Xây Dựng Mô Hình Ngôn Ngữ Lớn (Phần 6): Tinh chỉnh cho nhiệm vụ phân loại văn bản
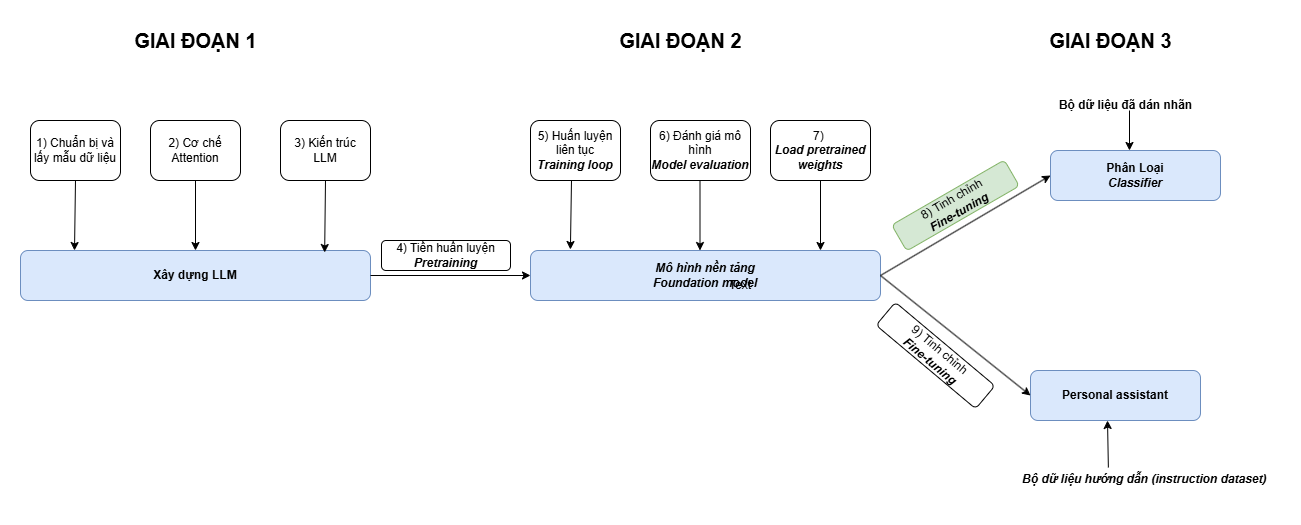
Ở các bài viết trước, ta đã triển khai gần như hoàn chỉnh việc xây dựng 1 mô hình ngôn ngữ lớn, từ việc xử lý dữ liệu đầu vào, cơ chế attention, logic trong khối Transformer cho đến tiền huấn luyện. Bây giờ, chúng ta sẽ cùng đi đến bước cuối trong quá trình xây dựng một mô hình ngôn ngữ lớn: Tinh chỉnh mô hình.
Mô hình sau khi trải qua quá trình tiền huấn luyện đã có thể sinh văn bản khá mượt mà.
Tuy nhiên, nó có thể vẫn đang còn hạn chế ở một số nhiệm vụ chuyên biệt như phân loại văn bản, dịch thuật ...
=> Do đó, tinh chỉnh là bước để xử lý và cải thiện các vấn đề trên.
File Juputer NoteBook của bài viết này nằm tại đây
1. Các phương pháp tinh chỉnh mô hình
Hai phương pháp phổ biến nhất là Classification fine-tuning và Instruction fine-tuning.
Điểm chung của 2 phương pháp là tập dữ liệu tinh chỉnh có nhãn dán (câu hỏi và đáp án).
Sự khác nhau về mục đích:
- Classification fine-tuning giúp mô hình phân loại dữ liệu tốt hơn (ví dụ cho đọc 1 email và xác định là
spamhaykhông spam) - Instruction fine-tuning giúp mô hình trả lời tốt hơn khi gặp các câu hỏi phức tạp
Ví dụ về Classification fine-tuning
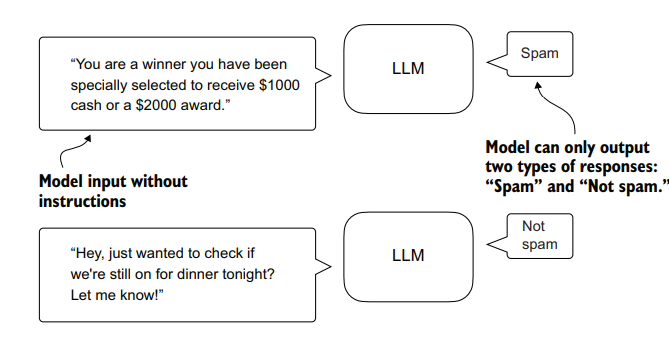
Ví dụ về Instruction fine-tuning

=> Ở bài viết này chúng ta sẽ tìm hiểu Classification fine-tuning trước.
