
EDA dữ liệu cuộc thi Bookingchallenge và Baseline model
Bài đăng này đã không được cập nhật trong 5 năm
Xin chào mọi người, cách đây khoảng 2 tháng mình có tham gia một cuộc thi về recommendation system do Booking.com tổ chức, hôm nay mình sẽ chia sẻ bài viết về cách mình đã phân tích dữ liệu như thế nào, bên cạnh đó cũng đưa ra mô hình baseline của mình.
Booking challenge
Cuộc thi này được booking.com tổ chức dựa trên dữ liệu về lịch sử book phòng của khách hàng khi đi du lịch đến một thành phố khác, mục đích của cuộc thi là đưa ra được thành phố tiếp theo mà khách hàng sẽ đến để booking có thể dễ dàng đoán đúng và gợi ý địa điểm tiếp theo. Để biết thêm về cuộc thi các bạn có thể theo dõi tại link này
Data
Dữ liệu được cung cấp bởi booking.com và dữ liệu này theo mình thấy thì rất là clean rồi  . Dữ liệu gồm các trường dưới đây:
user_id - User ID
. Dữ liệu gồm các trường dưới đây:
user_id - User ID
check-in - Thời gian check-in
checkout -Thời gian check out
affiliate_id - Một nơi (website, trang tìm kiếm, ...) mà khách hàng click vào trước khi vào booking.com giống những thông tin quảng cáo mn hay thấy về shopee hay tiki trên FB thì FB sẽ là trường này được mã hóa
device_class - desktop/mobile
booker_country - Thành phố tại nơi lúc mà khách hàng thực hiện đặt phòng
hotel_country - Đất nước của khách sạn bạn đặt
city_id - thành phố nơi khách sạn bạn đặt
utrip_id - Nhận dạng duy nhất của chuyến đi của khách hàng
EDA data
EDA bằng 1 dòng code
Như mình đã từng viết ở bài Exploring dữ liệu chỉ một dòng code trong python thì với dữ liệu của cuộc thi này chúng ta cũng có thể sử dụng để EDA dữ liệu như dưới đây.
import pandas as pd
import pandas_profiling
Đọc data train
data = pd.read_csv('booking_train_set.csv')
profile = pandas_profiling.ProfileReport(data, title='Pandas Profiling Booking Data Report', explorative=True)
profile
Dùng pandas_profiling để phân tích dữ liệu của cuộc thi bookingchallenge.com trong một dòng code kết quả thu được như sau:
 Hình1: EDA dữ liệu bằng pandas_profiling
Hình1: EDA dữ liệu bằng pandas_profiling
Các bạn thử down dữ liệu tại đây về rồi thử xem nhé.
Phân tích dữ liệu
Như ở trên mình thử test thử với một dòng code thì căn bản chúng ta có thể thấy data của cuộc thi này khá là clean và cũng không có missing data vì vậy chúng ta không cần phải giải quyết vấn đề missing data ở đây nữa .
Trước tiên chúng ta cùng xem xem shape của tập train và tập test là bao nhiêu nhé.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# read train, test data
train = pd.read_csv('booking_train_set.csv', dtype={"user_id": str, "city_id": str, 'affiliate_id': str,
'utrip_id': str},date_parser=['checkin', 'checkin'])
test = pd.read_csv('booking_test_set.csv')
# check shape train, test data
print(train.shape, test.shape)
Shape của train : (1166835, 10) ~ 1166835 hàng và 10 cột
shape của test: (378667, 11), 378667 hàng và 11 cột
 Hình 1: train, test data
Hình 1: train, test data
ở đây trong tập test có thêm 2 columns khác với tập train: 'row_num', 'total_rows' tuy nhiên 2 columns này không ảnh hưởng gì đến kết quả cả Tiếp theo chúng ta sẽ thử xem dữ liệu này chứa missing data hay không?
train.info()
 Hình2: check missing data
Dựa vào hình 2 chúng ta có thể nhận thấy rằng dữ liệu train của cuộc thi này khá là sạch và không có giá trị missing luôn vậy cũng tốt đỡ mất công điền giá trị bị missing =))
Hình2: check missing data
Dựa vào hình 2 chúng ta có thể nhận thấy rằng dữ liệu train của cuộc thi này khá là sạch và không có giá trị missing luôn vậy cũng tốt đỡ mất công điền giá trị bị missing =))
Tiếp tục phân tích dữ liệu để xem xem số lượng user_id, city_id, booker_country, hotel_country trong dữ liệu train là bao nhiêu?
