
Bóc trần hệ thống gợi ý của Twitter - một cú lừa ngày cá tháng tư???
Bài đăng này đã không được cập nhật trong 3 năm
Lời mở đầu
Xin chào các bạn, có lẽ gần đây thế giới công nghệ không khỏi choáng ngợp trước tần suất ra mắt của các sản phẩm AI từ ChatGPT, GPT-4 và gần đây nhất là vào ngày 1/4, Elon Musk và Twitter đã quyết định open source một phần của hệ thống gợi ý trên nền tảng Twitter tại đây và tại đây. Và mới chỉ sau hai ngày, repo này đã đạt được 38000 star trên Github đủ để thấy sức nóng của nó lớn đến mức nào. Là một người làm công nghệ làm sao chúng ta có thể không tò mò tìm hiểu xem trong repo này có gì mà thu hút đến như vậy, và liệu rằng nó có phải là một joke từ Elon Musk trong ngày cá tháng tư hay không? Chúng ta bắt đầu đi tìm hiểu nhé. OK, Gết gô
Có phải tất cả chức năng recommendation đều open source?
Trước tiên chúng ta cần làm rõ điều này, bởi nói đến recommendation tức là nói đến một chức năng có giá trị nhất của Twitter hay nói cách khác nó chính là một trong những cần câu cơm của họ. Có rất nhiều loại recommendation như:
- Đề xuất bài viết liên quan đến người dùng (trang For You trên Twitter)
- Đề xuất các người dùng có liên quan đến người dùng (chức năng Follow)
- Đề xuất các quảng cáo phù hợp với người dùng
- Đề xuất các nội dung liên quan trong chức năng tìm kiếm
- Đề xuất các nội dung liên quan trong chức năng Explore
- ... và còn nhiều phần khác nữa...
Và một câu hỏi đặt ra là Liệu học có open source toàn bộ các chức năng của hệ gợi ý này không? thì câu trả lời là KHÔNG. Bởi lẽ có một số chức năng như recommendation quảng cáo chẳng hạn là chức năng trực tiếp đem lại doanh thu cho họ và chưa kể nó có thể bao gồm cả các yếu tố không thuộc phạm vi kĩ thuật. Điều này là rất dễ hiểu, chúng ta cũng không nên tham lam đòi bê cả hệ thống nhà người ta về làm một chức năng nhỏ cho hệ thống nhà mình đúng không nào.
Vậy thì trong bản open source ngày 1/4 vừa qua thì Twitter Recommendation có gì? Nếu nói về chức năng thì họ open source cho chúng ta duy nhất một chức năng recommendation nhưng mình nghĩ đó cũng sẽ là chức năng lớn nhất đó là: Đề xuất bài viết liên quan đến người dùng (trang For You trên Twitter). Nghe thì có vẻ đơn giản như vậy nhưng tất cả các kĩ thuật họ đã thực hiện để cho ra được một chức năng đơn giản như vậy thì không hề tầm thường nha mọi người.
OK chúng ta tiếp tục cày nát repo này xem có gì nào
Bản chất của phương pháp này
Đầu tiên chúng ta cần hình dung rõ ràng về bối cảnh của bài toán. Phương pháp recommendation này với mục tiêu là tìm ra các bài viết phù hợp nhất với user để hiển thị ở trang For You, hiểu cơ bản thì bạn đang quan tâm đến một chủ đề nào đó thì thuật toán cần phải gợi ý cho bạn các bài viết liên quan, chứ đưa ra mấy cái không liên quan là nó bỏ service liền. Để thực hiện được điều đó, họ tiến hành thử nghiệm các thuật toán nhằm trả lời một số câu hỏi then chốt như:
- Người dùng hiện tại sẽ tương tác với một người dùng khác (like, comment, reply, retweet...) với xác suất là bao nhiêu?
- Người dùng hiện tại có hứng thú với các nội dung gì?
- Có bao nhiêu cộng đồng (communities) trên Tweeter hiện tại và các bài trending trong các cộng đồng đó như thế nào?
Để thực hiện được điều đó thì thuật toán của họ đề xuất cũng dựa trên một hướng có kiến trúc tương tự như Youtube Recommendation Paper đã được công bố trước đó.
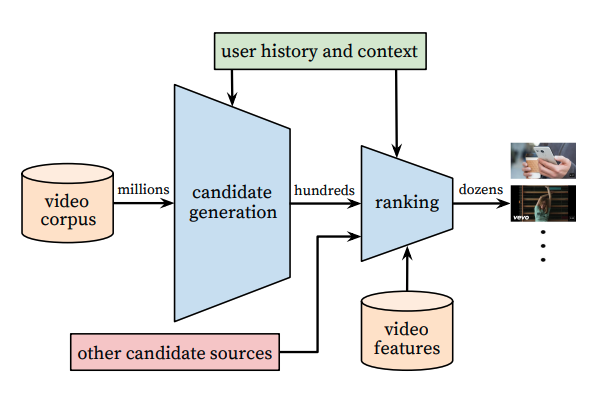
Hiểu đơn giản nó bao gồm các thành phần như sau:
- Candidate generation: bằng một cách nào đó tìm ra một tập nhỏ video hoặc post (đối với Twitter là 1500 posts) có liên quan nhất đến người dùng hiện tại từ hàng trăm triệu thậm chí hàng tỉ bài post trên Twitter.
- Ranking: cũng lại bằng một cách nào đó chấm điểm cho 1500 bài post đó để tién hành ranking, chọn ra top K (ví dụ 100) bài post có liên quan nhất để gợi ý cho người dùng.
Bản chất của hai phương pháp của Twitter và Youtube là giống nhau vì đều thực hiện dựa trên thuật toán multi-stage recommendation, tuy nhiên chi tiết cách thực hiện từng bước thì có nhiều điểm khác biệt và chúng ta sẽ tìm hiểu kĩ hơn trong các phần tiếp theo.
Nói về thuật toán multi-stage recommendation, các bạn có thể tìm hiểu kĩ hơn trong slide sau Multi-stage recommendation
Cụ thể các stage của Twitter recommendation được chia như sau:
- Candidate Sources (hay còn gọi là candidate generation)
- Ranking
- Heuristics,Filters,and ProductFeatures
Trong đó từng phần sẽ có các chức năng cụ thể.
