A Tutorial on EDA and Feature Engineering
Bài đăng này đã không được cập nhật trong 7 năm
Trong một bài toán Machine Learning thông thường, có thể nói Feature Engineering là bước quan trọng nhất quyết định đến chất lượng của mô hình dự đoán. Nếu coi mô hình là một cỗ máy, thì dữ liệu nguyên bản (raw data) giống như là dầu thô. Việc đổ "dầu thô" vào thẳng "cỗ máy dự đoán" chắc chắn sẽ mang lại kết quả không tốt. Vì vậy, attributes của dữ liệu nguyên bản cần được tinh lọc thành features trước khi đưa vào thuật toán Machine Learning. Việc tinh lọc này gọi là Feature Engineering.
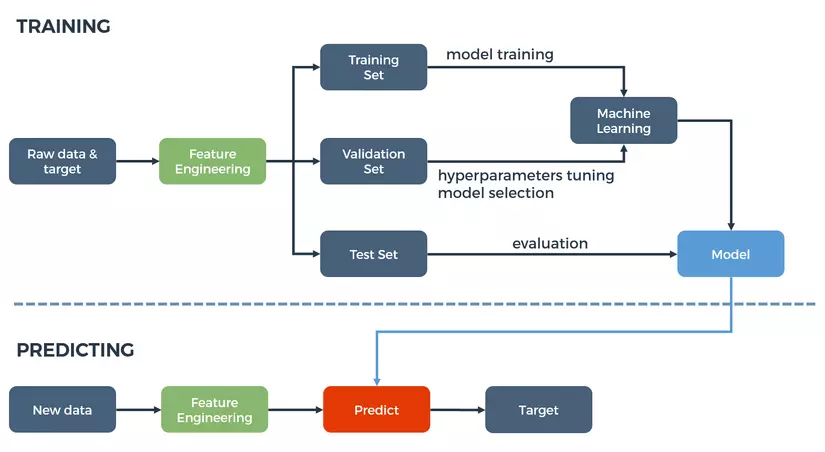
Quy trình thực hiện Feature Engineering gồm những bước nhỏ sau:
- Liệt kê features nhiều nhất có thể
- Quyết định features cần sử dụng
- Tạo ra features từ attributes
- Xác định ảnh hưởng của features lên mô hình
- Cải thiện features
- Quay lại bước 1 cho đến khi giải quyết được bài toán
Tuy nhiên, để có thể chọn lọc ra features từ dữ liệu, chúng ta cần có một cái nhìn toàn cảnh về bộ dữ liệu đó.
"The most difficult thing in life is to know yourself." -- Thales of Miletus
Việc khó nhất trong Data Science/Machine Learning là hiểu được dữ liệu. Có rất nhiều kỹ thuật để phân tích dữ liệu, một trong số đó là EDA.
1. EDA là gì?
Exploratory Data Analysis (EDA) là một phương pháp phân tích dữ liệu chủ yếu sử dụng các kỹ thuật về biểu đồ, hình vẽ.
Khác với statistical graphics, EDA không chỉ tập trung vào một phương diện đặc trưng nào của dữ liệu mà trực tiếp làm dữ liệu tự khám phá ra cấu trúc của nó, đồng thời giúp chúng ta có cơ sở để chọn mô hình trong các bước tiếp theo.
Những kỹ thuật biểu đồ được sử dụng trong EDA thường khá đơn giản, bao gồm một vài kỹ thuật sau:
- Vẽ dữ liệu nguyên bản sử dụng data traces, histograms, block plots, ...
- Vẽ phân bố của dữ liệu nguyên bản sử dụng mean plots, standard deviation plots, box plots, ...
- Sắp xếp các biểu đồ giúp tối đa hoá khả năng tự nhiên về nhận biết mô hình của con người.
