Công nghệ Matrix Factorization cho Hệ thống gợi ý
Bài đăng này đã không được cập nhật trong 7 năm
1. Tổng quan về hệ thống gợi ý
1.1. Giới thiệu về hệ thống gợi ý
Những hiện tượng dưới đây hiên nay đã trở nên phổ biến:
- Youtube tự động chuyển các clip liên quan đến clip bạn đang xem. Youtube cũng tự gợi ý những clip mà có thể bạn sẽ thích.
- Khi bạn mua một món hàng trên Amazon, hệ thống sẽ tự động gợi ý “Frequently bought together”, hoặc nó biết bạn có thể thích món hàng nào dựa trên lịch sử mua hàng của bạn.
- Facebook hiển thị quảng cáo những sản phẩm có liên quan đến từ khoá bạn vừa tìm kiếm.
- Facebook gợi ý kết bạn.
- Netflix tự động gợi ý phim cho người dùng.
Và rất nhiều ví dụ khác mà hệ thống có khả năng tự động gợi ý cho người dùng những sản phẩm họ có thể thích. Bằng cách quảng cáo hướng đúng đối tượng như thế này, hiệu quả của việc marketing cũng sẽ tăng lên. Những thuật toán đằng sau những ứng dụng này là những thuật toán Machine Learning có tên gọi chung là Recommender Systems hoặc Recommendation Systems, tức Hệ thống gợi ý.
Recommendation Systems là một mảng khá rộng của Machine Learning và có tuổi đời ít hơn so với Classification vì internet mới chỉ thực sự bùng nổ khoảng 10-15 năm đổ lại đây. Có hai thực thể chính trong Recommendation Systems là users và items. Users là người dùng. Items là sản phẩm, ví dụ như các bộ phim, bài hát, cuốn sách, clip, hoặc cũng có thể là các users khác trong bài toán gợi ý kết bạn. Mục đích chính của các Recommender Systems là dự đoán mức độ quan tâm của một user tới một item nào đó, qua đó có chiến lược recommend phù hợp.
1.2. Hai chiến thuật hay dùng trong hệ gợi ý
Chiến thuật Lọc nội dung (Content Filtering): Cách tiếp cận lọc nội dung tạo ra một hồ sơ cho mỗi người dùng hoặc sản phẩm để mô tả bản chất của nó. Ví dụ, một hồ sơ phim có thể bao gồm các thuộc tính liên quan đến thể loại của nó, các diễn viên tham gia, sự phổ biến của phòng vé, v.v. Hồ sơ người dùng có thể bao gồm thông tin nhân khẩu học hoặc câu trả lời được cung cấp trên bảng câu hỏi phù hợp. Các hồ sơ cho phép các chương trình liên kết người dùng với các sản phẩm phù hợp. Tất nhiên, chiến lược dựa trên nội dung yêu cầu thu thập thông tin bên ngoài có thể không có sẵn hoặc khó thu thập. Điển hình của chiến thuật này là Dự án Music Genome, ứng dụng ở Pandora.com. Các bài hát được phân tích thuộc tính (định nghĩa là genre) sẽ cho ra không chỉ đặc điểm bài toán mà còn là gu âm nhạc của người nghe.
Chiến thuật Lọc cộng tác (Collaborative Filtering): Thuật ngữ này được định nghĩa bởi Tapestry, hệ gợi ý đầu tiên trên thế giới. Đây là chiến thuật thay thế cho Lọc nội dung. Cách này chỉ dựa trên hành vi của người dùng trước đây. Ví dụ: Giao dịch trước đó hoặc xếp hạng sản phẩm, mà không yêu cầu tạo hồ sơ rõ ràng. Chiến thuật này phân tích mối liên quan giữa người dùng và các thuộc tính của sản phẩm để định nghĩa quan hệ giữa người dùng - sản phẩm.
Ưu điểm của Lọc cộng tác so với Lọc nội dung là không bị giới hạn miền, dẫn đến có thể giải quyết các khía cạnh dữ liệu thường khó nắm bắt và khó khăn để đưa vào khi sử dụng Lọc nội dung. Tuy nhiên không hiệu quả khi phải xử lý với dữ liệu mới được thêm vào, điều mà Lọc nội dung lại hiệu quả hơn.