Candidate sources
Twitter sử dụng một vài nguồn khác nhau để tìm ra một tập các video có liên quan nhất đến sở thích của người dùng hiện tại. Cụ thể cho mỗi request khi gửi đến hệ thống recommendation của Twitter sẽ chọn ra 1500 Tweets có liên quan nhất từ hàng tỉ các bài tweets trên Twitter thông qua các nguồn khác nhau. Theo như thuật toán của họ công bố thì các nguồn này bao gồm: In Network source và Out Network source
In Network source
Đây là nguồn cung cấp các video lớn nhất cho hệ thống recommendation. Nguồn này có thể hiểu đơn giản là tìm ra các post gần đây, có liên quan nhất đến bạn từ những user mà bạn đang follow trên Twitter. Nó xếp hạng mức độ liên quan các Tweet của những người bạn theo dõi bằng mô hình hồi quy logistic. Các Tweet có mức độ liên quan lớn nhất sẽ được chọn để làm đầu vào cho stage tiếp theo.
Thành phần quan trọng nhất để xếp hạng các Tweets có liên quan trong In Network source là Real Graph đây là một mô hình cho phép dự đoán xác suất mức độ gắn kết giữa hai users. Nếu giữa người dùng hiện tại và tác giả của Tweets có điểm số RealGraph cao thì bài viết của họ sẽ được ưu tiên hơn.
Chi tiết về RealGraph có thể mình sẽ đề cập trong một bài viết khác.
Out Network source
Nếu chỉ sử dụng các tweets được tạo ra bởi các author mà mình follow thì rõ ràng là quá giới hạn và không thể đa dạng các đề xuất phải không các bạn. Hãy tưởng tượng rằng nếu như bạn là một ngừoi dùng mới mà chưa follow ai bao giờ thì rõ ràng rằng bạn sẽ chẳng được recommend gì cả. Điều này là rất khó chấp nhận trong một sản phẩm SNS như Twitter. Chính vì thế nên việc tìm kiếm các bài tweets có liên quan từ các người dùng bạn không follow trước đó là một bài toán cần phải giải quyết. Twitter giải quyết chúng với hai hướng tiếp cận:
Sử dụng Social Graph
Hướng tiếp cận đầu tiên và cũng là hướng trực quan nhất đó là sử dụng Social Graph. Hướng này sẽ ước tính những nội dung có liên quan bằng cách phân tích mức độ tương tác của những người mà ta đang theo dõi hoặc những người có cùng sở thích với chúng ta. Để thực hiện điều này, chúng ta cần duyệt qua các đồ thị tương tác và đồ thị theo dõi để trả lời các câu hỏi như:
- Những tweets nào mà những người đang follow cũng đang quan tâm?
- Ai là những người đang thích các tweets giống tôi và gần đây họ đang xem các tweets nào khác?
Để thực hiện điều này thì việc truy vấn trên đồ thị là rất cần thiết và đòi hỏi phải có một engine hiệu quả. Twitter đã tạo ra một engine như thế gọi là GraphJet. Đây không phải là một thư viên mới, họ đã phát triển cách đây khoảng 7 năm rồi. Các bạn có thể tham khảo tạo Github. Engine này cho phép truy vấn trên đồ thị một cách real time.
Phương pháp dựa trên Social Graph đã được chứng minh mang lại hiệu quả khá tốt trên thực tế, và khoảng 15% bài viết trên Home TImeline của Twitter đang dựa vào Social Graph. Tuy nhiên hướng tiếp cận này lại khá tốn kém về chi phí vận hành và đặc biệt trong trường hợp extend cho các user mới. Chính vì thế, hướng tiếp cận theo Embedding cũng là một hướng quan trọng, chiếm đa số các ứng cử viên lựa chọn trong out network source.
Sử dụng Embedding space
Việc sử dụng embedding space sẽ giúp chúng ta trả lời câu hỏi về content similarity đó là: Các tweets và users nào tương tự với sở thích của tôi?. Embedding vector chắc không còn xa lạ với những bạn làm AI, nó là một dạng biểu diễn của thông tin dưới dạng một vector cố định số chiều. Từ các embedding vectors đại diện cho các users hay tweets chúng ta có thể tính toán được các users tương tự hay các tweets tương tự. Tuy nhiên lý thuyết là như thế nhưng lựa chọn phương pháp embedding nào để hiệu quả nhất lại là một vấn đề khác.
Ở đây Twitter sử dụng một Embedding space gọi là SimClusters. Về cơ bản thuật toán này sẽ tạo ra các community dựa vào đồ thị theo dõi của người dùng. Từ đó giúp sinh ra các embedding cho user, tweets, topics, hashtags. Chi tiết cách làm như thế nào chúng ta sẽ tìm hiểu ở phần sau. Bạn cứ hiểu đơn giản là dựa trên embedding space này thì mỗi người dùng có thể được gắn vào một community (hay một cụm người dùng có liên quan đến nhau) và được thể hiện bằng một embedding vector. Mỗi một cụm như thế có kích thước từ vài nghìn users đến hàng triệu users. Mỗi user cũng có thể thuộc vào nhiều cụm khác nhau.
Ranking
Sau khi đã có được một tạp hợp các candidate sources, chúng ta sẽ lấy ra khoảng 1500 bài tweets có liên quan nhất. Đến thời điểm này các bài viết này được được trọng số như nhau tức là có xác suất xuất hiện giống nhau bất kể tweet đó được đến từ nguồn nào.
Việc ranking sử dụng một mạng nơ ron cỡ 48M tham số được tối ưu với các tương tác của bài đăng nhằm tối ưu tính engagement của user đối vơi tweet đó (e.g. Likes, Retweets, and Replies). Mạng nơ ron này nhận đầu vào từ hàng nghìn đặc trưng khác nhau liên quan đến interaction của post và đưa ra 10 nhãn. Dựa vào 10 nhãn đó sẽ cho điểm cho Tweet. Sau đó tweet sẽ được ranking lại và lấy các tweet cao nhất.
Không có nhiều yếu tố "Trí tuệ nhân tạo" như bạn nghĩ
Mình là một người làm AI - nhắc lại cho các bạn kẻo các bạn quên không biết ông ất ơ nào đang viết bài. Chính vì recommendation là một mảng mình rất quan tâm. Ngay khi Twitter tung open source này ra mình đã dành cả một đêm thứ 6 không ngủ để phân tích đống source code của họ. Và điều đáng ngạc nhiên nhất là Nó không nhiều yếu tố AI như mình nghĩ. Hay nói đúng hơn, hệ thống này không hoàn toàn đưa ra các đề xuất dựa vào các thuật toán AI.
