
[AI Interview] 12 câu hỏi phỏng vấn Deep Learning siêu hay không thể bỏ qua
Bài đăng này đã không được cập nhật trong 6 năm
Xin chào các bạn, hôm nay mình sẽ quay lại với các bạn về một chủ đề không mới những chưa bao giờ hết hot. Đó chính là các câu hỏi mà thường được hỏi khi phỏng vấn vị trí AI Engineer là gì?. Thực ra cũng không phải cuộc phỏng vấn nào cũng cần phải dùng đến hết những câu hỏi ở trong này vì còn tuỳ thuộc vào kinh nghiệm và các dự án mà ứng viên đã từng làm qua nữa . Qua rất nhiều cuộc phỏng vấn, đặc biệt là với các bạn sinh viên mình đúc kết ra tập hợp 12 câu hỏi phỏng vấn tâm đắc nhất trong mảng Deep Learning mà ngày hôm nay sẽ chia sẻ lại cho các bạn trong bài viết lần này. Rất mong nhận được nhiều ý kiến đóng góp của các bạn. OK không lan man nữa chúng ta bắt đầu thôi nhé.
1. Trình bày ý nghĩa của Batch Normalization
Đây có thể coi là một câu hỏi rất hay vì nó cover được gần hết các kiến thức mà ứng viên cần phải biết khi làm việc với một mô hình mạng nơ ron. Các bạn có thể trả lời khác nhau nhưng cần làm rõ được các ý chính sau:

Batch Normalization là một phương pháp hiệu quả khi training một mô hình mạng nơ ron. Mục tiêu của phương pháp này chính là việc muốn chuẩn hóa các feature (đầu ra của mỗi layer sau khi đi qua các activation) về trạng thái zero-mean với độ lệch chuẩn 1. Vậy hiện tượng ngược lại đó là non-zero mean có ảnh hưởng như thế nào đến việc training mô hình:
- Thứ nhát có thể hiểu rằng Non zero mean là hiện tượng dữ liệu không phân bố quanh giá trị 0, mà dữ liệu có phần nhiều giá trị lớn hơn không, hoặc nhỏ hơn không. Kết hợp với vấn đề high variance khiến dữ liệu trở nên có nhiều thành phần rất lớn hoặc rất nhỏ. Vấn đề này rất phổ biến khi training các mạng nơ ron với số layer sâu. Việc feature không phân phối trong những khoảng ổn định (giá trị to nhỏ thất thường) sẽ có ảnh hưởng đến quá trình tối ưu của mạng. Vì như chúng ta đã biết việc tối ưu một mạng nơ ron sẽ cần phải sử dụng đến tính toán đạo hàm. Giả sử như một công thức tính layer đơn giản là thì đạo hàm của theo có dạng: . Như vậy giá trị ảnh hưởng trực tiếp đến giá trị của đạo hàm (tất nhiên khái niệm gradient trong các mô hình mạng nơ ron không thể đơn giản như vậy tuy nhiên về mặt lý thuyết thì sẽ có ảnh hưởng đến đạo hàm). Do đó nếu mang các giá trị thay đổi không ổn định dẫn đến đạo hàm sẽ có thể bị quá lớn, hoặc quá nhỏ dẫn đến việc learning model không được ổn định. Và điều đó cũng đồng nghĩa với việc chúng ta có thể sử dụng các learning rate cao hơn trong quá trình training khi sử dụng Batch Normalization.
- Batch normalization có thể giúp chúng ta tránh được hiện tượng giá trị của rơi vào khoảng bão hòa sau khi đi qua các hàm kích hoạt phi tuyển. Vậy nên nó đảm bảo rằng không có sự kích hoạt nào bị vượt quá cao hoặc quá thấp. Điều này giúp cho các weights mà khi không dùng BN có thể sẽ không bao giờ được học thì nay lại được học bình thường. Điều này giúp chúng ta làm giảm đi sự phụ thuộc vào giá trị khởi tạo của các tham số.
