Understanding Convolutional Neural Networks for Natural Language processing
Bài đăng này đã không được cập nhật trong 4 năm
Khi chúng ta nghe về Convolutonal Neural Networks (CNNs), chúng ta nghĩ về Computor Vision (thị giác máy tính). CNNs là phần chịu trách nhiệm lớn trong việc phân loại hình ảnh, và nó là phần cốt lõi của hầu hết Computer Vision ngày nay, từ việc xử lí tự động tag của Facebooks cho đến lái xe tự vận. Gần đây, chúng ta còn áp dụng CNNs cho vấn đề xử lí ngôn ngữ tự nhiên và đã nhận được nhiều kết quả thú vị. Vậy trong bài này chúng ta sẽ cùng xem CNNs là gì, cách áp dụng nó vào xử lí ngôn ngữ tự nhiên như thế nào. Thông thường CNNs sẽ dễ hiệu hơn trong trong việc xử lí học tập hình ảnh của thị giác, vì thế ta sẽ bắt đầu từ Computer Vision và tiến đến Natural Language processing(NLP)
What is Convolution
Cách dễ hiểu nhất về "convolution" là nó giống như một cửa sổ trượt (Sliding Windows) dưới một ma trận. Bạn có thể xem bên dưới:
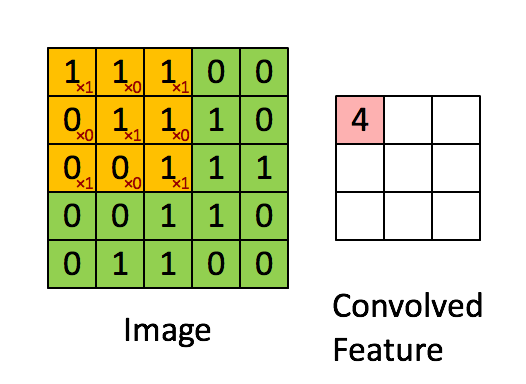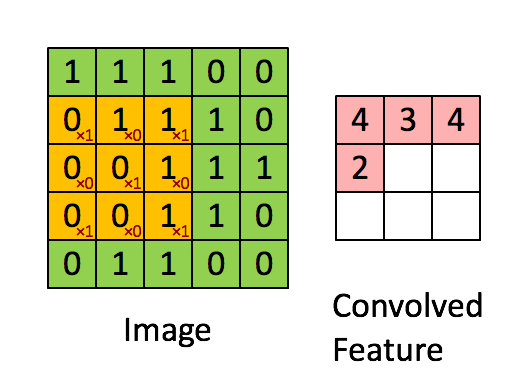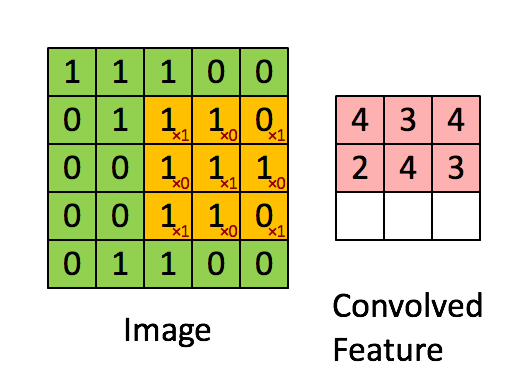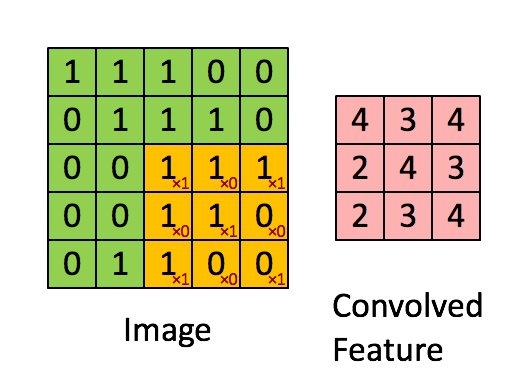
Hình ảnh ma trận bên trái là một ảnh trắng đen mô tả với các giá trị (0- black, 1- white) mội một thực thể tương ứng là một điểm ảnh 0,1. Sliding Windows là một ma trận có khích thước nhỏ hơn được gọi là kernel, filter hoặc feature detect. Trong ví dụ trên nó là ma trận có kích thước 3x3. Sau đó chúng ta sẽ tính tích chập ( nhân từng phần tử bên trong ma trận 3x3 với ma trận đầu vào bên trái). Kết quả sẽ được một ma trận mới, đấy chính là Convoled Feature.