2. Phân tích bộ dữ liệu Ames House Prices (Link)
Trong bài tutorial này, chúng ta sẽ áp dụng phương pháp EDA lên bộ dữ liệu Ames House Prices. Đây là bộ dữ liệu về giá nhà ở tại Ames, Iowa, USA dựa trên rất nhiều những tiêu chí đánh giá. Bộ dữ liệu này cũng được sử dụng cho một cuộc thi về Advanced Regression Techniques trên Kaggle.
Trước tiên, chúng ta tiến hành import những thư viện sẽ sử dụng (numpy, pandas, seaborn, scikit-learn). Tutorial này được chạy trên môi trường Python 3.
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.linear_model import LinearRegression
Bộ dữ liệu Ames bao gồm 1460 mẫu trong tập training và 1460 mẫu trong tập testing. Mỗi mẫu có 79 attributes, trong đó 43 attributes là định tính (qualitative) và 36 attributes là định lượng (quantitative). Ngoài ra còn có thêm 2 trường là Id và SalePrice (giá bán nhà cần dự đoán). Đoạn code sau thực hiện việc phân loại attributes.
quantitative = [f for f in train.columns if train.dtypes[f] != 'object']
quantitative.remove('SalePrice')
quantitative.remove('Id')
qualitative = [f for f in train.columns if train.dtypes[f] == 'object']
2.1. SalePrice
Trước khi đi vào phân tích attributes của bộ dữ liệu, ta cần phân tích biến SalePrice. Đây chính là giá trị mà mô hình cần dự đoán. Theo tinh thần của EDA, SalePrice sẽ được mô tả qua histogram.
f, (ax1, ax2) = plt.subplots(1, 2)
f.set_figwidth(15, forward=True)
ax1.set_title('Normal')
sns.distplot(train['SalePrice'], fit=stats.norm, ax=ax1)
ax2.set_title('Log Normal')
sns.distplot(train['SalePrice'], fit=stats.lognorm, ax=ax2)
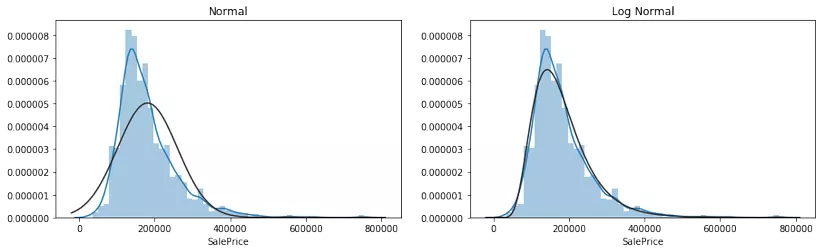
Dễ thấy, phân bố của biến SalePrice không phải là phân bố chuẩn (normal) mà giống với phân bố log-normal. Vì vậy, trước khi đưa vào thuật toán Machine Learning, biến SalePrice cần được biến đổi bằng log transformation.
2.2. Quantitative Attributes
Tương tự, chúng ta kiểm tra phân bố của tất cả các biến định lượng (quantitative) trong bộ dữ liệu.
