
[Deep Learning][Optimization] Neural Network Compression - All essential things You Need!
Bài đăng này đã không được cập nhật trong 5 năm
Chào mọi người, chúng ta đang sống và làm việc trong sự trỗi dậy rất lớn của AI trong một vài năm trở lại đây, đặc biệt là ở Việt Nam, người người nhà nhà đều AI, các trường đại học cũng mở ra vô số các khoa các nghành mới liên quan đến thuật ngữ này với một tương lai đầy hứa hẹn để thu hút các tân sinh viên. Với sự mạnh mẽ của các thuật toán như ML, đặc biệt là Deep Learning,... có những bài toán độ chính xác của máy đã có thể vượt con người trong khả năng nhận diện và tương lai sẽ còn hơn thế nữa. Ngay từ hồi đi học mình vẫn rất thường được nghe các thầy của mình nói vui rằng Deep Learning là bộ môn của con nhà giàu, tất nhiên đây chỉ là 1 cách nói biếm họa để chỉ cho thấy sự tốn kém trong việc đầu tư máy móc phục vụ việc nghiên cứu, phát triển các bài toán dạng này, và không phải ai cũng sẵn sàng để chi ra 1 số tiền lớn cho các máy tính kiểu như thế này, đặc biệt là khách hàng của chúng ta những người luôn đặt yếu tố kinh tế lên hàng đầu.
Vậy câu hỏi đặt ra là cơ hội nào cho những mô hình Deep Learning này chạy được trên các ứng dụng đời thường như các ứng dụng chạy trên máy tính CPU (without GPU) or trên các máy điện thoại. Đã có những ý tưởng được đưa ra ví dụ như sự cải tiến trong các mô hình deep learning, giúp nó nhẹ hơn, đòi hỏi ít tham số mô hình hơn mà vẫn đạt được độ chính xác cao như MobileNet, SqueezeNet,... hoặc các techniques compress model như Neural Network pruning, quantization,... etc
Do vậy, ở bài viết này, mình sẽ cung cấp cho mọi người:
- 1 cái nhìn tổng quan nhất về 1 số techniques của models compression
- Giải thích chi tiết cách thức hoạt động của
Neural Network Pruning,Neural Network quantizationbằng việc cung cấp các kiến thức từ papers - Cung cấp code implement để mọi người có thể áp dụng được
- Cung cấp các tài liệu mà mình đã thu được thành một nguồn để các bạn tham khảo
Note: Bài viết này được viết dựa trên ý hiểu cá nhân thông qua mình đọc các blog posts và papers, mọi ý kiến đóng góp xin vui lòng write comments down below or send throught email của mình @nguyen.van.dat@sun-asterisk.com. Nếu nó có ích cho bạn, đừng tiếc 1 upvote cho mình nhé  .
.
I. Introduction
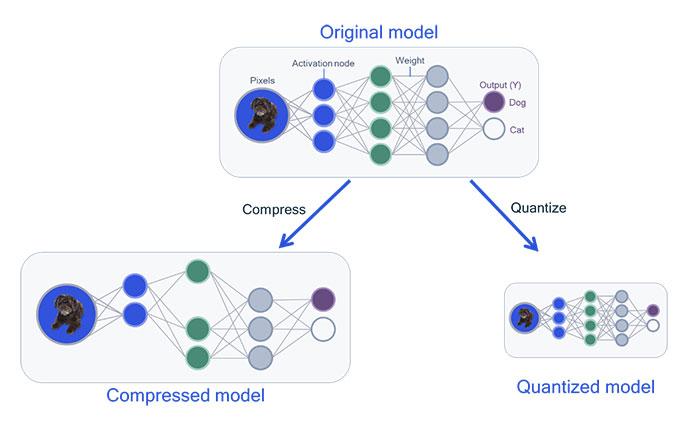
Ảnh minh họa cho compression model
Trước khi đi vào chi tiết về cách thức hoạt động, cách implement, chúng ta sẽ cùng nhau tìm hiểu sơ qua Neural Network Compression là gì, và tại sao cần quan tâm đến techniques này nhé.
