
[GAN series-2] Tự sinh chữ viết tay với GAN
Bài đăng này đã không được cập nhật trong 5 năm
Trong bài viết trước, mình đã điểm qua các khái niệm và công thức trong GAN. Nội dung bài này sẽ tập trung vào thực hành, mình sẽ bắt tay vào code một ứng dụng demo nho nhỏ. Nếu chưa hiểu về GAN, hãy đọc lại bài đầu tiên của mình .
Dataset
Để không mất quá nhiều thời gian vào việc chuẩn bị dữ liệu và tập trung vào thuật toán, mình sẽ dùng bộ dữ liệu đơn giản nhất mà ai cũng biết: Mnist - bộ dữ liệu chữ viết tay được tích hợp sẵn trong keras.
Bắt tay vào code
Import các thư viện cần thiết:
from keras.models import Sequential
from keras.layers import *
from matplotlib import pyplot as plt
import numpy as np
import cv2
from numpy.random import randn, randint
import os
from keras.datasets.mnist import load_data as origin_load_data
from keras.optimizers import Adam
from keras.models import Sequential, Model
import tqdm
from sklearn.model_selection import train_test_split
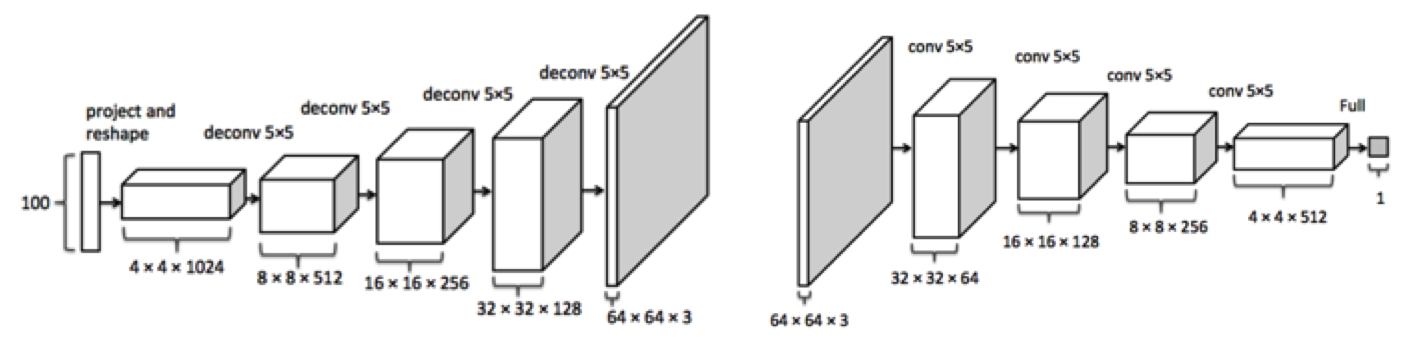
Định nghĩa generator và discriminator đơn giản: Đây là một DCGan điển hình, trong generator, mình dùng Transpose Convolution để upsample. Một trong những điểm cần chú ý r sau nhiều lần thực nghiệm, người ta rút ra kinh nghiệm rằng không nên Dropout trong Generator, chỉ dùng trong Discriminator.
GAN được định nghĩa có hình dạng tương tự hình minh họa, chỉ đơn giản hơn vì mình đang dùng trên bộ mnist đơn giản, không cần phải tạo mạng quá nhiều tham số
def adam_optimizer():
return Adam(lr=0.0001, beta_1=0.3)
def create_generator(latent_dim=100):
model = Sequential()
model.add(Dense(7*7*512, input_dim=latent_dim, activation='relu'))
new_shape = (7,7,512)
model.add(Reshape(new_shape))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.2))
model.add(Conv2DTranspose(filters=256, kernel_size=(3,3), padding='same', strides=2, bias=False))
model.add(LeakyReLU(alpha=0.2))
model.add(Conv2DTranspose(filters=128, kernel_size=(4,4), padding='same', strides=2, bias=False))
model.add(BatchNormalization())
model.add(LeakyReLU(alpha=0.2))
model.add(Conv2D(1, kernel_size=(5,5), strides=1, padding='same', activation='tanh', bias=False))
model.compile(loss='binary_crossentropy', optimizer=adam_optimizer())
return model
def create_discriminator(inp_shape=(28,28,1)):
model = Sequential()
# output: (14*14*512)
model.add(Conv2D(filters=512, kernel_size=(5,5), strides=2, padding='same', input_shape=inp_shape))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.3))
# output: (7*7*64)
model.add(Conv2D(filters=256, kernel_size=(3,3), strides=2, padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(Conv2D(filters=128, kernel_size=(3,3), strides=1, padding='same'))
model.add(LeakyReLU(alpha=0.2))
model.add(Flatten())
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer=adam_optimizer(), metrics=['accuracy'])
return model
def create_gan(discriminator, generator):
discriminator.trainable=False
gan_input = Input(shape=(100,))
x = generator(gan_input)
gan_output= discriminator(x)
gan= Model(inputs=gan_input, outputs=gan_output)
gan.compile(loss='binary_crossentropy', optimizer=adam_optimizer())
return gan
Định nghĩa các hàm phụ:
def load_data():
(x_train, y_train), (x_test, y_test) = origin_load_data()
x_train = (x_train.astype(np.float32) - 127.5)/127.5
x_train = np.expand_dims(x_train, axis=-1)
return (x_train, y_train, x_test, y_test)
# tạo input cho Generator
def gen_z_input(batch_size, latent_dim=100):
z = np.random.normal(0,1, [batch_size, 100])
return z
# tạo ra ảnh fake và label
def gen_fake_image(generator, batch_size):
z = gen_z_input(batch_size)
fake_image = generator.predict(z)
fake_label = gen_label(batch_size, is_real=False)
return fake_image, fake_label
def plot_image(images, n= 5):
for i in range(n * n):
