
Attention trong Seq2seq Model
Bài đăng này đã không được cập nhật trong 3 năm
Xin chào các bạn, bài viết hôm nay mình sẽ chia sẻ về Attention trong Sequence 2 sequence model. Như các bạn cũng biết Attention là một state-of-the-art model và cũng đã được mọi người ứng dụng và thử nghiệm trong nhiều bài toán. Và chúng ta cùng theo dõi xem vì sao Attention lại góp phần vào sự thành công của nhiều model deep learning khác trong đó có Seq2Seq mà mình sẽ chia sẻ ở dưới đây.
Attention trong Seq2seq model
Seq2seq truyền thống
Chúng ta có thể sử dụng mô hình Seq2Seq cho nhiều bài toán như Machine Translation (dịch máy), Named Enity Recognition (Nhận diện thực thể có tên) hay Sentiment Classification (Phân loại cảm xúc)....
Mô hình seq2seq sử dụng kiến trúc encoder và decoder có độ dài đầu ra và đầu vào khác nhau. Như hình vẽ dưới đây:
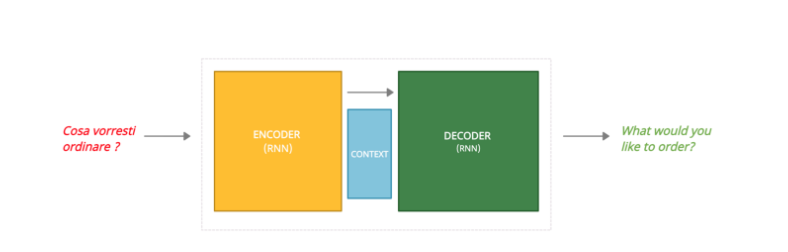 Hình: Seq2seq model
Hình: Seq2seq model
Bộ Mã hóa (Encoder) xử lý tất cả các đầu vào bằng cách chuyển đổi chúng thành 1 vector duy nhất, được gọi là context vector. Context vector này chứa tất cả thông tin bộ mã hóa có thể phát hiện ra từ đầu vào và giúp bộ giải mã đưa ra được quyết định chính xác, và context vector này sau đó cũng hoạt động như trạng thái ẩn đầu tiên của bộ giải mã.. Cuối cùng vector được gửi đến bộ giải mã (Decoder) để tạo ra chuỗi đầu ra.
Dưới đây là một ví dụ về xử lý 1 chuỗi cần dịch theo từng timestep:
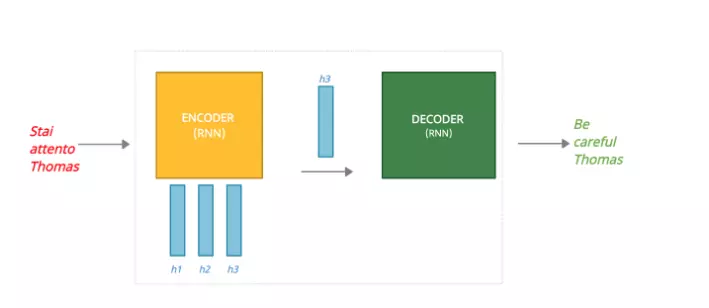 Hình: ví dụ Seq2seq
B1: Từ "Stai" được gửi đến Encoder, encoder cập nhật hiden state 1 (h1) dựa trên đầu vào.
B2: Từ "attento" được gửi tới Encoder, Encoder cập nhật hidden state2 (h2) dựa trên các đầu vào và các đầu vào trước đó của nó.
B3: Từ "Thomas" được gửi đến Encoder, Encoder cập nhật hidden state3 (h3) dựa trên các đầu vào và các đầu vào trước đó của nó.
B4: Hidden state 3 trở thành context vector đượcgửi đến Decoder, Decoder tạo ra output đầu tiên "be"
B5: DECODER tạo ra đầu ra thứ hai 'careful'
B6: DECODER tạo ra đầu ra thứ ba “Thomas”
Hình: ví dụ Seq2seq
B1: Từ "Stai" được gửi đến Encoder, encoder cập nhật hiden state 1 (h1) dựa trên đầu vào.