1.3 Hai lĩnh vực trong Lọc cộng tác
Hai lĩnh vực chính của lọc cộng tác là các phương pháp lân cận và các mô hình yếu tố tiềm ẩn.
Phương pháp vùng lân cận tập trung vào việc tính toán các mối quan hệ giữa các items hoặc giữa users. Cách tiếp cận theo định hướng đánh giá sản phẩm dựa trên cách người dùng đánh giá của các “sản phẩm hàng xóm”. Sản phẩm hàng xóm là các sản phẩm khác có xu hướng nhận được đánh giá tương tự khi được đánh giá bởi cùng một người dùng. Ví dụ: Hãy xem phim Giải cứu Binh nhì Ryan. Những người phim “hàng xóm” của nó có thể bao gồm các bộ phim chiến tranh, phim của Spielberg và phim có Tom Hanks. Để dự đoán xếp hạng của một người dùng cụ thể cho Giải cứu Binh nhì Ryan, ta sẽ tìm kiếm những người hàng xóm gần nhất của phim mà người dùng này thực sự đã xếp hạng. Như Hình 1 minh họa, cách tiếp cận hướng người dùng xác định những người dùng cùng sở thích có thể bổ sung cho các đánh giá của nhau.
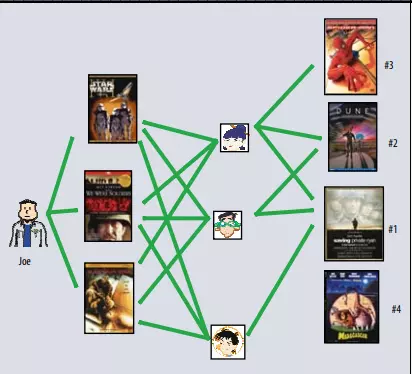
Hình 1: Phương pháp tiếp cận vùng lân cận: Joe thích 3 bộ phim như ở trong ảnh. Hệ thống sẽ tìm ra 3 người dùng tương tự cũng thích 3 bộ phim ấy và những bộ phim khác họ thích. Cả 3 người đều thích Giải cứu Binh nhì Ryan, hệ thống sẽ gợi ý đầu tiên phim ấy cho Joe. 2 người thích Dune nên tiếp theo Joe sẽ được gợi ý Dune, và cứ như vậy...
Mô hình yếu tố tiềm ẩn là một phương pháp thay thế, đưa ra các đánh giá bằng cách mô tả cả sản phẩm lẫn người dùng theo 20 đến 100 yếu tố được suy ra từ các mẫu đánh giá khác. Trong một khía cạnh nào đó, các yếu tố như vậy bao gồm một sự mô hình hóa bằng máy tính đối với các gen bài hát đã được đề cập ở trên. Đối với phim ảnh, các yếu tố được phát hiện có thể đo lường các yếu tố rõ ràng như thiên về hài kịch so với bi kịch; phim hành động hay định hướng cho trẻ em; các yếu tố ít được xác định rõ hơn như nhân vật có chiều sâu hay nhân vật độc đáo; hoặc các yếu tố khó giải thích được khác. Đối với người dùng, mỗi yếu tố quyết định mức độ người dùng thích phim như nào để cho điểm số cao trên hệ số phim tương ứng.
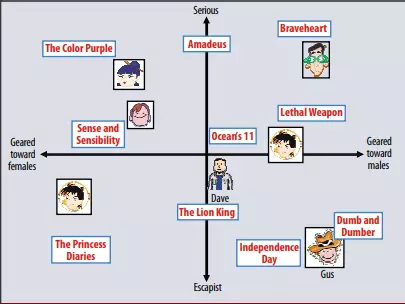
Hình 2: Minh họa của Mô hình tiềm năng: 1 đồ thị đã mô hình hóa cả người dùng lẫn phim bằng 2 yếu tố: hướng nam - hướng nữ và giả tưởng - thực tế
Hình 2 minh họa ý tưởng này cho một ví dụ đơn giản trong hai chiều. Hãy xem xét hai khía cạnh giả định được mô tả là hướng nữ giới - hướng nam giới và thực tế - giả tưởng. Hình này cho thấy một số bộ phim nổi tiếng và một số người dùng minh họa có thể thuộc vào hai chiều này. Đối với mô hình này, xếp hạng được dự đoán của người dùng cho một bộ phim, liên quan đến xếp hạng trung bình của phim, sẽ bằng sản phẩm dấu chấm của vị trí của phim và của người dùng trên biểu đồ. Ví dụ, Gus thích Dumb và Dumber, ghét The Color Purple, và để đánh giá Braveheart về mức trung bình. Lưu ý rằng một số phim như: Ocean 11 và người dùng như: Dave sẽ được mô tả là khá trung lập trên hai chiều này.
