Các phương pháp để RAG hoạt động khi lên production
Bài đăng này đã không được cập nhật trong 2 năm
Bài viết này dành cho những tâm hồn đồng điệu đang muốn build một con LLM lên production.
Ôn bài cũ - Một mô hình RAG cơ bản gồm những gì?
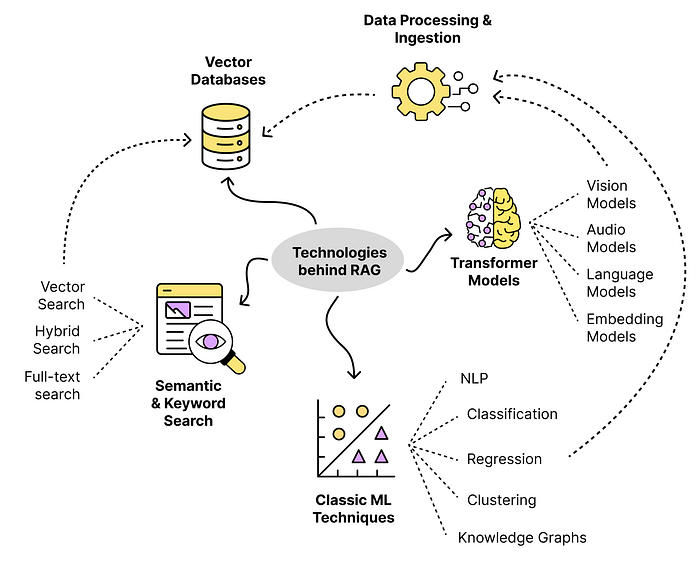
RAG không hề phức tạp, nó chỉ đơn giản là xây dựng một hệ thống xung quanh một con LLM và dùng đúng dữ liệu để con LLM trả lời dùng chính dữ liệu của bạn. Các kĩ thuật mà RAG sử dụng đến hầu hết đều đã xuất hiện rất lâu, như là xử lý dữ liệu chữ, semantic search, knowledge graphs, các mô hình ML cơ bản, vector database. Nhờ RAG mà câu trả lời của LLM có thể truy xuất thông tin từ nguồn dữ liệu bất kì với giới hạn kích thước duy nhất là chiếc ví của bạn.
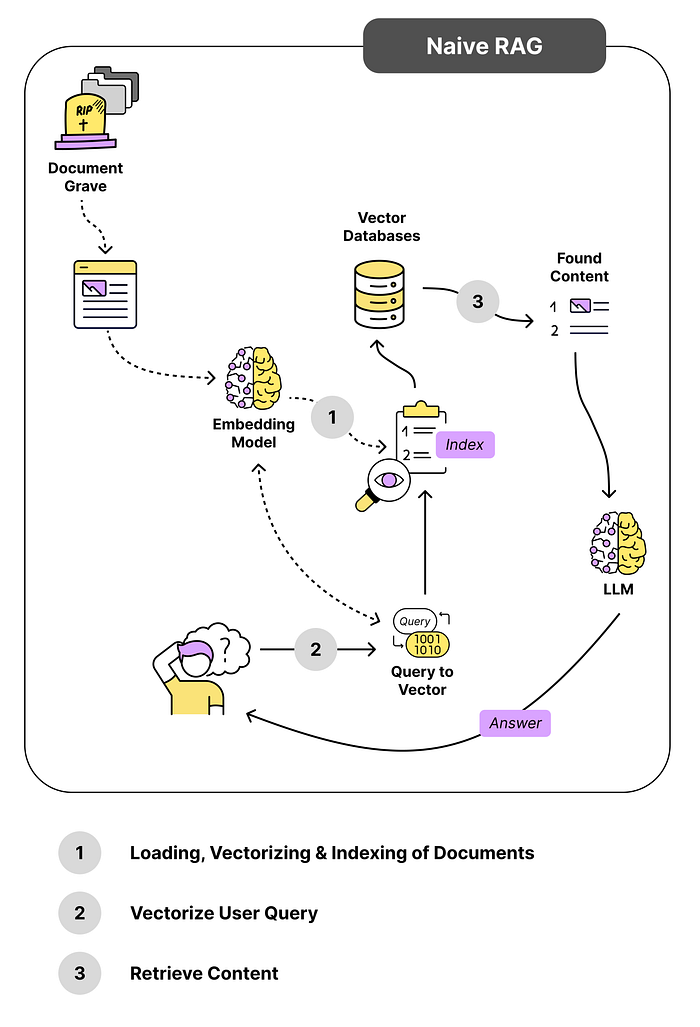
Hình bên trên là một mô hình RAG cơ bản. Khi user đặt câu hỏi, hệ thống sẽ truy xuất ở trong database, xem dữ liệu nào liên quan đến câu hỏi nhất thì lấy nó ra. Sau đó tất cả thông tin liên quan được tổng hợp để đưa cho LLM trả lời user.
