XỬ LÝ MULTI-PROCESS VỚI FORK()
Bài đăng này đã không được cập nhật trong 11 năm
Bài viết này được thực hiện từ năm 2012 với Ruby 1.9 và AR 3.x. Trên Ruby 2.x trở đi, Threadsafe là mặc định nên sẽ có một vài thông tin đã trở nên không cần thiết.
Related: THREADING IN RAILS
What is fork() on Unix
fork là 1 cách xử lý multi-process trong Unix, hoạt động theo kiểu sinh ra các tiến trình con xử lý nhiều process bằng cách copy chính nó thông qua hàm fork(). Kết quả của tiến trình con là 0, trong khi kết quả của tiến trình cha là PID của tiến trình con. (1)
Ruby on Rails có thể sử dụng fork() như 1 cách để xử lý multi-process, khi mà multi-thread vẫn chưa được ActiveRecord hỗ trợ tốt nhất.
Advantages
-
Không phải quan tâm đến thread-safe
fork là kỹ thuật kiểu pipeline (2) nên sẽ không bị ảnh hưởng bởi việc hệ thống có thread-safe hay không. Trong 1 pipeline, chỉ xử lý 1 process, và hoàn toàn độc lập, không share thông tin với pipeline khac, vì thế sẽ không có khả năng gặp deadlock như multi-thread.
2. ### Copy – on – write
Với xử lý pipeline thông thường, bộ nhớ của tiến trình cha (parent) và của tiến trình con (child) là độc lập, và hoàn toàn không được chia sẻ. Còn với fork(), thuật ngữ copy-on-write mô tả việc nó sử dụng bộ nhớ : sau khi child được sinh ra, bộ nhớ của parent và child được chia sẻ, và child sẽ chỉ phải sử dụng thêm 1 phần nhỏ bộ nhớ để hoàn thành công việc của riêng nó, như vậy tổng bộ nhớ bị chiếm sẽ chỉ là bộ nhớ của parent và thêm 1 phần nhỏ để child hoàn thành công việc riêng.
Ta có thể so sánh giữa multi-process thông thường và multi-process sử dụng fork() qua biểu đồ sau(5)

> Without prefork: usage = parent * n
> With prefork: usage = parent + child * n
-
Keep running
Sử dụng kỹ thuật pipeline, nên khi fork() 1 tiến trình, phần bộ nhớ được cung cấp cho nó là cố định, và sẽ do nó sở hữu cho tới khi pipeline kết thúc. Lợi dụng điểm này ta có thể sử dụng fork() cho Background Job hay Delayed Job mà không sợ tiến trình sẽ chết giữa chừng do 1 sự kiện nào đó phía ngoài pipeline.
Một số gem tiêu biểu cho việc chạy BJ và DJ trên Rails như : spawn(3), resque(4)
4. ### Easy to use
Ở những kỹ thuật khác có cùng 1 mục tiêu xử lý nhiều thứ trong cùng 1 thời gian, việc quản lý các process/thread sinh ra phải tuân thủ nghiêm ngặt nhiều chuẩn. Với fork(), do sử dụng phương pháp pipeline và được ActiveRecord hỗ trợ rất tốt nên việc quản lý dễ dàng hơn nhiều. Điều cần quan tâm chỉ là quản lý tương quan giữa số lượng pipeline với memory và việc bắt đầu/kết thúc pipeline.
How to use fork() in Ruby on Rails
-
How to use
Sử dụng fork() trong Rails khá đơn giản, bởi được ActiveRecord hỗ trợ nhiều nên không cần phải config nhiều thứ:
@fork_poll = 10
(1..@fork_poll).each do |i|
fork do
# Something goes here
end
end
results = Process.waitall
Điều đáng lưu ý khi sử dụng fork() là việc tính toán @fork_poll sao cho khi chạy ở mức lớn nhất, memory của hệ thống vẫn đủ đáp ứng.
2. ### A test with fork()
Làm 1 phép thử với connection như sau để có thể thấy được fork() hoạt động và tiết kiệm tài nguyên như thế nào:
# Connection
def fork_new_connection
config = ActiveRecord::Basease.remove_connection
pid = fork do
success = true
begin
ActiveRecord::Base.establish_connection(config)
srand
yield
rescue Exception => exception
puts (" Forked operating failed with exception " + exception)
success = false
ensure
ActiveRecord::Base.remove_connection
Process.exit! success
end
end
ActiveRecord::Base.establish_connection(config)
return pid
end
# Test function
def test(x)
@@failed = 0
@@fork_poll = x
(1..@@fork_poll).each do |i|
pid = fork_new_connection do
x = rand[10]
puts "Fork #{i} \n"
ActiveRecord::Base.connection.reconnect!