2. Phương pháp Matrix factorization
Một trong những ứng dụng thành công nhất của mô hình yếu tố tiềm ẩn là dựa trên Phân tích ma trận thành nhân tử (Matrix Factorization, Matrix Decomposition). Kết quả cuộc thi Netflix Prize đã chứng minh, các mô hình phân tích ma trận thành nhân tử vượt trội so với các kỹ thuật hàng xóm gần nhất cổ điển để đưa ra các khuyến nghị sản phẩm, cho phép kết hợp các thông tin bổ sung như phản hồi ngầm, hiệu ứng thời gian và mức độ tin cậy.
Trong dạng cơ bản của nó, phương pháp phân tích ma trận thành nhân tử kí tự hóa các mặt hàng và người dùng thành các vector yếu tố được suy ra từ các mẫu xếp hạng mặt hàng. Nếu các yếu tố của người dùng và mặt hàng có độ tương tự cao, hệ thống sẽ tạo nên một gợi ý. Ví dụ : Mỗi item có thể mang tính chất ẩn nào đó tương ứng với các hệ số của nó trong vector x, tương ứng user cũng sẽ có tính chất ẩn tương ứng với vector w. Chúng ta không nhất thiết phải đặt tên cho các tính chất ẩn này. Hệ số càng cao tương ứng với việc item hoặc user càng thể hiện rõ tính chất ẩn đó và ngược lại. Tính tương tự giữa item và user sẽ được thể hiện qua giá trị biểu thức xw. Giá trị này càng cao thì độ tương tự giữa item và user càng cao, nghĩa là item này càng có khả năng mang thuộc tính mà người dùng thích, vì vậy nên gợi ý item này cho user.
Phương pháp này trở nên phổ biến trong những năm gần đây vì nó có sự kết hợp tốt giữa gợi ý chính xác và ước lượng tỉ lệ. Thêm vào đó, phương pháp này cũng có thể ứng dụng linh hoạt để mô hình hóa các tình huống trong thực tế.
Các hệ thống gợi ý thường phải dựa vào nhiều kiểu dữ liệu đầu vào khác nhau. Những dữ liệu này thường được đặt trong một ma trận 2 chiều, một chiều tái hiện người dùng và một chiều tái hiện những mặt hàng mà người dùng đó quan tâm. Những dữ liệu thuận tiện nhất là những phản hồi rõ ràng có chất lượng cao, thường là đánh giá của người dùng về sản phẩm. Netflix có hệ thống đánh giá sao (rating-star) dành cho phim, các mạng xã hội như Facebook, Twitter hay thậm chí Youtube thường có nút like (hoặc cả dislike) để thể hiện sự đánh giá của người dùng về từng bài post, video. Chúng ta gọi chung những phản hồi rõ ràng từ người dùng là sự đánh giá của người dùng.
Thông thường, ma trận tạo nên từ các phản hồi rõ ràng khá thưa thớt (không kín), bởi người dùng thường chỉ đánh giá một bộ phận nhỏ các mặt hàng mà họ sử dụng, xem qua. Người dùng thường chỉ đánh giá hay để lại phản hồi khi mặt hàng đó tạo nên ấn tượng rất tốt hoặc rất xấu đối với họ, mà thường là khi họ gặp vấn đề. Theo thống kê, tỉ lệ phản hồi từ khách hàng trên Amazon vào khoảng 10-20%, và khoảng 10% đối với các hệ thống thông thường.
