0
Cách sử dụng Detectron2 cho Object detection
Chào mọi người mình đang học về Object detection và đang định chuyển sang dùng Detectron2. Không giống như trên pytorch bình thường mình thấy detectron nó chạy khó hiểu ngay cả dùng debug để đọc code thì mình vẫn không hiểu được nó chạy như nào.
Có bạn nào biết về phần này không ạ chỉ cho mình mấy đường cơ bản với ạ TT. Nản quá rồi ạ. Xin các cao nhân chỉ giáo ạ.
Thêm một bình luận
1 CÂU TRẢ LỜI
+1
Hello bạn, bạn follow guide này nhé, mình có dùng với bài toán segmentation là chính nhưng có sử dụng pretrain segment+OD đều trả ra kết quả OD
https://viblo.asia/p/state-of-the-art-instance-segmentation-chi-vai-dong-code-voi-detectron2-vyDZO7W9Zwj https://viblo.asia/p/face-detection-on-custom-dataset-using-detectron2-in-google-colab-Az45bDrzZxY
Hoặc xem tut của fb cho chuẩn https://colab.research.google.com/drive/16jcaJoc6bCFAQ96jDe2HwtXj7BMD_-m5
Example train segmen/OD tập hóa đơn:

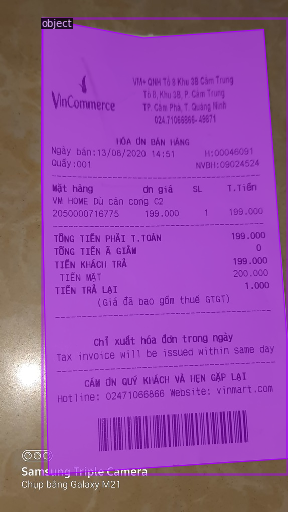
cảm ơn bạn ạ. đọc những bài này mình thấy hiểu hơn rồi ạ. Mình muốn sử dụng KITTI dataset, và BDD100K để object detection trên detectron. bạn có cách nào để load 2 dataset này không ạ.
Mình muốn sửa dùng dùng Architecture của mình trên Detectron2 nữa ý ạ. Bạn có biết làm như nào không ạ.
@Golden_Dragon Hi bạn
Để load dataset thì bạn có thể viết hàm custom lại Dataloader, trong Detectron2 thì có thể register với DatasetCatalog/MetadataCatalog. Docs tham khảo thêm tại đây
https://detectron2.readthedocs.io/en/latest/tutorials/datasets.html
Dưới này là sample tham khảo mình viết cho file annotation COCO format
def get_data_dicts(img_dir, train = False):
json_file = os.path.join(img_dir, "annotations.json")
with open(json_file) as f:
imgs_anns = json.load(f)
dataset_dicts = []
img_dir = img_dir + "train_images"
for idx, v in enumerate(imgs_anns.values()):
record = {}
filename = os.path.join(img_dir, v["filename"])
height, width = cv2.imread(filename).shape[:2]
record["file_name"] = filename
record["image_id"] = idx
record["height"] = height
record["width"] = width
annos = v["regions"]
objs = []
for annotation in annos:
px = annotation["shape_attributes"]["all_points_x"]
py = annotation["shape_attributes"]["all_points_y"]
poly = [(x , y) for x, y in zip(px, py)]
poly = [p for x in poly for p in x]
obj = {
"bbox": [np.min(px), np.min(py), np.max(px), np.max(py)],
"bbox_mode": BoxMode.XYXY_ABS,
"segmentation": [poly],
"category_id": 0
}
objs.append(obj)
record["annotations"] = objs
dataset_dicts.append(record)
dataset_train, dataset_test = train_test_split(dataset_dicts, test_size=0.15, random_state=42)
if train:
return dataset_train
else:
return dataset_test
from detectron2.data import MetadataCatalog, DatasetCatalog
var_train = "segtrain1"
DatasetCatalog.register(var_train, lambda:get_data_dicts("train_data/", train = True))
MetadataCatalog.get(var_train).set(thing_classes=["object"])
object_metadata = MetadataCatalog.get(var_train)
Sửa architecture thì có 2 cách:
- Register backbone mới và custom lại các hàm function/loss: https://detectron2.readthedocs.io/en/latest/tutorials/write-models.html (khuyến khích). Mình đã thay được tuy nhiên giới hạn một vài module
- Thay backbone và import lại các module của detectron2
Hy vọng giúp đỡ được bạn ^_^