Đầu tiên, có thể nói các thuật toán Neural Network Compression là một nhánh nhỏ trong tập thuật toán model optimization, nó được sinh ra với mục đích giúp giải quyết bài toán khi deploy các model Deep Learning trên các thiết bị phần cứng không được mạnh mẽ như (mobile devices, ...). Với một mô hình deep learning, sẽ luôn có 1 câu hỏi thường trực là liệu model này có khả năng ứng dụng thực tế hay không, có khả năng chạy realtime trên một device đời thường để khi deploy lên ai cũng có thể sử dụng được không. Thật sự là không dễ dàng gì khi mà chúng ta luôn phải trade-off giữa độ chính xác và tốc độ xử lý của 1 mô hình, thông thường độ chính xác cao như ở 1 số paper SOTA (state-of-the-art) thường chứa 1 lượng tham số rất lớn (chục triệu đến hàng trăm triệu tham số) dẫn đến việc lưu trữ và tính toán trở lên khó khăn hơn rất nhiều nếu không có các thiết bị hỗ trợ (như GPU), còn một số mô hình quá ít tham số thì dẫn đến việc đôi khi lại không đủ sâu để học được hết các features và trả về độ chính xác đủ tốt. Vì vậy, các phương pháp optimize model ra đời giúp các model này trở lên gọn nhẹ hơn, nhỏ hơn nhưng vẫn đủ mạnh mẽ như model ban đầu khi đưa chúng chạy trên các ứng dụng thực tế, điều này là rất cần thiết vì không ai trong chúng ta muốn một model tiêu tốn bao công training lại không thể apply vào bất kì ứng dụng nào.
Hiện nay có khá nhiều các thuật toán model compression, có thể kể đến như: Network Pruning and Quantization, Low-rank Factorization, Transferred/compact convolutional filters or Knowledge distillation, ... Cùng xem qua bảng tổng quan về ý tưởng, ứng dụng của các thuật toán qua ảnh dưới đây:
 Ảnh được copy từ official paper A Survey of Model Compression and Acceleration
for Deep Neural Networks
Ảnh được copy từ official paper A Survey of Model Compression and Acceleration
for Deep Neural Networks
Mỗi thuật toán có một nguyên lý hoạt động khác nhau, giờ chúng ta sẽ cùng tìm hiểu chi tiết một số thuật toán thông dụng.
II. Techniques
Ở đây, mình giả sử chúng ta đã train được 1 model đủ tốt, nghĩa là chúng ta hài lòng về độ chính xác, nhưng vì nó quá nặng cả về size lẫn thời gian tính toán, gặp khó khăn khi ta muốn đóng gói và deploy để thử nghiệm. Do đó chúng ta muốn nén cái model này lại để nó bé và nhanh hơn. Dưới đây là một vài techniques chúng ta có thể sử dụng:
2.1 Network Pruning
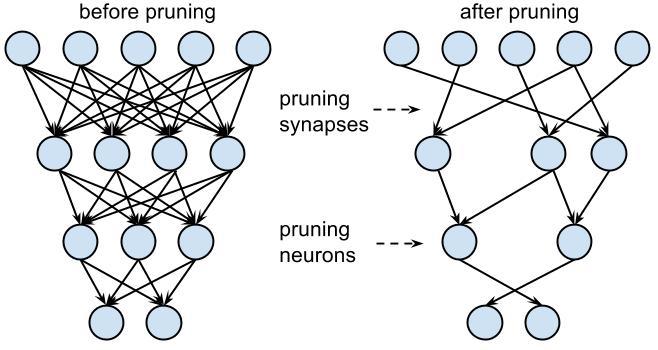
Ảnh minh họa cho Network Pruning
Đúng với ý nghĩa của từ "Pruning", kĩ thuật này dựa trên ý tưởng loại bỏ đi những thành phần dư thừa trên toàn bộ tham số mô hình. Trong tổng số những tham số mà mô hình đang lưu trữ, sẽ có những tham số đóng vai trò chính và cũng có những tham số không đóng góp được gì nhiều. Sự đóng góp này được thể hiện qua giá trị weight mà nó đang lưu trữ. Giá trị lớn hơn đóng vai trò lớn hơn và ngược lại.