Cụ thể chúng ta có thể chia thuật toán này thành 3 bước chính:
- Bước 1: Tổng hợp dữ liệu (sử dụng nhiều nguồn dữ liệu khác nhau)
- Bước 2: Tạo các đặc trưng làm đầu vào cho thuật toán
- Bước 3: Filter và mixing (lọc các bài viết theo các tiêu chí và mix các recommendation để trả về kết quả cuối cùng)
Cụ thể pipeline của nó các bạn có thể thấy trên chính bài viết của Twitter tại đây
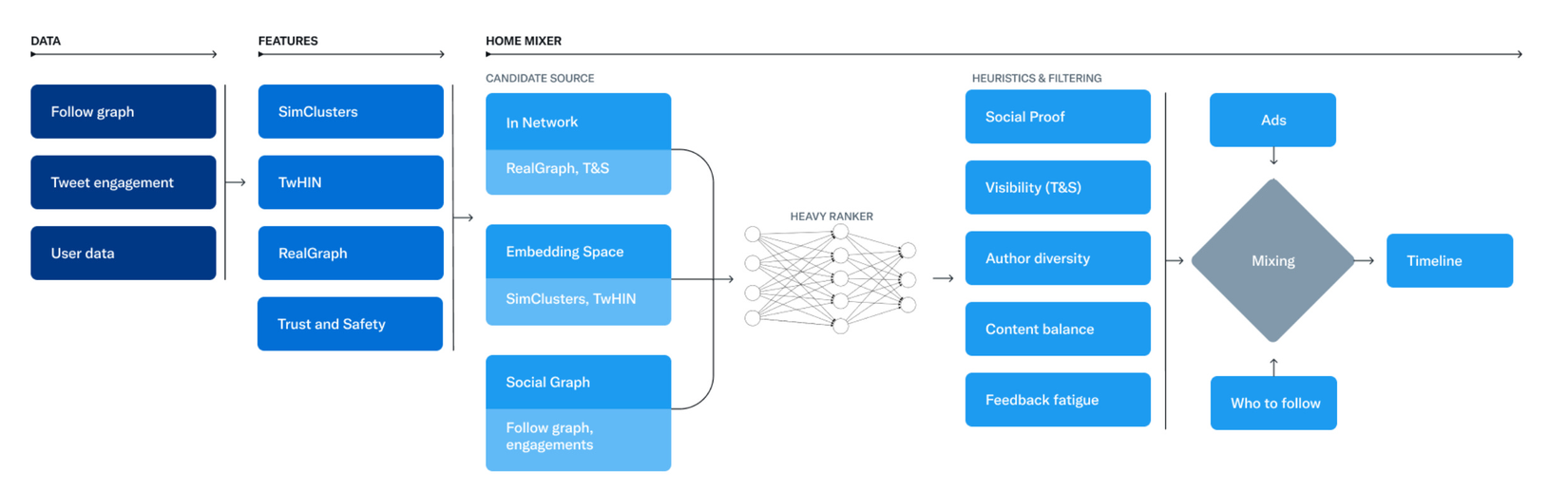
Rồi bây giờ chúng ta cùng phân tích từng bước nhỏ xem nó làm gì nhé:
Tổng hợp dữ liệu - phần không chứa AI
Như chúng ta thấy trong phần trên thì data đầu vào được tổng hợp từ 3 phần chính:
- Đồ thị follow hay nói các khác là từ các thông tin user mà bạn đang follow hoặc đang follow bạn
- Tweet engagement: dữ liệu của từng tweet để đánh giá mức độ engagement của bạn với từng tweet
- Dữ liệu cá nhân: dữ liệu của chính bạn.
Nhưng mà nói khơi khơi như thế thì ai chả nói được đúng không. Cụ thể chút nhé, nói có sách, mách có code.
Đồ thị follow
Phần này dữ liệu đơn giản sẽ là biểu diễn các user bạn follow và đang follow bạn dưới dạng một đồ thị có hướng. Phần này trong lúc tạo đặc trưng mình sẽ nói kĩ hơn. Các bạn có thể hình dung nó giống như một đồ thị như sau
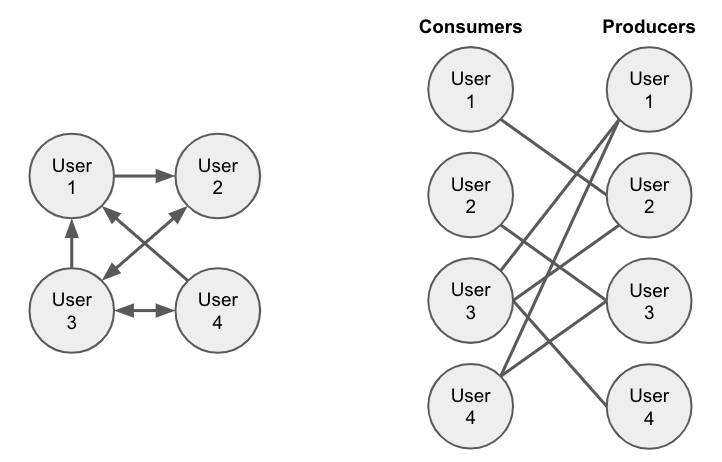
Dữ liệu tweet engagement
Các dữ liệu về bài viết sẽ được ranking theo một loạt các tiêu chí, mình có mày mò trong code của họ thì có thấy đoạn ranking các tiêu chí này như sau
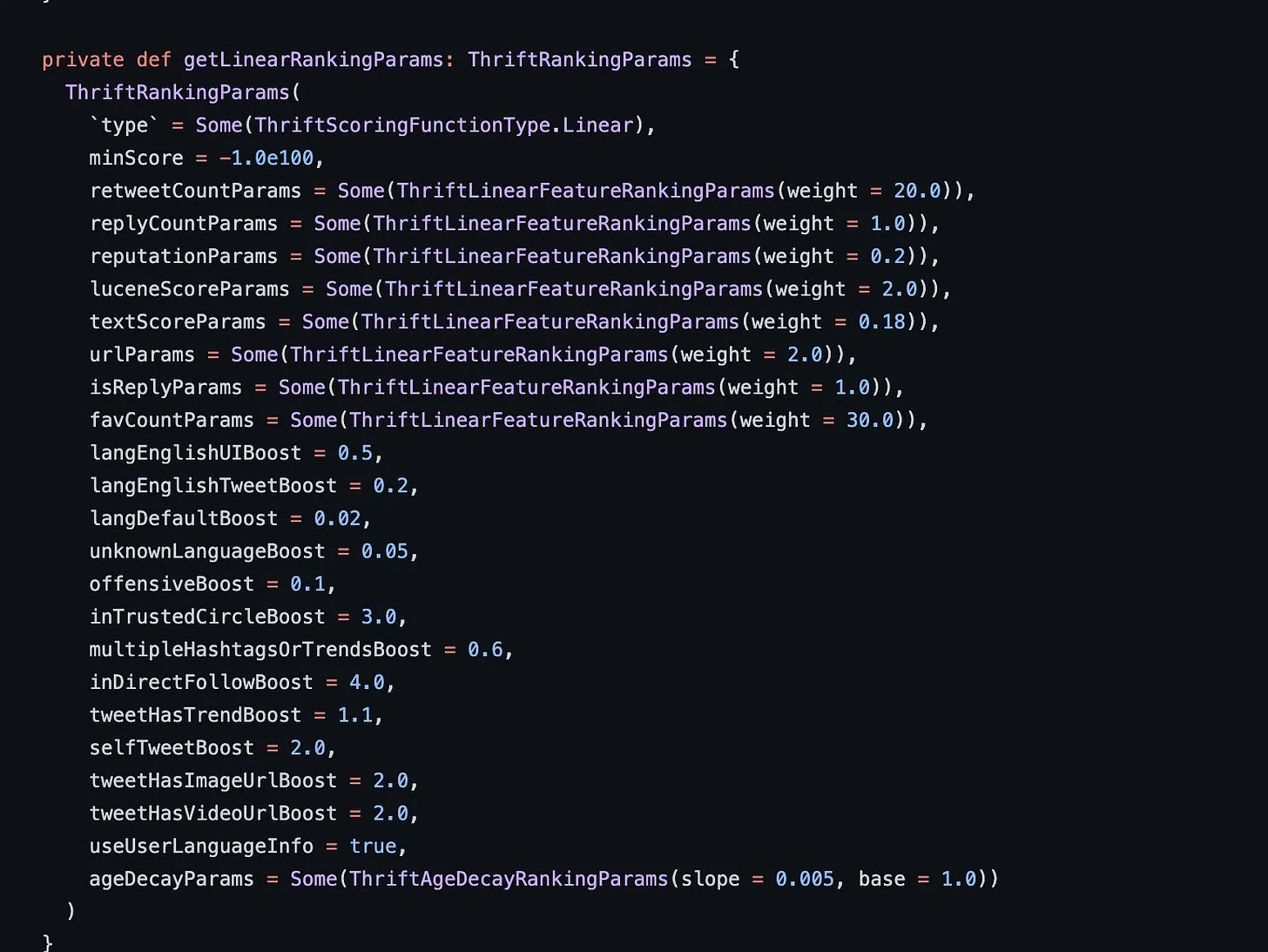
