Framework Kaldi sử dụng trong nhận dạng tiếng nói.
Bài đăng này đã không được cập nhật trong 7 năm
Một hệ thống nhận dạng tiếng nói tốt là hệ thống có khả năng nhận dạng được mọi câu nói của người sử dụng. Thực tế cho thấy ngay cả con người trong một số trường hợp cũng không thể hiểu được cùng một câu nói nếu nó được phát âm bởi một người ở địa phương khác. Làm sao để hệ thống sau khi đã huấn luyện có thể vẫn nhận dạng được các giọng nói mới với độ chính xác mong muốn.
Mục tiêu của bài viết này là hướng dẫn bạn cách sử dụng và cung cấp cho bạn các tài liệu giúp bạn có thể hiểu, làm việc với framework này.
Kaldi là gì?
Kaldi là một bộ công cụ mã nguồn mở được tạo ra để xử lý dữ liệu giọng nói. nó được sử dụng trong các ứng dụng liên quan đến giọng nói, chủ yếu để nhận dạng giọng nói mà còn cho các tác vụ khác - như nhận dạng loa và tăng âm loa. Bộ công cụ này đã khá cũ (khoảng 7 tuổi) nhưng vẫn liên tục được cập nhật và phát triển thêm bởi một cộng đồng khá lớn. Kaldi được áp dụng rộng rãi cả trong Học viện (hơn 400 trích dẫn trong năm 2015) và công nghiệp.
Kaldi được viết chủ yếu bằng C / C ++, nhưng bộ công cụ được gói bằng các tập lệnh Bash và Python. Đối với việc sử dụng cơ bản gói này không cần phải đi quá sâu vào mã nguồn.

Cấu trúc cơ bản của Kaldi một số thành phần chính của Kaldi.
Tiền xử lý và khai thác tính năng
Ngày nay, hầu hết các mô hình xử lý dữ liệu âm thanh đều hoạt động với một số biểu diễn dựa trên pixel của dữ liệu đó. Khi bạn muốn trích xuất đại diện như vậy, bạn sẽ hầu như muốn sử dụng các tính năng sẽ tốt cho hai điều:
- Xác định âm thanh của lời nói của con người
- Loại bỏ bất kỳ tiếng ồn không cần thiết.
Trong những năm qua đã có nhiều cố gắng để làm cho những tính năng và ngày nay phương pháp trích trọn đặc trưng sử dụng bộ lọc và thang tần số Mel (MFCC) được sử dụng rộng rãi trong ngành công nghiệp.
MFCC là viết tắt của Hệ số cepstral Mel-Tần số và nó gần như đã trở thành một tiêu chuẩn trong ngành kể từ khi nó được phát minh vào những năm 80 bởi Davis và Mermelstein . Bạn có thể có được một lời giải thích lý thuyết tốt hơn về MFCC trong bài viết tuyệt vời dễ đọc này . Đối với việc sử dụng cơ bản, tất cả những gì bạn cần biết là MFCC chỉ tính đến những âm thanh được nghe bằng tai tốt nhất.
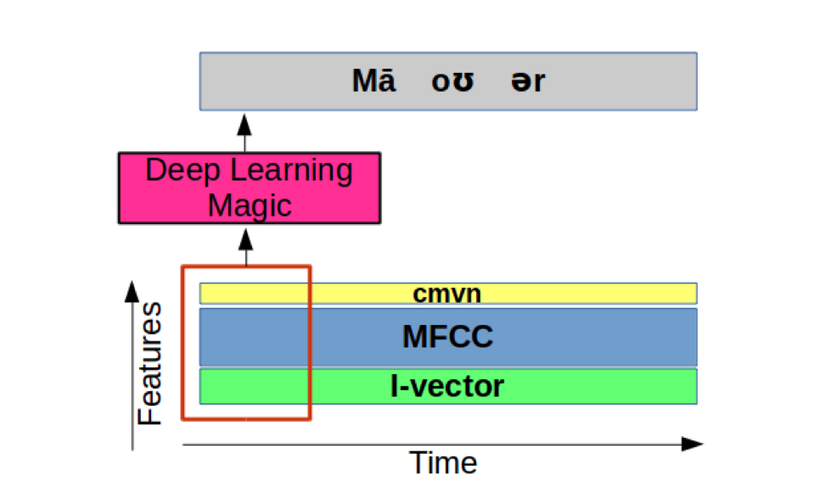
Trong Kaldi, chúng tôi sử dụng hai tính năng khác:
- CMVN được sử dụng để chuẩn hóa tốt hơn MFCC
- I-vector được sử dụng để hiểu rõ hơn về các phương sai trong miền. Ví dụ: tạo một đại diện phụ thuộc loa. I-vectơ dựa trên cùng một ý tưởng của JFA (Phân tích nhân tố chung), nhưng phù hợp hơn để hiểu cả phương sai của kênh và người nói.
