
[GAN series-3] Sinh nhân vật Anime với Deep learning - GAN
Bài đăng này đã không được cập nhật trong 5 năm

1. Dataset
Trong hai bài trước, mình đã nói qua về khái niệm GAN và thực hành GAN với bộ dataset đơn giản: Mnist. Trong bài này, mình sẽ tiến hành code một GAN phức tạp hơn, trên dataset phức tạp hơn: bộ chân dung các nhân vật Anime. Anime Dataset được public trên Kaggle theo link sau: Kaggle anime-faces . Bạn có thể download về máy hoặc code trực tiếp trên Kaggle (bằng cách click vào New notebook button)
2. Model
Trong bài GAN series P1, mình đã mô tả qua kiến trúc DC GAN. Trong bài này mình sẽ dùng kiến trúc DC GAN cho việc sinh ảnh nhân vật anime. DC GAN là viết tắt của Deep Convolution GAN, tức model được tạo thành từ nhiều lớp Conv, input là noise được random từ phân phối Gaussian. Kiến trúc Generator theo hướng tăng dần size ảnh, kiến trúc Discriminator theo hướng giảm dần như hình minh họa dưới đây.
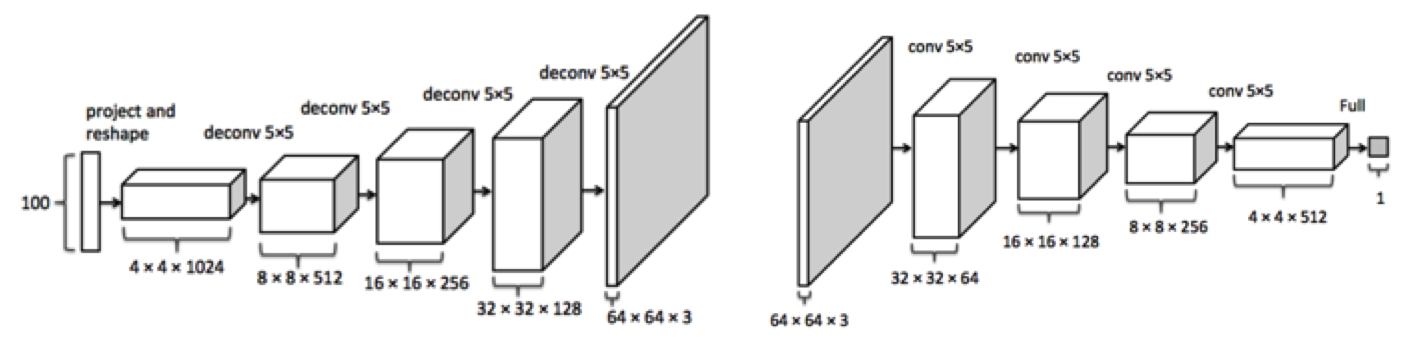
3. Tiến hành code
Code được mình lưu trên Kaggle theo link sau: https://www.kaggle.com/trungthanhnguyen0502/gan-anime
Import các thư viện cần thiết:
import numpy as np
import os
from PIL import Image
from matplotlib import pyplot as plt
import torch
import torchvision.transforms as T
from torch.utils.data import Dataset, DataLoader
from torchvision import datasets as torch_dataset
from torchvision.utils import make_grid
from torch import nn
from torch.nn import functional as F
3.1 Dataset
img_size = 64
data_dir = '../input/anime-faces/data'
data_transforms = T.Compose([
T.Resize(img_size),
T.CenterCrop(img_size),
T.ToTensor(),
T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
anime_dataset = torch_dataset.ImageFolder(root=data_dir, transform=data_transforms)
dataloader = DataLoader(dataset=anime_dataset, batch_size=128, shuffle=True, num_workers=4)
img_batch = next(iter(dataloader))[0]
combine_img = make_grid(img_batch[:32], normalize=True, padding=2).permute(1,2,0)
plt.figure(figsize=(15,15))
plt.imshow(combine_img)
plt.show()
Đây là 1 vài ảnh có trong dataset