Các bạn có thể thấy trong này yếu tố có ranking params lớn nhất cũng thế hiện rằng nó có ảnh hưởng tích cực nhiêu nhất định thuật toán là favCountParams tuy nhiên trên Github không có quy định rõ tham số này được tính như thế nào. Chúng ta có thể coi đó như một tham số chung biểu diễn mức độ thích của một user cho một bài đăng. Ví dụ favCountParams = Likes + Bookmarks chẳng hạn.
Điều này nói lên một số yếu tố ảnh hưởng đến việc một bài post trong hệ thống recommendation như:
- Nếu như bài đăng của chúng ta có lượng likes hoặc bookmarks nhiều thì nó sẽ dễ được boost 30x do được đánh trọng số cao nhất (param weight là 30).
- Nếu như bài đằng của chúng ta có lượng retweet nhiều thì nó sẽ được boost 20x (param weight = 20)
- Nếu bài đăng thuộc lĩnh vực mà bạn đang follow sẽ được boost 4x
- Tương tự, bài đăng sẽ được boost 2x nếu như có chứa video và image
- Và bài đăng được reply chỉ được 1x boost, cái này nghe có vẻ hơi lạ phải không
Trái lại với các tiêu chí nhỏ hơn 1 thì là các tiêu chí sẽ hạ rank của bài viết như:
- Tweets các ngôn ngữ không xác định bị đánh là 0.05 (có thể là các bài sai chính tả hoặc teen code)
- Tweets sử dụng ngôn ngữ mặc định bị đánh là 0.02
Điều này chứng tỏ thuật toán recommendation sẽ không ưu tiên cho các bài viết chỉ có post link hoặc các ngôn ngữ không nhân dạng được
Dữ liệu về cá nhân người dùng
Dữ liệu cuối cùng của thuật toán là chính các thông tin từ lịch sử của người dùng như số lần bạn blocks, muted, reported với các bài viết lạm dụng hay spam, hoặc unfollow đối với user, topic trong vòng 50 ngày trở lại đây. Các bạn có thể xem chi tiết hơn trong code
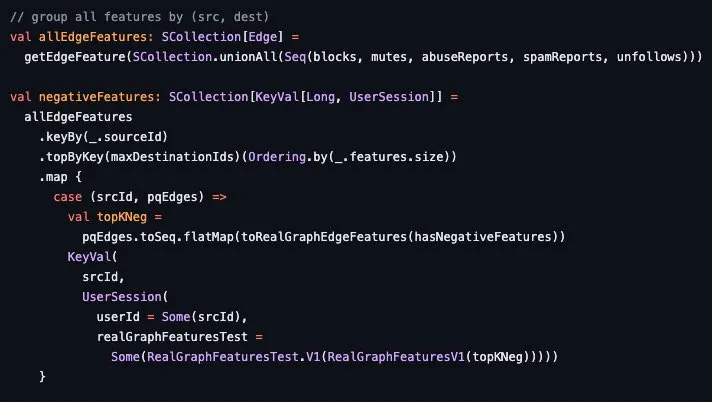
Như vậy là chúng ta đã tìm hiểu xong phần chuẩn bị dữ liệu. Tiếp sau đây là phần tạo các đặc trưng từ dữ liệu cho bài toán recommendation của chúng ta.