- Batch Normalization còn có vai trò như một dạng của regularization giúp cho việc giảm thiểu overfiting. Sử dụng batch normalization, chúng ta sẽ không cần phải sử dụng quá nhiều dropput và điều này rất có ý nghĩa vì chúng ta sẽ không cần phải lo lắng vì bị mất quá nhiều thông tin khi dropout weigths của mạng. Tuy nhiên vẫn nên sử dụng kết hợp cả hai kĩ thuật này
2. Trình bày khái niệm và mối quan hệ đánh đổi giữa bias và variance?
- Bias là gì? Có thể hiểu đơn giản thế này, bias chính là sự khác nhau của giá trị trung bình các dự đoán (average prediction) của mô hình hiện tại với kết quả thực tế mà chúng ta đang cần dự đoán. Mô hình nào có chỉ số bias cao chứng tỏ nó ít tập trung hơn vào dữ liệu huấn luyện. Điều này khiến cho mô hình trở nên quá đơn giản và không đạt được độ chính xác tốt trên cả tập training và tập testing hay hiện tượng này còn được gọi là underfitting
- Variance Có thể hiểu đơn giản là sự phân tán (hay co cụm) của kết quả đầu ra của mô hình trên một điểm dữ liệu. Nếu như varience càng lớn thì chứng tỏ mô hình đang tập trung chú ý nhiều vào dữ liệu huấn luyện và không mang được tính tổng quát trên dữ liệu chưa gặp bao giờ. Từ đó dẫn đến mô hình đạt được kết quả cực kì tốt trên tập dữ liệu huấn luyện, tuy nhiên kết quả rất tệ với tập dữ liệu kiểm thử. Đây chính là hiện tượng overfitting
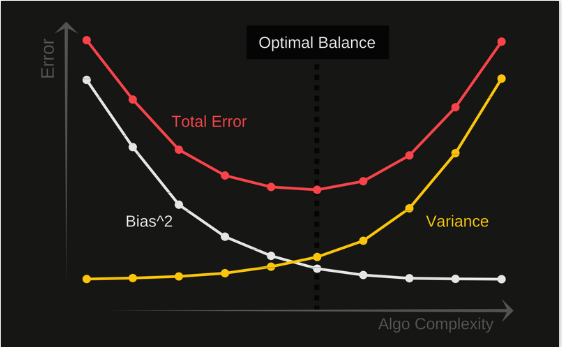
Có thể hình dung sự tương quan qua lại của hai khái niệm này trong hình sau:

Trong sơ đồ trên, trung tâm của hình tròn là một mô hình dự đoán hoàn hảo các giá trị chính xác. Thực tế là chẳng bao giờ các bạn tìm được một mô hình nào tốt như vậy cả. Khi chúng ta càng xa tâm vòng tròn thì dự đoán của chúng ta ngày càng trở nên tồi tệ hơn. Chúng ta có thể thay đổi mô hình để có thể tăng số lượt mô hình dự đoán rơi vào đúng tâm vòng tròn càng nhiều càng tốt. Việc cân bằng giữa hai giá trị Bias và Variance rất cần thiết. Nếu mô hình của chúng ta quá đơn giản và có rất ít tham số thì nó có thể có high bias và low variance. Mặt khác, nếu mô hình của chúng ta có số lượng lớn các tham số thì nó sẽ có high variance và low bias. Đây chính là cơ sở để chúng ta tính toán đến độ phức tạp của mô hình khi thiết kế thuật toán.
3. Giả sử sau mô hình Deep Learning tìm được 10 triệu vector khuôn mặt. Làm sao tìm query khuôn mặt mới nhanh nhất.
Câu hỏi này thiên về việc ứng dụng các giải thuật Deep Learning trên thực tế, điểm mấu chốt của câu hỏi này là phương pháp indexing dữ liệu. Đây là bước sau cùng của bài toán áp dụng One Shot Learning cho nhận diện khuôn mặt nhưng lại là bước quan trọng nhất giúp cho ứng dụng này có thể triển khai dễ dàng trên thực tế. Về cơ bản thì với câu hỏi này các bạn nên trình bày tổng quan về phương pháp nhận diện khuôn mặt bằng One Shot Learning trước. Nó có thể hiểu đơn giản là việc biến mỗi khuôn mặt thành một vector, và việc nhận dạng khuôn mặt mới chính là việc tìm ra các vector có khoảng cách gần nhất (giống nhất) với khuôn mặt đầu vào. Thông thường người ta se sử dụng mô hình deep learning với hàm loss được custom là triplet loss để thực hiện điều đó.