# number of user_id
len(train.user_id.unique())
# number of city_id
len(train.city_id.unique())
# number of booker_country
len(train.booker_country.unique())
# number of hotel_country
len(train.hotel_country.unique())
# number of utrip_id
len(train.utrip_id.unique())
Số lượng user_id ở đây là 200153
Số lượng city_id: 39901
Số lượng booker_country: 5
Số lượng hotel_country: 195
Số lượng utrip_id: 217686
Dựa vào số lượng utrip_id và city_id nếu như chúng ta dùng multiclass để classification 39901 class này khá là vất vả  . Vì vậy mình lựa chọn baseline là Matrix Factorization để gợi ý thì mình sẽ tính toán điểm tương đồng của các city_id với nhau để gợi ý cho từng user.
. Vì vậy mình lựa chọn baseline là Matrix Factorization để gợi ý thì mình sẽ tính toán điểm tương đồng của các city_id với nhau để gợi ý cho từng user.
Plot Số lượng device_class.
train.device_class.value_counts().plot(kind='bar')
 Hình: số lượng device_class
Hình: số lượng device_class
Plot số lượng booker_country
train.booker_country.value_counts().plot(kind='bar')
 Hình: số lượng booker_country
Hình: số lượng booker_country
Bây giờ chúng ta sẽ groupby user_id theo checkin để xem số lần check in của từng user_id là bao nhiêu trong tập dữ liệu mà ban tổ chức cung cấp.
# groupby user_id follow checkin
train_user_group = train.groupby('user_id').count()[['checkin']].sort_values('checkin',ascending=False)
Kiểm tra số lần checkin nhiều nhất trong các user_id là bao nhiêu
train_user_group.checkin.max()
# result: 172
Số lần checkin nhiều nhất là 172 lần, check xem thử xem user_id nào có số lượng checkin này nhiều nhất.
train_user_group[train_user_group['checkin'] == 172]
Vậy chúng ta có thể thấy user_id = 2209265 có số lượng lần checkin nhiều nhất là 172 lần. Thử vẽ biểu đồ xem phân bố của lượt checkin như thế nào nhé.
sns.boxplot(x="checkin", data=train_user_group)
 Hình: boxplot checkin của user_id
Hình: boxplot checkin của user_id
Dựa vào biểu đồ trên chúng ta có thể thấy rằng số lần checkin của từng user_id hầu hết ở trong (0, 75), còn số lượng lớn hơn 75 thì rất ít.
Tính số ngày ở tại các city_id của từng user_id.
train['checkin'] = pd.to_datetime(train['checkin'])
train['checkout'] = pd.to_datetime(train['checkout'])
train['duration'] = (train['checkout'] - train['checkin']).dt.days
train.head()

Hình: data train
train_group_checkin = train.groupby('checkin').agg({'user_id': 'count', 'duration': 'mean'})
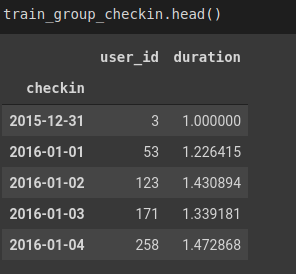
Hình: train_group_checkin
Vẽ biểu đồ quan hệ giữa checkin và user_id
g = sns.relplot(
data=train_group_checkin,
x="checkin", y="user_id", kind="line", height=8
)
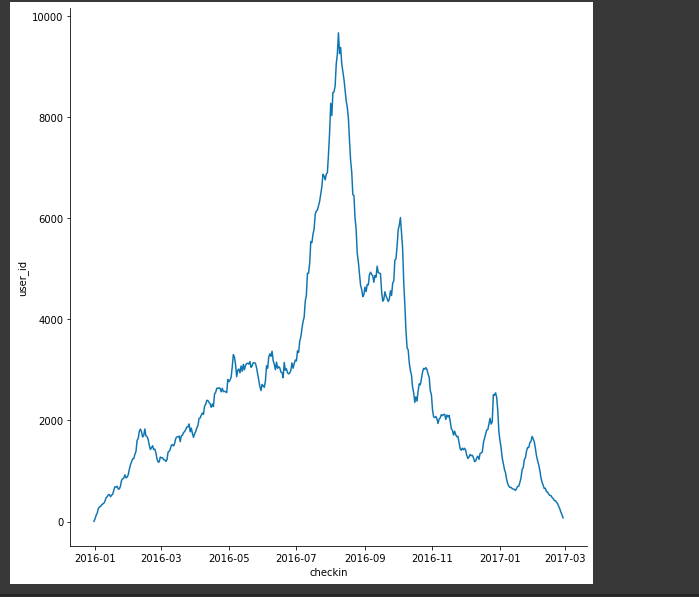
Hình: relative of user_id and checkin
Groupby city_id theo checkin và duration để tính xem mỗi city_id được checkin bao nhiêu lần.