3.2 Model and module
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
def Conv(n_input, n_output, k_size=4, stride=2, padding=0, bn=False):
return nn.Sequential(
nn.Conv2d(
n_input, n_output,
kernel_size=k_size,
stride=stride,
padding=padding, bias=False),
nn.BatchNorm2d(n_output),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(p=0.2, inplace=False))
def Deconv(n_input, n_output, k_size=4, stride=2, padding=1):
return nn.Sequential(
nn.ConvTranspose2d(
n_input, n_output,
kernel_size=k_size,
stride=stride, padding=padding,
bias=False),
nn.BatchNorm2d(n_output),
nn.ReLU(inplace=True))
class Generator(nn.Module):
def __init__(self, z=100, nc=64):
super(Generator, self).__init__()
self.net = nn.Sequential(
Deconv(z, nc*8, 4,1,0),
Deconv(nc*8, nc*4, 4,2,1),
Deconv(nc*4, nc*2, 4,2,1),
Deconv(nc*2, nc, 4,2,1),
nn.ConvTranspose2d(nc,3, 4,2,1,bias=False),
nn.Tanh()
)
def forward(self, input):
return self.net(input)
class Discriminator(nn.Module):
def __init__(self, nc=64):
super(Discriminator, self).__init__()
self.net = nn.Sequential(
nn.Conv2d(
3, nc,
kernel_size=4,
stride=2,
padding=1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
Conv(nc, nc*2, 4,2,1),
Conv(nc*2, nc*4, 4,2,1),
Conv(nc*4, nc*8, 4,2,1),
nn.Conv2d(nc*8, 1,4,1,0, bias=False),
nn.Sigmoid())
def forward(self, input):
return self.net(input)
device = torch.device('cuda')
dis_model = Discriminator()
gen_model = Generator()
gen_model.apply(weights_init)
dis_model.apply(weights_init)
dis_model.to(device)
gen_model.to(device)
print('init model')
3.3 Train model
Define some parameters
from torch import optim
real_label = 1.
fake_label = 0.
lr = 0.0002
beta1 = 0.5
criterion = nn.BCELoss()
optim_D = optim.Adam(dis_model.parameters(), lr=lr, betas=(beta1, 0.999))
optim_G = optim.Adam(gen_model.parameters(), lr=lr, betas=(beta1, 0.999))
Train model:
img_list = []
G_losses = []
D_losses = []
iters = 1
epoch_nb = 30
fixed_noise = torch.randn(32, 100, 1,1, device=device)
from torch.distributions.uniform import Uniform
for epoch in range(epoch_nb):
for i, data in enumerate(dataloader):
# Train Discriminator
## Train with real image
dis_model.zero_grad()
real_img = data[0].to(device)
bz = real_img.size(0)
# label smoothing
label = Uniform(0.9, 1.0).sample((bz,)).to(device)
output = dis_model(real_img).view(-1)
error_real = criterion(output, label)
error_real.backward()
D_x = output.mean().item()
## Train with fake image
noise = torch.randn(bz, 100, 1,1, device=device)
fake_img = gen_model(noise)
label = Uniform(0., 0.05).sample((bz,)).to(device)
output = dis_model(fake_img.detach()).view(-1)
error_fake = criterion(output, label)
error_fake.backward()
D_G_z1 = output.mean().item()
error_D = error_real + error_fake
optim_D.step()
## Train Generator
gen_model.zero_grad()
label = Uniform(0.95, 1.0).sample((bz,)).to(device)
output = dis_model(fake_img).view(-1)
error_G = criterion(output, label)
error_G.backward()
optim_G.step()
D_G_z2 = output.mean().item()
if i % 300 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, epoch_nb, i, len(dataloader),
error_D.item(), error_G.item(), D_x, D_G_z1, D_G_z2))
if epoch > 1:
if (iters % 1000 == 0) or ((epoch == epoch_nb-1) and (i == len(dataloader)-1)):
with torch.no_grad():
fake_img = gen_model(fixed_noise).detach().cpu()
fake_img = make_grid(fake_img, padding=2, normalize=True)
img_list.append(fake_img)
plt.figure(figsize=(10,10))
plt.imshow(img_list[-1].permute(1,2,0))
plt.show()
iters += 1
Và đây là kết quả chỉ sau 5 phút, khá ổn và giống thật đúng không 

All rights reserved