Một thế mạnh của phương pháp phân tích ma trận thành nhân tử là nó cho phép chúng ta kết hợp những thông tin bổ sung. Khi những phản hồi rõ ràng không có sẵn hoặc không đầy đủ, hệ thống gợi ý cho phép ta suy đoán sở thích người dùng dựa trên những phản hồi ẩn bằng cách theo dõi lịch sử mua hàng, lịch sử duyệt web, những thứ họ thường tìm kiếm hoặc thậm chí cả di chuyển của con trỏ chuột. Những phản hồi ngầm này thường gián tiếp thể hiện ý kiến, quan điểm của người dùng về các loại mặt hàng. Do các phản hồi ngầm biểu thị cả sự hiện diện lẫn không hiện diện của một sự kiện nào đó, nên ma trận tạo nên từ phản hồi ngầm thường khá kín.
3. Mô hình Matrix factorization cơ bản
Mô hình phân tích ma trận thành nhân tử (Matrix factorization) ánh xạ cả người dùng lẫn sản phẩm đến không gian yếu tố tiềm ẩn chung của không gian f, nhờ vậy mối quan hệ giữa người dùng - sản phẩm được mô hình hóa thành một phần tử thuộc không gian đấy. Thông qua đó, mỗi item i được liên kết với 1 vector . Và mỗi user được liên kết với 1 vector . Với mỗi item i xác định, phần tử đánh giá những yếu tố mà item đó sở hữu, dương hay âm. Đối với mỗi user u, phần tử đánh giá những mối quan tâm của người dùng, dương hay âm. Tích giữa và thể hiện mối quan hệ giữa người dùng u và sản phẩm i, thể hiện đánh giá tổng thể của người dùng về item cụ thể. Điều này sẽ xấp xỉ rating của người dùng dành cho sản phẩm, , dẫn đến công thức:
Thách thức của thuật toán này chính là việc learning, tức là tính toán ánh xạ giữa item và người dùng để tạo thành vector , . Sau khi hệ gợi ý hoàn thành tính toán xong việc ánh xạ, chúng ta có thể dễ dàng ước lượng được đánh giá của người dùng bằng công thức trên.
Mô hình này gần giống với mô hình SVD (Singular Value Decomposition). Việc áp dụng SVD trong các chiến thuật lọc cộng tác đòi hỏi phân tích ma trận rating của user-item. Điều này thường làm tăng độ khó khăn bởi lượng lớn các giá trị bỏ trống do các ma trận rating của user-item thường khá thưa thớt. Các mô hình SVD thông thường thường không xác định khi tri thức về ma trận không đầy đủ. Hơn nữa, việc chỉ ghi lại những các mục đã biết, trong khi số lượng các mục này tương đối ít, sẽ chỉ càng gây thêm vấn đề overfitting.
Hệ thống nêu trên đòi hỏi vào việc gán giá trị để lấp đầy những giá trị còn thiếu và làm cho ma trận trở nên kín hơn. Tuy nhiên, việc gán giá trị có thể trở nên khá tốn kém khi số lượng dữ liệu gia tăng. Thêm vào đó, việc gán giá trị sai có thể khiến việc xem xét dữ liệu trở nên không đúng. Vì thế, những hệ thống gợi ý gần đây mô hình hóa trực tiếp từ quan sát rating, bỏ qua sự overfitting trong mô hình chuẩn hóa. Để học các vector yếu tố ( và ), hệ thống giảm thiểu tối đa sự sai sót do chuẩn hóa trên tập các rating đã biết
Trong đó, K là tập hợp các cặp (u,i) mà của chúng đã được xác định.
Hệ thống sẽ học mô hình bằng cách cố gắng phù hợp chúng với những rating đã quan sát được chúng trước đó. Tuy nhiên, mục tiêu ở đây là tổng quát hóa những rating trước đây theo một cách nào đó để có thể dự đoán được các rating sau này, hay các rating chưa biết.
4. Các thuật toán dùng khi học
Như mọi mô hình học khác việc tối thiểu hàm mất mát luôn là việc cần thiết để tăng độ chính xác cho mô hình. Để tối ưu hàm mất mát bên trên có 2 phương pháp hay dùng là Stochastic gradient descent và Alternating least squares.