Bây giờ bạn có thể thắc mắc, vậy chúng ta tính tích chập để làm gì?
Chúng ta làm điều đó để cho hai mục đích:
1 Làm mờ bức ảnh ban đầu: nếu chúng ta lấy giá trị trung bình của mỗi điểm ảnh trung tâm với các điểm lân cận thì nó sẽ cho ta một kết quả trung bình ( bức ảnh sẽ từ bị làm mờ đi)

 2 Nhận diện được các đường cạnh ( các nét vẻ đặc trưng từng khối): Để làm điều đó bằng cách thêm vào hoặc bỏ đi các giá trị bằng 0 trong ma trận. chung ta hãy tưởng tượng nếu đó là một đường nét thì giá trị điểm ảnh tại các vị trí trên đường nét sẽ cao, vậy sau quá trình biến đổi nó sẽ tạo ra tự khác biệt về màu sắc trắng(1) và đen(0) trong ma trận
2 Nhận diện được các đường cạnh ( các nét vẻ đặc trưng từng khối): Để làm điều đó bằng cách thêm vào hoặc bỏ đi các giá trị bằng 0 trong ma trận. chung ta hãy tưởng tượng nếu đó là một đường nét thì giá trị điểm ảnh tại các vị trí trên đường nét sẽ cao, vậy sau quá trình biến đổi nó sẽ tạo ra tự khác biệt về màu sắc trắng(1) và đen(0) trong ma trận
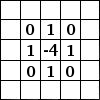
 Ở đây để bạn hiểu rõ về các bộ filter hơn thì xem link này nhé https://docs.gimp.org/en/plug-in-convmatrix.html
Cũng là khá đơn giản nếu bạn nào đã từng làm tí về xử lí ảnh trong các app mobile với các bộ lọc cơ bản.
Ở đây để bạn hiểu rõ về các bộ filter hơn thì xem link này nhé https://docs.gimp.org/en/plug-in-convmatrix.html
Cũng là khá đơn giản nếu bạn nào đã từng làm tí về xử lí ảnh trong các app mobile với các bộ lọc cơ bản.
What are Convolutional Neural Networks?
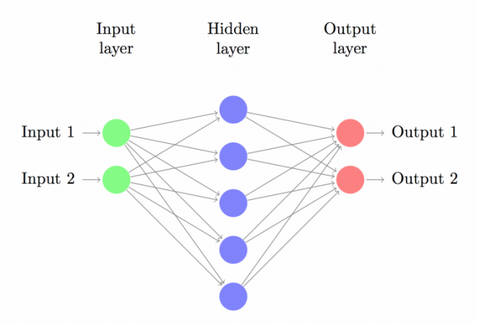
Bạn đã biết được Convolutional là gì, vậy CNNs là gì, CNNs cơ bản chỉ là một mạng gồm nhiều lớp Convolution chồng lên nhau, sử dụng các hàm phi tuyến tính như ReLU và tanh để đưa ra kết quả. Trong mô hình mạng noron truyền ngược ( feedforward neural network) chúng ta liên kết mỗi noron đầu vào đến mỗi noron đầu ra của lớp kế tiếp. Nó được gọi là mạng liên kết đầy đủ.
feedforward neural network
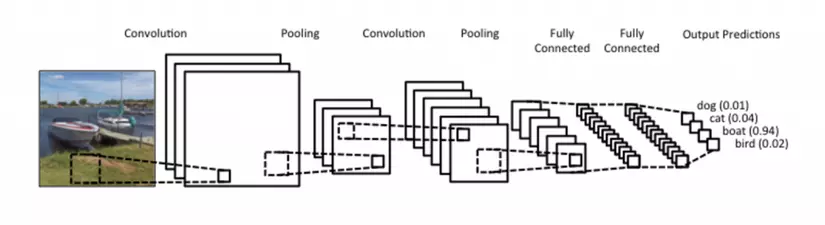
 Nhưng với CNNs chúng ta không làm như vậy, thay vào đó chúng ta sử dụng convolutions với input layer để tính toán out put. Mỗi lớp layer sẽ áp dụng các bộ lọc khác nhau, thông thường có hàng trăm đến hàng ngàn bộ lọc như vậy, sau đó chúng ta tổng hợp kết quả của chúng lại. Và chúng ta còn có một vài lớp khác ( ở đây mình gọi là bộ lọc cũng được) nó gọi là pooling, để từ các output từ các lớp sẽ được chọn lựa giảm thiểu số input đầu vào cho lớp tiếp theo trong mạng CNNs.