plt.subplot(n, n, 1 + i)
plt.axis('off')
plt.imshow(images[i, :, :, 0], cmap='gray')
plt.show()
def gen_real_image(dataset, batch_size):
ix = randint(0, dataset.shape[0], batch_size)
real_image = dataset[ix]
real_label = gen_label(batch_size, is_real=True)
return real_image, real_label
# validate discriminator
def val_model(discriminator, generator, val_dataset):
batch_size = 32
real_acc = []
fake_acc = []
for i in range(len(val_dataset)//batch_size-1):
real_image = val_dataset[i:i+1]
z = gen_z_input(batch_size)
fake_image = generator.predict(z)
real_acc.append(discriminator.predict(real_image)[:].mean())
fake_acc.append(discriminator.predict(fake_image)[:].mean())
return np.array(real_acc).mean(), 1- np.array(fake_acc).mean()
def gen_label(size, is_real=True, noise_ratio=0.1):
if is_real:
label = np.ones(size,)*0.9
else:
label = np.ones(size,)*0.1
return np.squeeze(label)
# validate gan model -> đánh giá khả năng đánh lừa discriminator của generator
def val_gan_model(GAN_model, epochs=100):
gan_acc = []
batch_size = 32
for i in range(epochs):
z = np.random.rand(batch_size, 100)
acc = GAN_model.predict(z).mean()
gan_acc.append(acc)
return np.array(gan_acc).mean()
Tạo các model cần thiết:
generator = create_generator()
discriminator = create_discriminator()
GAN_model = create_gan(discriminator, generator)
Tiến hành tiến trình train model:
Note: Khi tạo GAN_model mình đã set discriminator.trainable=False, nhưng một số bản Keras discriminator.trainable vẫn là True (-> khiến weights của discriminator vẫn bị update) trong khi bản khác discriminator.trainable=False khi train GAN_model. Vì vậy mình sẽ set lại trainable trong mỗi step
epochs=5
batch_size = 8
gan_batch_size = 25
step_per_epoch = len(train_dataset)//batch_size
# vì step_per_epoch quá lớn nên mình quyết định cho nó nhỏ đi
# ---> nhanh được nhìn thấy kết quả hơn
step_per_epoch = step_per_epoch//10
for i in range(epochs):
for step in tqdm.tqdm(range(step_per_epoch)):
real_image, real_label = gen_real_image(train_dataset, batch_size)
z_input = gen_z_input(batch_size)
fake_image = generator.predict(z_input)
fake_label = gen_label(batch_size, is_real=False)
discriminator.trainable=True
discriminator.train_on_batch(real_image, real_label)
discriminator.train_on_batch(fake_image, fake_label)
discriminator.trainable=False
gan_fake_label = gen_label(batch_size, is_real=True)
GAN_model.train_on_batch(z_input, gan_fake_label)
# real_acc, fake_acc = val_model(discriminator, generator, val_dataset)
# dis_acc = (real_acc+ fake_acc)/2
# gan_acc = val_gan_model(GAN_model)
# print("train gan_model: epoch {} step {} ---> dis_acc {}, gan_acc {}".format(i, step, dis_acc, gan_acc))
val_input = gen_z_input(gan_batch_size)
val_image = generator.predict(val_input)
plot_image(val_image)
Để có thể control được quá trình train, xác định xem quá trình train có bị hỏng hay không thì phải quan sát dis_acc và gan_acc. Nếu dis_acc quá lớn, nghĩa là discriminator học quá nhanh -> generator không kịp học theo => quá trình train khả năng cao là thất bại. Điều này cũng tương tự như khi dis_acc quá nhỏ, gan_acc quá khác biệt so với dis_acc. Bạn cần phải điều chính learning_rate, các hệ số trong optimizer và kiến trúc model sao cho khi train, hai thông số dis_acc và gan_acc không quá lệch nhau thì quá trình train mới có khả năng thành công.
Dưới đây là kết quả thu được sau 8 epoch, khá nhanh chỉ mất 2p là ta đã thu được những hình trông khá giống chứ viết trong bộ mnist:


Trong bài tiếp theo, mình sẽ hướng dẫn code GAN trên bộ dữ liệu phức tạp hơn 1 chút: bộ dữ liệu khuôn mặt anime.
Note: Các bài viết được viết trên trang https://viblo.asia , nếu trích dẫn hãy ghi nguồn trang cùng tên tác giả đầy đủ.
facebook: trungthanhnguyen0502
All rights reserved