4.1. Phương pháp Stochastic gradient descent (SGD):
Đầu tiên Gradient descent (GD) là gì? Quay lại hồi cấp 3 khi muốn tìm điểm cực tiểu toàn cục của 1 hàm số ta sẽ tìm đạo hàm và giải phương trình bằng 0, sau đó thay các nghiệm tìm được và so sánh các cực tiểu cục bộ. Nhưng đối với hàm mất mát với đạo hàm phức tạp thì ngay cả việc tìm nghiệm bằng 0 cũng không hề dễ dàng. Và GD là phương pháp giúp chúng ta tìm được điểm tiệm cận cực tiểu đó, bằng cách chọn 1 điểm bất kỳ, sau đó lặp lại 1 công thức giúp tiến dần điểm đó đến khi đạo hàm gần bằng 0 tức điểm cực tiểu. Chính vì vậy GD được gọi là giảm đạo hàm hay phương pháp xuống dốc. Cho là điểm hiện tại, thì điểm tiếp theo sẽ được tính bằng lần đạo hàm tại với (đọc là eta) là hệ số thể hiện tốc độ di chuyển của điểm
Để giải thích công thức này thì hơi dài dòng nên có thể hiểu đơn giản là: sau mỗi lần lặp điểm hiện tại sẽ giảm (hoặc tăng nếu ở bên trái cực tiểu) 1 lượng tùy vào tốc độ eta và đạo hàm đến khi giá trị của đạo hàm gần bằng 0. Công thức đối với hàm vecto như hàm mất mát cũng sẽ tương tự:
Với là vecto hay điểm dữ liệu là đạo hàm tại vecto hiện tại ( đọc là nabla)
SGD - giảm đạo hàm ngẫu nhiên Là một phương pháp nhằm cải thiện tốc độ tìm điểm cực tiểu so với khi dùng GD. Khi dùng GD trong mỗi vòng lặp ta chỉ tính đạo hàm tại 1 điểm hiện tại rồi cập nhật điểm này dựa trên đạo hàm đó, còn SGD thì tính đạo hàm tại toàn bộ các điểm dữ liệu sau đó giảm theo đạo hàm của 1 điểm ngẫu nhiên. Và sự ngẫu nhiên này sẽ cho cơ hội nhảy 1 bước xa khi tính toán giúp tốc độ tiến đến điểm cần tìm nhanh hơn (do tốn ít vòng lặp hơn GD). Vì vậy đối với bài toán có lượng dữ liệu lớn như bài toán này thì SGD là phương pháp rất hiệu quả. Khi đó công thức cập nhật sẽ là:
Đặt . Khi áp dụng vào hàm mất mát (2) bên trên ta sẽ có công thức cập nhật của từng biến:
Ta chọn 2 điểm bắt đầu cho 2 biến số cần tìm rồi giảm dần theo đạo hàm để có được điểm cực tiểu (điểm khiến hàm mất mát đạt giá trị nhỏ nhất) chính là điểm cần tìm.
4.2. Phương pháp Alternating least squares (ALS):
Tuy nhiên trong một vài trường hợp sự dụng phương pháp ALS lại có hiệu quả hơn.
ALS hay còn gọi là phương pháp bình phương tối thiểu thay phiên nhau. Gọi là thay phiên nhau bởi hàm mất mát trên có 2 biến khiến hàm không lồi (khó để tìm cực tiểu) chính vì vậy ta thay phiên cố định 1 biến rồi tối ưu hàm theo biến còn lại. Khi cố định 1 biến hàm trở thành hàm bậc 2 và có thể giải bằng phương pháp bình phương tối thiểu. Việc cố định 1 biến rồi tính toán lại biến còn lại được thực hiện lần lượt cho đến khi các điểm hội tụ lại tại điểm cực tiểu.
Tựu chung thì SGD dễ sử dụng và tốc độ nhanh hơn ALS tuy nhiên có 2 trường hợp mà ALS lại được ưu tiên hơn.
Trường hợp 1 là hệ thống có khả năng chạy các tiến trình 1 cách song song.
Ta thấy khi cố định 1 trong 2 cột công thức hàm cần tối ưu sẽ trở thành
Từ đó bài toán có thể chuyển thành việc tối ưu từng cột 1 của q (hoặc p) cho nên việc sử dụng trong hệ thống song song sẽ dễ dàng hơn. Trong khi nếu SGD sử dụng trong hệ thống song song sẽ dễ gặp vấn đề bị ghi đè nếu kết quả cập nhật có liên quan đến 2 phép toán diễn ra song song.
