
Xử lý missing data trong Data analysis
Bài đăng này đã không được cập nhật trong 6 năm
Hello mn lại thêm một tháng nữa trôi qua =))), hôm nay mình sẽ chia sẻ về handle với Missing data trong data analysis. Như mọi người đã và đang làm việc với dữ liệu thực tế thì vấn đề missing data khá là phổ biến, vì vậy việc giải quyết vấn đề missing value là cần thiết để góp phần giúp cho bài toán của chúng ta được cải thiện một cách đáng kể hơn. Trong bài viết lần này mình sẽ trình bày một số cách giải quyết vấn đề này.
Những kiểu missing data
Để giải quyết vấn đề này thì cũng ta phải hiểu loại giá trị missing của data mình có. Có 3 loại missing data sẽ được trình bày ở dưới đây:
Missing at Random - Dữ liệu khuyết ngẫu nhiên
Sự mất mát dữ liệu ở đây là ngẫu nhiên, tuy nhiên vẫn có mối quan hệ hệ thống giữa dữ liệu bị mất và dữ liệu được quan sát. Ví dụ ở hình 1 những người trẻ tuổi bị khuyết dữ liệu về IQ, có nghĩa là có một mối quan hệ hệ thống giữa biến IQ và biến tuổi.
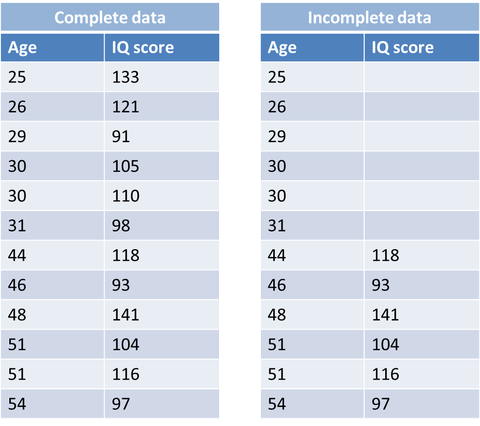
Hình 1: Ví dụ về MAR
Missing Completely at Random - Dữ liệu thiếu hoàn toàn ngẫu nhiên
Như tên gọi của nó đã nói lên tất cả. Sự mất mát dữ liệu ở đây là hoàn toàn ngẫu nhiên, và không có bất kỳ một mối quan hệ hay sự liên quan nào giữa dữ liệu và bất kì dữ liệu nào, missing hoặc dữ liệu quan sát. Ở ví dụ dưới đây chúng ta sẽ không hề tìm thấy một mối quan hệ nào giữa giá trị bị thiếu và giá trị được giữ nguyên.
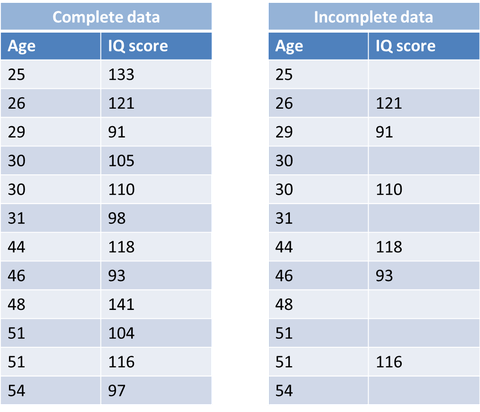
Hình 2: Ví dụ về MCAR
Missing Not at Random - Dữ liệu khuyết không ngẫu nhiên
MNAR: Sự mất mát dữ liệu không phải là ngẫu nhiên mà có một mối quan hệ xu hướng giữa giá trị bị missing và giá trị không bị missing trong một biến. Ví dụ: ở Hình 3 - những người có IQ thấp sẽ bị missing còn IQ cao thì không bị thiếu, có nghĩa là có sự liê quan giữa 2 giá trị missing và không missing trong chính biến IQ.
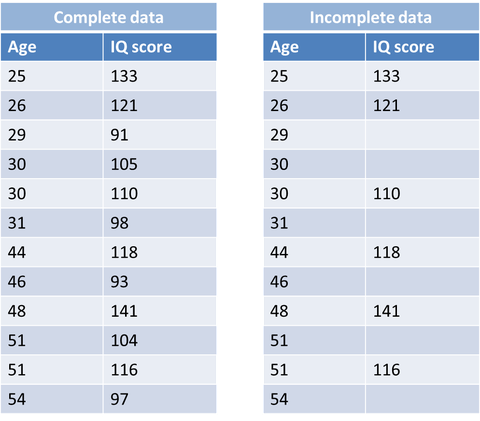
Hình 3: Ví dụ về MNAR
Giải quyết vấn đề missing như thế nào
Tìm kiếm missing data trong dataset
Chúng ta có thể thấy có rất nhiều kiểu dữ liệu missing xuất hiện: có thể là một chuỗi rống, có thể là NA, N/A, Non, -1, 99 hoặc 999. Cách tốt nhất để giải quyết mising values là bạn phải hiểu rõ được data mình có: Hiểu được cách dữ liệu missing đang được biểu diễn, cách data được thu thập, dữ liệu bị missing thuộc trường nào, ...