Tuy nhiên với số lượng ảnh tăng lên như đầu bài thì việc tính toán khoảng cách đến 10 triệu vector trong mỗi lần nhận diện là một giải pháp không được thông minh. Khiến cho hệ thống bị chậm đi rất nhiều. Chúng ta cần nghĩ ngay dến các phương pháp indexing dữ liệu trên không gian vector số thực để khiến cho việc truy vấn được thuận lợi hơn. Tư tưởng chính của các phương pháp này đó chính là phân chia dữ liệu thành các cấu trúc dễ dàng cho việc query dữ liệu mới (có thể tương tự cấu trúc cây). Khi có dữ liệu mới, việc truy vấn trên cây sẽ giúp nhanh chóng tìm ra được vector có khoảng cách gần nhất với thời gian rất nhanh chóng.
Có một số phương pháp có thể sử dụng cho mục đích này như Locality Sensitive Hashing - LSH, Approximate Nearest Neighbors Oh Yeah - Annoy Indexing, Faiss .... có thể được sử dụng cho mục đích này
4. Với bài toán classification, chỉ số accuracy có hoàn toàn tin tưởng được không. Bạn thường sử dụng các độ đo nào để đánh giá mô hình của mình ?
Với một bài toán phần lớp thì có nhiều cách đánh giá khác nhau. Riêng đối với accuracy (tức độ chính xác) thì công thức chỉ đơn giản là lấy số điểm dữ liệu dự đoán đúng chia cho tổng số dữ liệu. Điều này nghe qua thì có vẻ hợp lý nhưng trên thực tế đối với những bài toán dữ liệu bị mất cân bằng thì đại lượng này chưa đủ ý nghĩa. Giả sử chúng ta đang xây dựng mô hình dự đoán tấn công mạng (giả sử các request tấn công chiếm khoảng 1/100000 số lượng request) . Nếu mô hình dự đoán tất cả các request đều là bình thường thì độ chính xác cũng lên đến 99.9999% và con số này thường không thể tin tưởng được trong mô hình phân lớp. Cách tính accuracy ở trên thường chỉ cho chúng ta biết được có bao nhiêu phần trăm dữ liệu được dự đoán đúng chứ chưa chỉ ra được mỗi class được phân loại cụ thể như thế nào. Thay vào đó chúng ta có thể sử dụng Confusion matrix. Về cơ bản, confusion matrix thể hiện có bao nhiêu điểm dữ liệu thực sự thuộc vào một class, và được dự đoán là rơi vào một class. Nó có dạng mẫu như sau

Ngoài ra để biểu diễn sự thay đổi của các chỉ số True Possitive và False Positive tương ứng với từng threshold quy định việc phân lớp thì chúng ta có được một đồ thị gọi là Receiver Operating Characteristic - ROC. Dựa trên ROC biết được mô hình có hiệu quả hay không.
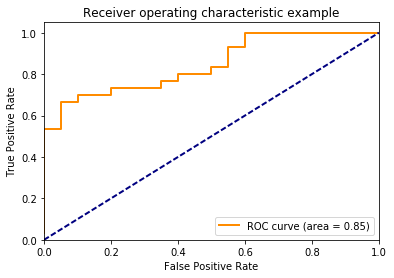
Một đường ROC lý tưởng là đường màu cam càng gần góc trên cùng bên trái (tức True Postitive cao và False Positive thấp) thì càng tốt. Một đại lượng khác để thể hiện độ tốt của mô hình đó là Area Under the Curve chỉ phần diện tích nằm phía dưới của ROC Curve. Diện tích này càng cao chứng tỏ mô hình càng có hiệu quả.
