Xây dựng chức năng đếm số hiệu quả
Bài đăng này đã không được cập nhật trong 3 năm
Vấn đề
Yêu cầu bài toán là cần tracking được số lượng request gửi đến hệ thống để có thể hiển thị ở backend chi tiết đến từng ngày, tháng hay năm
Do đặc điểm số lượng request gửi đến hệ thống lớn, lên tới hàng triệu request mỗi ngày, việc xử lý tính toán lưu số lượng request, thiết kế database lưu trữ được lâu dài, truy vấn hiệu quả là những vấn đề cần giải quyết
Ý tưởng tổng quan
1. Xử lý việc lưu số lượng request
1.1 Ý tưởng
Bắt đầu với ý tưởng ai cũng nghĩ đến, với mỗi request được gửi sang ta sẽ gọi 1 command +1 request vào db
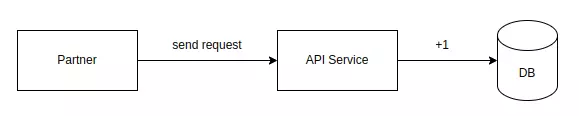
Vấn đề:
- Chúng ta phải chờ đợi thêm việc gọi vào db làm chậm response trả về
- Việc số lượng lớn request gửi đến cùng lúc có thể khiến db tăng tải, có thể ảnh hưởng luôn tốc độ xử lý toàn bộ service
1.2 Cải thiện
Làm thế nào để việc cộng số lượng request nhanh, đồng thời giảm thiểu số lượng commands gọi vào db ?
Ta cần tinh chỉnh lại kiến trúc một chút
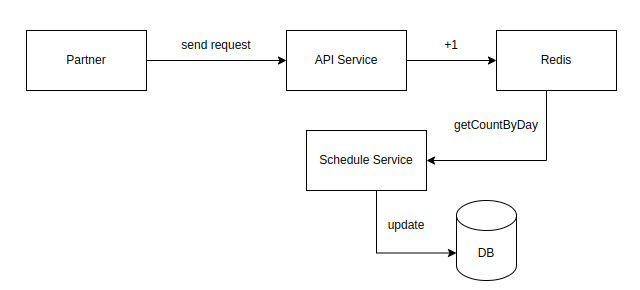
- Thay vì xử lý việc cộng gọi vào db, ta sẽ gọi vào redis vì việc xử lý I/O dùng redis là rất nhanh, và xử lý cùng lúc được số lượng lớn request
- Ta sẽ lưu thông tin tổng số lượng request trong ngày, sau mỗi ngày sẽ có 1 service gọi vào redis, update thông tin vào db
=> Như vậy tránh được việc gọi vào db quá nhiều
2. Xử lý việc lưu trữ lâu dài & truy vấn hiệu quả
1.1 Ý tưởng
Vì ta cần tracking được số lượng request chi tiết nhất là theo từng giờ. Nên ta cần lưu số lượng request theo giờ trong db.
Mình thì dùng MongoDB nên ta có thể lưu thông tin như sau:
{
partner_id: 12345,
timestamp: ISODate("2023-03-01T01:00:00.000Z"),
count: 40
}
{
partner_id: 12345,
timestamp: ISODate("2023-03-01T02:00:00.000Z"),
count: 100
}
.....
{
partner_id: 12345,
timestamp: ISODate("2023-03-01T23:00:00.000Z"),
count: 20
}
Vấn đề:
- Việc lưu thông tin đơn thuần như phía trên sẽ khiến ta phải vất vả trong việc tự tổng hợp dữ liệu từng ngày, rồi từng tháng, từng năm
- Tốc độ truy vấn số lượng lớn bản ghi và cần tổng hợp chúng lại khiến tốc độ tìm kiếm chậm
1.2 Cải thiện
1.Ta có thể áp dụng Bucket Pattern: Hiểu đơn giản là nhóm những dữ liệu cùng loại vào 1 bản ghi nhằm tiết kiệm bộ nhớ, và dễ dàng truy vấn
Ta có thể lưu tất cả tổng số tin theo giờ trong một ngày với 1 bản ghi duy nhất
{
partner_id: 12345,
date: "2023-03-01",
counts: {
1: 40,
2: 100,
.....,
23: 20
},
total_count: 2000
}
Với cách lưu này ta đã có thể dễ dàng truy vấn thông tin theo từng ngày. Vậy còn theo tháng theo năm thì phải làm sao ?
Tương tự ta cũng có thể lưu lại thông tin theo tháng như sau:
{
partner_id: 12345,
date: "2023-03",
counts: {
1: 2000,
2: 2023,
.......,
31: 3100
},
total_count: 100000
}
=> Như vậy là ta có thể truy vấn theo ngày, tháng, năm rất hiệu quả và đơn giản
2. Để có dữ liệu truy vấn như trên thì bước đồng bộ ta cần update vào 3 bản ghi ( ngày, tháng, năm ) thay vì chỉ 1 bản ghi duy nhất như trước
Những vấn đề khác
1. Nên lưu thông tin trong redis như thế nào
Chắc mọi người sẽ phân vân giữa việc lưu thông tin dưới dạng key value, hay dùng hash trong redis để lưu data trong ngày
Theo mình thì việc lưu data dưới dạng hash sẽ tốt hơn vì dễ dàng lấy tất cả thông tin bằng lệnh hgetall và xóa đi khi đã đồng bộ xong.
Hash trong redis cũng hỗ trợ commands cộng là hincrby xử lý việc cộng
Key có thể sử dụng dạng sau: counts.{partner_id}.{yyyy-mm-dd}.
Ví dụ: counts.123456.2023-03-01
2. Xử lý việc đồng bộ sau mỗi ngày
Theo mình nên lưu trạng thái mỗi lần đồng bộ, và cho job chạy vài lần trong ngày tránh việc chỉ chạy 1 lần failure mà lost data
Với logic như sau:
- Check xem lần đồng bộ trong ngày đã thành công chưa ?
- Nếu thành công thì dừng lại
- Nếu chưa thành công hoặc chưa từng đồng bộ thì tiếp tục đồng bộ
- Lưu lại trạng thái đồng bộ
Chú ý: Là khi đồng bộ hoàn tất 1 hash trong redis thì ta sẽ xóa luôn hash đi, tránh để việc xóa hash sau khi đã đồng bộ xong tất cả
Vậy là kết thúc bài viết rồi, hẹn mọi người ở những bài viết tiếp theo 
All rights reserved