f = pd.melt(train, value_vars=quantitative)
grid = sns.FacetGrid(f, col='variable', col_wrap=4, sharex=False, sharey=False)
grid = grid.map(sns.distplot, 'value')
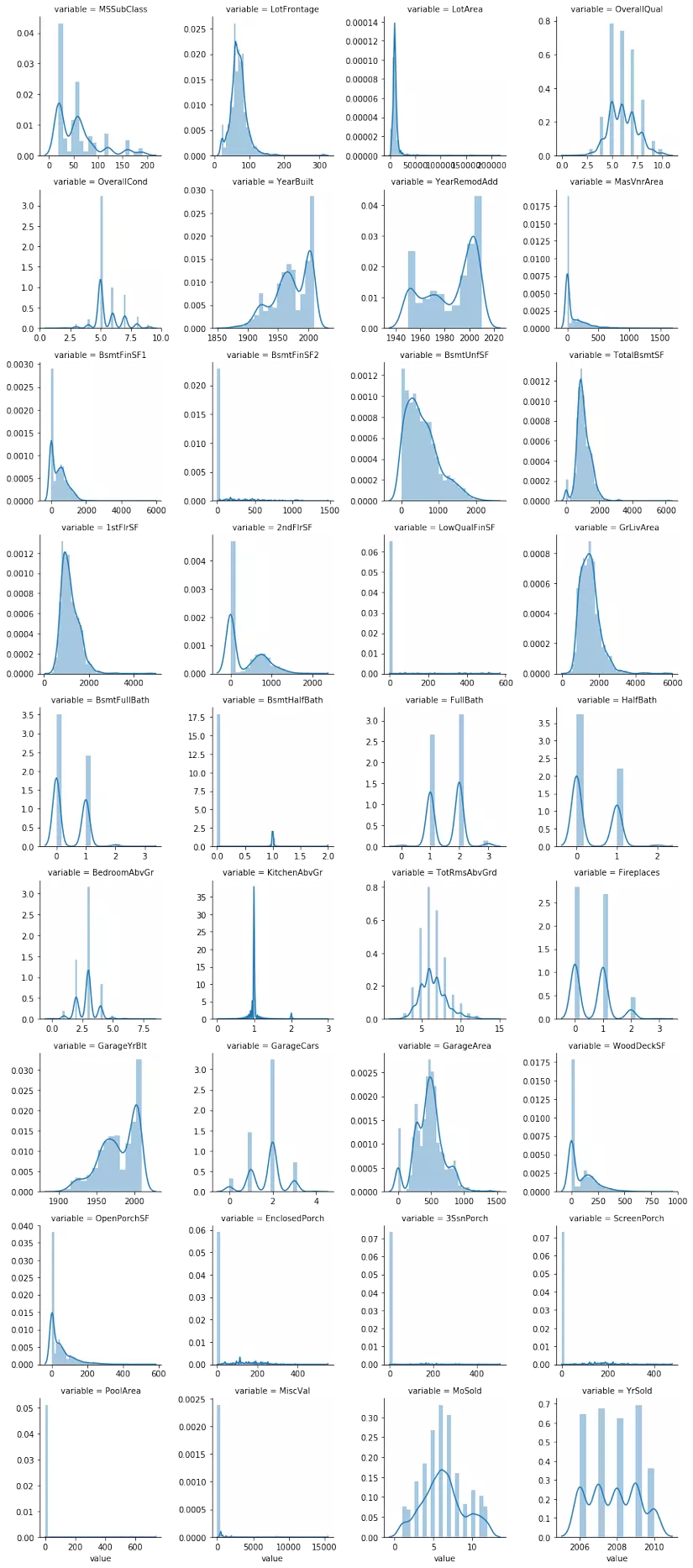
Có thể thấy, có một vài biến cần phải biến đổi log transformation như: TotalBsmtSF, KitchenAbvGr, LotFrontage, LotArea, ... Tiếp theo, chúng ta quan sát quan hệ giữa giá nhà với các giá trị định lượng thông qua biểu đồ scatter plot.