5. Bạn hiểu như thế nào về Backpropagation? Giải thích cơ chế hoạt động?

Câu hỏi này nhầm kiểm tra kiến thức về cách mà một mạng nơ ron hoạt động. Bạn cần phải làm rõ lên được các điểm
- Quá trình forward (tính toán tiến) là quá trình giúp mô hình tính toán các trọng số của từng layers và kết quả sau khi tính toán sẽ cho ra một kết quả . Lúc này sẽ tính toán được giá trị của hàm loss, giá trị của hàm loss sẽ thể hiện được độ tôt của mô hình như thế nào. Nếu thấy hàm loss chưa đủ tốt thì ta cần phải tìm cách làm giảm giá trị hàm loss. Training một mạng nơ ron bản chất là cực tiểu hoá một hàm loss. Hàm loss thể hiện mức độ sai khác giữa giá trị đầu ra của mô hình và giá trí thực của nhãn dữ liệu .
- Muốn giảm giá trị của hàm loss ta cần sử dụng đạo hàm. Back-propagation chính là giúp chúng ta tính toán được đạo hàm cho từng layers của mạng. Căn cứ vào giá trị của đạo hàm trên từng layers thì các optimizer (Adam, SGD, AdaDelta...) áp dụng gradient descent sẽ cập nhật lại trọng số của mạng .
- Backpropagation sử dụng cơ chế chain-rule hay còn gọi là đạo hàm hàm hợp để tính toán giá trị gradient của từng layers kể từ layers cuối cùng đến layer đầu tiên
6. Ý nghĩa của hàm activation function là gì? Thế nào là điểm bão hòa của các activation functions?
Ý nghia của activation function
Hàm kích hoạt hay activation functions được sinh ra với mục đích bẻ gãy sự tuyến tính của mạng nơ ron. Các hàm này có thể hiểu đơn giản như một bộ lọc để quyết định xem thông tin có được đi qua nơ ron hay không. Trong quá trình huấn luyện mạng nơ ron, các hàm kích hoạt đóng vai trò quan trọng trong việc điều chỉnh độ dốc của đạo hàm. Một số hàm kích hoạt giống như sigmoid, tanh hay ReLU sẽ được bàn bạc kĩ hơn trong các phần tiếp theo. Tuy nhiên chúng ta cần hiểu rằng tính chất của các hàm phi tuyến này giúp cho mạng nơ ron có thể học được biểu diễn của các hàm phức tạp hơn là chỉ sử dụng các hàm tuyến tính. Hầu hết các activation functions là các continuous và khả vi differentiable functions Các hàm này là các hàm liên tục (continuous), tức là có sự thay đổi nhỏ ở kết quả đầu ra nếu như đầu vào có sự thay đổi nhỏ và khả vi (differentiable) tức là có đạo hàm tại mọi điểm trong miền xác định của nó. Tất nhiên rồi, như đã đề cập ở phía trên thì việc tính toán được đạo hàm là rất quan trọng và nó là một yếu tố quyết định đến nơ ron của chúng ta có thể training được hay không. Có một số hàm activation function có thể kể đến như Sigmoid, Softmax, ReLU.
Khoảng bão hoà của activation function
Các hàm kích hoạt phi tuyến như hàm Tanh, hàm Sigmoid, hàm ReLU đều có những khoảng bão hoà

Có thể hiểu đơn giản rằng các khoảng bão hoà của hàm kích hoạt là các khoảng mà giá trị đầu ra của hàm không thay đổi mặc dù giá trị đầu vào thay đổi. Có hai vấn đề của khoảng thay đổi đó là trong chiều forward của mạng nơ ron thì những giá trị của layer bị rơi vào khoảng bão hoà của hàm kích hoạt sẽ dần đến có nhiêu giá trị dầu ra giống nhau. Dẫn đến luồng dữ liệu bị giống nhau trong toàn model. Hiện tượng này là hiện tượng covariance shifting. Vấn đề thứ hai là theo chiều backward, đạo hàm sẽ bằng 0 tại vùng bão hoà và do đó mạng gần như sẽ không học được thêm gì. Đó chính là lý do tại sao chúng ta cần đưa khoảng giá trị về mean zero giống như đã đề cập trong phần Batch Normalization