Do đó việc tìm ra một ngưỡng (threshold) để phân loại giữa đâu là weight quan trọng và đâu là weight không quan trọng là cốt lõi của thuật toán này. Các threshold này có thể là 1 số do ta tự định nghĩa hoặc cũng có thể dynamic theo kiểu là giá trị độ lệch chuẩn (standard deviation) của tập weights. Quan sát ảnh phía trên có thể thấy, các connection có giá trị weight nhỏ hơn giá trị threshold này sẽ bị lược bỏ (xét về 0), dẫn đến chúng ta sẽ thu được các sparse weight matrix hay còn gọi là ma trận weight rời rạc.
Tại thời điểm này, sau khi pruning chất lượng mô hình sẽ không còn được như ban đầu vì nó đã bị cắt đi một vài thành phần. Do đó chúng ta cần train lại pruned model để các weights params của nó được cập nhật lại các giá trị mới sao cho nó bù lại được những gì nó đã mất. Kỹ thuật này được gọi là Iterative Pruning. Ngoài ra, trong paper Learning both Weights and Connections for Efficient
Neural Networks, tác giả còn prune cả neurons, không chỉ mỗi weights.
Note: Tensorflow có cung cấp cho chúng ta 1 module tensorflow-model-optimization giúp giải quyết bài toán này, chúng ta chỉ cần follow theo hướng dẫn tại đây là có thể thực hiện được. Tuy nhiên, trong phần implementation để hiểu hơn về thuật toán, mình sẽ cùng nhau implement lại từ đầu để hiểu hơn về thuật toán thay vì chỉ biết dùng công cụ có sẵn
2.2 Network Quantization
 Ảnh minh họa cho quantization techniques
Ảnh minh họa cho quantization techniques
Tại đây, chúng ta quan tâm đến việc tối ưu hóa việc lưu weight như thế nào hơn là tối ưu hóa giá trị weight đang có. Quay ngược lại lý thuyết arithmetic operations, hiện ta cần dùng 32bits để biểu diễn mỗi weight (floating-point of 32 bits), do đó ý tưởng chính của quantization là làm sao để giảm số lượng bit cần dùng để biểu diễn này xuống mà vẫn giữ được độ chính xác của mô hình. Cụ thể hơn là chuyển hoá các floating-point arithmetic thành fixed-point trong các mạng neural networks.
Một số thuật ngữ về quantization chúng ta có thể quan tâm đến như:
- Low precision: biểu thị việc dùng các numeric format như FP16 (half precision floating point), INT8 (fixed point integer of 8 bits),... để biểu diễn weights
- Mixed precision: dùng cả FP32 và FP16 cho việc lưu trữ, trong đó FP16 giúp giảm 1 nửa memory size, còn FP32 có nhiệm vụ lưu giữ lại những weights quan trọng nhất.
1 số sub-categories của quantization như:
- Binary Neural Network: Neural networks với binary weight
- Ternary Weight Networks: Neural networks với các giá trị weights trong khoảng +1, 0, -1
 Ví dụ 1 số kiểu kiến trúc áp dụng model quantization (ảnh copy)
Ví dụ 1 số kiểu kiến trúc áp dụng model quantization (ảnh copy)
Hiện nay một số frameworks cung cấp cho chúng ta cả các Quantize/Dequantize layers giúp convert input/output thành INT8 trước khi đưa/lấy chúng qua/từ các Convolution/FC layers, về mặt bản chất thì các input/output và model vẫn có dạng format FP32. Hoặc cũng có 1 số hỗ trợ việc convert cả mô hình sang kiểu INT8 luôn. Cùng tham khảo hình phía trên.