f = pd.melt(train, id_vars=['SalePrice'], value_vars=quantitative)
grid = sns.FacetGrid(f, col='variable', col_wrap=4, sharex=False, sharey=False)
grid = grid.map(plt.scatter, 'value', 'SalePrice')
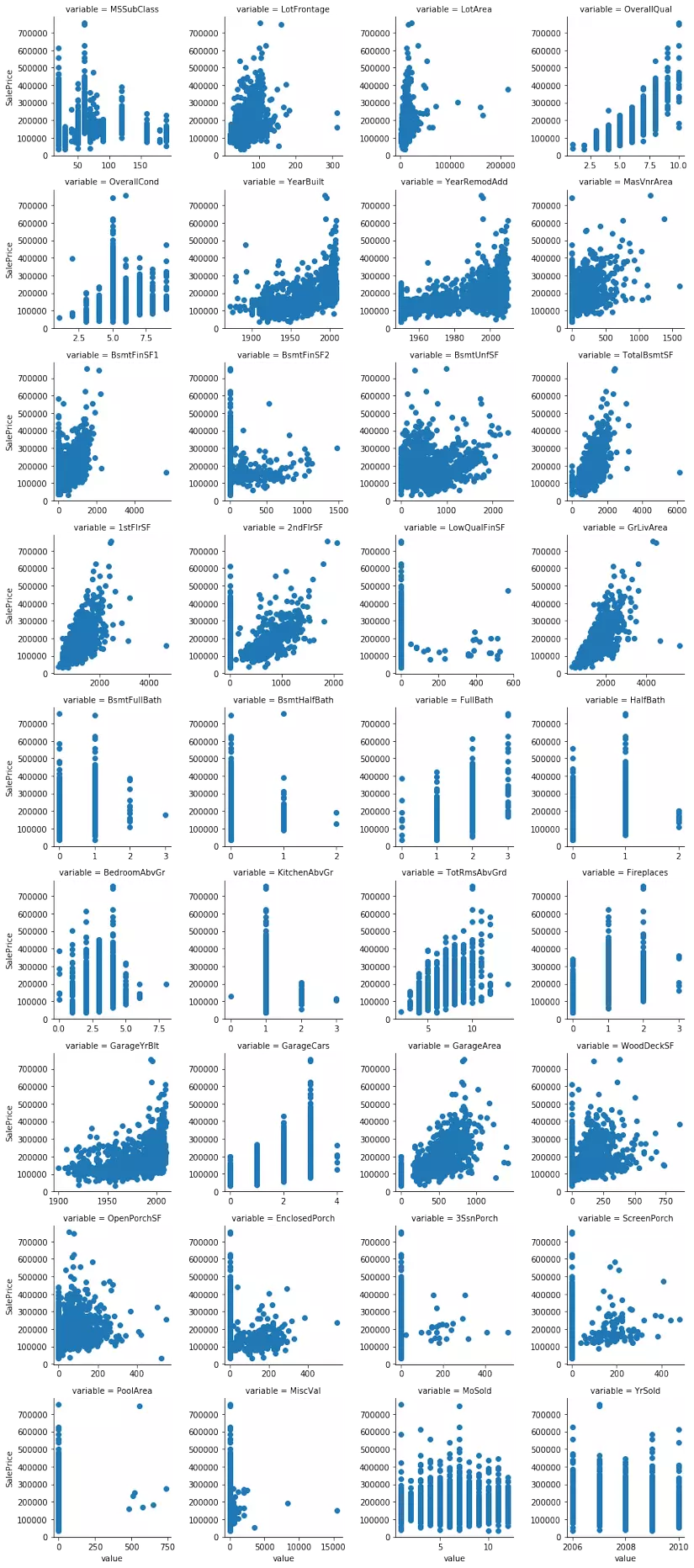
Qua phân tích các scatter plot, các biến như LotFrontage, LotArea, OverallQual, TotalBsmtSF, ... có quan hệ tuyến tính (linear) với SalePrice. Một số biến khác như BsmtFullBath, HalfBath, Fireplaces, ... lại có thể biễu diễn SalePrice thông qua phương trình bậc hai (quadratic equation).
2.3. Qualitative Attributes
Đối với các biến định tính, box plot sẽ được sử dụng để phân tích phân bố của SalePrice đối với từng attribute.