Tạo các đặc trưng - phần chứa nhiều AI nhất
Sau bước chuẩn bị dữ liệu là các bước tạo đặc trưng cho thuật toán. Có 4 loại đặc trưng mà chúng ta cần xem xét ở đây đó là SimClusters, TwHIN, RealGraph và Trust and Safety model. Đây có lẽ là phần nhiều yếu tố AI nhất trong project này. Chúng ta cũng tìm hiểu kĩ hơn nhé
SimClusters
Phần này mình đã nhắc đến ở bên trên. Cá nhân mình nghĩ là nó là phần nhiều AI nhất trong hệ thống này. Để hiểu chi tiết hơn về nó các bạn có thể tham khảo paper của họ tại đây
Trong bài viết này mình sẽ không đi sâu vào phân tích paper này. Tuy nhiên các bạn có thể hiểu tư tưởng chính của nó là phân cụm ra các cộng đồng trên Twitter, mỗi cộng động sẽ bao gồm những người dùng có chung sở thích, phong cách hoặc cùng nói về một chủ đề trên trên Twitter. Làm thế nào để tạo ra được các cộng đồng như thế này? Sau đây là một vài bước cơ bản:
- Đầu tiên Twiiter sẽ tạo ra các đồ thị có hướng có follow như đã nói ở phần chuẩn bị dữ liệu phía trên.
- Từ đồ thị này có thể định nghĩa ra các group of Producers có tập người follower tương tự nhau. Làm thế nào để đo độ tương tự của hai producer, cách đơn giản nhất là sử dụng khoảng cách cosine trên tập các người dùng đang follow họ. Khoảng cách cosine giữa các producer sẽ tạo thành một ma trận producer-producer như hình bên dưới
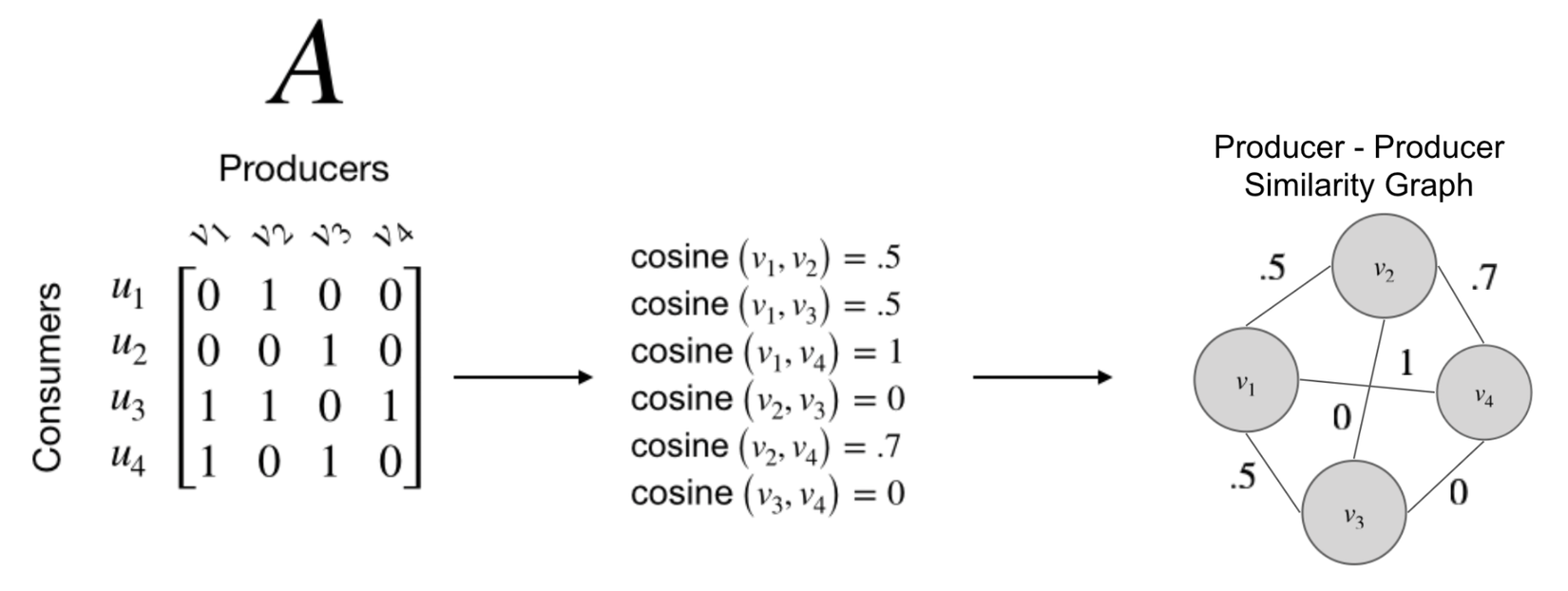
- Sau khi có được đồ thị Producer-producer người ta sử dụng một thuật toán phâm cụm gọi là Metropolis-Hastings sampling-based để tìm ra K cộng đồng từ đồ thị trên.
- Sau khi đã tìm được K cộng đồng, chúng ta có thể xây dựng một ma trận trong đó là số lượng producer và là số lượng cộng đồng. Dễ thấy rằng ma trận này rất thưa thớt do mỗi một producer sẽ được gắn với nhiều nhất 1 cộng đồng. Twiiter đã tiết lộ rằng rên production của họ có khoảng 20 triệu producer và khoảng 145 nghìn cộng đồng. Ví dụ về ma trận Producer-Comunity này được mô tả trong hình dưới. Tất nhiên trên thực tế sẽ lớn hơn nhiều.