B2: Từ "attento" được gửi tới Encoder, Encoder cập nhật hidden state2 (h2) dựa trên các đầu vào và các đầu vào trước đó của nó.
B3: Từ "Thomas" được gửi đến Encoder, Encoder cập nhật hidden state3 (h3) dựa trên các đầu vào và các đầu vào trước đó của nó.
B4: Hidden state 3 trở thành context vector đượcgửi đến Decoder, Decoder tạo ra output đầu tiên "be"
B5: DECODER tạo ra đầu ra thứ hai 'careful'
B6: DECODER tạo ra đầu ra thứ ba “Thomas”
Vấn đề trong Seq2seq truyền thống
Model truyền thống cũng khá là tốt tuy nhiên, RNN gặp một số vấn đề như:
- Vanishing Gradient: (Đạo hàm triệt tiêu) hiện tượng gradient bị biến mất khi câu quá dài, tức là RNN không thể học được những phụ thuộc xa.
- Exploding Gradient :(bùng nổ gradient) Đây là hiện tượng gradient quá lớn do tích tụ gradient ở những lớp cuối đặc biệt hay xảy ra đối với câu dài
- Không tương thích với dữ liệu có cấu trúc (structured bias) : Ví dụ câu " Tôi rất thích học môn Toán" ở đây từ "học " và "môn Toán" có mối quan hệ với nhau so với các từ khác. Tuy nhiên cơ chế của RNN là học tuần tự từ trái sang phải (inductive bias) thiếu đi mất những cơ chế để mô hình học được những từ thực sự có liên quan đến nhau.
Ở vấn đề Vanishing gradient và Exploding Gradient gần như đã được giải quyết bởi LSTM/GRU. Trong khi đó vấn đề không tương thích với dữ liệu có cấu trúc chưa được giải quyết và **Attention đã giải quyết được vấn đề đó. **
Attention
Như mình vừa đề cập ở trên Attention có thể giúp giải quyết vấn đề không tương thích với dữ liệu có cấu trúc, bây giờ chúng ta cùng xét 1 ví dụ nhé.
Input: Tôi rất thích học môn Toán
Ở đây bạn có thể thấy "học " và "môn Toán" có mối quan hệ với nhau so với các từ khác,Vì vậy, thay vì nhìn vào tất cả những từ trong đầu vào thì chúng ta có thể tăng tầm quan trọng của một vài từ cụ thể của đầu vào có ý nghĩa đối với đầu ra giúp mô hình dự đoán kết quả chính xác hơn. Đó là ý tưởng cơ bản của cơ chế Attention.
Model Seq2seq ở đây cũng bao gồm: Encoder, Attention Decoder.
Khác với model Seq2seq truyền thống, ở đây sử dụng cả hidden state và context vector, như ở trên chúng ta chỉ dùng mỗi context vector. Như hình ở dưới đây:
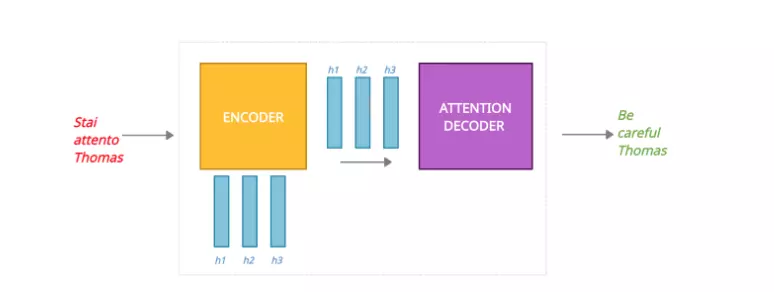 Hình: Seq2seq với attention
Hình: Seq2seq với attention
Ở model Seq2seq truyền thống chúng ta chỉ thấy mỗi hidden state 3 được đưa vào Decoder để dự đoán đầu ra, còn ở đây chúng ta có thể thấy tất vả hidden state được đưa vào Decoder.