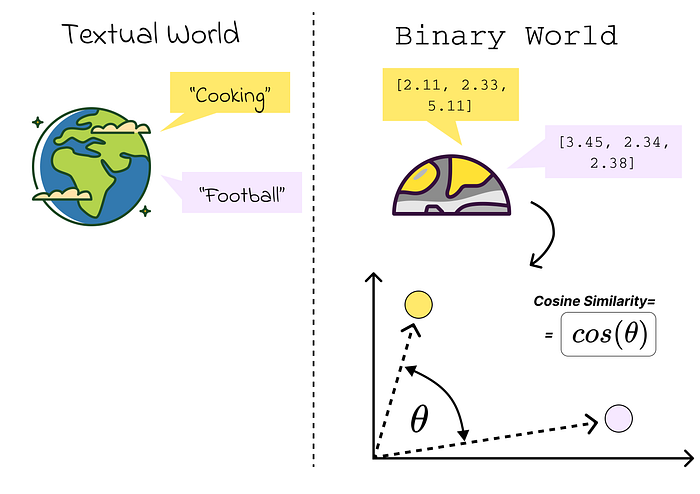
Cách thức để đo lường độ tương quan giữa hai thông tin khá đa dạng, mà phổ biến nhất là xét cosine similarity của embedding hai thông tin đó.
Sau khi có thông tin liên quan, chúng ta xây dựng một prompt bao gồm system prompt, câu hỏi của người dùng, và ngữ cảnh - thông tin đã được tìm thấy bên trên.

Tuy nhiên, trong khi làm thì một số vấn đề có thể xuất hiện như là:
- Vấn đề khi đo lường độ tương quan
- Chunk optimization: Thông tin lưu vào vector database thì phải bẻ nhỏ nó ra thành các chunk rồi mới dùng nó để đem ra so sánh (hoặc để nguyên cũng được nhưng nó nặng lắm không ai làm thế cả). Vậy bẻ nhỏ thông tin như thế nào là vừa đủ nhỏ để vừa đi vào thông tin chi tiết được cho từng mẩu thông tin, vừa lưu giữ được thông tin ngữ cảnh xung quanh nó?
- Theo dõi performance của model như thế nào? (LLMOps)
- Người dùng hỏi khó quá, phức tạp quá thì xử lý như thế nào?
Vậy thì để cải thiện RAG, chúng ta có thể ngó qua 17 cách sau, chia theo 5 giai đoạn chính của RAG:
- Pre-Retrieval: Giai đoạn biến dữ liệu thành các embedding để đưa vào vector store
- Retrieval: Tìm thông tin liên quan
- Post-Retrieval: Tìm được thông tin rồi thì xử lý một chút trước rồi đưa qua LLM chứ nhỉ
- Generation: Để LLM tự tung tự tác với thông tin mình đưa nó
- Evaluation
0. Thu thập/Xử lý dữ liệu thô
(1) Chuẩn bị dữ liệu tốt
 Dữ liệu tốt cần thỏa mãn ít nhất các yếu tố sau:
Dữ liệu tốt cần thỏa mãn ít nhất các yếu tố sau:
- Nội dung đa dạng, đầy đủ, có ngữ cảnh
- Không chứa thông tin không liên quan, lỗi, nhiễu
- Cân bằng - Số lượng dữ liệu mỗi loại cân bằng
- Không chứa ngôn từ kích động, gây phản cảm, chứa thông tin bảo mật
Dữ liệu có nhãn thì hiệu quả của mô hình sẽ dễ kiểm soát và cải thiện hơn. Còn nếu không có nhãn thì vẫn có cách để mô hình học, nên đừng lo quá.
1. Indexing / Chunking — Chunk Optimization
(2) Tối ưu chunk
Fixed-size (in characters) Overlapping Sliding Window
Phương pháp này liên quan đến việc chia văn bản thành các đoạn cố định dựa trên số ký tự. Sự đơn giản trong triển khai và việc bao gồm các đoạn chồng chéo nhằm ngăn chặn việc cắt câu hoặc ý nghĩ. Tuy nhiên, các hạn chế bao gồm việc kiểm soát kích thước ngữ cảnh không chính xác, nguy cơ cắt từ hoặc câu, và thiếu sự xem xét về ngữ nghĩa. Phù hợp cho phân tích khám phá nhưng không được khuyến nghị cho các tác vụ yêu cầu hiểu sâu về ngữ nghĩa.
Ví dụ sử dụng LangChain:
text = "..." # your text
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
chunk_size = 256,
chunk_overlap = 20
)
docs = text_splitter.create_documents([text])
Recursive Structure Aware Splitting Phương pháp lai kết hợp giữa cửa sổ trượt kích thước cố định và phân chia nhận thức cấu trúc. Nó cố gắng cân bằng kích thước đoạn cố định với ranh giới ngôn ngữ, cung cấp kiểm soát ngữ cảnh chính xác. Độ phức tạp trong triển khai cao hơn, với nguy cơ kích thước đoạn biến đổi. Hiệu quả cho các tác vụ yêu cầu độ chi tiết và tính toàn vẹn ngữ nghĩa nhưng không được khuyến nghị cho các tác vụ nhanh hoặc các chia nhỏ cấu trúc không rõ ràng.
Ví dụ sử dụng LangChain:
text = "..." # your text
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 256,
chunk_overlap = 20,
separators = ["\n
Structure Aware Splitting (by Sentence, Paragraph)
Phương pháp này xem xét cấu trúc tự nhiên của văn bản, phân chia nó dựa trên câu, đoạn văn, phần hoặc chương. Tôn trọng ranh giới ngôn ngữ bảo vệ tính toàn vẹn ngữ nghĩa, nhưng gặp khó khăn khi cấu trúc phức tạp khác nhau. Hiệu quả cho các tác vụ yêu cầu ngữ cảnh và ngữ nghĩa, nhưng không phù hợp với các văn bản thiếu các chia nhỏ cấu trúc rõ ràng.
Ví dụ:
text = "..." # your text
docs = text.split(".")