2. Chuẩn bị tập dữ liệu
Ở bước đầu tiên này chúng ta tiến hành tải về, xem thử bên trong tệp dữ liệu.
import urllib.request
import zipfile
import os
from pathlib import Path
import pandas as pd
url = "https://archive.ics.uci.edu/static/public/228/sms+spam+collection.zip"
zip_path = "sms_spam_collection.zip"
extracted_path = "sms_spam_collection"
data_file_path = Path(extracted_path) / "SMSSpamCollection.tsv"
def download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path):
if data_file_path.exists():
print(f"{data_file_path} already exists. Skipping download and extraction.")
return
# Downloading file
with urllib.request.urlopen(url) as response:
with open(zip_path, "wb") as out_file:
out_file.write(response.read())
# Giải nén file zip
with zipfile.ZipFile(zip_path, "r") as zip_ref:
zip_ref.extractall(extracted_path)
# Add .tsv file extension
original_file_path = Path(extracted_path) / "SMSSpamCollection"
os.rename(original_file_path, data_file_path)
print(f"File downloaded and saved as {data_file_path}")
try:
download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)
except (urllib.error.HTTPError, urllib.error.URLError, TimeoutError) as e:
print(f"Primary URL failed: {e}. Trying backup URL...")
url = "https://f001.backblazeb2.com/file/LLMs-from-scratch/sms%2Bspam%2Bcollection.zip"
download_and_unzip_spam_data(url, zip_path, extracted_path, data_file_path)
# Đọc dữ liệu trong file và in ra
df = pd.read_csv(data_file_path, sep="\t", header=None, names=["Label", "Text"])
print(df)
# In ra số lượng bản ghi chia theo nhãn dán
print(df["Label"].value_counts())
"""
Label
ham 4825
spam 747
Name: count, dtype: int64
"""
Label Text
0 ham Go until jurong point, crazy.. Available only ...
1 ham Ok lar... Joking wif u oni...
2 spam Free entry in 2 a wkly comp to win FA Cup fina...
3 ham U dun say so early hor... U c already then say...
4 ham Nah I don't think he goes to usf, he lives aro...
... ... ...
- Dễ thấy có sự chênh lệch giữa số email spam và ham
- Để đơn giản hóa, ta sẽ lấy tập con sao cho chứa 747 mẫu từ mỗi lớp.
- Còn có nhiều cách khác để xử lý sự mất cân bằng lớp, nhưng chúng nằm ngoài phạm vi của chhương. Có thể tìm thấy ví dụ và thêm thông tin trong hướng dẫn sử dụng
imbalanced-learn.
def create_balanced_dataset(df):
# Đếm số lượng "spam"
num_spam = df[df["Label"] == "spam"].shape[0]
# Random lấy số lượng "ham" bằng với số lượng "spam" ở trên
ham_subset = df[df["Label"] == "ham"].sample(num_spam, random_state=123)
# Gộp lại
balanced_df = pd.concat([ham_subset, df[df["Label"] == "spam"]])
# bộ dữ liệu gồm 747 spam và ham
return balanced_df
balanced_df = create_balanced_dataset(df)
print(balanced_df["Label"].value_counts())
- Chuyển đổi nhãn dữ liệu sang dạng số
balanced_df["Label"] = balanced_df["Label"].map({"ham": 0, "spam": 1})
print(balanced_df)
4307 0 Awww dat is sweet! We can think of something t...
4138 0 Just got to <#>
4831 0 The word "Checkmate" in chess comes from the P...
4461 0 This is wishing you a great day. Moji told me ...
5440 0 Thank you. do you generally date the brothas?
... ... ...