Encoder - Bộ mã hóa
Trước khi được đưa vào encoder, dữ liệu của chúng ta mỗi từ sẽ được chuyển thành 1 vector thông qua quá trình embedding. Từ đầu tiên, “Stai” trong câu dưới đây, sau khi được embedding sẽ được chuyển đến encoder. Ở đây RNN tạo ra hidden state 1, tương tự cho từ thứ hai và thứ ba, các hidden state này được tạo ra từ đầu vào và các đầu vào trước đó của nó. Khi tất cả các từ trong câu của chúng ta đã được xử lý, các trạng thái ẩn (h1, h2, h2) sẽ được chuyển đến Attention Decoder.
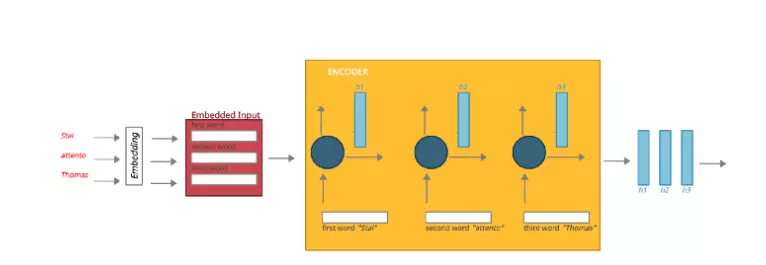 Hình: Encoder
Hình: Encoder
Attention Decoder
Ở bước đầu tiên, bộ giải mã attention thực hiện embedding hidden state từ encoder, RNN xử lý các đầu vào và tạo ra một vector trạng thái ẩn của bộ Decoder mới (h4).
Mỗi trạng thái ẩn của bộ mã hóa được ấn định một điểm số theo công thức concat của Luong Attention paper như sau:
 Hình: công thức concat
Hình: công thức concat
mỗi score sẽ được đưa qua công thức softmax (attention weighted):
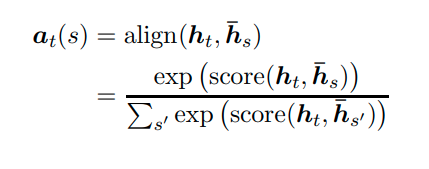
Trạng thái ẩn của bộ mã hóa và điểm softmax liên quan được nhân với nhau, Các trạng thái ẩn(hidden states) thu được được thêm vào để có được vectơ ngữ cảnh (context vector) (c4)
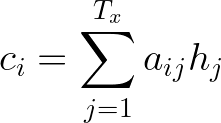
Context Vector (c4) và attention weighted được đưa vào 1 lớp RNN => Vector output, Vector này được chuyển qua một mạng fully connected neural network, được nhân với ma trận trọng số Wc và sử dụng tanh activation
Đầu ra của lớp được kết nối đầy đủ này sẽ là từ đầu ra đầu tiên của chúng ta trong chuỗi đầu ra (đầu vào: “Stai” -> đầu ra: “Be”).
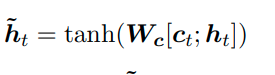
ở timestep tiếp theo bắt đầu với đầu ra của bước đầu tiên (“Be”) và với trạng thái ẩn của bộ giải mã (h5) được tạo ra. Tất cả được thực hiện tương tự như trên.
