưng của ảnh thành queries embedding sao cho thông tin thu thập được liên quan đến văn bản nhất. Sau đó, trong giai đoạn 2, queries embedding sẽ được “dịch" thành prompt (tương tự như việc mô tả bức ảnh). Trọng tâm của giai đoạn 2 là để khối FC học cách “dịch" queries embedding sao cho LLM tạo được đầu ra mong muốn. Chi tiết cách hoạt động các bạn có thể tham khảo thêm ở paper.
Kết quả
Khác với các phương pháp khác, BLIP-2 tập trung huấn luyện một mô hình trung gian thay vì huấn luyện toàn bộ. Bằng cách này, mô hình BLIP-2 vừa đạt được hiệu suất SOTA mà lại tiết kiệm, giúp cắt giảm phần lớn chi phí ứng dụng.
Tuy nhiên, BLIP-2 vẫn tồn tại một số điểm yếu liên quan đến kiến thức và lập luận. Những điểm yếu này có thể liên quan trực tiếp đến trích xuất ảnh của Q-Former hoặc do bộ data dùng để huấn luyện Q-Former.
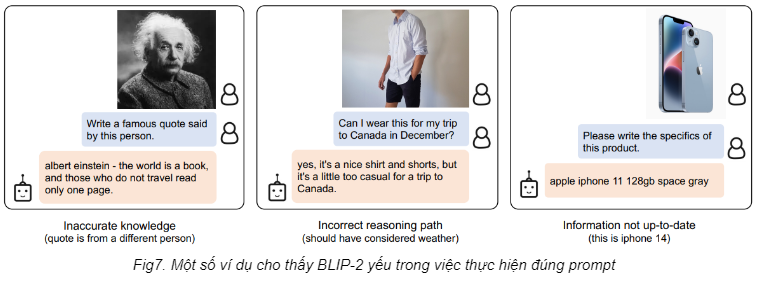
InstructBLIP: Cải tiến BLIP-2 bằng phương pháp Instruction Tuning
Sơ lược về InstructBLIP
Như đã đề cập ở trên, một đặc điểm mà BLIP-2 vẫn cải thiện được nằm ở khả năng trích xuất đặc trưng ảnh của Q-Former. Việc chỉ huấn luyện Q-Former với cặp ảnh và văn bản miêu tả khiến cho nhiều thông tin trích xuất không liên quan đến prompt (hay còn gọi là instruction) của người dùng, dẫn đến việc câu trả lời có thể không đúng trọng tâm. Bởi vậy, InstructBLIP đã ra đời với mục tiêu cải tiến BLIP-2 bằng phương pháp instruction tuning.
Kiến trúc InstructBLIP
Để giải quyết vấn đề thì InstructBLIP cho phép prompt cũng được đưa vào Q-Former để trích xuất thông tin ảnh. Điều này giúp cho thông tin LLM nhận được “chất lượng” hơn, qua đó khiến cho câu trả lời nhắm đúng vào nhu cầu của người dùng.
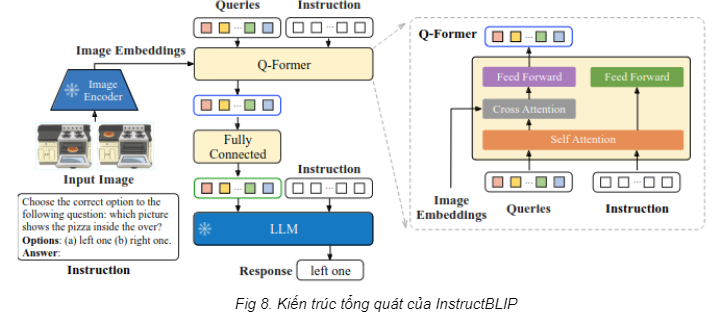 Ý tưởng InstructBLIP chỉ có vậy, tuy rất đơn giản nhưng việc fine tune dựa trên instruction đã cải thiện đáng kể hiệu suất của BLIP-2. Hãy cùng ngó qua một số kết quả thu được nhé.