Content-Aware Splitting (Markdown, LaTeX, HTML)
Phương pháp này tập trung vào loại nội dung và cấu trúc, đặc biệt trong các tài liệu có cấu trúc như Markdown, LaTeX hoặc HTML. Nó đảm bảo các loại nội dung không bị trộn lẫn trong các đoạn, giữ nguyên tính toàn vẹn. Thách thức bao gồm việc hiểu cú pháp cụ thể và không phù hợp với các tài liệu không có cấu trúc. Hữu ích cho các tài liệu có cấu trúc nhưng không được khuyến nghị cho nội dung không có cấu trúc.
Ví dụ cho văn bản Markdown sử dụng LangChain:
from langchain.text_splitter import MarkdownTextSplitter
markdown_text = "..."
markdown_splitter = MarkdownTextSplitter(chunk_size=100, chunk_overlap=0)
docs = markdown_splitter.create_documents([markdown_text])
Ví dụ cho văn bản LaTeX sử dụng LangChain:
from langchain.text_splitter import LatexTextSplitter
latex_text = "..."
latex_splitter = LatexTextSplitter(chunk_size=100, chunk_overlap=0)
docs = latex_splitter.create_documents([latex_text])
NLP Chunking: Tracking Topic Changes
Một phương pháp tinh vi dựa trên hiểu biết ngữ nghĩa, phân chia văn bản thành các đoạn bằng cách phát hiện các thay đổi quan trọng về chủ đề. Đảm bảo tính nhất quán ngữ nghĩa nhưng yêu cầu các kỹ thuật NLP nâng cao. Hiệu quả cho các tác vụ yêu cầu ngữ cảnh ngữ nghĩa và tính liên tục của chủ đề nhưng không phù hợp cho các nhiệm vụ có sự trùng lặp chủ đề cao hoặc chia nhỏ đơn giản.
Ví dụ sử dụng bộ công cụ NLTK từ LangChain:
text = "..." # your text
from langchain.text_splitter import NLTKTextSplitter
text_splitter = NLTKTextSplitter()
docs = text_splitter.split_text(text)
(3) Cải thiện chất lượng dữ liệu - Từ viết tắt, thuật ngữ chuyên môn, link
Để mô hình nhận diện được các từ viết tắt tốt hơn, chúng ta có thể tạo một bảng thuật ngữ để xử lý dữ liệu trước khi đưa vào model, hoặc nếu máy đủ khỏe có thể đưa bảng thuật ngữ vào LLM cho nó tự xử lý
(4) Thêm metadata
Bạn có thể thêm metadata vào cho các vector trong database để thực hiện lọc dễ dàng hơn. Giả sử như khách hàng của bạn ở châu Á, thì thay vì tìm trong toàn bộ database bạn có thể tìm trong database châu Á trước cho dễ.
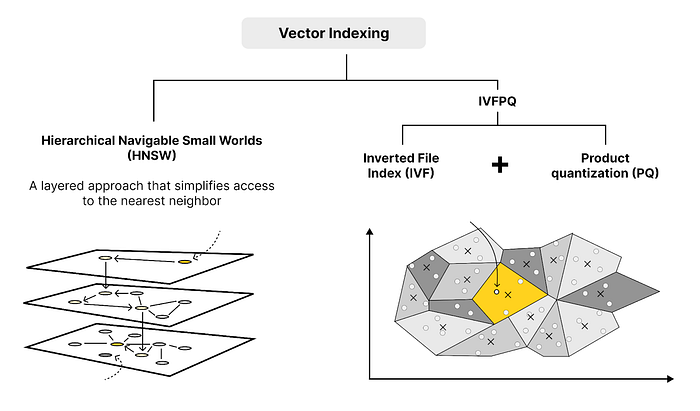
(5) Lựa chọn cơ chế indexing phù hợp
Mình thì tin rằng nếu model tạo embedding đủ tốt rồi thì cơ chế tìm kiếm thế nào cũng được, chỉ cần đủ nhanh và phương án đủ tốt là được. Cơ bản nhất thì chúng ta dùng KNN, nếu như có đủ phần cứng và dữ liệu ít. Còn nếu như dữ liệu vài triệu dòng thì tiền đâu cho vừa. Nên thường thế giới họ dùng các phương pháp tìm lân cận xấp xỉ (ANN) đến từ các framework như FAISS của Mark râu, NMSLIB, ANNOY của Spotify hay qrant mà OpenAI đang dùng. Về cơ bản, các framework này sẽ phân cụm trước/phân nhánh trước bằng các cơ chế khác nhau, rồi sau đó chỉ tìm các điểm dữ liệu trong cùng một (vài) cụm/nhánh gần nhất. Nếu có thời gian thì các bạn có thể thử nghiệm với các cơ chế indexing khác nhau xem có gì khác biệt không.
(6) Sử dụng mô hình tạo embedding phù hợp
Thật ra mình nghĩ dùng BM25 là một baseline không tệ để tìm kiếm các tài liệu liên quan đến query của người dùng. Trong trường hợp dữ liệu ít và các đặc trưng giữa các câu từ mình đánh giá là đủ khác nhau thì chỉ cần một mô hình đơn giản, và thế là có thể skip luôn phần này.
Sau khi sử dụng BM25 xong mà thấy kết quả chưa đủ tốt hay tốc độ infer chậm quá thì các bạn có thể dùng đến phương pháp tạo vector store từ các dữ liệu của mình và thực hiện retrieve thông tin trong đó. Tuy nhiên, phương pháp này đòi hỏi mô hình tạo embedding phải phù hợp, tức là có khả năng đưa các nội dung khác nhau ra xa nhau còn các nội dung giống nhau thì có khoảng cách gần hơn.