7. Hyperparameters của mô hình là gì? Khác với parameters như thế nào?
Với câu hỏi này mình xin phép được trích lại một đoạn giải thích rất kĩ về vấn đề này trong một bài viết mà mình đã viết từ trước đó. Một vài hiểu nhầm khi mới học Machine Learning
Model parameter là gì
Quay về bản chất của Machine Learning một chút, đầu tiên để làm về học máy chúng ta cần phải có một tập dữ liệu - muốn nói gì thì nói chứ không có dữ liệu chúng ta sẽ lấy cái gì mà học với chả hành đúng không? Sau khi có dữ liệu rôi thì việc cần làm của máy là tìm ra một mối liên hệ nào đó trong cái đống dữ liệu này. Giả sử dữ liệu của chúng ta là thông tin về thời tiết như độ ẩm lượng mưa nhiệt độ... và yêu cầu cho máy thực hiện là tìm mối liên hệ giữa các yếu tố trên và việc người yêu có giận ta hay không giận?. Nghe thì có vẻ không liên quan lắm nhưng việc cần làm của máy học đôi khi là những thứ khá vớ vẩn như vậy đó. Bây giờ giả sử chúng ta sử dụng biến để biểu diễn việc người yêu có giận hay không giận? các biến đại diện cho các yếu tố thời tiết. Chúng ta quy một liên hệ về việc tìm hàm như sau:
Các bạn có thấy các hệ số không? Đó chính là mối liên hệ giữa đống dữ liệu và yếu tố chúng ta đang yêu cầu đó, chính các hệ số này được gọi là Model Parameter đó. Như vậy chúng ta có thể định nghĩa model parameter như sau:
Model Parameter là các giá trị của model được sinh ra từ dữ liệu huấn luyện giúp thể hiện mối liên hệ giữa các đại lượng trong dữ liệu
Như vậy khi chúng ta nói tìm được mô hình tốt nhất cho bài toán thì nên ngầm hiểu rằng chúng ta đã tìm ra được các Model parameter phù hợp nhất cho bài toán trên tập dữ liệu hiện có. Nó có một số đặc điểm như sau:
- Nó được sử dụng để dự đoán đối với dữ liệu mới
- Nó thể hiện sức mạnh của mô hình chúng ta đang sử dụng. Thường được thể hiện bằng tỷ lệ accuracy hay chúng ta gọi là độ chính xác
- Được học trực tiếp từ tập dữ liệu huấn luyện
- Thường không được đặt thủ công bởi con người
Model paramter có thể bắt gặp trong một số dạng như là các trọng số trọng mạng nơ ron, các support vectors trong SVM hay các coefficients trong các giải thuật linear regression hoặc logistic regression...
Model Hyperparameter là gì?
Có lẽ do thời quen thường dịch Hyperparameter là siêu tham số nên chúng ta thường ngầm định nó giống Model Parameter nhưng có phần khủng hơn. Thực ra hai khái niệm này là hoàn toàn tách biệt. Nếu như Model parameter được mô hình sinh ra từ chính tập dữ liệu huấn luyện thì Model Hyperparameter lại hoàn toàn khác. Nó hoàn toàn nằm ngoài mô hình và không phụ thuộc và tập dữ liệu huấn luyện. Như vậy mục đích của nó là gì? Thực ra chúng có một vài nhiệm vụ như sau:
- Được sử dụng trong quá trình huấn luyện, giúp mô hình tìm ra được các parameters hợp lý nhất
- Nó thường được lựa chọn thủ công bởi những người tham gia trong việc huấn luyện mô hình
- Nó có thể được định nghĩa dựa trên một vài chiến lược heuristics
Chúng ta hoàn toàn không thể biết được đối với một bài toán cụ thể thì đâu là Model Hyperparameter tốt nhất. Chính vì thế trong thực tế chúng ta cần sử dụng một số kĩ thuật để ước lượng được một khoảng giá trị tốt nhất (Ví dụ như hệ số trong mô hình k Nearest Neighbor) như Grid Search chẳng hạn.
Sau đây mình xin đưa một vài ví dụ về Model Hyperparameter:
- Chỉ số learning rate khi training một mạng nơ ron nhân tạo
- Tham số và khi training một Support Vector Machine
- Hệ số trong mô hình k Nearest Neighbor
8. Điều gì xảy ra khi learning rate quá lớn hoặc quá nhỏ?