- Chia dữ liệu thành các phần training, validation và test lần lượt theo tỷ lệ 70%, 10% và 20%
def random_split(df, train_frac, validation_frac):
df = df.sample(frac=1, random_state=123).reset_index(drop=True)
train_end = int(len(df) * train_frac)
validation_end = train_end + int(len(df) * validation_frac)
train_df = df[:train_end]
validation_df = df[train_end:validation_end]
test_df = df[validation_end:]
return train_df, validation_df, test_df
train_df, validation_df, test_df = random_split(balanced_df, 0.7, 0.1)
train_df.to_csv("train.csv", index=None)
validation_df.to_csv("validation.csv", index=None)
test_df.to_csv("test.csv", index=None)
3. Xử lý tập dữ liệu
Ta đang làm việc với một tập dữ liệu nội dung email với các độ dài khác nhau. Để nhóm các email này thành batch để xử lý, chúng ta có hai lựa chọn chính:
- Cắt bớt (truncate) tất cả các email xuống độ dài của email ngắn nhất .
- Đệm thêm (pad) vào tất cả sao cho đều độ dài bằng độ dài của email dài nhất.
Lựa chọn đầu tiên tiết kiệm chi phí tính toán và lưu trữ hơn, nhưng gây mất mát thông tin đáng kể và có thể làm giảm hiệu suất của mô hình. Do đó, chúng ta chọn cách thứ hai. Ký tự đệm thêm là <|endoftext|>
Như đã biết, mô hình không thể hiểu được dữ liệu dạng văn bản thô mà cần phải "số hóa". Tập dữ liệu dùng để tinh chỉnh cũng không ngoại lệ. Tiến hành chuyển dữ liệu sang dạng tokenID.
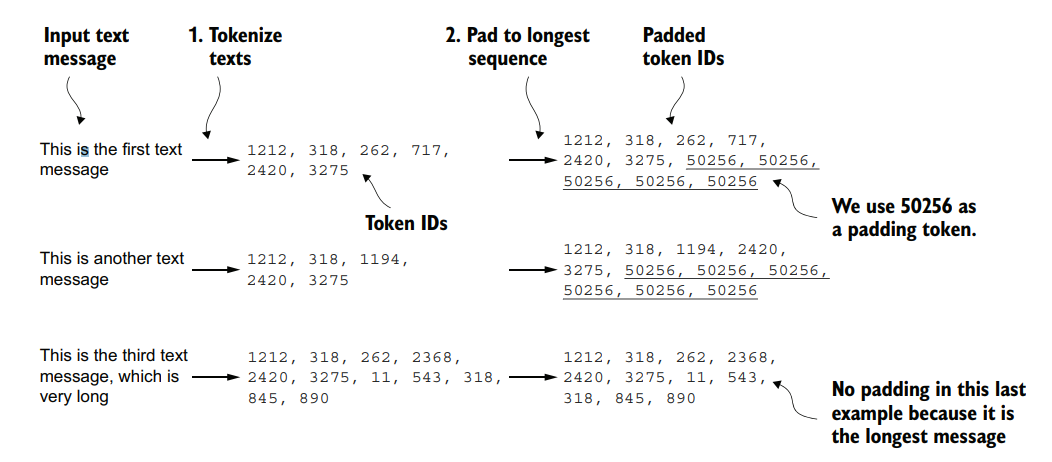
Phần gạch chân là phần đệm thêm vào, sao cho các chuỗi có độ dài bằng nhau
import tiktoken
import torch
from torch.utils.data import Dataset
import pandas as pd
# Dùng `DataLoader` để chia các tập dữ liệu theo các batch
from torch.utils.data import DataLoader
tokenizer = tiktoken.get_encoding("gpt2")
print(tokenizer.encode("<|endoftext|>", allowed_special={"<|endoftext|>"}))
class SpamDataset(Dataset):
def __init__(self, csv_file, tokenizer, max_length=None, pad_token_id=50256):
self.data = pd.read_csv(csv_file)
