Ngoc N Tran
@ngoctnq
Báo cáo
file python
Ngoc N Tran
Đã trả lời thg 7 4, 2021 1:36 CH
Nếu bạn muốn vừa viết vừa đọc một file thì cần mở với mode='w+' nhé.
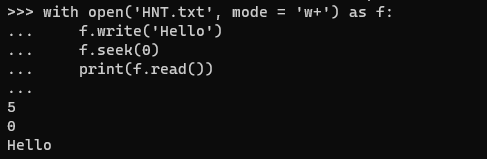
Bạn có thể tham khảo thêm về file open mode tại https://docs.python.org/3/library/functions.html#open
Thuật toán liệt kê các chuỗi khác nhau từ các kí tự ban đầu
Ngoc N Tran
Đã trả lời thg 5 24, 2021 4:43 SA
Nếu bạn dùng Python thì khá đơn giản:
from itertools import product
for chars in product('ABCDEFGHIJKL', repeat=7):
print(''.join(chars))
Còn không thì có cách khác  Đó là để ý mỗi chữ cái có 12 trường hợp, giống như các số base-12:
Đó là để ý mỗi chữ cái có 12 trường hợp, giống như các số base-12:
def i2b12(i: int):
res = [0] * 7
for idx in range(7):
res[6 - idx] = i % 12
i //= 12
return res
for i in range(12 ** 7):
print(''.join('ABCDEFGHIJKL'[x] for x in i2b12(i)))
Bạn có thể optimize bằng cách tăng dần idxs mà không phải tính lại base-12 representation mỗi lần, nhưng nó lằng nhằng nên sẽ để bạn tự tìm hiểu
kdevtmpfsi using the entire CPU
Ngoc N Tran
Đã trả lời thg 3 11, 2020 11:54 SA
Chúc mừng, bạn đã bị hack và bị cài một cryptominer
Hãy chạy đoạn code sau:
docker stop <tên_redis_container>
find / -iname kdevtmpfsi --exec rm -fv {} \;
docker start <tên_redis_container>
Dòng đầu và cuối thì chỉ là khởi động lại container thôi, còn dòng giữa là lấy vị trí của con cryptominer đó bằng find rồi rm nó. Bạn cũng có thể dùng dòng 2 với file kinsing luôn theo như các link ở dưới kia chỉ, và có thể tạo file bù nhìn lấp chỗ đó.
Sau đó, bạn nên không để lộ cổng Redis public (nếu có thì cần thêm cài đặt iptables), và đặt password cho chắc kèo.
Nguồn tham khảo:
https://github.com/docker-library/redis/issues/217
https://github.com/laradock/laradock/issues/2451
Mình cũng chỉ tìm ra đáp án này bằng Google; sau bạn cũng có thể Google trước khi hỏi nhé.
Xác suất thống kê
Ngoc N Tran
Đã trả lời thg 2 21, 2020 10:00 SA
Vì cả 2 chuỗi cùng random, em có thể giả sử A, B bất kỳ cố định. Hãy nghĩ bài này như một vấn đề trong dynamic programming/induction: định nghĩa là xác suất bits cuối của chuỗi B là substring của bits cuối của chuỗi A. Do cả 2 chuỗi cùng random, xác suất 1 bit bất kỳ của A bằng với 1 bit bất kỳ của B là 0.5. Sử dụng điều đó với Bayes' Rule và greedy matching, ta có:
với phần tử đầu tiên tương ứng với trường hợp chữ cái bên chuỗi A giống với chữ cái bên chuỗi B, và phần tử sau là ngược lại. Cùng lúc, ta có base case , bởi vì xác suất một chuỗi với độ dài là substring của một chuỗi khác cùng độ dài chính là xác suất 2 chuỗi bằng nhau. 2 công thức trên có quen thuộc không -- vì nhìn vào đó em có thể ra luôn công thức closed-form cuối cùng đó:
How to use Auto Encoder for Unsupervised Learning Models?
Ngoc N Tran
Đã trả lời thg 1 18, 2020 3:44 SA
On the most basic level, you would have an Encoder-Decoder pair. You would pass your unlabeled data through the Encoder and the Decoder in that order, and the expected output is the input itself — train that dual network so the output is as close to the input as possible. If the Encoder is bottlenecking, i.e. the encoded output is much smaller in size than the input, then one can say it has effectively extracted the key features from the input data. Now you can do all sorts of things with those extracted features, for example: use those features for classification, or add some perturbation to those features and pass through the Decoder to get some fun deformities, and so on.
Hỏi về host để lưu project | live demo
Ngoc N Tran
Đã trả lời thg 11 19, 2019 7:50 SA
Như mình biết thì Github Pages chỉ hỗ trợ host các trang web tĩnh thôi. Còn nếu muốn demo được, hãy thử một số trang như
Free:
- PythonAnywhere (có shell nên chắc chạy được ngoài Python, mình chưa thử)
- Heroku (hình như project đầu tiên free?)
Free cho cỡ nhỏ (free tier, hình như cần thông tin thẻ tín dụng trong trường hợp tiêu lẹm):
- Google Cloud Platform
- Amazon EC2
lấy dữ liệu sử dụng pandas
Ngoc N Tran
Đã trả lời thg 10 21, 2019 9:56 SA
Khi bạn sử dụng dropna(), pandas sẽ trả lại cho bạn một cái bảng mới không có NaN và không sửa thẳng vào bảng cũ. Vậy nên, khi bạn print lại, bảng cũ sẽ vẫn có NaN.
Để tránh việc này, bạn có thể viết đè lên bảng cũ:
a = a.dropna()
hoặc sử dụng lựa chọn có sẵn của pandas:
a.dropna(inplace=True)
lưu ý: trong code của bạn hiện tại đang thiếu một dấu xuống dòng trước dòng print. đồng thời, bạn có 3 dòng print mà output ngắn quá, bạn có đang copy thiếu gì không?