2.3 Weight-Sharing
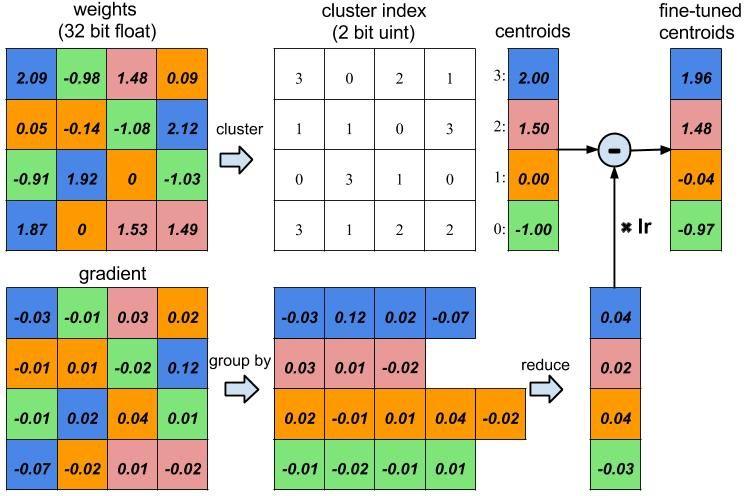
Ảnh minh họa: Weight Sharing (Copy từ official paper)
Tại đây chúng ta cùng tìm hiểu một loại technique mới cũng được áp dụng rất nhiều trong model compression đó là Weight-Sharing, 1 số paper rất hay nói về technique này các bạn có thể đọc tại Deep Compression. Ý tưởng chung của thuật toán này đó là việc chia sẻ các tham số weight giữa các phần tử weight trong các matrix weight của mô hình. Như các mô hình thông thường, mỗi phần tử trong ma trận weight sẽ có giá trị riêng của chúng, nhưng khi áp dụng weight-sharing, các giá trị weight của ma trận sẽ được tổ chức lại thành các nhóm, các phần tử cùng nhóm sẽ có cùng chỉ số weight.
Vậy tại sao nó lại tiết kiệm được bộ nhớ, giúp mô hình nhẹ hơn. Các bạn cùng quan sát hình phía trên, thay vì nó lưu toàn bộ weight thì giờ đây ta chỉ lưu lại giá trị weight của các nhóm và ma trận chỉ số nhóm cho các phần tử thuộc ma trận weight này.
Phân tích thêm 1 chút nhé: Lấy ví dụ cách tính toán ở hình trên, đầu tiên ta khởi tạo giá trị các nhóm bằng cách lấy trung bình cộng của các giá trị gần giống nhau và lưu lại các chỉ số nhóm cho các phần tử này. Với mỗi lần tính toán gradient, các giá trị gradient của mỗi phần tử tại các nhóm sẽ được tính tổng lại rồi nhân với giá trị learning_rate. Giờ đây ta sẽ áp dụng gradient descent lên các nhóm này.
Việc chia sẻ weights như thế này tất nhiên sẽ ảnh hưởng đến độ chính xác của mô hình, do đó sau mỗi lần tính toán weight-sharing ta cần retrain để update và tìm được bộ tham số tốt nhất cho mô hình. Ngoài ra việc tìm được số nhóm weight tối ưu cũng là rất quan trọng.
Mình sẽ chia sẽ cách thực hiện thuật toán này với tensorflow tại phần implementation.
2.4 Knowledge Distillation (KD)
 Ảnh ví dụ một thuật toán sử dụng KD (copy)
Ảnh ví dụ một thuật toán sử dụng KD (copy)
Thuật toán đầu tiên được sử dụng với cái tên knowledge transfer để xuất bởi Caruana, về sau được hiểu dưới context của Knowledge Distillation. Tư tưởng chính của thuật toán là nén một mô hình lớn và sâu hơn dưới dạng một mô hình nhỏ hơn bằng cách cho mô hình nhỏ hơn bắt chước những gì mô hình lớn đã học được thông qua phân phối các output class từ softmax. Các mô hình kiểu này được training dựa theo kiểu teacher-student, mô hình lớn sẽ là teacher còn mô hình nhỏ hơn là student. Các mô hình nhỏ sẽ học dựa trên các label hay soft-label được sinh ra từ mô hình lớn.