# Tiền xử lý: chuyển mỗi văn bản trong cột "Text" thành danh sách các token.
self.encoded_texts = [
tokenizer.encode(text) for text in self.data["Text"]
]
# Nếu không chỉ định max_length, tự động tìm độ dài của chuỗi dài nhất
if max_length is None:
self.max_length = self._longest_encoded_length()
else:
self.max_length = max_length
# Nếu có chỉ định max_length, cắt bớt chuỗi nếu chúng có độ dài lớn hơn max_length
self.encoded_texts = [
encoded_text[:self.max_length]
for encoded_text in self.encoded_texts
]
# Thêm phần tử cho tất cả chuỗi để đảm bảo chúng có cùng độ dài.
self.encoded_texts = [
encoded_text + [pad_token_id] * (self.max_length - len(encoded_text))
for encoded_text in self.encoded_texts
]
def __getitem__(self, index):
encoded = self.encoded_texts[index]
label = self.data.iloc[index]["Label"]
return (
torch.tensor(encoded, dtype=torch.long),
torch.tensor(label, dtype=torch.long)
)
def __len__(self):
return len(self.data)
# Hàm tìm độ dài lớn nhất của 1 chuỗi trong tập dữ liệu
def _longest_encoded_length(self):
max_length = 0
for encoded_text in self.encoded_texts:
encoded_length = len(encoded_text)
if encoded_length > max_length:
max_length = encoded_length
return max_length
train_dataset = SpamDataset(
csv_file="train.csv",
max_length=None,
tokenizer=tokenizer
)
val_dataset = SpamDataset(
csv_file="validation.csv",
max_length=train_dataset.max_length,
tokenizer=tokenizer
)
test_dataset = SpamDataset(
csv_file="test.csv",
max_length=train_dataset.max_length,
tokenizer=tokenizer
)
# Thiết lập số worker (0 nghĩa là không sử dụng đa luồng)
# Kích thước 1 lô là 8
num_workers = 0
batch_size = 8
torch.manual_seed(123)
train_loader = DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers,
drop_last=True,
)
val_loader = DataLoader(
dataset=val_dataset,
batch_size=batch_size,
num_workers=num_workers,
drop_last=False,
)
test_loader = DataLoader(
dataset=test_dataset,
batch_size=batch_size,
num_workers=num_workers,
drop_last=False,
)
# Xem số lượng batch ở mỗi tập
print(f"{len(train_loader)} training batches")
print(f"{len(val_loader)} validation batches")
print(f"{len(test_loader)} test batches")
"""
130 training batches
19 validation batches
38 test batches
"""
4. Thử nghiệm khả năng của mô hình trước khi tinh chỉnh
Cùng thử xem mô hình sẽ xử lý thế nào khi được yêu cầu phần loại tin nhắn spam.
# ... File đầy đủ: https://sal.vn/6SEtHM
def main():
CHOOSE_MODEL = "gpt2-small (124M)"
INPUT_PROMPT = "Every effort moves"
BASE_CONFIG = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"drop_rate": 0.0, # Dropout rate
"qkv_bias": True # Query-key-value bias
}
model_configs = {
"gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12},
"gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16},
"gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20},
"gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25},
}
BASE_CONFIG.update(model_configs[CHOOSE_MODEL])
model_size = CHOOSE_MODEL.split(" ")[-1].lstrip("(").rstrip(")")
settings, params = download_and_load_gpt2(model_size=model_size, models_dir="gpt2")
model = GPTModel(BASE_CONFIG)
load_weights_into_gpt(model, params)
model.eval()
text = (
"Is the following text 'spam'? Answer with 'yes' or 'no':"
" 'You are a winner you have been specially"
" selected to receive $1000 cash or a $2000 award.'"
)
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids(text, tokenizer),
max_new_tokens=23,
context_size=BASE_CONFIG["context_length"]
)
print(token_ids_to_text(token_ids, tokenizer))
if __name__ == "__main__":
main()
Is the following text 'spam'? Answer with 'yes' or 'no': 'You are a winner you have been specially selected to receive $1000 cash or a $2000 award.'
The following text 'spam'? Answer with 'yes' or 'no': 'You are a winner
Với việc yêu cầu trả lời yes hoặc no, mô hình đang chưa hiểu và trả ra kết quả không liên quan. Giờ lại lúc bắt tay vào bước tinh chỉnh.
5. Điều chỉnh định dạng đầu ra của mô hình
Với nhiệm phụ phân loại spam, đầu ra của mô hình chỉ cần 2 giá trị là 0 và 1.