Ý tưởng InstructBLIP chỉ có vậy, tuy rất đơn giản nhưng việc fine tune dựa trên instruction đã cải thiện đáng kể hiệu suất của BLIP-2. Hãy cùng ngó qua một số kết quả thu được nhé.
Kết quả đánh giá
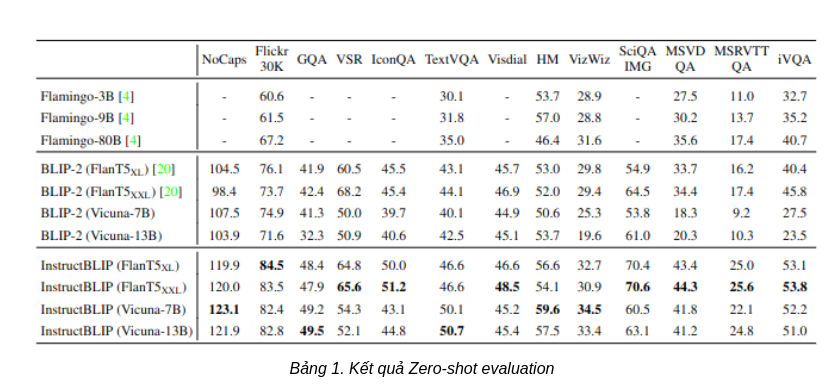
Zero-shot evaluation
Đối với zero-shot evaluation, nhóm tác giả thực hiện so sánh với những mô hình thuộc họ BLIP-2 và Flamingo. Tập data sử dụng để đánh giá cũng là tập validation data đề cập ở trên. Trong bảng 1, ta có thể thấy InstructBLIP vượt qua BLIP-2 và Flamingo ở mọi tập data, minh chứng cho tính hiệu quả của instruction tuning. Cụ thể, InstructBLIP FlanT5XL cải thiện 15% so với BLIP-2 FLanT5XL. Thậm chí với một số tác vụ mà InstructBLIP không được huấn luyện (ví dụ như video QA, tập MSRVTT QA), InstructBLIP cũng cải thiện khoảng 47.1% so với các mô hình SOTA trước đó. Bên cạnh đó, mô hình InstructBLIP FlanT5 nhỏ nhất (4 tỉ tham số) cũng vượt qua mô hình Flamingo-80B (80 tỉ tham số) với mức độ cải thiện trung bình 24.8%.
Kết luận
BLIP, BLIP-2 và InstructBLIP đều là những phương pháp tận dụng sức mạnh từ những mô hình đơn nhiệm để phát triển khả năng đa nhiệm. So với BLIP, BLIP-2 tiết kiệm chi phí bằng cách huấn luyện một ông “biên dịch" Q-Former để tận dụng 2 mô hình Visual Transformer và Large Language Model. InstructBLIP lại cải tiến BLIP-2 thêm một bước xa hơn nữa bằng cách huấn luyện Q-Former trích xuất thông tin chất lượng và liên quan đến prompt, qua đó cải thiện khả năng trả lời đúng trọng tâm của mô hình. Nhờ vào việc tiết kiệm chi phí huấn luyện mà lại cải thiện hiệu suất mà những mô hình kể trên thường được tin dùng cho bài toán Vision-Language.
Demo
Bên dưới là một số demo của InstructBLIP (có so sánh với các mô hình khác như GPT-4, LLaVA, và MiniGPT-4).



References
- BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
- BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
- BLIP-2: Scalable Pre-training of Multimodal Foundation Models for the World's First Open-source Multimodal Chatbot
🔗 Tìm hiểu về Pixta Vietnam
Cập nhật tin tức mới nhất của Pixta Vietnam 👉 http://bit.ly/3kdkzvW
All rights reserved