train_city_group = train.groupby('city_id').agg({'checkin': 'count', 'duration': 'mean'})\
.sort_values('checkin',ascending=False)
Kiểm tra xem city_id nào được checkin nhiều nhất:
train_city_group[train_city_group['checkin'] == train_city_group.checkin.max()]
Result: city_id: 47499 checkin 11242 lần. Thử vẽ biểu đồ xem phân bố của lượt checkin đối với city_id như thế nào nhé.
sns.boxplot(x="checkin", data=train_city_group)
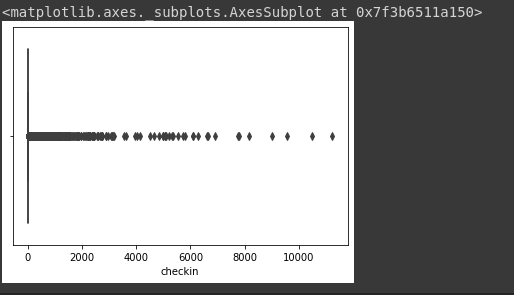
Hình: boxplot checkin của city_id
Dựa vào hình trên chúng ta có thể thấy rằng lượng checkin chủ yếu nằm trong khoảng từ 0 cho đến 6000 còn lớn hơn 6000 thì khác là ít
Tiếp theo chúng ta kiểm tra những chuyển đi đến city_id trong mỗi tháng.
train['checkin_month'] = train.checkin.dt.month
# groupby city_id and checkin_month follow checkin and duration
train_city_month_group = train.groupby(['city_id', 'checkin_month']).agg({'checkin': 'count', 'duration': 'mean'})\
.reset_index().sort_values(['city_id', 'checkin_month', 'checkin'],ascending=False)
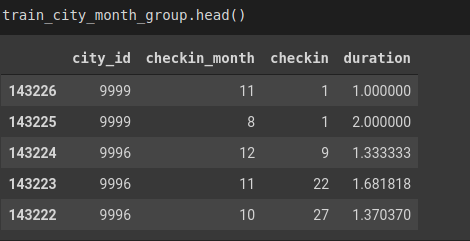
Hình: train_city_month_group data
# Initialize a grid of plots with an Axes for each walk
city_idx = list(train_city_group.index)[:10]
df_plot = train_city_month_group[train_city_month_group.city_id.isin(city_idx)]
grid = sns.FacetGrid(df_plot, col="city_id", hue="city_id", palette="tab20c",
col_wrap=5, height=2.5)
grid.map(plt.plot, "checkin_month", "checkin", marker="o")
grid.fig.tight_layout(w_pad=1)
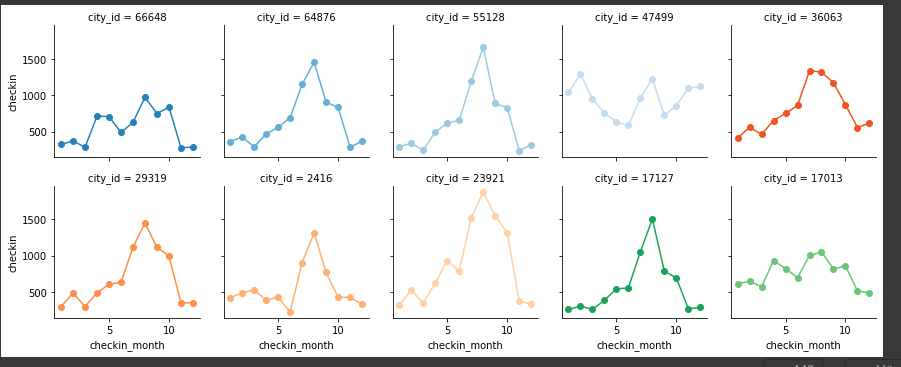
Hình: plot 10 city_id
Ở trên đây mình đã phân tích dữ liệu train rồi mọi nguời có thể tham khảo colab ở đây nhé . Tiếp theo chúng ta sẽ đến với mô hình baseline nhé ^^.
Baseline model
City_id Population
Idea cho tìm ra thành phố phổ biến nhất khá là đơn giản.
- Đầu tiên mình tìm thành phố phổ biến nhất trong từng hotel_country
- Sau đó với tập test: Với mỗi utrip_id mình kiểm tra xem user_id đó trong utrip_id này đã đi đến hotel_country nào nhiều nhất, => thành phố tiếp theo chính là thành phố phổ biến nhất trong hotel_country đó.