=> Do đó, chúng ta cần sửa lại sao cho số giá trị đầu ra giảm từ hơn 50k xuống còn 2.
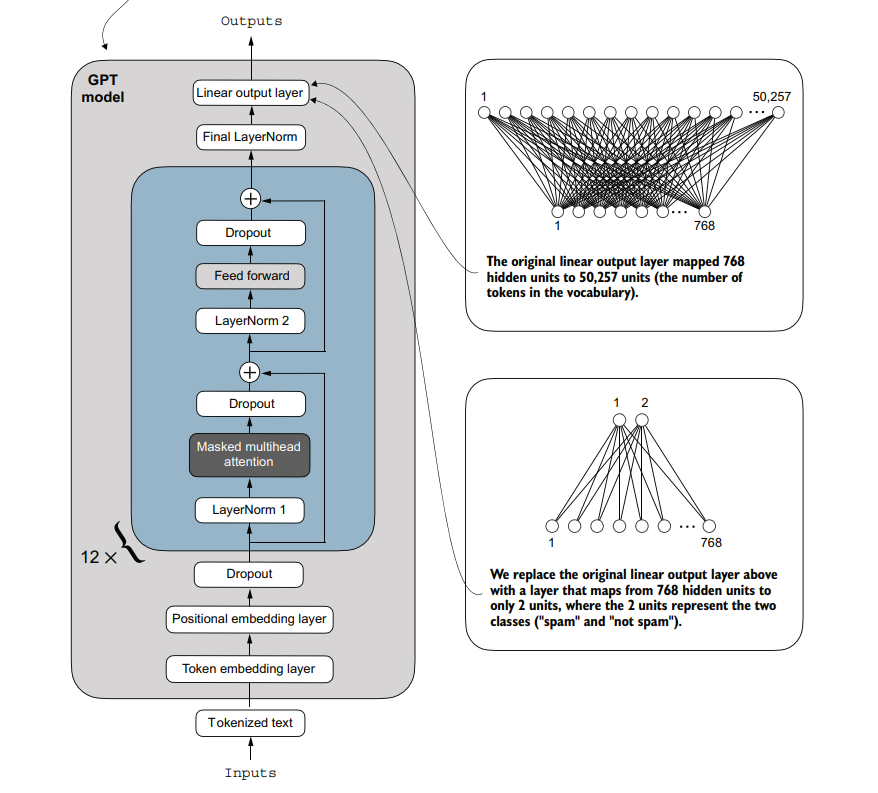
Hình minh họa việc thay đổi lớp Linear output trong mô hình để phù hợp với nhiệm vụ phân loại spam.
# ...
def main():
# ...
# đóng băng mô hình, nghĩa là dừng quá trình cập nhật các tham số
for param in model.parameters():
param.requires_grad = False
torch.manual_seed(123)
num_classes = 2
# Thay thế lớp Linear output để đầu ra chứa 2 giá trị
model.out_head = torch.nn.Linear(in_features=BASE_CONFIG["emb_dim"], out_features=num_classes)
# Cho phép khối Transformer cuối cùng (thứ 12) có thể cập nhật tham số khi huấn luyện
for param in model.trf_blocks[-1].parameters():
param.requires_grad = True
# Cho phép lớp chuẩn hóa cuối cùng có thể cập nhật tham số khi huấn luyện
for param in model.final_norm.parameters():
param.requires_grad = True
model.eval()
inputs = tokenizer.encode("Do you have time")
inputs = torch.tensor(inputs).unsqueeze(0)
with torch.no_grad():
outputs = model(inputs)
print("Outputs:\n", outputs)
"""
Outputs:
tensor([[[-1.5854, 0.9904],
[-3.7235, 7.4548],
[-2.2661, 6.6049],
[-3.5983, 3.9902]]])
Outputs dimensions: torch.Size([1, 4, 2])
"""
print("Last output token:", outputs[:, -1, :])
# Last output token: tensor([[-3.5983, 3.9902]])
# Với TH 2 giá trị đầu ra thì có thể lược bỏ bước softmax đi
# chỉ cần giá trị cái nào lớn hơn thì chọn cái đó là được
probas = torch.softmax(outputs[:, -1, :], dim=-1)
label = torch.argmax(probas)
print("Class label:", label.item())
# Class label: 1 => Yes
- Về mặt kỹ thuật, chỉ cần sửa
out_headlà đủ. - Tuy nhiên, thực tế cho thấy rằng việc tinh chỉnh thêm các khối khác có thể cải thiện hiệu suất đáng kể.