Trong suốt quá trình trainning, CNNs tự học để nhận ra các đường cạnh từ các dòng pixels trong lớp đầu tiên, tiếp theo nó sẽ nhận biết được các hình khối đơn giản từ các đường cạnh trong lớp tiếp theo... cho đến việc nhận diện được các thực thể cap hơn. Lớp cuối cùng là là lớp được sử dụng dể trích xuất các kết quả nhận diện cao nhất
Nhưng với CNNs chúng ta không làm như vậy, thay vào đó chúng ta sử dụng convolutions với input layer để tính toán out put. Mỗi lớp layer sẽ áp dụng các bộ lọc khác nhau, thông thường có hàng trăm đến hàng ngàn bộ lọc như vậy, sau đó chúng ta tổng hợp kết quả của chúng lại. Và chúng ta còn có một vài lớp khác ( ở đây mình gọi là bộ lọc cũng được) nó gọi là pooling, để từ các output từ các lớp sẽ được chọn lựa giảm thiểu số input đầu vào cho lớp tiếp theo trong mạng CNNs.
Trong suốt quá trình trainning, CNNs tự học để nhận ra các đường cạnh từ các dòng pixels trong lớp đầu tiên, tiếp theo nó sẽ nhận biết được các hình khối đơn giản từ các đường cạnh trong lớp tiếp theo... cho đến việc nhận diện được các thực thể cap hơn. Lớp cuối cùng là là lớp được sử dụng dể trích xuất các kết quả nhận diện cao nhất
 Có hai khía cạnh chúng ta cần chú ý trong CNNs: Location Invariance ( tính bất biến) và Compositionality (tính kết hợp). Với cùng một đối tượng, nếu được chiếu theo các góc độ khác nhau ( translation, rotation, scaling) thì sẽ cho ta các kết quả độ sai lệch đáng kể, nó ảnh hưởng đến độ chính xác của kết quả chung. Các lớp pooling layer sẽ cho bạn tính bất biến đối với các phép dịch (translation), phép quay (rotation) vaf phép co giãn (scaling). Mỗi bộ lọc tạo ra một mảng vá từ các featurer thấp để tạo ra một đại diện cao hơn. Đó là lí do CNNs rất mạnh trong Computer Vision. Nó giống như cách con người nhận biết các vật thể trong tự nhiên.
Có hai khía cạnh chúng ta cần chú ý trong CNNs: Location Invariance ( tính bất biến) và Compositionality (tính kết hợp). Với cùng một đối tượng, nếu được chiếu theo các góc độ khác nhau ( translation, rotation, scaling) thì sẽ cho ta các kết quả độ sai lệch đáng kể, nó ảnh hưởng đến độ chính xác của kết quả chung. Các lớp pooling layer sẽ cho bạn tính bất biến đối với các phép dịch (translation), phép quay (rotation) vaf phép co giãn (scaling). Mỗi bộ lọc tạo ra một mảng vá từ các featurer thấp để tạo ra một đại diện cao hơn. Đó là lí do CNNs rất mạnh trong Computer Vision. Nó giống như cách con người nhận biết các vật thể trong tự nhiên.
how does any of this apply to NLP?
CNNs trông chỉ phù hợp với Computer Vision, vậy làm sao áp dụng nó trong việc xử lí ngôn ngữ tự nhiên?
Thay vì input đầu vào là các điểm ảnh trong Computer Vision, đầu vào của phân tích ngôn ngữ tự nhiên là các mệnh đề, các văn bản được biểu diễn như một ma trận. Mỗi dòng của một ma trận tương ứng với một mã, đa phần đó là một từ, nhưng nó cũng có thể là một kí tự. Mối hàng chính là một vector đại diện cho một từ. Thông thường các vector word này được trình bày ở mức thấp như dạng word2vec hay Glove, nhưng nó cũng có thể là một vector với việc các từ sẽ được đánh chỉ số thuộc một bộ từ vựng. Và khi chung ta sử dụng nhiều chiều ánh xạ một câu thì nó sẽ tạo cho chúng ta một ma trận nhiều chiều, như thế nó đã được biến thành input image đầu vào.