Ngay từ đầu, điểm hạn chế của KD là không hiệu quả với các mô hình con với kiểu kiến trúc quá nông, quá ít tham số. Tuy nhiên với sự ra đời của 1 cách tiếp cận mới, FitNets, và các kiểu kiến trúc giúp mô hình nhẹ hơn, ít tham số hơn nhưng vẫn giữ được độ sâu như kiến trúc residual connection, inception, squeeze đã giúp KD trở lên mạnh mẽ hơn rất nhiều.
Hạn chế của KD là nó chỉ áp dụng được cho các bài toán classification, vì mạng student học qua output lớp softmax của mạng teacher, và so sánh với 1 số thuật toán Model Compression khác, nó cũng tỏ ra kém hiệu quả hơn.
III. Coding Implementation
Hiện nay, tensorflow đã cung cấp api giúp việc compress model rất hiệu quả. Tuy nhiên, để hiểu rõ bản chất vấn đề và mình cũng muốn biết đâu trong quá trình mày mò implement mình lại ra được ý tưởng gì đó để viết paper (hihi).
Ở phần này, mình follow theo tư tưởng của paper DEEP COMPRESSION: COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINED QUANTIZATION AND HUFFMAN CODING, bước 1 sẽ là network pruning, bước 2 là quantization và weight sharing, còn mình bỏ qua bước 3 vì huffman coding là 1 thuật toán riêng biệt và nên được tách ra thành 1 bài cụ thể thì hay hơn. Vì code cho toàn bộ quá trình training và các kỹ thuật là khá dài nên mình sẽ chỉ show lên 1 vài function chính nhất, phần source code mình sẽ cung cấp để mọi người tham khảo được kỹ hơn. Giờ ta sẽ đi chi tiết vào từng phần 1.
3.1 Network pruning
Ta sẽ tạo 1 class layer, trong đó bao gồm hàm khởi tạo các thông số layer, hàm feed forward, các hàm pruning và quantization.
Đầu tiên, khởi tạo layers:
class TrainLayer(object):
def __init__(self, input_dims, output_dims, n_clusters, name, kernel_size=(5, 5)):
self.name = name
self.kernel_size = kernel_size
if "conv" in self.name:
self.w = tf.Variable(initial_value=tf.random.normal((*kernel_size, input_dims, output_dims),
stddev=0.1))
elif "fc" in self.name:
self.w = tf.Variable(initial_value=tf.random.normal([input_dims, output_dims],
stddev=0.1))
self.w_PH = tfv.placeholder(tf.float32, shape=self.w.shape)
self.assign_w = tfv.assign(self.w, self.w_PH)
self.num_total_weights = np.prod(self.w.shape)
### Create mask for pruning weight
self.pruning_mask_data = np.ones_like(self.w.shape, dtype=np.float32)
### Number of cluster for quantization
self.n_clusters = n_clusters
def forward(self, x):
if "conv" in self.name:
return tf.nn.conv2d(x, self.w, strides=[1, 1, 1, 1], padding="SAME")
elif "fc" in self.name:
return tf.matmul(x, self.w)
Trên đây, chúng ta quan tâm đến w lưu các giá trị weight của layer, w_PH dùng để tính toán các giá trị weight sau khi thay đổi sau đó feed vào hàm assign để gán lại giá trị cho w. pruning_mask_data dùng để lưu vị trí giá trị weights, 0 là đã bị pruning, và 1 là có giá trị. Và cuối cùng là clusters, số nhóm dùng cho quantization và weight-sharing.