Chúng ta có thể loại bỏ dữ liệu missing khi chúng ta nhận ra thiếu dữ liệu hoàn toàn ngẫu nhiên (MCAR). Tuy nhiên với MAR và MNAR thì việc loại bỏ sẽ làm ảnh hưởng đến độ chính xác của mô hình tốt hơn hết chúng ta nên tìm cách để xử lý vấn đề này.
Xác định giá trị missing trong data
Cụ thể ở đây mình sẽ sử dụng tập dữ liệu titanic, đầu tiên mình sẽ xem tập dữ liệu này có bao nhiêu biến thiếu dữ liệu. Đầu tiên import đầu vào :
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Load Data
train = pd.read_csv('data/train.csv')
test = pd.read_csv('data/test.csv')
# Concatenate train & test
train_objs_num = len(train)
y = train['Survived']
dataset = pd.concat(objs=[train.drop(columns=['Survived']), test], axis=0)
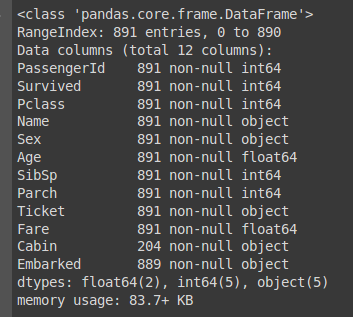
Dùng lệnh dataframe.info() để kiểm tra dữ liệu thiếu:
dataset.info()
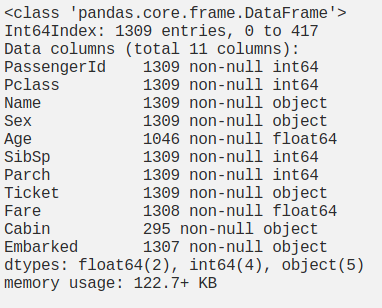
Hình 4: Tổng quan dữ liệu
Dựa vào Hình 4 chúng ta có thể thấy các features: Age, Fare, Cabin, Embarked chứa missing values. Tiếp theo chúng ta cùng show xem tỷ lệ dữ liệu bị thiếu theo từng feature như thế nào nhé:
total = dataset.isnull().sum().sort_values(ascending=False)
percent = (dataset.isnull().sum()/dataset.isnull().count()).sort_values(ascending=False)
missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
f, ax = plt.subplots(figsize=(15, 6))
plt.xticks(rotation='90')
sns.barplot(x=missing_data.index, y=missing_data['Percent'])
plt.xlabel('Features', fontsize=15)
plt.ylabel('Percent of missing values', fontsize=15)
plt.title('Percent missing data by feature', fontsize=15)
missing_data.head()
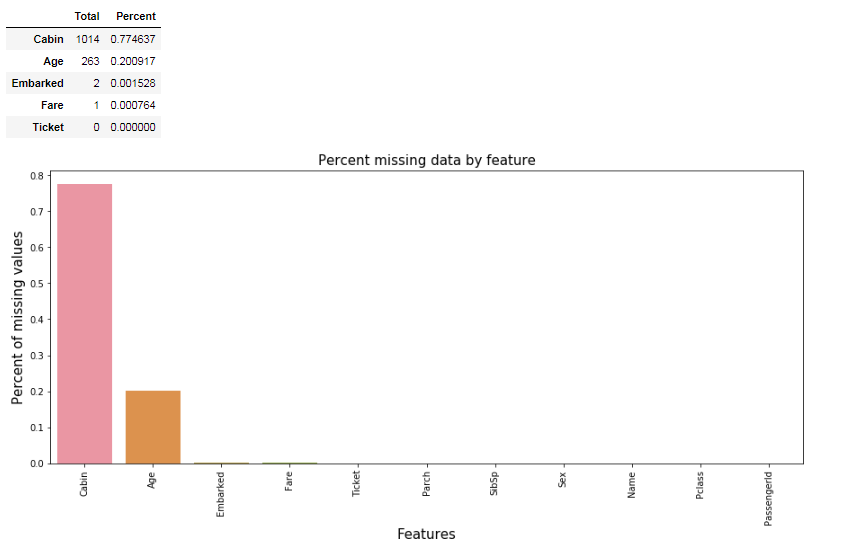
Hình 5: tỷ lệ dữ liệu missing theo từng feature
Removing Data
Listwise deletion
Nếu dữ liệu missing trong tập dữ liệu là MCAR và số lượng missing values không nhiều, chúng ta sẽ xóa đi những giá trị missing đó. Như ở Hình 1: những giá trị bị thiếu ở biến IQ score tương ứng với biến Age (age:25, 30, 31, 48, 51, 54) chúng ta sẽ drop nó đi. Hoặc với tập dữ liệu titanic ở trên features: Embarked và Fare bị thiếu dữ liệu rất ít thì mình sẽ loại bỏ những giá trị này đi bằng thực hiện dòng lệnh dưới đây
data = dataset.dropna(subset=['Fare', 'Embarked'])
Khi bạn muốn loại bỏ hết các giá trị bị thiếu ở tất cả các trường bạn dùng lệnh này:
dataset.dropna(how='all',inplace=True)
Hoặc khi bạn chỉ muốn loại bỏ những dòng data mà bị missing ở ít nhất 2 features trở lên:
dataset.dropna(thresh=2,inplace=True)
Dropping variable
Có rất nhiều trường hợp xảy ra khi thiếu data, nếu trong trường hợp một biến có nhiều giá trị bị thiếu và chúng ta có thể phán đoán rằng biến bị thiếu đó thật sự không quan trọng nếu không xuất hiện trong dữ liệu, thì chúng ta có thể xóa luôn cả biến đó đi. Thông thường, khi dữ liệu của một biến bị thiếu khoảng 60 ~70 % thì chúng ta nên xem xét đến việc loại bỏ hoàn toàn biến đó đi.