- Tính toán Consumer Embedding: việc sử dụng SimClusters sẽ giúp các bạn dễ dàng tìm được Customer Embedding bằng phép nhân hai ma trận Customer-Producer và ma trận Producer-Comunity.. Embedding này sẽ thể hiện customer đang có hứng thú với cộng đồng nào nhất. Minh hoạ trong hình sau cho dễ hiểu
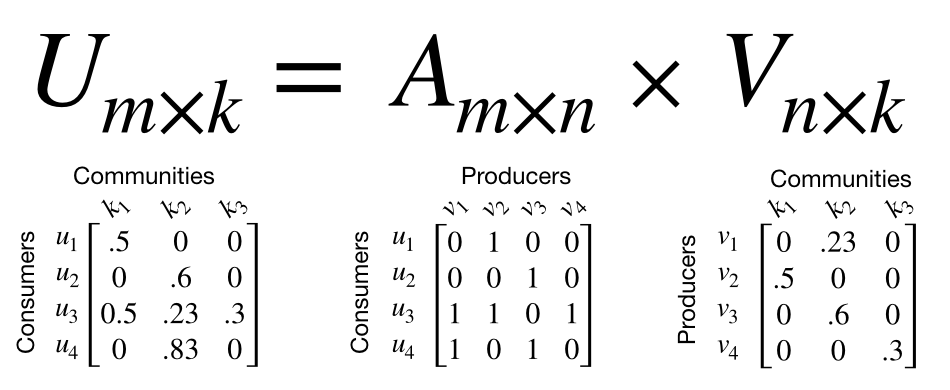
- Producer Embeddings: Khi tính toán ma trận producer-community, mỗi một producer chỉ được assign với một community nhất đinh. Mặc dù điều này làm cho ma trận trở nên rất thưa thớt và rất có lợi cho việc tính toán sau này. Tuy nhiên các bạn có thể nhận thấy một điều rằng thường một người dùng có thể post rất nhiều về các chủ đề khác nhau. Không nhất thiết lúc nào cũng phải thuộc 1 community mà nó có thể thuộc nhiều community khác nhau tuỳ theo các nội dung mà họ quan tâm. Twiiter định nghĩa chúng bằng các tạo ra ma trận Producer Embeddings có tên là nhằm thể hiện mối liên quan của các producer với các cộng đồng khác nhau. Nó được tính bằng khoảng cách cosine giữa mỗi Producer follow graph và vector thể hiện mức độ hứng thú với các cộng đồng. Các bạn có thể thấy nó trong hình sau
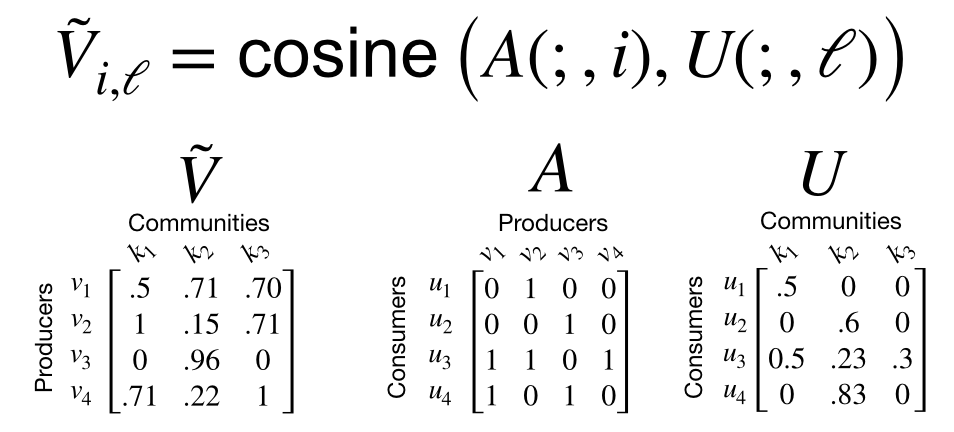
- Tweet Embeddings: Sử dụng SimClusters này hay ở chỗ nó có thể sử dụng để tính toán embedding cho nhiều thứ khác như Tweet hay Topics chẳng hạn. Đổi với Tweet Embeddings, lúc đầu tiên mỗi tweet khi được tạo sẽ được khởi tạo embedding bằng một vector rỗng. Tweet embedding sẽ được cập nhật mỗi khi Tweet đó được quan tâm. Cụ thể hơn, mỗi khi một tweet được người dùng quan tâm (có thể là like hoặc retweet chẳng hạn) thì vector interested của user sẽ được cộng thêm vào vector của tweet. Điều đó có nghĩa là Tweet Embedding sẽ được thay đổi theo thời gian dựa trên tương tác của người dùng với nó. Tweet embedding đóng một vai trò quan trọng trong việc recommend các bài viết cho người dùng dựa trên các lịch sử xem bài viết của họ.
TwHIN - Twitter Heterogeneous Information Network
Về cơ bản các bạn hiểu các Heterogeneous Information là các thông tin được tạo ra từ các nguồn khác nhau. Ví dụ như user tương tác với bài viết sẽ là một nguồn thông tin đến từ user và bài viết. Tất cả các thông tin này tạo thành các đồ thị tri thức (knowledge graph) và mỗi cạnh của đồ thị sẽ biểu diễn một hoặc nhiều tương tác giữa các thành phần. Ví dụ về các thông này được thể hiện trong hình sau
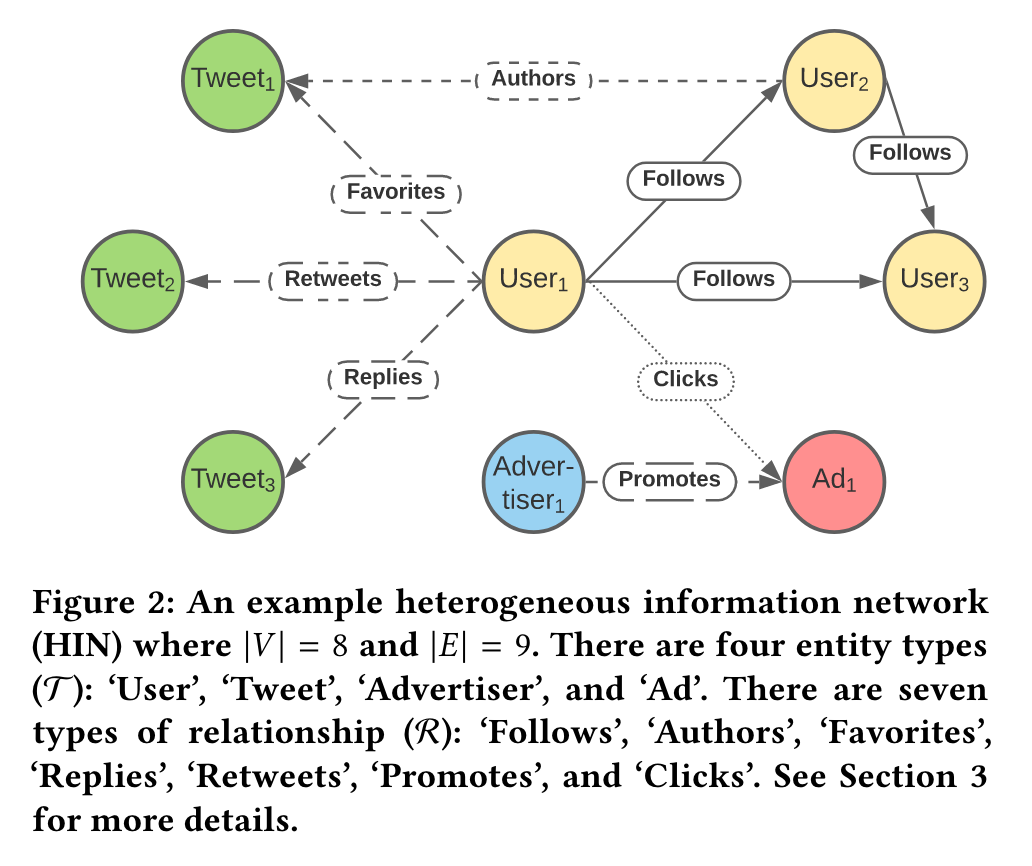
Thuật toán này sẽ sử dụng các knowledge graph đó để học các thông tin embedding cho các entities. Các knowledge graph có thể bao gồm các loại tương tác như "User follows User" "User favorites Tweet" "User clicks Advertisement" và phương pháp này sẽ học các biểu diễn chung dựa trên tất cả các tương tác sử dụng một mạng nơ ron. Các bạn có thể hình dung thế này cho dễ, cứ vứt tất cả các đồ thị tương tác này vào và thuật toán sẽ học được các biểu diễn chung dựa vào tất cả các tương tác đó. Và các biểu diễn chung này sẽ rất hữu ích cho các downstream task như Ranking model chẳng hạn.