Quá trình thực hiện sử dụng I-Vectors
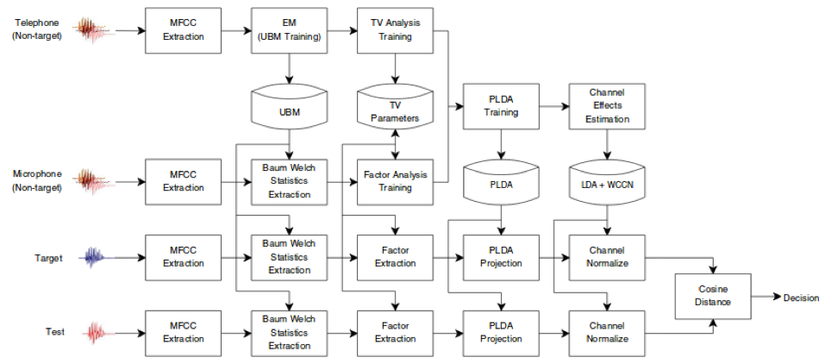
Để hiểu cơ bản về các khái niệm này, hãy nhớ những điều sau đây:
- MFCC và CMVN được sử dụng để thể hiện nội dung của từng âm vị cách phát âm.
- I-vector được sử dụng để thể hiện đặc trưng của từng phát ngôn hoặc âm thanh .
Model
Các ma trận toán học đằng sau Kaldi được thực hiện trong một trong hai BLAS (Basic Linear Algebra Subprograms) và LAPACK — Linear Algebra PACKage (viết bằng Fortran!). Hoặc với một sự lựa chọn thực hiện GPU dựa trên CUDA . Do sử dụng các gói cấp thấp như vậy, Kaldi có hiệu quả cao trong việc thực hiện các nhiệm vụ đó.
Mô hình của Kaldi có thể được chia thành hai thành phần chính: Phần đầu tiên là Mô hình âm thanh , từng là GMM nhưng giờ đây nó đã được thay thế một cách dữ dội bởi các mạng lưới Deep neural . Mô hình đó sẽ phiên âm các tính năng âm thanh mà chúng tôi đã tạo thành một số chuỗi âm vị phụ thuộc vào ngữ cảnh.
Mô hình Acoustic:
Phần thứ hai là Đồ thị giải mã , lấy các âm vị và biến chúng thành các mạng . Một mạng là một đại diện của các chuỗi từ thay thế có khả năng cho một phần âm thanh cụ thể. Đây thường là đầu ra mà bạn muốn nhận được trong một hệ thống nhận dạng giọng nói. Biểu đồ giải mã có tính đến ngữ pháp của dữ liệu của bạn, cũng như phân phối và xác suất của các từ cụ thể liền kề ( n-gram ).
Đây là một sự đơn giản hóa về cách thức mà mô hình hoạt động. Thực tế có rất nhiều chi tiết về việc kết nối hai mô hình với cây quyết định và về cách bạn thể hiện các âm vị, nhưng sự đơn giản hóa này có thể giúp bạn nắm được quy trình thực hiện giải mã của kaldi.
Conclusion
Bài viết này mình đã giới thiệu về Kaldi ứng dụng trong nhận dạng giọng nói và một số thành phần chính giúp kaldi có thể sử dụng để xử lý âm thanh để cho ra kết quả tương ứng.
Bạn có thể tìm hiểu nhiều hơn và tài liệu tại Josh Meyer’s website và Github-Kaldi-awesome-list.
All rights reserved