Với tập dữ liệu ở trên mình cũng có thể loại bỏ hết tất cả các biến bị thiếu bằng cách thực hiện dòng lệnh dưới đây tuy nhiên điều này sẽ làm cho chúng ta bị mất rất nhiều dữ liệu có ích.
dataset.dropna(axis=1,inplace=True)
Data Imputation
Thay thế những dữ liệu missing với các giá trị: -1, -99, -999
Với những features có tính liên tục thì việc chúng ta thay thế những giá trị missing bằng các giá trị -1, -99, -999, ... sẽ giúp cho những mô hình cây như (RF - Random Forest) hoạt động tốt hơn bởi khi thay thế bằng những giá trị ở trên thì các mô hình này có thể giải thích cho việc thiếu dữ liệu thông qua việc encoding này. Nhược điểm của nó làm giải hiệu suất của mô hình tuyến tính sẽ bị ảnh hưởng.
dataset.Fare.fillna(-99,inplace=True)
Thay thế bằng giá trị mean, midian, mode
Với phương pháp này chúng ta điền những giá trị bị thiếu bằng giá trị** mean** hay median của một vài biến nếu biến liên tục và điền mode nếu biến là biến categorical. Tuy phương pháp này nhanh nhưng lại làm giảm phương sai của dữ liệu. Bên cạnh đó khi thực hiện cách này thì nó phù hợp với mô hình tuyến tính đơn giản và NN. Nhưng đối với những bài toán dựa trên tree thì có vẻ không phù hợp lắm.
dataset.Age.fillna(dataset.Age.mean(),inplace=True)
hoặc :
dataset.Age.fillna(dataset.Age.median(),inplace=True)
Hoặc với biến categorical chúng ta sử dụng mode:
dataset.Cabin.fillna(dataset.Cabin.mode()[0],inplace=True)
Sử dụng mô hình dự đoán cho data impution
Ở đây chúng ta có thể sử dụng K-NN, Linear-Regression để dự đoán các giá trị còn thiếu:
from sklearn.linear_model import LinearRegression
linreg = LinearRegression()
train = pd.read_csv("train.csv")
data = train[['Pclass','SibSp','Parch','Fare','Age']]
x_train = data[data['Age'].notnull()].drop(columns='Age')
y_train = data[data['Age'].notnull()]['Age']
x_test = data[data['Age'].isnull()].drop(columns='Age')
y_test = data[data['Age'].isnull()]['Age']
linreg.fit(x_train, y_train)
predicted = linreg.predict(x_test)
train.Age[train.Age.isnull()] = predicted
train.info()
Hoặc với KNN chúng ta sử dụng thư viện sklearn:
import numpy as np
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5)
imputer.fit(train.select_dtypes('float64'))
cols_float = list(train.select_dtypes('float64').columns)
train[cols_float] = imputer.transform(train.select_dtypes('float64'))
Kết quả sau khi thực hiện ta được:
Với dữ liệu dạng categorical ở đây mình sẽ điền giá trị missing bằng cách sử dụng các phương pháp trên.
Kết Luận
Cảm ơn mọi người đã đọc bài viết của mình. HI vọng bài viết này sẽ hữu ích cho mọi người trong việc pre-processing dữ liệu. Nếu bài viết có gì chưa đúng hay thiếu sót mong nhận được sự góp ý và bổ sung của các bạn.
Reference
https://www.iriseekhout.com/missing-data/missing-data-mechanisms/mcar/
https://medium.com/@danberdov/dealing-with-missing-data-8b71cd819501
https://medium.com/@george.drakos62/handling-missing-values-in-machine-learning-part-1-dda69d4f88ca
All rights reserved