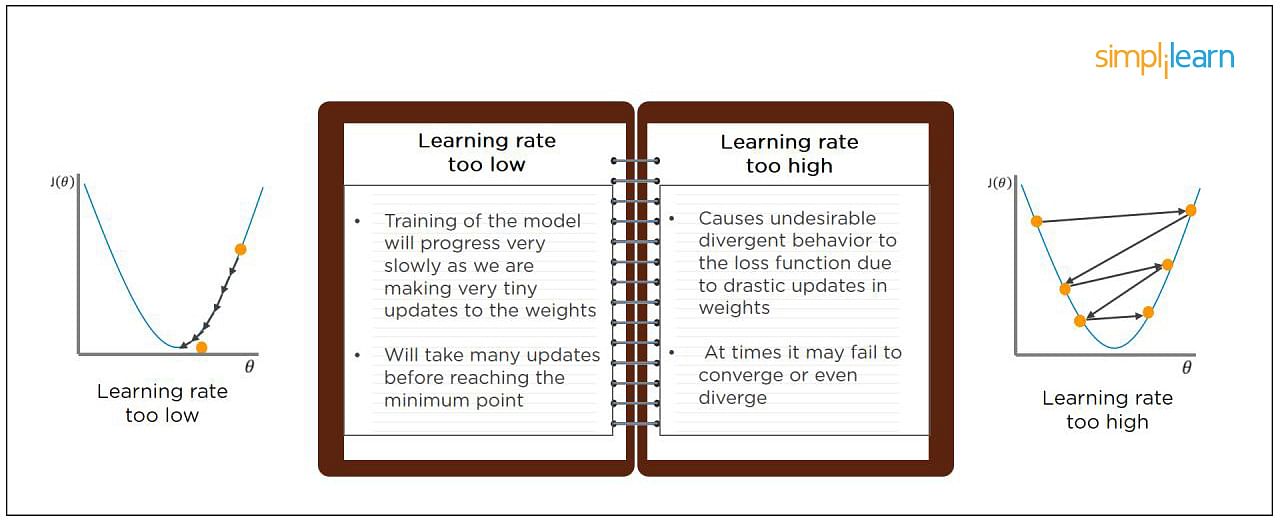
- Khi learning rate của mô hình được đặt quá thấp, việc huấn luyện mô hình sẽ diễn ra rất chậm vì nó phải thực hiện các cập nhật rất nhỏ cho các trọng số. Nó sẽ mất nhiều cập nhật trước khi đạt đến điểm tối ưu cục bộ
- Nếu learning rate được cài đặt quá cao thì khả năng mô hình sẽ khó hội tụ do sự cập nhật quá mạnh của các trọng số mà có thể trong một bước cập nhật trọng số thì mô hình đã vượt qua khỏi tối ưu cục bộ khiến cho các lần cập nhật sau đó mộ hình sẽ khó có thể trở lại điểm tối ưu (có thể tưởng tượng mô hình đang chạy qua chạy lại giữa điểm tối ưu cục bộ do đã nhảy quá xa)
9. Khi kích thước ảnh đầu vào tăng gấp đôi thì số lượng tham số của CNN tăng lên bao nhiêu lần? Tại sao?
Đây là một câu hỏi rất dễ gây hiểu nhầm cho các ứng viên vì đa phần mọi người sẽ bị suy nghĩ theo hướng của câu hỏi rằng số lượng tham số của CNN sẽ tăng lên bao nhiêu lần. Tuy nhiên hãy cùng nhìn lại kiến trúc của mạng CNN
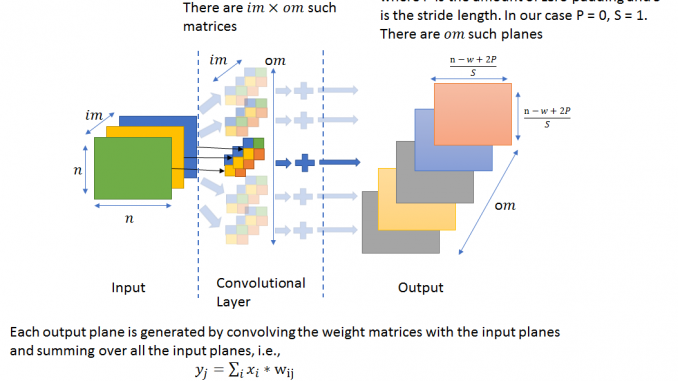
Chúng ta có thể thấy số lượng tham số của mô hình CNN phụ thuộc vào số lượng, kích thước của các filter chứ không phụ thuộc vào ảnh đầu vào. Chính vì thế việc kích thước của ảnh tăng gấp đôi cũng không làm cho số lượng tham số của mô hình thay đổi.