Trường hợp thứ 2 là khi sử dụng với hệ thống tập trung vào các dữ liêu ẩn. Bởi không phải lúc nào tập huấn luyện cũng thưa thớt, nên việc lặp lại qua tất cả các điểm dữ liệu theo cách của SGD lại trở lên không thực tiễn. Trong trường hợp này sử dụng ALS cũng có hiệu quả cao hơn.
5. Thêm Bias (độ lệch hay thiên vị)
Một lợi thế của hướng tiếp cận Matrix Factorization cho Collaborative Filtering là khả năng linh hoạt của nó khi có thêm các điều kiện ràng buộc khác, các điều kiện này có thể liên quan đến quá trình xử lý dữ liệu hoặc đến từng ứng dụng cụ thể. Như trong công thức (1) giá trị ratings cuối cùng chỉ chỉ ra được mối liên hệ giữa users và items, nhưng trong thực tế các ratings đều có những thiên lệch về users hoặc/và items. Có user dễ và khó tính, cũng có những item được rated cao hơn những items khác chỉ vì user thấy các users khác đã đánh giá item đó cao rồi. Vấn đề thiên lệch có thể được giải quyết bằng các biến gọi là biases, phụ thuộc vào mỗi user và item.
Như các bạn trước đó đã trình bày về vấn đề thiên lệch bằng cách trừ đi trung bình ratings, thì MF cũng có cách giải quyết tương tự nhưng khác 1 chút là chỉnh sửa rating bằng các bias Khi đó hàm dự đoán xếp hạng của người dùng u cho sản phẩm i được biểu diễn bởi công thức sau:
Với giá trị là giá trị trung bình toàn toàn cục, là giá trị xếp hạng trung bình của tất cả người dùng trên tất cả sản phẩm với tập dữ liệu huấn luyện, giá trị là độ lệch người dùng (là giá trị lệch trung bình của các người dùng so với giá trị trung bình toàn cục), giá trị là độ lệch của sản phẩm (là giá trị lệch trung bình của các sản phẩm so với giá trị trung bình toàn cục)
Lấy ví dụ như tính lại ratings cho 1 người dùng A nào đó đối với phim Titanic. Tổng trung bình ratings toàn bộ các phim là 3.7 điểm nhưng Titanic lại được đánh gía cao hơn trung bình 0.5 điểm, còn A là người dùng khó tính luôn đánh giá cho phim trung bình là 0.3 điểm so với mức trung bình, nên ratings của A đối với phim Titanic sẽ là (3.7 + 0.5 - 0.3) = 3.9 điểm.
Khi thay công thức (1) mới bên trên vào hàm mất mát ta được:
và từ đó có thể tối ưu sử dụng các thuật toán như bình thường.
Do Biases có thêm nhiều thông tin hơn nên trong thực tế nó sẽ chính xác hơn.
6. Các vấn đề còn lại
6.1. Vấn đề bổ sung thông tin
Thông thường một hệ thống phải đối phó với vấn đề cold-start (user mới vừa bắt đầu tương tác với hệ thống), trong đó nhiều người dùng cung cấp rất ít xếp hạng, khiến việc đạt được kết luận chung về sở thích của họ trở nên khó khăn. Một cách để giải quyết vấn đề này là kết hợp các nguồn thông tin bổ sung về người dùng. Recommender systems có thể sử dụng phản hồi ngầm để có được thông tin chi tiết về các tùy chọn của người dùng.
Thật vậy, họ có thể thu thập thông tin hành vi bất kể người dùng có sẵn sàng đánh giá hay không. Một nhà bán lẻ có thể sử dụng hành vi mua hàng của khách hàng hoặc lịch sử duyệt web để tìm hiểu xu hướng của họ, ngoài rating mà user có thể cung cấp.