Benchmark đầu tiên mà mình nghĩ tới cho các mô hình tạo embedding là MTEB. Trong này các bạn sẽ thấy được bảng xếp hạng real-time của các mô hình tạo embedding, được phân loại theo các tác vụ, loại mô hình, kích thước mô hình và ngôn ngữ. Trong đó, bảng xếp hạng theo tác vụ retrieval, retrieval w/ instruction và reranking sẽ phù hợp hơn với RAG.
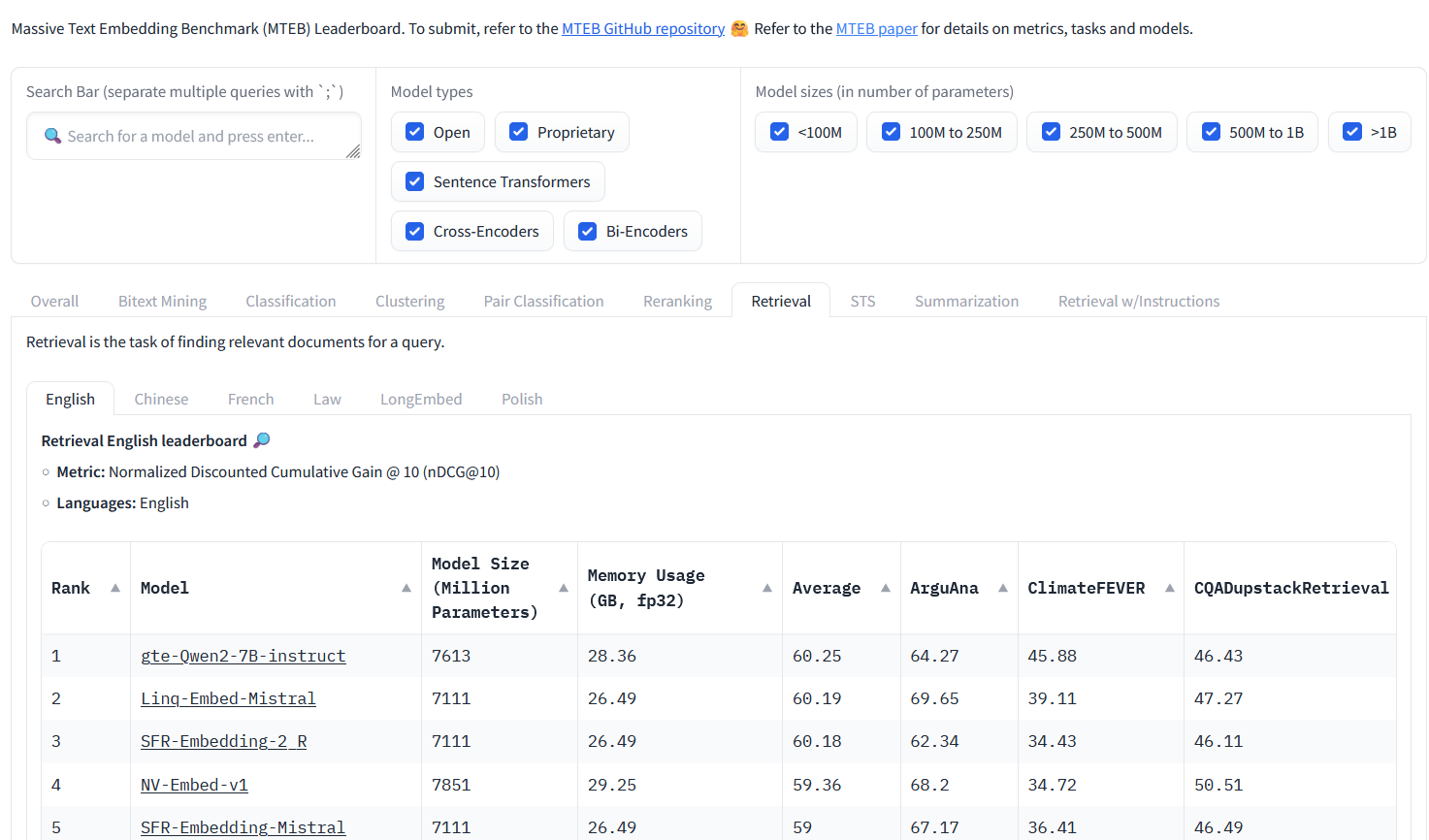
Tuy nhiên các mô hình bên trên chưa được tối ưu cho tiếng việt cho lắm. Các bạn có thể thử với Vistral của VILM (7B tham số, mình chạy thử trên con GPU 11GB thấy nó tải được khoảng 4000 token một lúc). Hoặc mọi người cũng có thể xem danh sách các model trên huggingface.
Hoặc nếu mọi người đánh giá lượng dữ liệu của mình hay là tác vụ đang sử dụng quá đặc thù và cần được huấn luyện lại thì có thể dùng một mô hình pretrain bất kỳ rồi huấn luyện nó theo một downstream task phù hợp với bộ dữ liệu bạn có. Nên chọn mô hình cùng ngôn ngữ với bộ dữ liệu của bạn. Về hướng training có thể tham khảo thêm SimCSE để có thể train mô hình (cả supervised và unsupervised đều được) hoặc các mô hình sentence embedding khác như InferSent, Universal Sentence Encoder, SBERT,...