# list hotel_country
list_hotel_country = data.hotel_country.unique()
len(list_hotel_country)
Chúng ta có tổng cộng 195 hotel_country, tiếp theo sẽ tìm các city phổ biến trong từng hotel_country.
popular_city = []
for i in range(len(list_hotel_country)):
# print(list_hotel_country[i])
data_hotel = data[data.hotel_country == list_hotel_country[i]]
z = data_hotel.city_id.value_counts()
z1 = z.to_dict() #converts to dictionary
data_hotel['count_city'] = data_hotel['city_id'].map(z1)
popular_city.append(data_hotel[data_hotel.count_city == data_hotel.count_city.max()]\
[['city_id', 'count_city']].drop_duplicates().city_id.to_list()[0])
# Create dataframe popular_city
popular_data = pd.DataFrame(
columns=['hotel_country', 'city_id'])
popular_data['hotel_country'] = list_hotel_country.tolist()
popular_data['city_id'] = popular_city
Cùng dự đoán thành phố tiếp theo cho tập test data của bookingchallenge.com nhé. Đầu tiên đọc dữ liệu test :
test = pd.read_csv('booking_test_set.csv')
trong data test này mỗi utrip_id sẽ có một thành phố là Null vì vậy trước hết chúng ta sẽ loại bỏ thành phố null và giữ lại những thành phố not null trước nhé.
test_data_nona = test[test.hotel_country.notna()]
Tiếp theo đây chúng ta sẽ dự đoán thành phố tiếp theo mà user sẽ đi tới nhé.
city_id_pred = []
for i in range(len(list_utrip_id)):
test_hotel = test_data_nona[test_data_nona.utrip_id == list_utrip_id[i]]
z = test_hotel.hotel_country.value_counts()
z1 = z.to_dict() #converts to dictionary
test_hotel['count_hotel'] = test_hotel['hotel_country'].map(z1)
hotel = test_hotel[test_hotel.count_hotel == test_hotel.count_hotel.max()]\
[['hotel_country', 'count_hotel']].drop_duplicates().hotel_country.to_list()[0]
city_id_pred.append(popular_data[popular_data.hotel_country==hotel].city_id.to_list()[0])
Như vậy chúng ta đã dự đoán được thành phố tiếp theo dựa vào thành phố phổ biến của từng hotel_country như idea mình đã đưa ra ở trên, mọi người thử chạy theo nhé .
Mô Hình dự đoán city tiếp theo
Mô hình baseline mình dùng là mô hình MF dùng thư viện implicit của benfred
Đầu tiên import thư viện đã nhỉ
import pandas as pd
import numpy as np
import datetime
train_data = pd.read_csv("booking_train_set.csv")
test_data = pd.read_csv("booking_test_set.csv")
# get test data is nan
test_data_na = test_data[test_data.hotel_country.isna()]
# get test_data is not na
test_data_nona = test_data[test_data.hotel_country.notna()]
train_data = train_data[[ 'user_id', 'checkin', 'checkout', 'city_id',
'device_class', 'affiliate_id', 'booker_country', 'hotel_country',
'utrip_id']]
test_data_nona_1 = test_data_nona[[ 'user_id', 'checkin', 'checkout', 'city_id',
'device_class', 'affiliate_id', 'booker_country', 'hotel_country',
'utrip_id']]
# concat train an test data
total_data = pd.concat([train_data, test_data_nona_1])
Sau khi đã concat data train và data test xong thì chúng ta sẽ tính số lượng utrip_id trong 1 chuyến đi đã di chuyển đến bao nhiêu thành phố.
z = total_data.utrip_id.value_counts()
z1 = z.to_dict() #converts to dictionary
total_data['count_utrip'] = total_data['utrip_id'].map(z1)
Tiếp theo đó chúng ta sẽ tính số lần đi đến một city của một utrip_id
total_data['user_city'] = total_data[['utrip_id','city_id']].apply(tuple, axis=1)
z = total_data['user_city'].value_counts()
z1 = z.to_dict() #converts to dictionary
total_data['count_u_c'] = total_data['user_city'].map(z1)
Tính số lần đi đến hotel_country của một utrip_id
total_data['user_hotel'] = total_data[['utrip_id','hotel_country']].apply(tuple, axis=1)
z = total_data['user_hotel'].value_counts()
z1 = z.to_dict() #converts to dictionary
total_data['count_u_h'] = total_data['user_hotel'].map(z1)
Tính số ngày trong một chuyển đi của mỗi utrip_id
total_data['checkin'] = pd.to_datetime(total_data['checkin'])
total_data['checkin1'] = total_data['checkin'].map(datetime.datetime.toordinal)
total_data['checkout'] = pd.to_datetime(total_data['checkout'])
total_data['checkout1'] = total_data['checkout'].map(datetime.datetime.toordinal)
total_data['days'] = total_data['checkout1'] - total_data['checkin1']
Mình xem xem tổng (total_data['count_u_c'] + total_data['count_u_h'] + total_data['d']) là rating của mỗi utrip_id với một city_id để training mô hình.