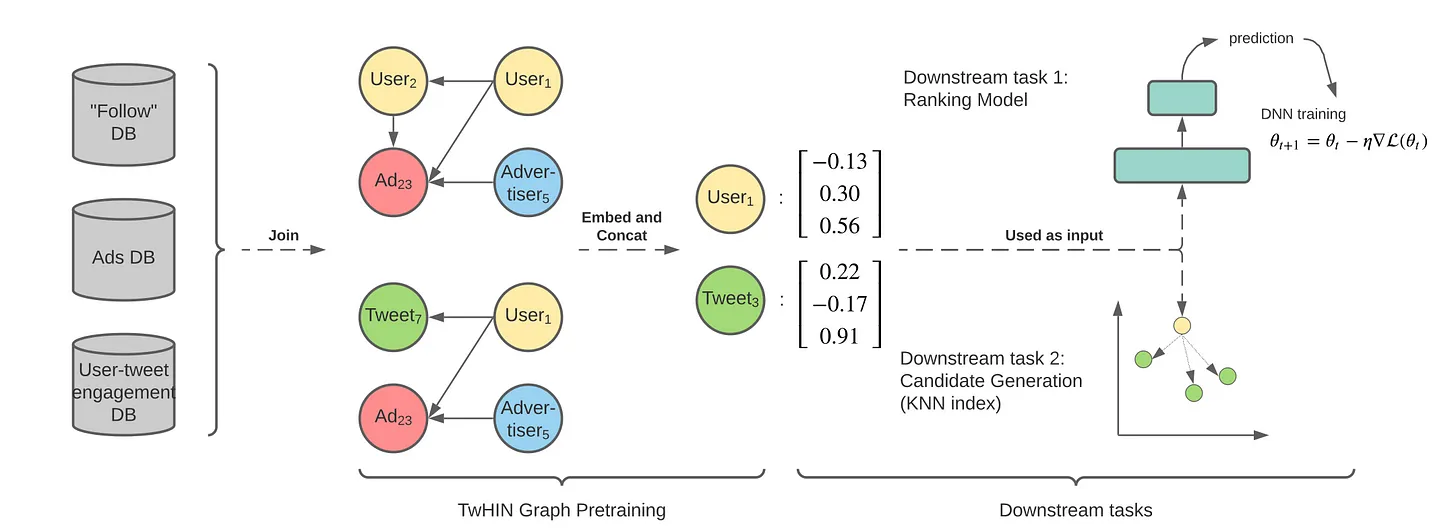
Source code chi tiết của phần này các bạn có thể tham khảo ở đây
Real Graph
Như đã chia sẻ ở phần trên, việc ranking mức độ engagement của các user trong in-network là rất có ý nghĩa để tìm ra tập ứng cử viên phù hợp. Mô hình RealGraph này sử dụng một mô hình khá đơn giản là Gradient Boosting Tree làm mô hình dự đoán xác suất một user có tương tác với một user khác.
Để huấn luyện mô hình này, tất nhiên chúng ta cần một tập dữ liệu và các mà họ đã tạo dữ liệu có nhãn như sau:
- Đầu tiên lựa chọn một tập các candidate interactions bằng cách định nghĩa tất cả các edges có tương tác, active trong một khoảng thời gian nhất định. Ví dụ từ 1/3/2023 - 31/3/2023 chẳng hạn
- Tạo một tập labeled interactions bằng cách chọn tất cả các interactions trong khoảng thời gian 1 ngày sau khoảng thời gian lựa chọn candidate interactions trên. Ở đây là tất cả các interaction trong ngày 1/4
- Tất cả các cặp tương tác nào có tương tác trong ngày 1/4 đươcj đánh label là 1, ngược lại là 0
Tập dữ liệu này sẽ được sử dụng để huấn luyện mô hình RealGraph. Sau khi được huấn luyện, mô hình này sẽ đươcj sử dụng để dự đoán khả năng tương tác của một user với một user khác dựa trên dữ liệu tương tác trong quá khứ.
Code của nó các bạn có thể xem ở đây
Trust & Safety
Sử dụng một vài mô hình học máy để dự đoán các nội dung như bạo lực, khiêu dâm, lạm dụng tình dục hay các nội dung độc hại khác. Phần này họ không có công khai mô hình do tính chất nhạy cảm của dữ liệu. Nhưng có thể đoán rằng họ cũng sử dụng các mô hình phân loại thông thường thôi.
Sau khi phân loại thì họ tiến hành đánh trọng số cho các phần nội dung này, đáng chú ý rằng trong các phần thông tin black list của họ có cả những thứ liên quan đến vấn đề xung đột ở Ucraine.