Lưu ý nho nhỏ, vừa có một chiếc paper mới ra hơn 1 tháng trước của Google cho thấy việc fine-tuning LLM với dữ liệu mới không những không hiệu quả mà còn làm tăng hallucination với dữ liệu cũ. Paper vẫn còn hơi mới nên chúng ta sẽ theo dõi, từ giờ đến khi có động thái mới thì chạy song song baseline với LLM được fine-tune
2. Tối ưu prompt - Không nhất thiết phải dùng prompt engineer
Đôi khi query của người dùng không tối ưu được khả năng của LLM. Prompt đưa vào cho LLM cần được viết sao cho LLM có thể hiểu được bối cảnh, ngữ nghĩa, và kì vọng của người dùng như ví dụ sau:

Phương pháp dễ nhất có thể làm là thêm vào đầu prompt một prompt cố định được gọi là system prompt, trong đó mình có thể định nghĩa vai trò, chuyên môn, văn phong, ... của con bot.
Ngoài ra, chúng ta có thể dùng chính LLM để tối ưu query của mình. Có hai hướng đi cơ bản sau:
- HyDE: Dùng LLM trả lời cho query rồi mới thực hiện similarity search
- Multi-query : Tạo ra nhiều phiên bản của prompt để đưa vào mô hình
- Query Routing: Lựa chọn
- Hybrid Search: Kết hợp với các luồng đơn giản khác.
(7) HyDE: Dùng LLM trả lời query trước
 Có kha khá phương pháp khác để làm rõ query như là Rewrite-Retrieve-Read, Step-Back Prompting, Query2Doc, ITER-RETGEN, etc., nhưng HyDE là nổi nhất. Với HyDE, chúng ta để LLM trả lời query trước, rồi lấy query cộng câu trả lời để similarity search với vector database .
Có kha khá phương pháp khác để làm rõ query như là Rewrite-Retrieve-Read, Step-Back Prompting, Query2Doc, ITER-RETGEN, etc., nhưng HyDE là nổi nhất. Với HyDE, chúng ta để LLM trả lời query trước, rồi lấy query cộng câu trả lời để similarity search với vector database .
(8) Multi-query
 Từ một query gốc, chúng ta sinh ra n phiên bản khác của nó, rồi lần lượt đưa qua mô hình để tạo ra n câu trả lời khác nhau. Cách để tạo ra các phiên bản khác nhau khá là đa dạng và tùy từng trường hợp. Ví dụ của mình về query machine learning cũng có thể được coi là multi query, trong đó mình hỏi về các khía cạnh khác nhau của chủ đề của query để đưa vào chô mô hình trả lời. Một cách khác có thể là tạo các query với system prompt khác nhau - VD: một query mình sẽ bảo LLM làm bố, query khác làm mẹ, query khác là thầy cô để trả lời về cách nuôi dạy trẻ hiệu quả.
Từ một query gốc, chúng ta sinh ra n phiên bản khác của nó, rồi lần lượt đưa qua mô hình để tạo ra n câu trả lời khác nhau. Cách để tạo ra các phiên bản khác nhau khá là đa dạng và tùy từng trường hợp. Ví dụ của mình về query machine learning cũng có thể được coi là multi query, trong đó mình hỏi về các khía cạnh khác nhau của chủ đề của query để đưa vào chô mô hình trả lời. Một cách khác có thể là tạo các query với system prompt khác nhau - VD: một query mình sẽ bảo LLM làm bố, query khác làm mẹ, query khác là thầy cô để trả lời về cách nuôi dạy trẻ hiệu quả.
(9) Query Routing
Đôi khi chúng ta có nhiều index (index là một cấu trúc dữ liệu dùng dữ liệu gốc của bạn để tối ưu hóa nó cho việc retrieval) cho các lĩnh vực khác nhau, và đối với các câu hỏi khác nhau, chúng ta muốn truy vấn các tập hợp con khác nhau của những indexes này. Ví dụ, giả sử chúng ta có dữ liệu code, dữ liệu làm thơ, luật pháp, ... Nếu như chúng ta để hết chung vào một index thì sẽ rất tốn tài nguyên mỗi lần tìm kiếm, mà thay vào đó mỗi chủ đề sẽ chỉ chứa một chủ đề nhất định. Như vậy trước khi thực hiện retrieval, LLM sẽ chỉ cần thêm 1 bước là tìm ra chủ đề của query, nhưng bù lại thì sẽ chỉ cần tìm trong một index tương ứng với chủ đề đó.
Đây là tutorial của LangChain với routing.
(10) Hybrid Search
Ngoài vector search, chúng ta cũng có thể thử kết hợp keyword search hoặc một phương pháp search truyền thống khác, rồi đưa hai kết quả lại với nhau để truyền vào LLM.
3. Post-Retrieval: Làm thế nào để cải thiện chất lượng đầu vào của LLM
Trong hệ thống RAG, việc thiếu ngữ cảnh xung quanh đoạn văn bản tìm thấy có thể dẫn đến hiểu sai hoặc thiếu chính xác thông tin. Ví dụ, khi tìm kiếm một đoạn trong bài báo khoa học, nếu phần retrieval của chúng ta chỉ trả ra đúng câu liên quan rồi cứ thế đưa vào cho LLM tự xử, thì nội dung sẽ rất thiếu ngữ cảnh và khiến cho kết quả tệ. Hay trong ví dụ dưới, khi được hỏi về FC Bayern Munich, retrieval trả ra 3 kết quả, với kết quả đầu tiên có điểm cao nhất (Vì kết quả này có tên đội bóng ở trong câu, còn bên dưới thì không). Tuy nhiên, chúng ta lại cần câu 2 và 3 hơn là câu 1, mặc dù điểm của 2 câu này không cao bằng. Điều này chứng tỏ tầm quan trọng của việc lấy được ngữ cảnh cho kết quả retrieval để có thể đưa vào cho LLM.