puts " Hello world ! \n"
sleep 30
puts " Fork #{i} completed \n"
end
puts " Process #{pid} excuted \n"
end
results = Process.waitall
results.each{ |s| @@failed += s[1].exitstatus }
puts @@failed
end
This code base on bowerstudios.com (7)
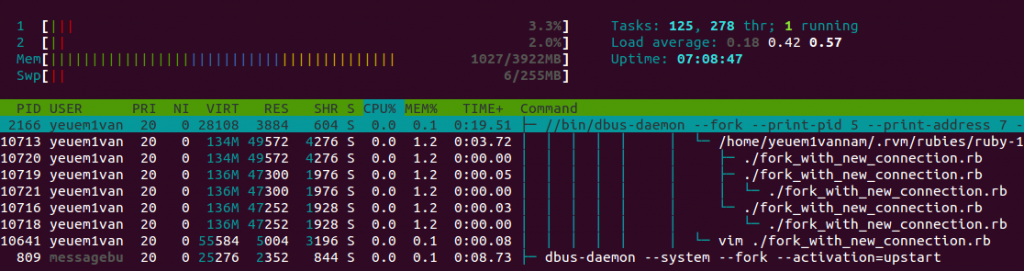
Để thực hiện test, ta có thể dùng 1 trình monitor hệ thống đơn giản như htop.
Chạy test() với x = 1, chúng ta sẽ biết 1 connection chiếm bao nhiêu bộ nhớ, ở đây 1 connection chiếm khoảng 50MB bộ nhớ
Khi chạy test() với x = 2, nếu không dùng fork() thì 2 connection sẽ chiếm 100MB, nhưng thực tế khi sử dụng fork(), 2 connection chỉ chiếm 60MB.
Hiển thị trên htop cho ta thấy có 2 connection “con” chạy song song với 1 connection “cha” -> 1 connection “con” chiếm khoảng 5MB bộ nhớ
 Làm test tương tự với
Làm test tương tự với x=10, bộ nhớ chỉ bị chiếm khoảng 100MB, tức là tiết kiệm gấp 5 lần so với không dùng fork()
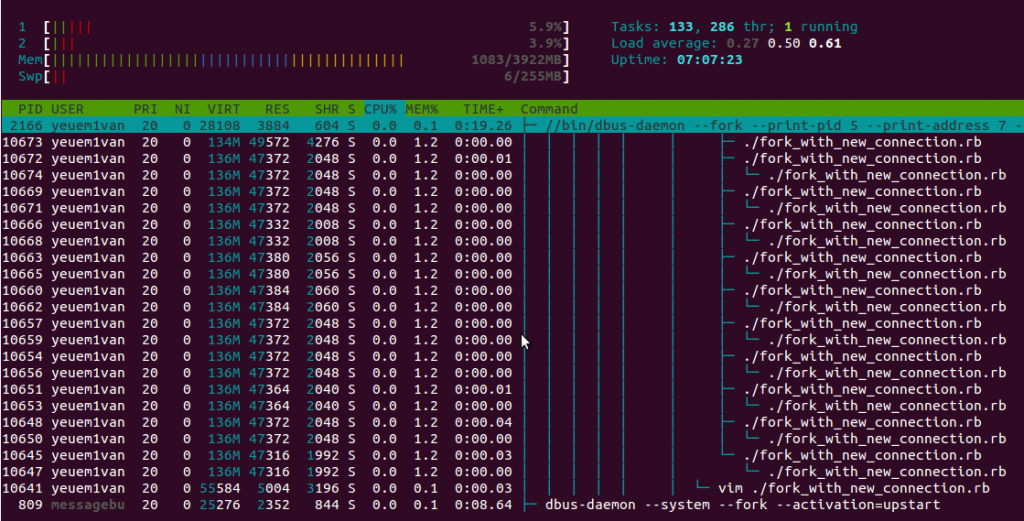 Với test đơn giản này, ta đã có thể hiểu rõ ràng hơn về khả năng
Với test đơn giản này, ta đã có thể hiểu rõ ràng hơn về khả năng copy-on-write của fork()
Disadvantages
Khả năng copy-on-write của fork() khiến nó tiết kiệm được rất nhiều không gian nhớ, nhưng so với thread thì fork() vẫn chiếm bộ nhớ nhiều hơn, và không có khả năng giải phóng bộ nhớ khi các fork() đang chạy (pipeline)
Cũng bởi fork() là pipeline, nên sẽ khó debug với 1 process đã được fork(), và chỉ có thể xử lý hữu hạn số fork() trong 1 thời điểm. Số lượng này quyết định bởi khả năng của hệ thống.
1 điều không vui cho các hệ thống base on Windows : fork() không chạy được trên Windows, chỉ có thể chạy trên các nền tảng Unix có fork()
Conclusion
fork() có một số điểm khá tương đồng với thread, nhất là khả năng tiết kiệm tài nguyên. Nhưng do hiện tại thread chưa được ActiveRecord hỗ trợ đầy đủ, nên fork() được sử dụng nhiều hơn. Được phát triển từ lâu trên Unix, fork() được ActiveRecord hỗ trợ mạnh nên rất an toàn khi sử dụng, hoàn toàn có thể triển khai thực tế với AR 3.x
References
All rights reserved