total_data['count_u_c'] + total_data['count_u_h'] + total_data['d']
# data train
data_train = total_data[['utrip_id', 'city_id', 'new_rt']]
# drop duplicate
data_train2 =data_train[['utrip_id', 'city_id']].drop_duplicates()
data_train1 = data_train.groupby(['utrip_id', 'city_id']).max()['new_rt']
c_maxes = data_train.groupby(['utrip_id', 'city_id']).new_rt.transform(max)
data_train_1 = data_train.loc[data_train.new_rt == c_maxes]
data_train1 = data_train.sort_values("new_rt", ascending=False)
data_train1 = data_train.drop_duplicates(['utrip_id', 'city_id'])
Tiếp theo chúng ta sẽ normalize dữ liệu city_id và utrip_id về dạng theo thứ tự từ 1-> n. Đầu tiên là với utrip_id
utrip = data_train1.utrip_id.value_counts().to_frame()
utrip = utrip.reset_index()
utrip[['utrip_id_new', 'utrip_id']] =utrip[['index', 'utrip_id']]
utrip = utrip[['utrip_id_new', 'utrip_id', 'count']]
utrip = utrip.reset_index()
Tiếp theo đến city_id
city_data = data_train1.city_id.value_counts().to_frame()
city_data = city_data.reset_index()
city_data[['city_id', 'count']] = city_data[['index', 'city_id']]
city_data = city_data[['city_id', 'count']]
city_data = city_data.reset_index()
Sau khi đã normalize xong thì chúng ta merge lại để tạo data_train nhé.
utrip_id_new = utrip[['utrip_id', 'utrip_id_new']]
city_id_new = city_data[['city_id', 'city_id_new']]
data_train1 = data_train1.merge(city_id_new, how='left')
data_train1 = data_train1.merge(utrip_id_new, how='inner')
Hình: dữ liệu data_train_1
Bây giờ chúng ta sẽ train với implicit
#install implicit
!pip install implicit
import implicit
import scipy.sparse as sparse
from scipy.sparse.linalg import spsolve
Chuyển dữ liệu về dạng sparse matrix
user_id = pd.CategoricalDtype(sorted(data_train1.utrip_id_new.unique()), ordered=True)
city_id = pd.CategoricalDtype(sorted(data_train1.city_id_new.unique()), ordered=True)
rating = list(data_train1.new_rt)
rows = data_train1.utrip_id_new.astype(user_id).cat.codes
# Get the associated row indices
cols = data_train1.city_id_new.astype(city_id).cat.codes
# Get the associated column indices
data_sparse = sparse.csr_matrix((rating, (cols, rows)), shape=(city_id.categories.size, user_id.categories.size))
Định nghĩa và train mô hình
model = implicit.als.AlternatingLeastSquares(factors=416,
regularization = 0.01,
iterations = 500)
model.fit((data_sparse*15).astype('double'))
data_test = pd.read_csv('dara_test.csv')
user_items = data_sparse.T.tocsr()
test = pd.read_csv('booking_test_set.csv')
for i in range(len(data_test)):
# print(data_test.utrip_id_new[i])
rec = model.recommend(data_test.utrip_id_new[i], user_items)
rec_list_mf.append(rec[0][0])
Vậy là đã train xong mô hình baseline rồi! Mọi người tham khảo code ở đây nhé.
Kết Luận
Ở bài viết này mình đã phân tích dữ liệu của cuộc thi cũng như đưa ra 2 mô hình baseline là dự đoán thành phố tiếp theo dựa trên thành phố phổ biến của từng hotel_country. Mô hình thứ 2 mình sử dụng user-user based. Bên cạnh đó các bạn có thể dùng RNN hay Attention để dự đoán cho bài toán này. Mọi người có thể tham khảo mô hình Self-attention for Recommendation của mình ở đây nhé.
Cảm ơn mọi người đã đọc bài viết của mình nhé. Mọi người nhớ upvoted cho mình nha
Reference
https://www.bookingchallenge.com/
https://viblo.asia/p/exploring-du-lieu-chi-mot-dong-code-trong-python-ByEZk29xKQ0
https://drive.google.com/file/d/12OjQrLsre3iIn9kap1PF-RmxTojm0IMr/view?usp=sharing
All rights reserved