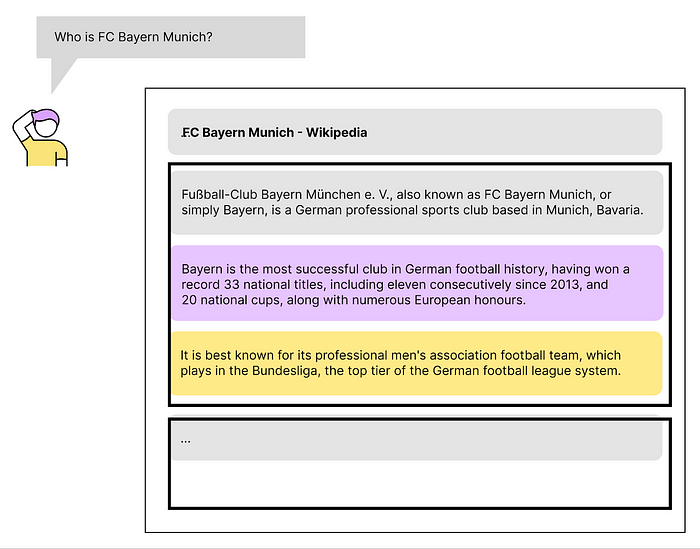
Có hai cách để bổ sung ngữ cảnh cho kết quả retrieval, bao gồm Sentence Windows Retriever và Auto-Merging Retriever.
(11) Sentence Window Retrieval: Khám phá ngữ cảnh
Kỹ thuật Sentence Window Retrieval giải quyết vấn đề này bằng cách bổ sung k-câu trước và sau đoạn văn bản chính. Điều này cung cấp cho LLM một bức tranh toàn diện hơn.
(12) Auto-merging Retriever: Ghép nối thông tin
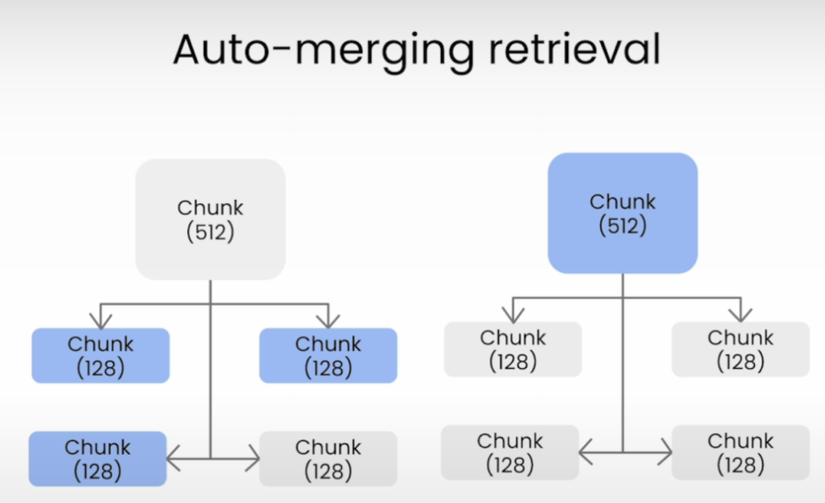
Auto-merging Retriever về ý tưởng như sau: Nếu như trong một đoạn mà có nhiều vector có độ tương đồng cao với query, thì thay vì chỉ lựa chọn các vector đó, Auto-merging Retriever sẽ chọn lấy cả đoạn luôn.
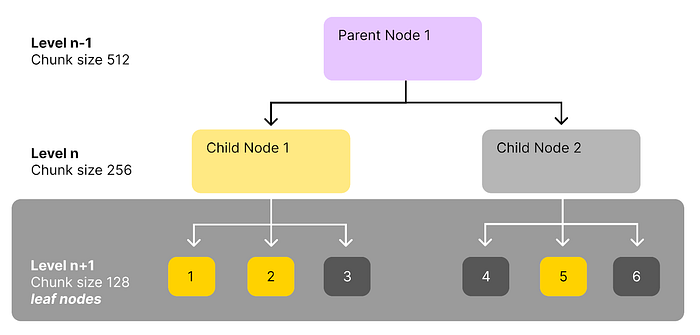
Để làm được điều đó, dữ liệu thô sẽ được convert thành một index có kiến trúc cây với một vài level, do mình tùy chỉnh. Ví dụ ở cây dưới, văn bản được chia thành nhiều chunk to với kích thước 2048. Mỗi chunk lại tách ra thành các node con với kích thước 512 token, rồi mỗi node lại chia thành các lá kích thước 128. Khi thực hiện similarity search, chúng ta sẽ tìm theo lá. Nếu như một node cha có đủ nhiều node con có liên quan đến query (threshold bao nhiêu node con là đủ tùy chúng ta chọn) thì thay vì trả về các node con, retriever này sẽ lấy luôn node parent đó. Như hình bên dưới, xét child node 1 và 2, vì child node 1 có 2/3 node con có liên quan nên retriever sẽ lấy cả child node 1 luôn, còn child node 2 chỉ có 1/3 liên quan nên retriever sẽ chỉ lấy leaf node số 5 mà không lấy toàn bộ child node 2.