10. Với những tập dữ liệu bị imbalance thì có những cách xử lý nào?
Đây là một câu hỏi kiểm tra việc tiếp cận của ứng viên đối với những bài toán có dữ liệu thực tế. Thông thường dữ liệu thực tế sẽ khác rất nhiều cả về tính chất cũng như số lượng dữ liệu so với các tập dữ liệu mẫu (các tập dữ liệu chuẩn không cần chỉnh). Với tập dữ liệu trên thực tế có thể có một trường hợp là dữ leiuej bị imbalance tức dữ liệu bị mất cân bằng giữa các class. Lúc này chúng ta có thể tính đến các kĩ thuật sau:
- Lựa chọn đúng metric đánh gía mô hình việc đầu tiên là cần phải lựa chọn chính xác metric để đánh gía mô hình với một tập dữ liệu mất cân bằng thì việc sử dụng accuracy để đánh giá là một việc làm rất nguy hiểm như đã trình bày trong các phần trên. Nên lựa chọn các đại lượng đánh giá phù hợp như Precision, Recall, F1 Score, AUC
- Resample lại tập dữ liệu training: Ngoài việc sử dụng các tiêu chí đánh giá khác nhau, người ta cũng có thể áp dụng các kĩ thuật để có được các tập dữ liệu khác nhau. Hai cách tiếp cận để tạo ra một bộ dữ liệu cân bằng từ một mất cân bằng đó là Under-sampling và Over-sampling với các phương pháp như repetition, bootstrapping or SMOTE (Synthetic Minority Over-Sampling Technique)
- Ensemble nhiều mô hình khác nhau: Việc thực hiện tổng quát hoá mô hình bằng cách tạo thêm nhiều dữ liệu không phải lúc nào cũng khả thi trong thực tế. Ví dụ bạn có hai lớp một lớp hiếm có 1000 dữ liệu, một lớp đại trà chứa 10000 mẫu dữ liệu. Vậy thay vì cố gắng tìm được 9000 mẫu dữ liệu của lớp hiếm để thực hiện training một mô hình thì chúng ta có thể nghĩ đến giải pháp training 10 mô hình. Mỗi mô hình được training từ 1000 lớp hiếm và 1000 lớp đại trà. Sau đó sử dụng kĩ thuật ensemble để cho ra kết quả tốt nhất
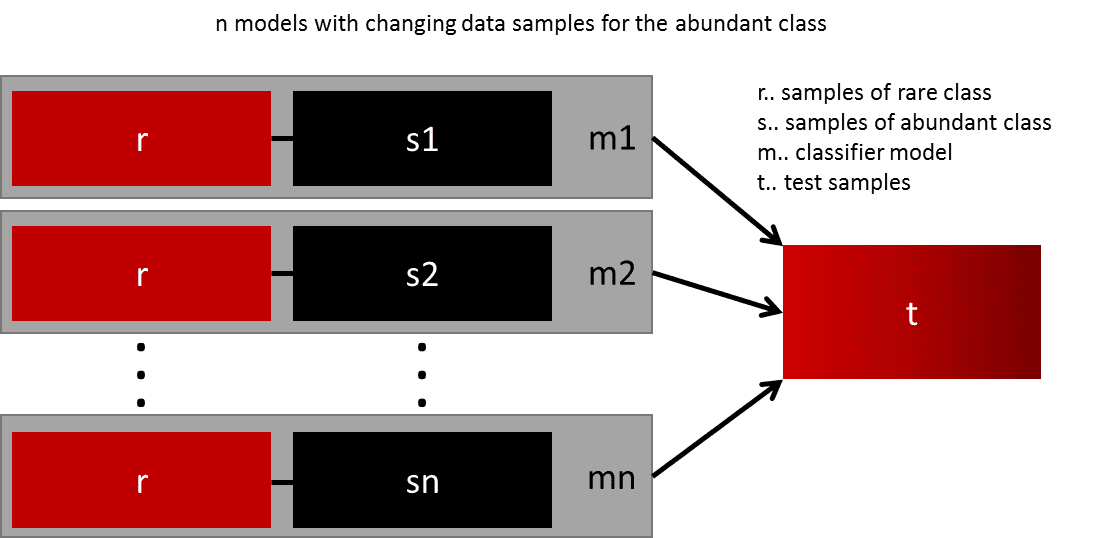
- Thiết kế lại mô hình - cost function: Sử dụng các kĩ thuật penalty để phạt thật nặng các lớp phong phú trong cost function giúp cho bản thân model có khả năng học tốt hơn các dữ liệu của lớp hiếm. Điều này khiến cho giá trị của hàm loss biểu diễn được tổng quảt hơn giữa các lớp.