Để đơn giản, hãy xem xét một trường hợp với một phản hồi ngầm với kiểu boolean. biểu thị tập hợp các mục mà người dùng u thể hiện một tùy chọn ẩn. Bằng cách này, hệ thống sẽ nhận diện người dùng thông qua các mục mà họ thích. Ở đây cần có một tập các hệ số của item, trong đó item i được liên kết với . Theo đó, user đã hiển thị sự yêu thích cho các item thuộc được đặc trưng bởi vector:
Chuẩn hóa kết quả:
Có một nguồn thông tin khác là các thuộc tính user đã biết, ví dụ: nhân khẩu học. Một lần nữa, để đơn giản, hãy xem xét các thuộc tính dạng boolean trong đó user u tương ứng với tập hợp các thuộc tính , có thể mô tả giới tính, tuổi, zip code, thu nhập, v.v. Một vectơ yếu tố riêng biệt tương ứng với từng thuộc tính để mô tả user thông qua tập hợp các thuộc tính liên quan đến người dùng:
Mô hình Matrix factorization có thể tích hợp các nguồn tín hiệu, với việc diễn tả user đã được tăng cường
Trong khi các ví dụ trước liên quan đến việc diễn tả user đã được tăng cường - việc thiếu thốn dữ liệu là phổ biến - item có thể được nghiên cứu một cách tương tự khi cần thiết.
6.2. Vấn đề thay đổi theo thời gian (mô hình động)
Cho đến nay, các mô hình đã được diễn tả trước đó đều là mô hình tĩnh. Trong thực tế, nhận thức và mức độ phổ biến của sản phẩm liên tục thay đổi khi các sản phẩm mới xuất hiện. Tương tự, khách hàng cũng có nhận thức tăng lên, dẫn đến thị hiếu của họ thay đổi. Do đó, hệ thống cần tính đến các thành phần tạm thời phản ánh tính "động", thay đổi theo thời gian của các tương tác user-item.
Phương pháp Matrix factorization sử dụng chính nó để mô hình hóa các thành phần tạm thời, có thể cải thiện đáng kể độ chính xác. Phân rã ratings thành các điều kiện riêng biệt cho phép hệ thống xử lý các thành phần khác nhau một cách riêng biệt. Cụ thể, các điều kiện sau thay đổi theo thời gian: item biases (item thay đổi tính phổ biến theo thời gian), user biases (user dễ tính/khó tính), ; và sở thích của người dùng, .
Thành phần thứ nhất giải quyết một thực tế là mức độ phổ biến của vật phẩm có thể thay đổi theo thời gian. Ví dụ, các bộ phim có thể trở nên phổ biến và được gây nên bởi các sự kiện bên ngoài như sự xuất hiện của diễn viên trong một bộ phim mới. Do đó, các mô hình này coi item bias là một hàm theo thời gian.
Thành phần thứ hai phản ánh mức độ dễ tính/khó tính của user. Ví dụ: một người dùng có xu hướng xếp hạng phim trung bình là 4 sao có thể đánh giá một phim tồi là 3 sao. Điều này có thể phản ánh một số yếu tố bao gồm độ khuynh hướng tự nhiên trong đánh giá của người dùng, hoặc thực tế là đánh giá của user chịu ảnh hưởng từ các đánh giá gần đây khác, hoặc thực tế là danh tính của user cũng có thể thay đổi theo thời gian. Do đó, trong các mô hình này, tham số là một hàm theo thời gian.
Đặc tính dễ thay đổi của con người cũng ảnh hưởng đến sở thích của người dùng và do đó sự tương tác giữa người dùng và vật phẩm. Người dùng thay đổi sở thích của họ theo thời gian.
Ví dụ, một người hâm mộ thể loại phim kinh dị tâm lý có thể trở thành fan của phim truyền hình tội phạm một năm sau đó. Tương tự, con người thay đổi nhận thức của họ về các diễn viên và đạo diễn nhất định. Mô hình đánh giá hiệu ứng này bằng cách lấy các yếu tố người dùng (vector ) làm hàm của thời gian. Mặt khác, nó chỉ định các thuộc tính item tĩnh , bởi vì khác với con người là "động", item là "tĩnh".