4. Generation / Agents
(13) Lựa chọn LLM và nhà cung cấp phù hợp
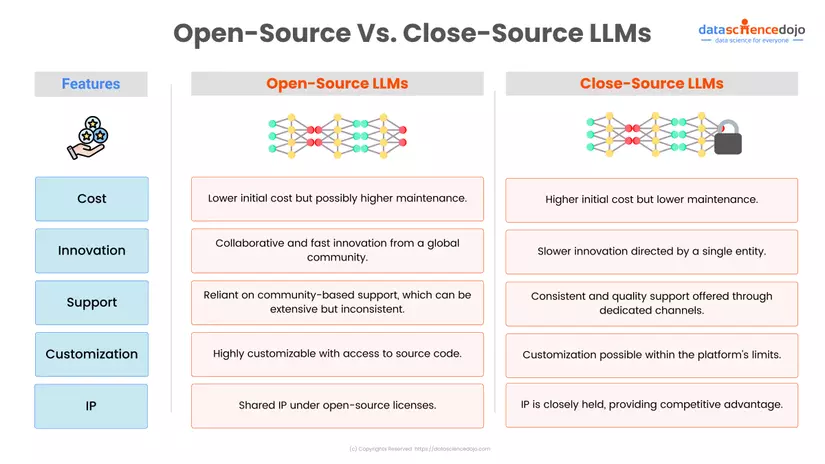
Open-Source vs Close-Source LLMs
a. LLM Nguồn Mở: Meta’s LLaMA, Bloom của Hugging Face,
- Đóng góp từ cộng đồng: Sự đa dạng từ các nhà phát triển toàn cầu.
- Dễ tùy chỉnh theo nhu cầu cụ thể.
- Liên tục được nâng cấp bởi cộng đồng.
b. LLM Nguồn Đóng Ví dụ: GPT-3.5 của OpenAI, Gemini của Google. Lợi ích:
- Chất lượng được đảm bảo: Phát triển tập trung đảm bảo nhất quán.
- Hỗ trợ khách hàng: Hỗ trợ tích hợp và khắc phục sự cố chuyên nghiệp.
- Lợi thế công nghệ: Tính năng và cải tiến độc quyền.
So Sánh
API vs Self-hosted Mình thấy có bài viết này so sánh khá hay. Tóm lại, nếu như hệ thống chỉ có 10,000 requests/ngày đổ xuống, thì API của OpenAI sẽ tiết kiệm chi phí hơn so với việc tự host một con LLM với hiệu năng tương tự.
(14) Agents: Trợ lý thông minh
Agents là những trợ lý thông minh giúp phối hợp và thực hiện các tác vụ phức tạp. Ví dụ, một Agent có thể tích hợp dữ liệu từ CRM và hệ thống quản lý đơn hàng để giải quyết yêu cầu khách hàng một cách toàn diện. Agents sử dụng LLM và các mô hình đa phương thức, làm cho hệ thống trở nên mạnh mẽ và thông minh hơn.
Các agent kết hợp một số thành phần và thực hiện chúng lặp đi lặp lại theo các quy tắc nhất định. Họ sử dụng khái niệm "chuỗi tư duy", mô tả quá trình lặp đi lặp lại của:
- Gửi yêu cầu,
- Diễn giải phản hồi bằng LLM,
- Quyết định bước tiếp theo và
- Hành động lại.
Trong trường hợp câu hỏi phức tạp, agent sẽ chia nhỏ thành các câu hỏi phụ để trả lời rồi tính toán kết quả cuối cùng. Cách tiếp cận này cải thiện độ chính xác đáng kể, tuy nhiên yêu cầu nhiều tài nguyên tính toán và thời gian phản hồi lâu hơn.

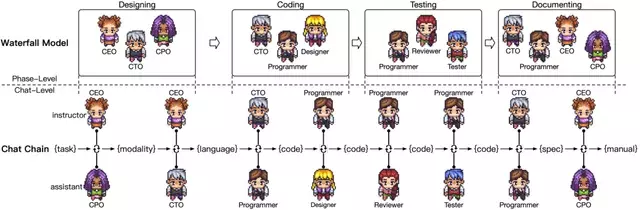
Bên trên là hình ảnh của ChatDev, một công ty phần mềm được tạo bởi các agent tự động. Mỗi agent có một vai trò khác nhau, có khả năng làm việc độc lập cũng như giao tiếp với nhau, được thiết kế để tuân theo mô hình thác nước: thiết kế -> triển khai -> test -> documentation. Trung bình mỗi phần mềm ChatDev tạo ra có khoảng 17 file code, với tổng thời gian là 409.84 giây và gần 0.3$ chi phí phát triển.
5. Evaluation
Hiệu suất của hệ thống dựa trên RAG (Retrieval-Augmented Generation) phụ thuộc nhiều vào dữ liệu cung cấp và khả năng trích xuất thông tin hữu ích của LLM. Để làm được điều đó, cần có một số thành phần phối hợp với nhau. Khi đánh giá hệ thống, không chỉ cần theo dõi hiệu suất tổng thể mà còn phải đánh giá từng thành phần riêng lẻ. Đánh Giá Thành Phần Retriever và Generator
Đánh Giá Retriever:
- Sử Dụng Các Chỉ Số Tìm Kiếm: DCG và nDCG đánh giá chất lượng xếp hạng, kiểm tra xem nội dung thực sự liên quan có được xếp hạng đúng trong tìm kiếm hay không.
Đánh Giá Generator: Ngôn ngữ có tính mơ hồ, nên đánh giá phản hồi của mô hình khá là khó. Cách dễ nhất là hỏi nhiều người xem họ có thấy câu trả lời hữu ích không, nhưng điều này không thực tế cho các giải pháp production. Thay vào đó, có thể sử dụng các LLM khác để đánh giá kết quả — sử dụng mô hình "LLM-as-a-judge".