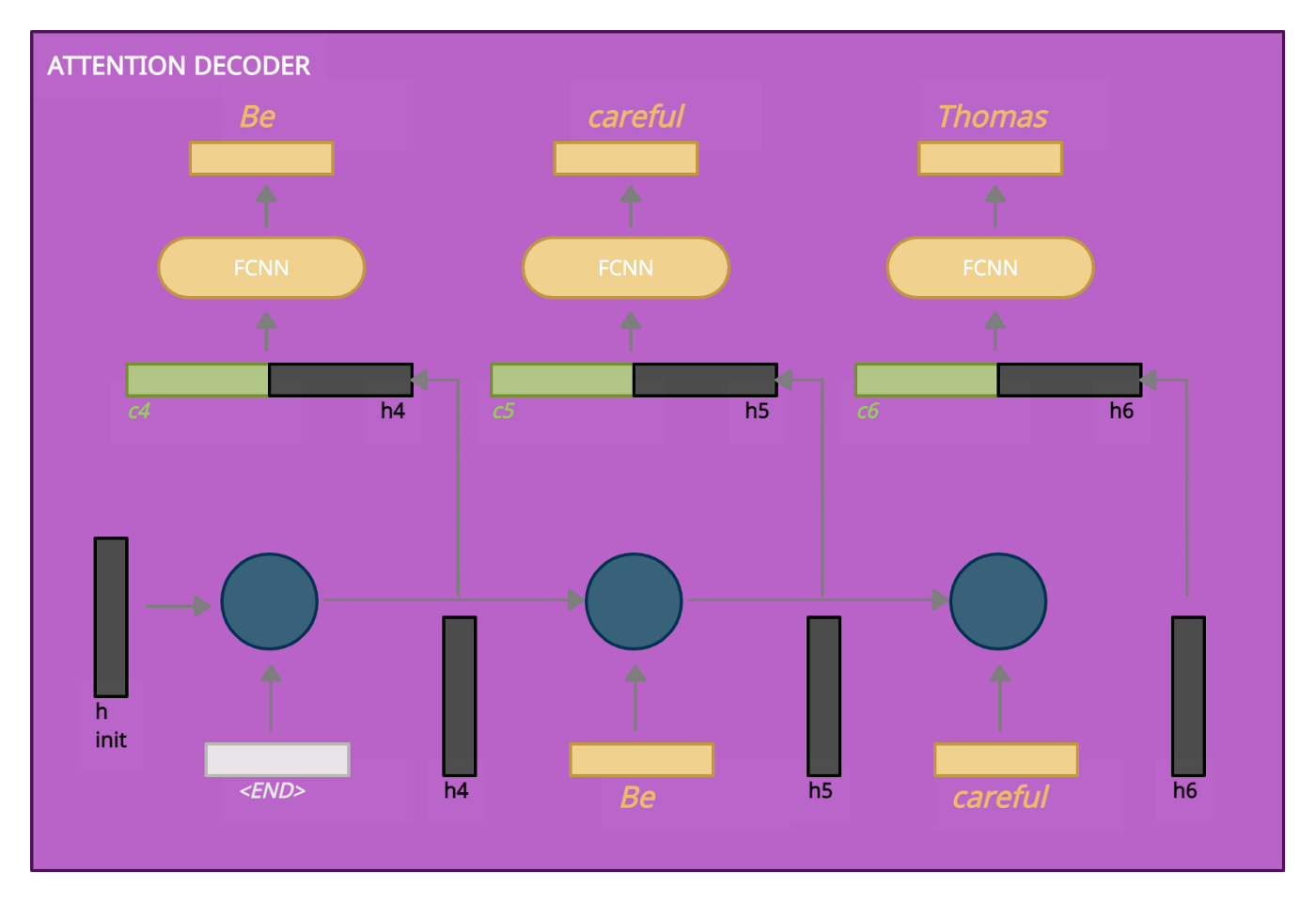 Hình Attention Decoder
Hình Attention Decoder
Kết Luận
Cảm ơn các bạn đã đọc bài viết của mình, mong nhận được sự góp ý của mọi người.
Reference
https://viblo.asia/p/machine-learning-attention-attention-attention-eW65GPJYKDO
https://towardsdatascience.com/classic-seq2seq-model-vs-seq2seq-model-with-attention-31527c77b28a
All rights reserved