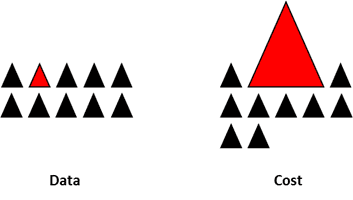
11. Các khái niệm Epoch, Batch và Iteration có ý nghĩa gì khi training mô hình Deep Learning
Đây là các khái niệm rất cơ bản trong khi training một mạng nơ ron nhưng thực tế là có khá nhiều ứng viên bị lúng túng khi phân biệt các khái niệm này. Cụ thể các bạn nên trả lời như sau:
- Epoch - Đại diện cho một lần lặp trên toàn bộ tập dữ liệu (mọi thứ được đưa vào mô hình đào tạo).
- Batch - Đề cập đến khi chúng ta không thể chuyển toàn bộ tập dữ liệu vào mạng nơ ron cùng một lúc, vì vậy chúng tôi chia tập dữ liệu thành một số batch gồm một tập hợp dữ liệu nhỏ hơn .
- Iteration LÀ số batch cần lạp để đi hết một epoch. Giả sử, chúng ta có 10.000 hình ảnh dưới dạng dữ liệu và kích thước của batch (batch_size) là 200. thì một epoch sẽ gồm có 50 Iteration (10.000 chia cho 200).
12. Khái niệm Data Generator là gì? Cần dùng nó khi nào?
Là một khái niệm cũng rất quan trọng trong lập trình, đó là hàm sinh. Hàm sinh dữ liệu giúp cho chúng ta sinh ra trực tiếp dữ liệu để fit vào mô hình trong từng batch training

Việc tận dụng hàm sinh giup ích rất nhiều trong quá trình training các dữ liệu lớn. Vì không phải lúc nào tập dữ liệu cũng cần phải load hết vào RAM gây lãng phí bộ nhớ, hơn nữa nếu như tập dữ liệu quá lớn thì có thể dẫn đên tràn bộ nhớ và thời gian tiền xử lý dữ liệu đầu vào sẽ lâu hơn.
Tổng kết
Trên đây là 12 câu hỏi phỏng vấn về Deep Learning mà mình thường hỏi ứng viên nhất trong quá tình phòng vấn. Tuy nhiên tuỳ thuộc vào mỗi ứng viên mà cách hỏi sẽ khác nhau hoặc cũng có những câu hỏi được hỏi ngẫu hứng từ những bài toán mà ứng viên đã từng làm qua. Mặc dù bài viết là về các vấn đề kĩ thuật nhưng có liên quan đến việc phỏng vấn và quan điểm cả nhân của mình về việc phỏng vấn luôn là thái độ quyết định đến 50% sự thành công của buổi phỏng vấn. Vậy nên ngoài việc tích luỹ cho bản thân mình những kiến thức, kĩ năng cứng thì hãy luôn thể hiện mình với một thái độ chân thành, cầu tiến, khiêm tốn thì chắc chắn các bạn sẽ gặt hái được nhiều thành công trong bất cứ cuộc đối thoại nào. Chúc các bạn sớm đạt được những mong muốn của mình. Xin chào và hẹn gặp lại trong các blog tiếp theo.
All rights reserved