Mixing
Mixing là bước cuối cùng để nhóm tất cả các features đã liệt kê phía trên vào 3 cadidates sources là InNetwork (Sử dụng Real Graph và Trust and Safety), Embedding Space (sử dụng SimClusters và TwHIN) và Social Graph (Follower Graph, Engagement) và cho vào một đầu vào của một model gọi là Heavy Ranker. Đầu vào của model này được mô tả như trong hình sau
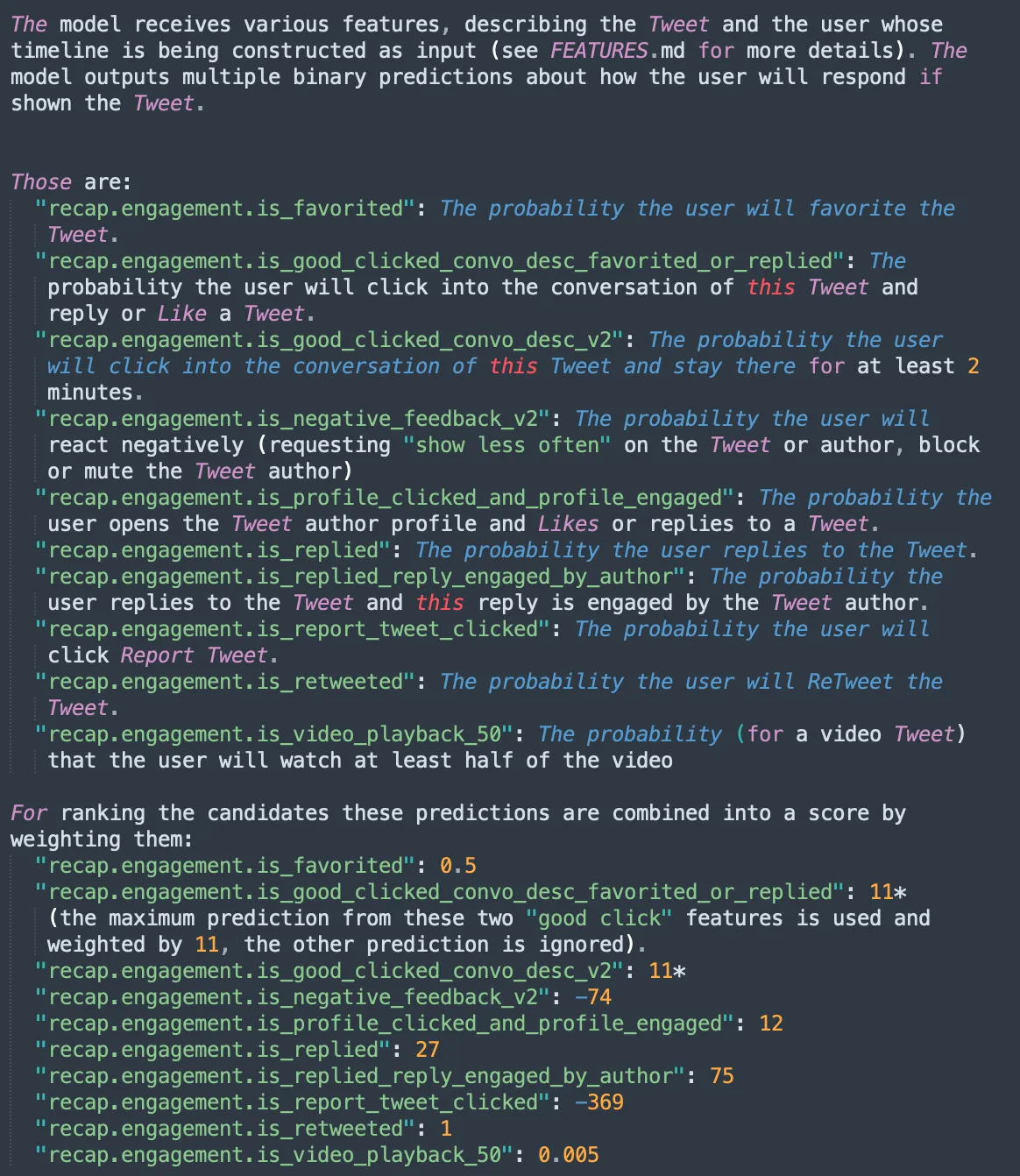
Heavy Ranker sẽ đưa ra dự đoán liệu người dùng có đọc tweet và ở lại trong hai phút hay không. Điều này giải thích tại sao các chủ đề và các tweet dài hoạt động rất tốt trên nền tảng này. Nó cũng dự đoán liệu người dùng có trả lời hay không và liệu tác giả có trả lời câu trả lời hay không. Đó thực sự là trọng số cuối cùng cao nhất! Nó giúp cho bài đăng của bạn tăng 75 lần.
Về cơ bản, những gì HeavyRanker đang cố gắng thực hiện là xếp hạng từng tweet có thể hiển thị cho người dùng theo xác suất sẽ dẫn đến các hành động tích cực cho Twitter.
Sau khi Heavy Ranker trả về kết quả tính toán cho một post, Twitter áp dụng một số heuristic và filtering như việc cân bằng về số lượng content của các author. Điều này tránh cho việc bạn chỉ quanh quẩn với các gợi ý của các author trong cộng đồng của bạn. Nó cũng sử dụng các nội dung viral và các phản hồi của người dùng để tiến hành đưa ra đề xuất cuối cùng.
Lạm bàn
Sau rất nhiều những vụ private source từ các công ty khác trước đây thì cuối cùng cộng đồng AI cũng được chào đón một open source với khá nhiều thứ hay ho có thể học được. Dù vẫn còn rất nhiều phần trong repo này chưa được public mà chỉ có file README.md summary lại cách mà họ thực hiện nhưng dù sao chúng ta vẫn thu thập được những kiến thức nhất định chứ không như những gì mà OpenAI đã làm khi công bố Technical Report của GPT-4 (tham khảo Trải lòng sau khi đọc GPT-4 Technical Report của OpenAI - các bác nên đổi tên công ty đi.
Đây thực sự là một động thái tích cực và hi vọng rằng chúng ta sẽ chào đón thêm nhiều hơn nữa các Open Source từ các tập đoàn lớn như Twiiter trong tương lai. Bài viết cũng khá dài rồi, một lần nữa cảm ơn các bạn đã luôn theo dõi và ủng hộ những bài viết của mình và hẹn gặp lại các bạn trong các bài viết tiếp theo.
All rights reserved