- Vì vậy, a sẽ sửa thêm khối Transformer cuối cùng và khối
Final LayerNorm.
Tại sao lại chỉ dùng thêm Final LayerNorm và khối Transformer cuối cùng ?
- Tiết kiệm tài nguyên tính toán
- Tinh chỉnh có nghĩa là thay đổi nhỏ chứ không phải là huấn luyện lại.
- Bộ dữ liệu đặc thù nhỏ hơn nhiều so với dữ liệu pretrained, việc tinh chỉnh toàn bộ mô hình có thể dẫn đến overfitting
6. Tính toán hàm mất mát và độ chính xác
Tính hàm mất mát
- Hàm mất mát vẫn được tính theo phương pháp Cross Entropy tương tự như giai đoạn tiền huấn luyện.
- Hàm
calc_loss_batchở đây giống với trong chương 5, ngoại trừ việc chúng ta chỉ quan tâm đến việc tối ưu token cuối cùngmodel(input_batch)[:, -1, :]thay vì tất cả các tokenmodel(input_batch)
def calc_loss_batch(input_batch, target_batch, model, device):
input_batch, target_batch = input_batch.to(device), target_batch.to(device)
logits = model(input_batch)[:, -1, :]
loss = torch.nn.functional.cross_entropy(logits, target_batch)
return loss
def calc_loss_loader(data_loader, model, device, num_batches=None):
total_loss = 0.
if len(data_loader) == 0:
return float("nan")
elif num_batches is None:
num_batches = len(data_loader)
else:
# Reduce the number of batches to match the total number of batches in the data loader
# if num_batches exceeds the number of batches in the data loader
num_batches = min(num_batches, len(data_loader))
for i, (input_batch, target_batch) in enumerate(data_loader):
if i < num_batches:
loss = calc_loss_batch(input_batch, target_batch, model, device)
total_loss += loss.item()
else:
break
return total_loss / num_batches
Training loss: 2.453
Validation loss: 2.583
Test loss: 2.322
Tính độ chính xác
def calc_accuracy_loader(data_loader, model, device, num_batches=None):
model.eval()
correct_predictions, num_examples = 0, 0
if num_batches is None:
num_batches = len(data_loader)
else:
num_batches = min(num_batches, len(data_loader))
# Lặp qua từng batch trong data_loader và kiểm tra nếu chưa vượt quá số batch tối đa.
for i, (input_batch, target_batch) in enumerate(data_loader):
if i < num_batches:
input_batch, target_batch = input_batch.to(device), target_batch.to(device)
# Tính toán đầu ra
with torch.no_grad():
logits = model(input_batch)[:, -1, :] # Logits of last output token
predicted_labels = torch.argmax(logits, dim=-1) # Giá trị đầu ra
# Số mẫu đã xử lý
num_examples += predicted_labels.shape[0]
# Số dự đoán chính xác
correct_predictions += (predicted_labels == target_batch).sum().item()
else:
break
# Tỷ lệ chính xác
return correct_predictions / num_examples
def main():
# ...
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device) # no assignment model = model.to(device) necessary for nn.Module classes
torch.manual_seed(123) # For reproducibility due to the shuffling in the training data loader
train_accuracy = calc_accuracy_loader(train_loader, model, device, num_batches=10)
val_accuracy = calc_accuracy_loader(val_loader, model, device, num_batches=10)
test_accuracy = calc_accuracy_loader(test_loader, model, device, num_batches=10)
print(f"Training accuracy: {train_accuracy*100:.2f}%")
print(f"Validation accuracy: {val_accuracy*100:.2f}%")
print(f"Test accuracy: {test_accuracy*100:.2f}%")
Training accuracy: 46.25%
Validation accuracy: 45.00%
Test accuracy: 48.75%
Độ chính xác còn chưa được 50%, do chúng ta vẫn chưa hề thực hiện huấn luyện.