Tiếp đến ta sẽ cùng ngó qua hàm pruning, và các hàm update giá trị sau mỗi lần pruning:
def prune_weights(self, sess, threshold):
w_data = sess.run(self.w)
self.pruning_mask_data = (w_data >= threshold).astype(np.float32)
sess.run(self.assign_w, feed_dict={self.w_PH: self.pruning_mask_data*w_data})
def prune_weights_gradient(self, grad):
return grad * self.pruning_mask_data
def prune_weights_update(self, sess):
w_data = sess.run(self.w)
sess.run(self.assign_w, feed_dict={self.w_PH: self.pruning_mask_data*w_data})
Ta sẽ chỉ pruning weight 1 lần sau khi mô hình đã được train đến 1 độ chính xác nhất định, và các bước sau đó là việc train đi train lại để phục hồi được độ chính xác cho mô hình. Tuỳ theo từng kiến trúc mô hình và độ sâu, thường thì sau iterative pruning độ chính xác mô hình sẽ giảm đi đôi chút. Việc xét ngưỡng để pruning là rất quan trọng, nó ảnh hướng khá nhiều đến độ chính xác, lời khuyên của mình là nên tính toán ra mean, và độ lệch chuẩn của weight để có thể chọn ra được 1 giá trị threshold phù hợp.
 Ảnh minh hoạ cho weight matrix sau khi pruning (copy)
Ảnh minh hoạ cho weight matrix sau khi pruning (copy)
3.2 Quantization and Weight-sharing
Như đã trình bày từ trước, tư tưởng chính của thuật toán này là việc phân cụm cho các giá trị weight. Cụ thể mọi người có thể đọc lại phần bên trên nhé. Dưới đây sẽ là example code cho phần này nha:
def quantize_weights(self, sess):
w_data = sess.run(self.w)
max_val = np.max(w_data)
min_val = np.min(w_data)
self.centroids = np.linspace(min_val, max_val, self.n_clusters)
w_data = np.expand_dims(w_data, 0)
centroids_prev = np.copy(self.centroids)
for i in range(30):
if 'conv' in self.name:
distances = np.abs(w_data - np.reshape(self.centroids, (-1, 1, 1, 1, 1)))
distances = np.transpose(distances, (1, 2, 3, 4, 0))
elif 'fc' in self.name:
distances = np.abs(w_data - np.reshape(self.centroids, (-1, 1, 1)))
distances = np.transpose(distances, (1, 2, 0))
classes = np.argmin(distances, axis=-1)
self.cluster_masks = []
for i in range(self.n_clusters):
cluster_mask = (classes == i).astype(np.float32) * self.pruning_mask_data
self.cluster_masks.append(cluster_mask)
num_weights_assigned = np.sum(cluster_mask)
if num_weights_assigned != 0:
self.centroids[i] = np.sum(cluster_mask * w_data) / num_weights_assigned
else:
pass
if np.array_equal(centroids_prev, self.centroids):
break
centroids_prev = np.copy(self.centroids)
self.quantize_weights_update(sess)
def quantize_weights_update(self, sess):
w_data_updated = np.zeros(self.w.shape, dtype=np.float32)
for i in range(self.n_clusters):
cluster_mask = self.cluster_masks[i]
centroid = self.centroids[i]
w_data_updated = w_data_updated + cluster_mask * centroid
sess.run(self.assign_w, feed_dict={self.w_PH: self.pruning_mask_data * w_data_updated})
def quantize_centroids_update(self, sess):
w_data = sess.run(self.w)
for i in range(self.n_clusters):
cluster_mask = self.cluster_masks[i]
cluster_count = np.sum(cluster_mask)
if cluster_count != 0:
self.centroids[i] = np.sum(cluster_mask * w_data) / cluster_count
else:
pass
def group_and_reduce_gradient(self, grad):
grad_out = np.zeros(self.w.shape, dtype=np.float32)
for i in range(self.n_clusters):
cluster_mask = self.cluster_masks[i]
centroid_grad = np.sum(grad * cluster_mask)
grad_out = grad_out + cluster_mask * centroid_grad
return grad_out
Đầu tiên ta cần tìm ra các điểm là trung tâm (centroid) của các cụm này, và các mask chỉ số biểu thị cho các các phần tử ma trận thuộc về từng class, số lượng các mask sẽ tương tự với số centroid và số lượng clusters. Để tìm được giá trị centroid, các cluster_mask tốt nhất, ta thực hiện 1 số vòng lặp nhất định , với mỗi vòng lặp tính toán khoảng cách từ centroid đến từng điểm weight của matrix weight, cluster mask tương ứng sẽ là các vị trí mà tại đó giá trị khoảng cách là nhỏ nhất. Sau mỗi lần lặp, giá trị centroid của từng cluster cũng sẽ được cập nhật lại bằng trung bình các giá trị weight được assign cho mỗi cluster (dựa vào cluster mask, ta sẽ biết được đâu là điểm được assign). Cuối cùng sau khi tìm được các giá trị tối ưu, ta thực hiện việc update nó cho ma trận weight của layer.