train_nomissing = train.copy()
for c in qualitative:
train_nomissing[c] = train[c].astype('category')
if train_nomissing[c].isnull().any():
train_nomissing[c] = train_nomissing[c].cat.add_categories(['MISSING'])
train_nomissing[c] = train_nomissing[c].fillna('MISSING')
def boxplot(x, y, **kwargs):
sns.boxplot(x=x, y=y)
x=plt.xticks(rotation=90)
f = pd.melt(train_nomissing, id_vars=['SalePrice'], value_vars=qualitative)
g = sns.FacetGrid(f, col='variable', col_wrap=4, sharex=False, sharey=False)
g = g.map(boxplot, 'value', 'SalePrice')
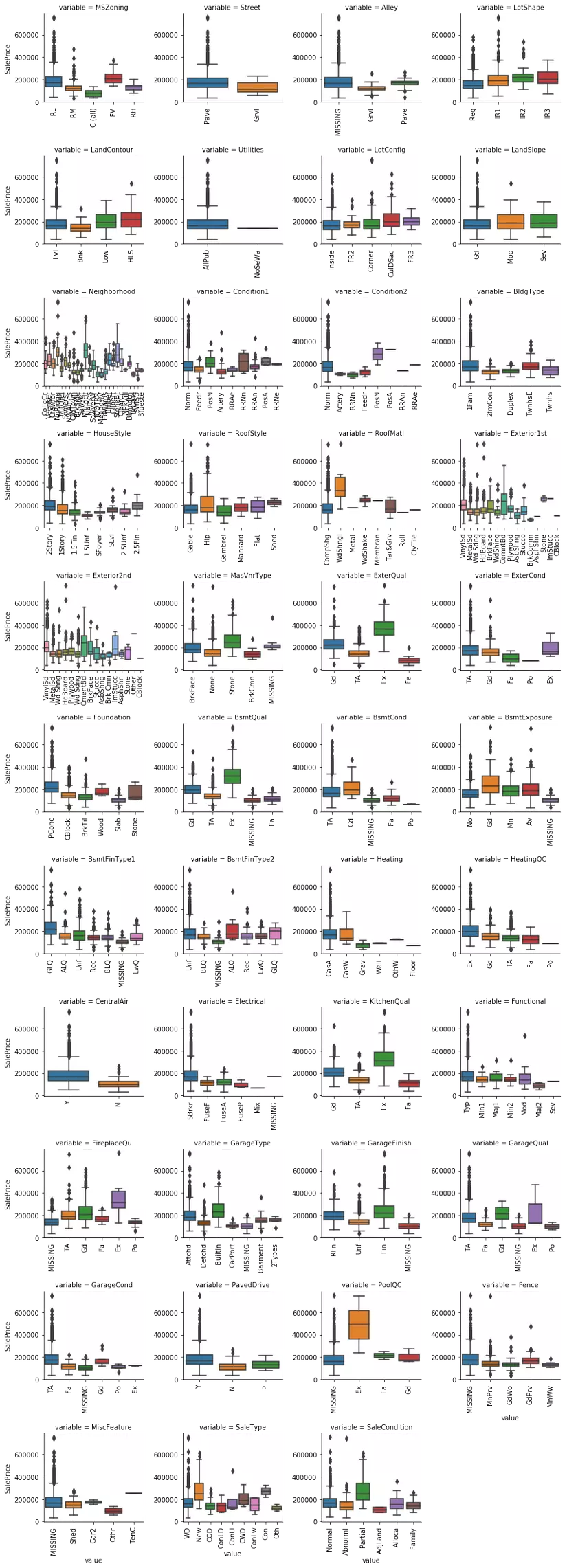
Một số biến thể hiện sự đa dạng rõ rệt của SalePrice so với các biến còn lại, ví dụ như: Neighborhood, SaleCondition, ...
2.4. Correlations
Cuối cùng, chúng ta xem xét mối tương quan giữa các biến của dữ liệu.