7. Tinh chỉnh mô hình với dữ liệu gán nhãn
-
Trong phần này, chúng ta huấn luyện để cải thiện độ chính xác trong việc phân loại email của mô hình
-
Hàm
train_classifier_simpledưới đây gần như giống với hàmtrain_model_simplemà chúng ta đã sử dụng ở chương 5 -
Chỉ có hai điểm khác biệt là:
- Theo dõi số lượng mẫu huấn luyện đã xử lý (
examples_seen) thay vì số lượng token đã xử lý - Tính toán độ chính xác sau mỗi chu kỳ huẩn luyện thay vì in ra một đoạn văn bản mẫu
- Theo dõi số lượng mẫu huấn luyện đã xử lý (
# Giống ở phần pretraining
def evaluate_model(model, train_loader, val_loader, device, eval_iter):
model.eval()
with torch.no_grad():
train_loss = calc_loss_loader(train_loader, model, device, num_batches=eval_iter)
val_loss = calc_loss_loader(val_loader, model, device, num_batches=eval_iter)
model.train()
return train_loss, val_loss
def train_classifier_simple(model, train_loader, val_loader, optimizer, device, num_epochs,
eval_freq, eval_iter):
# Khởi tạo các biến lưu trữ giá trị hàm mất mát và độ chính xác của tập train và validation
train_losses, val_losses, train_accs, val_accs = [], [], [], []
examples_seen, global_step = 0, -1
# Vòng lặp huấn luyện chính
for epoch in range(num_epochs):
model.train() # Đặt mô hình ở chế độ huấn luyện
for input_batch, target_batch in train_loader:
optimizer.zero_grad() # Đặt lại gradient lỗi từ lần lặp batch trước đó
loss = calc_loss_batch(input_batch, target_batch, model, device)
loss.backward() # Tính toán gradient lỗi
optimizer.step() # Cập nhật trọng số mô hình bằng gradient lỗi
examples_seen += input_batch.shape[0] # theo dõi số lượng mẫu thay vì token
global_step += 1
# Làm việc với hàm mất mát
if global_step % eval_freq == 0:
train_loss, val_loss = evaluate_model(
model, train_loader, val_loader, device, eval_iter)
train_losses.append(train_loss)
val_losses.append(val_loss)
print(f"Ep {epoch+1} (Step {global_step:06d}): "
f"Train loss {train_loss:.3f}, Val loss {val_loss:.3f}")
# Tính độ chính xác sau mỗi chu kỳ
train_accuracy = calc_accuracy_loader(train_loader, model, device, num_batches=eval_iter)
val_accuracy = calc_accuracy_loader(val_loader, model, device, num_batches=eval_iter)
print(f"Training accuracy: {train_accuracy*100:.2f}% | ", end="")
print(f"Validation accuracy: {val_accuracy*100:.2f}%")
train_accs.append(train_accuracy)
val_accs.append(val_accuracy)
return train_losses, val_losses, train_accs, val_accs, examples_seen
Thực thi quá trình huấn luyện
import time
# ... File đầy đủ: https://sal.vn/ZijlcZ
def main():
# ...
start_time = time.time()
torch.manual_seed(123)
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5, weight_decay=0.1)
num_epochs = 5
train_losses, val_losses, train_accs, val_accs, examples_seen = train_classifier_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=50, eval_iter=5,
)
end_time = time.time()
execution_time_minutes = (end_time - start_time) / 60
print(f"Training completed in {execution_time_minutes:.2f} minutes.")
if __name__ == "__main__":
main()
Kết quả in ra sau 5 chu kỳ huấn luyện:
Ep 1 (Step 000000): Train loss 2.153, Val loss 2.392
Ep 1 (Step 000050): Train loss 0.617, Val loss 0.637
Ep 1 (Step 000100): Train loss 0.523, Val loss 0.557
Training accuracy: 70.00% | Validation accuracy: 72.50%
Ep 2 (Step 000150): Train loss 0.561, Val loss 0.489
Ep 2 (Step 000200): Train loss 0.419, Val loss 0.397
Ep 2 (Step 000250): Train loss 0.409, Val loss 0.353
Training accuracy: 82.50% | Validation accuracy: 85.00%
Ep 3 (Step 000300): Train loss 0.333, Val loss 0.320
Ep 3 (Step 000350): Train loss 0.340, Val loss 0.306
Training accuracy: 90.00% | Validation accuracy: 90.00%
Ep 4 (Step 000400): Train loss 0.136, Val loss 0.200
Ep 4 (Step 000450): Train loss 0.153, Val loss 0.132
Ep 4 (Step 000500): Train loss 0.222, Val loss 0.137
Training accuracy: 100.00% | Validation accuracy: 97.50%
Ep 5 (Step 000550): Train loss 0.207, Val loss 0.143
Ep 5 (Step 000600): Train loss 0.083, Val loss 0.074
Training accuracy: 100.00% | Validation accuracy: 97.50%
Training completed in 5.31 minutes.