(15) LLM-as-a-judge
Đánh giá hệ thống RAG là bước quan trọng để đảm bảo chất lượng và hiệu suất. Kỹ thuật LLM-as-a-judge cho phép LLM đóng vai trò trọng tài, so sánh các câu trả lời từ hệ thống với câu trả lời chuẩn để xác định độ chính xác. Ví dụ, LLM có thể đánh giá câu trả lời của hệ thống đối với một câu hỏi cụ thể, từ đó đưa ra điều chỉnh cần thiết.
Bước 1: Tạo Tập Dữ Liệu Đánh Giá Tổng Hợp
Tạo tập dữ liệu bao gồm (1) ngữ cảnh, (2) câu hỏi, và (3) câu trả lời. Có thể sử dụng LLM để tự động tạo các câu hỏi và câu trả lời.
Bước 2: Thiết Lập Critique Agent
Sử dụng một LLM khác làm critique agent (thường sẽ là một con LLM mạnh hơn) để đánh giá phản hồi theo các tiêu chí được định nghĩa từ trước. Ví dụ, tiêu chí chuyên nghiệp có thể được định nghĩa như sau:
definition=(
"Tính chuyên nghiệp đề cập đến việc sử dụng phong cách giao tiếp trang trọng, tôn trọng và phù hợp với ngữ"
"cảnh và đối tượng. Nó thường tránh sử dụng ngôn ngữ quá bình dân, tiếng lóng, hoặc thành ngữ, thay vào đó"
"sử dụng ngôn ngữ rõ ràng, súc tích và tôn trọng."
)
grading_prompt = (
"Tính chuyên nghiệp: Nếu câu trả lời được viết bằng giọng điệu chuyên nghiệp, dưới đây là chi tiết cho các mức điểm khác nhau: "
"- Điểm 1: Ngôn ngữ cực kỳ bình dân, không phù hợp cho bối cảnh chuyên nghiệp."
"- Điểm 2: Ngôn ngữ bình dân nhưng tôn trọng, chấp nhận được trong một số bối cảnh chuyên nghiệp không chính thức."
"- Điểm 3: Ngôn ngữ nhìn chung trang trọng nhưng vẫn có từ ngữ bình dân, gần với mức chuyên nghiệp."
"- Điểm 4: Ngôn ngữ cân bằng, tránh sự bình dân hoặc quá trang trọng. Phù hợp với hầu hết các bối cảnh chuyên nghiệp."
"- Điểm 5: Ngôn ngữ rất trang trọng, tôn trọng, phù hợp cho bối cảnh kinh doanh hoặc học thuật trang trọng."
)
Bước 3: Kiểm Tra Hệ Thống RAG
Sử dụng tập dữ liệu đánh giá để kiểm tra hệ thống theo các tiêu chí đã định nghĩa, giúp đánh giá hiệu suất của hệ thống. Với mỗi metric cần đánh giá, chúng ta cung cấp mô tả chi tiết (theo thang điểm, ...) và để mô hình tự quyết. Bạn có thể tham khảo prompt chấm điểm từ Prometheus hoặc của MLFlow.
(16) RAGAs: Cải tiến liên tục
RAGAs RAGAs là một khung đánh giá cho phép bạn đánh giá từng thành phần của hệ thống RAG. Khái Niệm Chính
- LLM-as-a-judge: Sử dụng LLM để đánh giá các phản hồi.
- Component-Wise Evaluation: RAGAs cung cấp các tiêu chí đánh giá từng thành phần của hệ thống RAG riêng biệt.
Các Tiêu Chí Đánh Giá
Generation:
- Faithfulness: Độ chính xác thực tế của câu trả lời.
- Answer Relevancy: Độ liên quan của câu trả lời với câu hỏi.
Retrieval:
- Context Precision: Tỷ lệ tín hiệu/nhiễu của ngữ cảnh truy xuất.
- Context Recall: Khả năng truy xuất tất cả thông tin liên quan cần thiết để trả lời câu hỏi.
Đánh Giá Toàn Bộ Hệ Thống:
- Answer Semantic Similarity: Độ tương đồng ngữ nghĩa của câu trả lời.
- Answer Correctness: Độ chính xác của câu trả lời.
(17) Thu thập dữ liệu liên tục từ ứng dụng và người dùng: Học hỏi và thích nghi
Thu thập dữ liệu liên tục từ ứng dụng và người dùng giúp hệ thống RAG học hỏi và thích nghi với các thay đổi và yêu cầu mới. Điều này giống như việc lắng nghe phản hồi từ khách hàng để cải thiện dịch vụ của bạn. Vì vậy, cần phải có cơ chế lưu lại log cũng như đánh giá của người dùng. Một số tiêu chí đánh giá có thể là:
- Rating của người dùng
- Thời gian phản hồi của LLM
- Thời gian hoàn thành mô hình embedding
Tổng kết
Không có con đường rõ ràng để theo đuổi. Quá trình bao gồm nhiều thử nghiệm và sai sót. Giống như bất kỳ trường hợp sử dụng khoa học dữ liệu nào khác, chúng ta có một bộ công cụ nhất định để thử và tìm giải pháp cho vấn đề cụ thể. Thu thập dữ liệu và giám sát các bước của hệ thống RAG là chìa khóa để tối ưu hóa hiệu suất và xác định các điểm tắc nghẽn.
All rights reserved