Ta cũng chỉ quantize và weight-sharing 1 lần duy nhất sau khi quá trình pruning hoàn tất, tương tự pruning, độ chính xác của mô hình sẽ bị ảnh hưởng khá nhiều sau khi thực hiện quantize và sharing weight, do đó ta lại cần train tiếp để giúp mô hình có khả năng lấy lại được những gì nó vừa thay đổi.
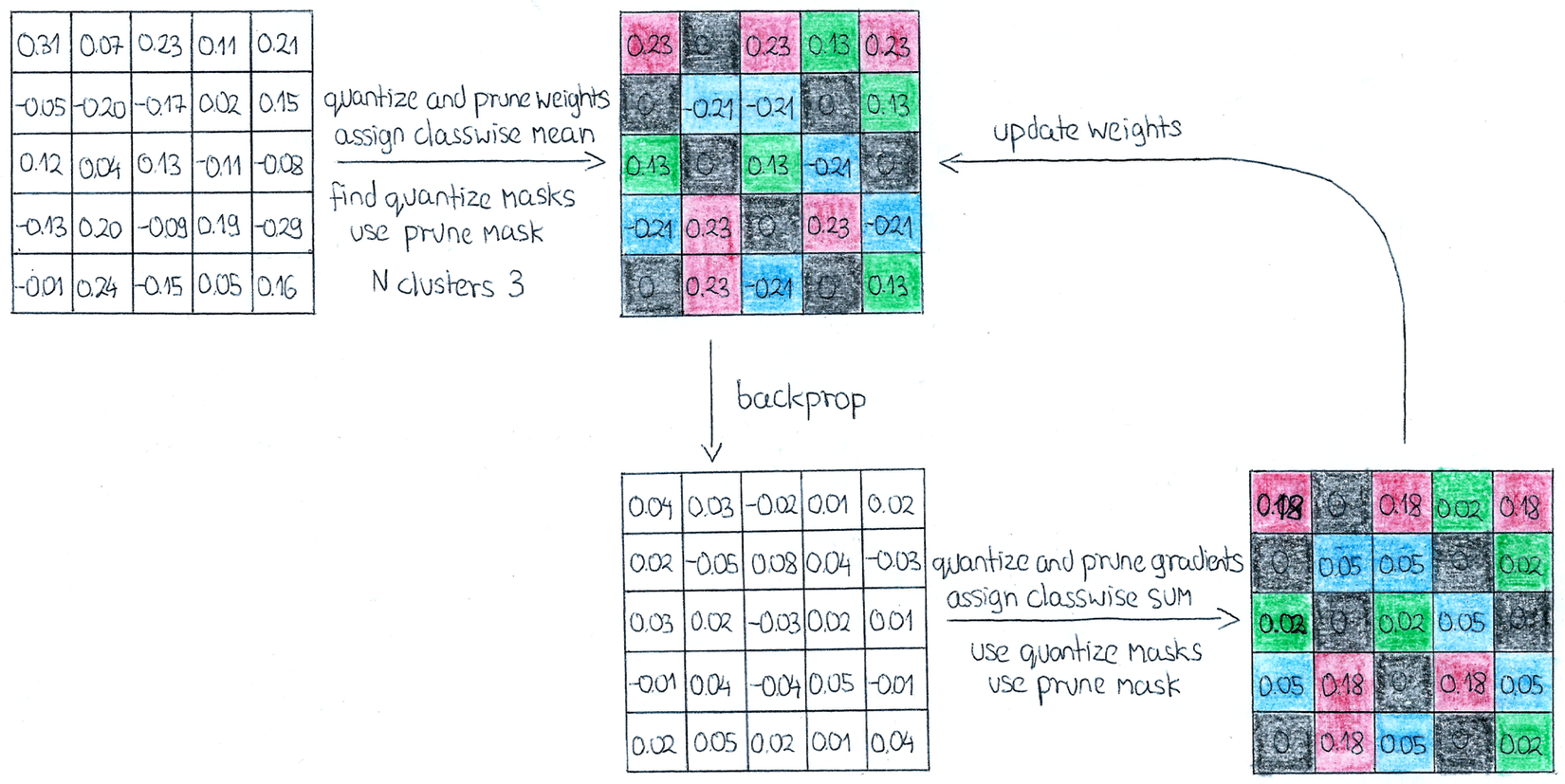
Ảnh minh hoạ cho quá trình quantize model (copy)
Theo paper Learning both Weights and Connections for Efficient Neural Networks, việc apply network pruning cho l2 regularization sẽ cho kết quả tốt hơn, các chỉ số dropout để retrain cũng sẽ thay đổi so với ban đầu để có thể thu được độ chính xác tốt hơn sau khi đã bị pruning đi 1 vài connections. Sau khi pruning, quantization và share weight, quá trình retrain lại sẽ mất khá nhiều thời gian, tuy nhiên đánh đổi với nó là ta thu được một mô hình có độ chính xác tương đương nhưng thời gian tính toán và kích thước mô hình lại nhẹ hơn rất nhiều.
=> Ok ngon rồi, giờ cùng qua phần conclusion nhé.
IV. Conclusion
