AI Deployment in Production _ phần 1
Bài đăng này đã không được cập nhật trong 6 năm
Giới thiệu chung
Trong một team AI nhỏ hoặc trong giai đoạn đầu làm POC (Proof of Concepts) để thuyết phục khách hàng, hoặc kiểm chứng business idea, thì đa phần đều dừng lại ở bước prototype, làm một codebase tiếp cận theo dạng monolithic. Rồi sau đó sẽ thực hiện nhanh và dừng lại ở 2 bước:
- Phân tích data và training model
- Chuẩn bị giao diện để demo real-time, hoặc quay video
Tuy nhiên khi chuyển từ prototype sang Production thì chúng ta cần nhiều hơn thế.
Ví dụ về mặt nhân lực:
để làm AI-prototype chúng ta chỉ cần 1 vài bạn AI engineer là đủ để làm 2 task trên, nhưng production thì cần nào là labler, AI deployment, AI infustructure.... (cụ thể vai trò của các bạn này là gì thì mình sẽ dành riêng một post khác để chia sẻ).
Về mặt kĩ thuật:
-
Tổng quan cấu trúc, "hệ sinh thái" mà tensorflow(cụ thể là 2.0) đã xây dựng để hỗ trợ cho production.
....etc (end of thinking capacity
 )
)(đùa chứ có khá nhiều cái trong ... nhưng viết đến đâu mình điền đến đó ứng với mỗi bài post cho dễ )
Mình sẽ mở đầu series bằng 1 bài tóm tắt về course "Advanced Deployment Scenarios with Tensorflow" trên coursera, nếu bạn nào đọc xong overview cảm thấy khá hứng thú thì có thể tự tìm hiểu thêm tại đây.
Phân tích hệ sinh thái tensorflow tạo ra
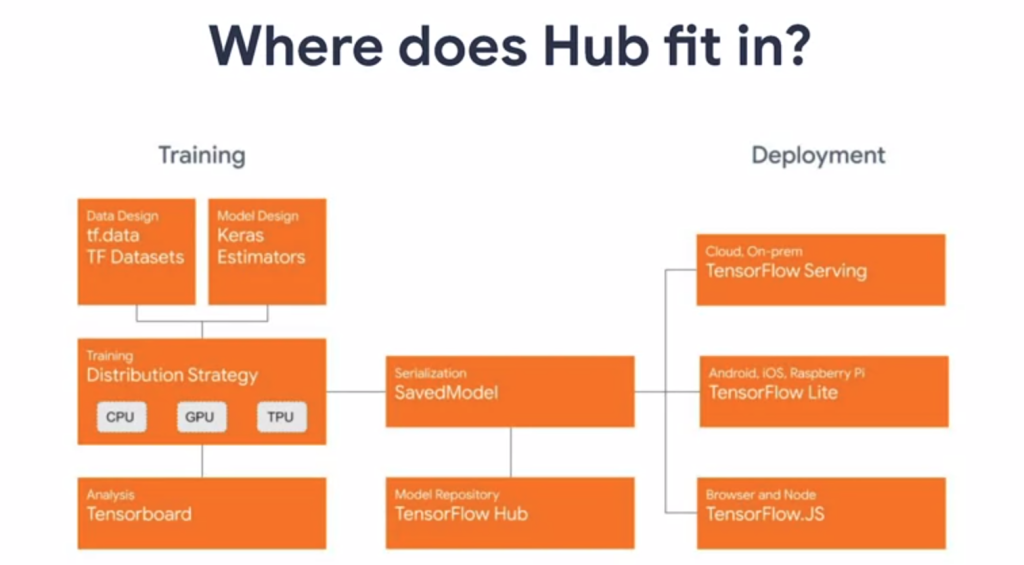
Tóm tắt qua phần Training:
Ở phần này đa số các AI engineer đều làm hàng ngày và có rất nhiều framework để lựa chọn:
-
Chuẩn bị data: chúng ta có thể đưa về đúng format của tf.Dataset rồi sau đó sử dụng những hàng preprocess có sẵn, hoặc customize thêm.
-
Thiết kế model: dựa trên Keras.
-
Hiểu, đánh giá model (week3 của course):
Để hiểu model, visualize kết quả, data thì TensorFlow có hỗ trợ TensorBoard. Với Tensorboard chúng ta có thể visualize rất nhiều thứ (histogram, accuracy, loss, data...) , tất cả những gì chúng ta cần làm là viết 1 function callback (có thể customize bằng cách sử dụng LambdaCallback ), đưa vào model.fit, update theo từng epoch, và bật tensor_board lên để xem. Cũng khá tiện
Phần saving model
Sau khi model được train xong thì chúng ta thường tới buước tiếp theo là optimize model (quantization, prunning, graph optimization, chuyển sang .pb...., mình sẽ chia sẻ trong 1 bài post khác ) và save lại để chuẩn bị cho deployment, hoặc cho người khác xài  .
.
Cái cho người khác xài này tưởng như vô hại nhưng lợi hại vô cùng. Một trong những việc đó chính là sử dụng cho transfer learning (pre-trained model).
Week 2 nói về cách dùng tensorflow Hub, để tải những pretrained model đã được sẵn các công ty lớn như google, facebook, kaggle... upload lên. Cũng như các sample code từ đó có thể download về, tiếp tục train/finetune tiếp, hoặc lấy full model. Cho các bạn muốn tìm hiểu thêm (tensorflow Hub , theo đánh giá của mình thì còn khá ít model, cứ lên git, thấy cái nào hay về mình customize cũng dc.
Phần deployment
Ở phần trên sau khi mình save model xong, thì mình có thể bật server lện chạy model. Khi nào Client cần kết quả thì gửi request về server.
Ở week 1 sẽ giới thiệu về tensorflow Serving, giúp mình thực hiện những mục đích trên với vài dòng lệnh:
- model server sẽ dc khởi chạy = tensorflow_model_server từ tensorflowServing.
- chạy request tới Server này, đưa input vào phù hợp là sẽ có dc output
Example code đây:
# Define đường dẫn model
MODEL_DIR = tempfile.gettempdir()
version = 1
.....
os.environ["MODEL_DIR"] = MODEL_DIR
...
# Server: run in a terminal
nohup tensorflow_model_server \
--rest_api_port=8501 \
--model_name=fashion_model \
--model_base_path="${MODEL_DIR}" >server.log 2>&1
# Client run on another ...
import requests
headers = {"content-type": "application/json"}
json_response = requests.post('http://localhost:8501/v1/models/foo_model:predict', data=data, headers=headers)
predictions = json.loads(json_response.text)['predictions']
Các bạn có thể tìm hiểu toàn bộ sample code tại đây để có thể speed up công việc của mình nhanh nhất có thể.
Mong các bạn tìm được gì đó chắt lọc cho mình qua bài post này. Cám ơn các bạn đã đọc, nếu thấy hay thì tiếp tục đọc qua phần 2 của m nhé.
All rights reserved