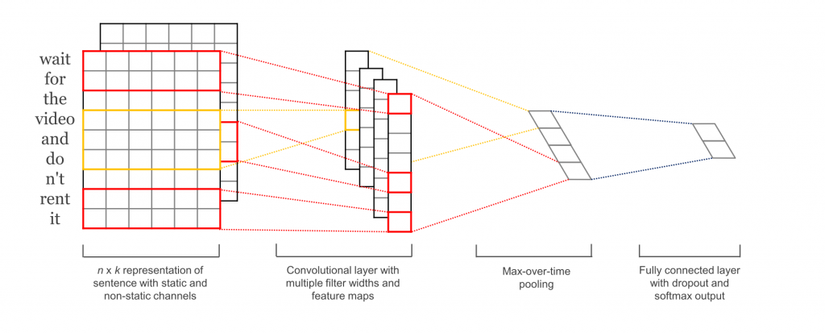
Chúng ta có thể xem, các bộ lọc sẽ trượt qua các mảnh vá của image đầu vào, nhưng trong NLP chúng ta thường sử dụng các bộ lọc trượt qua tất cả các dòng của ma trận (words). Do đó bộ lọc của chúng ta sẽ - độ rộng bằng độ rộng của matrix, chiều dài có thể thay đổi nhưng thông thường chúng ta sẽ trượt qua 2-5 từ. Như vậy bạn đã có thể mường tượng rõ ràng việc áp dụng CNNs vào NLP như thế nào rồi đúng không. Chúng ta sẽ xem mô tả hình bên dưới để dễ hình dung hơn nữa nhé
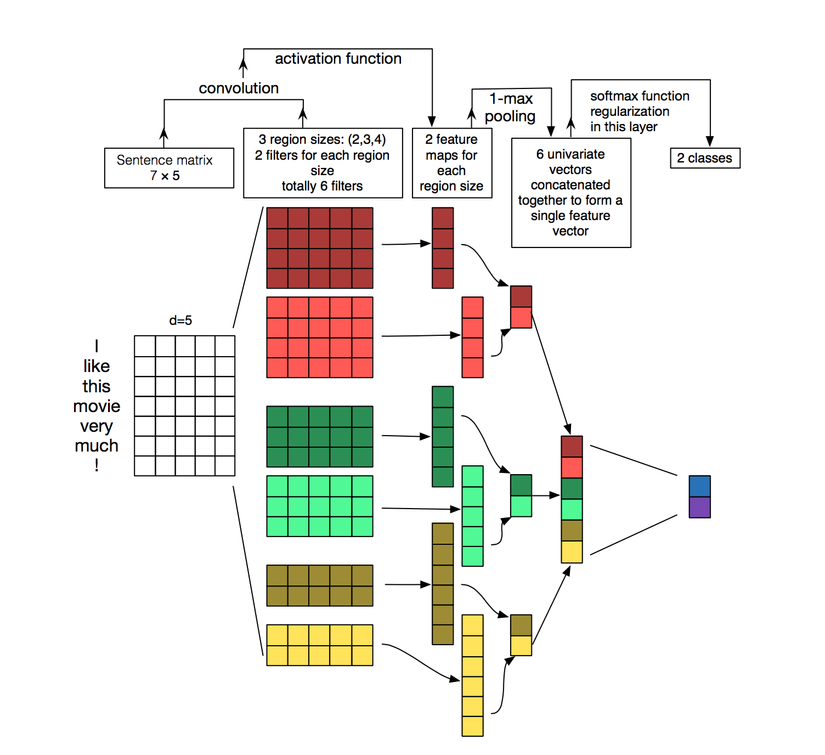 Sơ đồ trên chúng ta có matrix đầu vào cho 1 mệnh đề "I like this movie very much1" Nó sẽ là một matran với độ rộng là 5 và chiều dài là 7 dòng, tiếp theo như mô tả ta sẽ có các vùng để phân tích và kích thước sẽ là width-7, heigth tùy biến (2,3,4) và chúng ta sẽ apply 2 bộ lọc cho từng vùng, sau colvolution đầu tiên ta sẽ có 6 output, tiếp theo sử dụng max-pooling để tìm đặc trưng cao nhất cho mỗi vùng, output layer 2 sẽ còn 3, chúng ta sẽ biến đổi để đưa 3 vector đơn này thành chung 1 vector cho 1 chức năng phân tích (cũng là input layer tiếp theo) cuối cùng softmax để đưa ra 2 lớp output cuối
Sơ đồ trên chúng ta có matrix đầu vào cho 1 mệnh đề "I like this movie very much1" Nó sẽ là một matran với độ rộng là 5 và chiều dài là 7 dòng, tiếp theo như mô tả ta sẽ có các vùng để phân tích và kích thước sẽ là width-7, heigth tùy biến (2,3,4) và chúng ta sẽ apply 2 bộ lọc cho từng vùng, sau colvolution đầu tiên ta sẽ có 6 output, tiếp theo sử dụng max-pooling để tìm đặc trưng cao nhất cho mỗi vùng, output layer 2 sẽ còn 3, chúng ta sẽ biến đổi để đưa 3 vector đơn này thành chung 1 vector cho 1 chức năng phân tích (cũng là input layer tiếp theo) cuối cùng softmax để đưa ra 2 lớp output cuối
CNN Hyperparameters