Tại bài này mình đã cung cấp cho mọi người những kỹ thuật phổ biến nhất của Model Compression và code minh hoạ cho những kỹ thuật này. Các kỹ thuật này tuy không còn mới, tuy nhiên hiểu biết về nó cung cấp cho chúng ta một cách sâu hơn trong việc tính toán, custom weights cũng như một lĩnh vực nghiên cứu mới. Cảm ơn mọi người đã đọc đến đây, mọi người có thể kham khảo source code của mình dưới đây.
Mình sẽ chia sẻ sớm nhất ngay sau khi mình cần refactor lại source code. Cảm ơn mọi người.
References
- https://arxiv.org/pdf/1710.09282.pdf
- https://arxiv.org/pdf/1510.00149.pdf
- https://arxiv.org/pdf/1506.02626.pdf
- https://arxiv.org/pdf/1602.01528.pdf
- https://jackwish.net/2019/neural-network-quantization-introduction.html
- https://towardsdatascience.com/how-to-accelerate-and-compress-neural-networks-with-quantization-edfbbabb6af7
- https://github.com/WojciechMormul/deep-compression
- https://docs.oracle.com/cd/E19957-01/806-3568/ncg_goldberg.html
- https://viblo.asia/p/ong-toan-vi-loc-bi-kip-vo-cong-de-tao-mo-hinh-sieu-sieu-nho-li-ti-voi-do-chinh-xac-khong-lo-Qpmleon9Krd
- https://viblo.asia/p/compression-model-ap-dung-cac-ky-thuat-nen-de-tang-hieu-nang-su-dung-cac-mo-hinh-deep-learningphan-1-Az45br0z5xY
- https://arxiv.org/pdf/1712.05877v1.pdf
- https://youtu.be/vouEMwDNopQ
All rights reserved