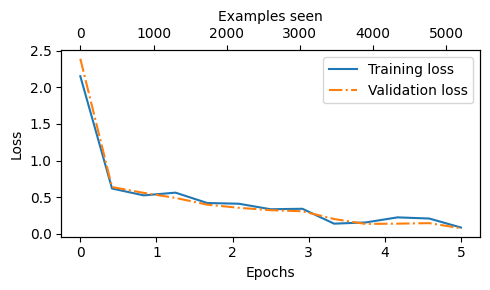
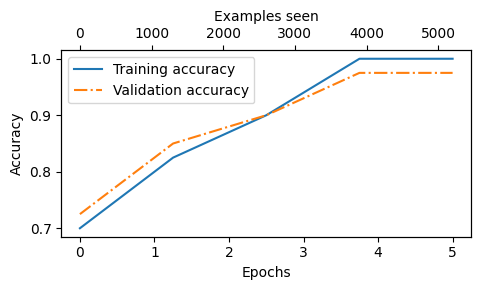
- Dựa vào độ dốc đi xuống của 2 giá trị mất mát, chúng ta thấy rằng mô hình học tốt
- Hơn nữa, 2 đường màu xanh và cam giảm cùng nhau trong suốt 5 chu kỳ cho thấy rằng mô hình không có xu hướng overfit
8. Thử nghiệm thực tế để phân loại email
Thử nghiệm
Chúng ta cùng lại các câu hỏi cũ mà trước đó nó chưa hiểu xem mô hình trả lời thế nào ?
def classify_review(text, model, tokenizer, device, max_length=None, pad_token_id=50256):
model.eval() # Đặt mô hình ở chế độ đánh giá
# Chuẩn bị đầu vào cho mô hình
input_ids = tokenizer.encode(text) # tokenizer hóa văn bản
supported_context_length = model.pos_emb.weight.shape[0] # Độ dài tối đa mà mô hình hỗ trợ
# Cắt ngắn chuỗi nếu quá dài
input_ids = input_ids[:min(max_length, supported_context_length)]
# Đệm chuỗi để đạt đến độ dài tối đa
input_ids += [pad_token_id] * (max_length - len(input_ids))
input_tensor = torch.tensor(input_ids, device=device).unsqueeze(0) # Thêm chiều batch (kích thước lô)
# Suy luận mô hình
with torch.no_grad(): # Không tính toán gradient trong quá trình suy luận để tiết kiệm bộ nhớ
logits = model(input_tensor)[:, -1, :] # Logits của token đầu ra cuối cùng
predicted_label = torch.argmax(logits, dim=-1).item() # Lấy nhãn có xác suất cao nhất
# Trả về kết quả phân loại
return "spam" if predicted_label == 1 else "not spam" # Chuyển đổi đầu ra thành dạng văn bản
Mô hình đã hiểu và phân biệt đúng 2 nội dung thuộc spam hay not spam
text_1 = (
"You are a winner you have been specially"
" selected to receive $1000 cash or a $2000 award."
)
print(classify_review(
text_1, model, tokenizer, device, max_length=train_dataset.max_length
))
# spam
text_2 = (
"Hey, just wanted to check if we're still on"
" for dinner tonight? Let me know!"
)
print(classify_review(
text_2, model, tokenizer, device, max_length=train_dataset.max_length
))
# not spam
Lưu lại mô hình
Mô hình hoạt động khá tốt, ta tiến hành lưu lại thông số mô hình để có thể tái sử dụng với code sau:
torch.save(model.state_dict(), "review_classifier.pth")
Nạp lại mô hình từ file đã lưu
model_state_dict = torch.load("review_classifier.pth, map_location=device")
model.load_state_dict(model_state_dict)
Tài liệu tham khảo
All rights reserved