Việc tham số hóa các tham số thay đổi theo thời gian dẫn đến việc thay thế (3) bằng luật dự đoán động cho một đánh giá tại thời điểm t:
6.3. Vấn đề thêm giá trị mức độ tin cậy
Trong một số thiết lập, không phải tất cả các đánh giá đều phải có cùng hệ số hoặc độ tin cậy. Ví dụ: một đoạn quảng cáo lớn có thể ảnh hưởng đến đánh giá cho một số mặt hàng trong một khoảng thời gian nhất định, không phản ánh đúng các đặc tính dài hạn của sản phẩm. Tương tự, một hệ thống có thể phải đối mặt với vấn đề user đánh giá sai lệch một số item nhất định với mục đích nào đó. Một ví dụ khác là các hệ thống được xây dựng xung quanh phản hồi ngầm. Trong các hệ thống như vậy, diễn giải hành vi người dùng, mức độ ưu tiên chính xác của người dùng rất khó định lượng. Do đó, hệ thống này hoạt động với kiểu nhị phân dưới dạng thô, "thích sản phẩm" hoặc "không thích sản phẩm". Trong những trường hợp này, sẽ có giá trị hơn nếu thêm độ tin cậy với độ ưu tiên đã ước tính. Độ tin cậy có thể phát triển từ các giá trị đã có mô tả tần suất hành vi, ví dụ, thời gian người dùng xem một chương trình nhất định hoặc tần suất người dùng mua một mặt hàng nhất định. Những giá trị số này cho thấy độ tin cậy của quan sát. Nhiều yếu tố không liên quan đến sở thích của người dùng có thể gây ra sự kiện chỉ diễn ra một lần. Ví dụ user có thể xem một chương trình TV chỉ vì cô ấy ở trên kênh của chương trình đã xem trước đó, một user khác có thể mua một mặt hàng làm quà tặng cho người khác, mặc dù không thích mặt hàng đó cho mình. Tuy nhiên, một sự kiện định kỳ nhiều khả năng phản ánh chính xác quan điểm của user.
Mô hình nhân tố ma trận có thể dễ dàng chấp nhận các mức độ tin cậy khác nhau, điều này cho phép nó giảm hệ số cho các quan sát có ít ý nghĩa hơn. Nếu độ tin cậy trong việc quan sát rui được ký hiệu là , thì mô hình tăng cường hàm chi phí (4) để tính độ tin cậy sẽ như sau:
7. Demo
Demo được thực hiện trên tập dữ liệu Movie lens 1M với 1 triệu ratings từ 6000 người dùng trên 4000 bộ phim. https://grouplens.org/datasets/movielens/1m/
8. Tổng kết
Phương pháp phân tích ma trận thành nhân tử đã trở thành phương pháp thống trị trong hệ thống các phương pháp lọc cộng tác. Việc tiếp xúc với bộ dữ liệu của Netfix Prize đã chứng tỏ phương pháp này đem lại khả năng chính xác vượt trội so với các phương pháp thuộc kĩ thuật hàng xóm cổ điển. Bên cạnh đó, phương thức này cũng cung cấp mô hình với độ yêu cầu bộ nhớ thấp, giúp hệ thống có thể học dễ dàng hơn. Điều càng làm phương pháp này trở nên thuận tiện là, nó cho phép chúng ta tích hợp nhiều khía cạnh quan trọng của dữ liệu, giúp cải thiện độ chính xác rất nhiều.
9. TÀI LIỆU THAM KHẢO
http://is.hust.edu.vn/~khoattq/lectures/KE-2018-9/Reading/R6-Matrix factorization techniques for recommender systems -Koren09.pdf, Yehuda Koren, Robert Bell and Chris Volinsky, 2009
- Matrix Factorization cơ bản: https://machinelearningcoban.com/2017/05/31/matrixfactorization/ Vũ Hữu Tiệp, 2017 Và các bài viết liên quan trên machinelearingcoban.com
- Hệ thống gợi ý: Kỹ thuật và ứng dụng: https://www.researchgate.net/publication/310059523_He_thong_goi_y_Ky_thuat_va_ung_dung Nhà xuất bản Đại học Cần Thơ, 2016
- Thuật toán ALS: https://stanford.edu/~rezab/classes/cme323/S15/notes/lec14.pdf Reza Zadeh, Databricks and Stanford, 2015
- CÁ NHÂN HÓA ỨNG DỤNG VÀ DỊCH VỤ DI ĐỘNG HƯỚNG NGỮ CẢNH NGƯỜI DÙNG http://data.uet.vnu.edu.vn/jspui/bitstream/123456789/892/2/BuiAnLoc_Tom tat luan van.pdf Bùi An Lộc, 2016
10. Credit
Đây là báo cáo môn Kỹ nghệ tri thức của nhóm sinh viên AS K59, gồm:
- Hoàng Quốc Việt
- Đào Bảo Quang
- Nguyễn Tuấn Anh
- Hoàng Đức Quân
All rights reserved