# Enumerate categorical variables
def encode(frame, feature):
ordering = pd.DataFrame()
ordering['val'] = frame[feature].unique()
ordering.index = ordering.val
ordering['spmean'] = frame[[feature, 'SalePrice']].groupby(feature).mean()['SalePrice']
ordering = ordering.sort_values('spmean')
ordering['ordering'] = range(1, ordering.shape[0]+1)
ordering = ordering['ordering'].to_dict()
for cat, o in ordering.items():
frame.loc[frame[feature] == cat, feature+'_E'] = o
qual_encoded = []
train_encoded = train.copy()
for q in qualitative:
encode(train_encoded, q)
qual_encoded.append(q + '_E')
qual_encoded.append('SalePrice')
# Draw correlation matrices
cmap = sns.cubehelix_palette(light = 0.95, as_cmap = True)
plt.figure(figsize = (10, 10))
sns.heatmap(abs(train.drop(['Id'], axis=1).corr(method = 'pearson')), vmin = 0, vmax = 1, square = True, cmap = cmap)
plt.figure(figsize = (10, 10))
sns.heatmap(abs(train_encoded[qual_encoded].corr(method = 'pearson')), vmin = 0, vmax = 1, square = True, cmap = cmap)
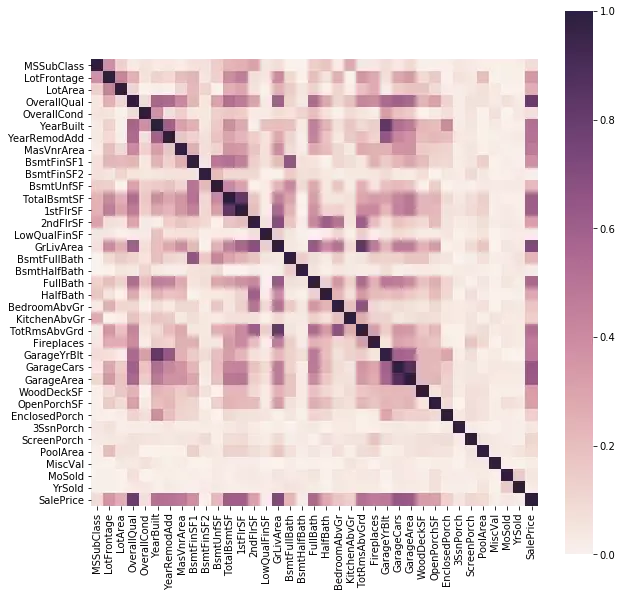
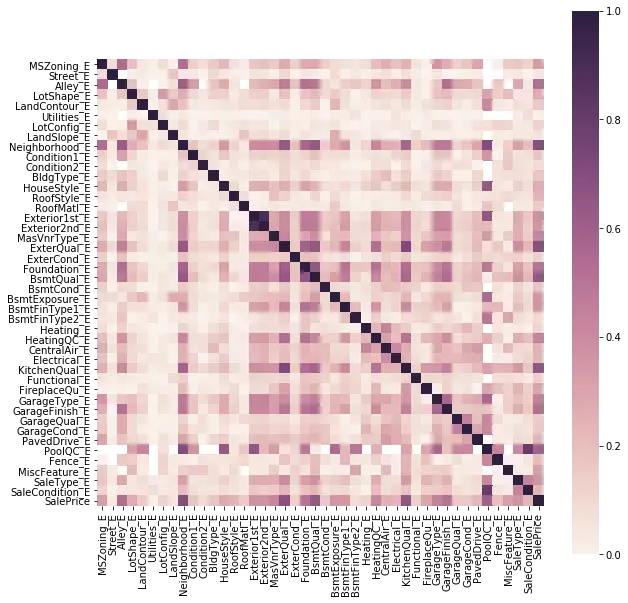
Trong Corretion Matrix trên, chúng ta thấy có một số biến có tương quan rõ rệt với nhau như họ các biến Garage hay họ các biến Bsmt. Do đó, có thể lược bỏ một số biến để làm giảm độ phức tạp của mô hình mà không làm ảnh hưởng quá nhiều đến hiệu suất.
3. Kết luận
Thông qua bài viết và ví dụ trên, chúng ta đã phần nào hiểu được tầm quan trọng cũng như quy trình thực hiện phân tích dữ liệu EDA trước khi đưa dữ liệu vào Feature Engineering. Việc lựa chọn features đúng và tốt sẽ giúp chất lượng mô hình dự đoán được cải thiện đáng kể.
4. Tài liệu tham khảo
All rights reserved