Trước khi giải thích cách CNNs được áp dụng cho việc xử lí ngôn ngữ tự nhiên như thế nào, hãy xem xét một số lựa chon bạn cần thực hiện khi xây dựng CNN. Nó sẽ giúp chúng ta hiểu rõ hơn về CNNs.
Narrow vs. Wide convolution
Phía trên khi chúng ta nó về việc áp dụng các bộ lọc thì có một vấn đề đó là khi sử dụng bộ lọc 3x3 tại trung tâm của ma trận sẽ rất fine, vậy khi nó đẩy về các cạnh thì sẽ như thế nào.( các điểm ở ngoài lề của ma trận khi chúng ta không thể tính tích chập cho chúng nếu như muốn đẩy ra output đầy đủ ) Vậy làm thế nào để áp dụng các bộ lọc mà không có bất kỳ yếu tố về điểm lân cận top hoặc bên trái , phải.. Khi đó chúng ta sẽ áp dụng zero-padding, tất cả các phần tử nằm bên ngoài ma trận được tính bằng 0. Với cách này chúng ta có thể áp dụng bộ lọc cho tất cả các phần của ma trận đầu vào, và khi đó sẽ đưa ra được một ma trận output có kích thước lớn hơn hoặc bằng ma trận đầu vào. Việc thêm zero-padding được gọi là wide convolution ( xoắn rộng) và việc không sử dụng zero-padding được gọi là narrow convolution ( xoắn hẹp). Hình bên dưới thể hiện xoắn hẹp và xoắn rộng
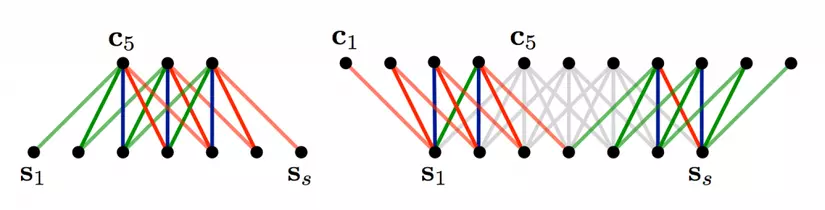 Bạn có thể thấy được wide convolution là rất hữu ích, khi bạn có bộ lọc lớn liên quan đến kích thước đầu vào. Phía trên ta có output size của narrow convolutions : (7-5) +1 = 3, và wide convolution output: ( 7 + 2 4 -5) +1 = 11. Công thức tính output sẽ là n_out=(n_in + 2n_padding - n_filter) + 1
Bạn có thể thấy được wide convolution là rất hữu ích, khi bạn có bộ lọc lớn liên quan đến kích thước đầu vào. Phía trên ta có output size của narrow convolutions : (7-5) +1 = 3, và wide convolution output: ( 7 + 2 4 -5) +1 = 11. Công thức tính output sẽ là n_out=(n_in + 2n_padding - n_filter) + 1
Stride Size
Một khái niệm nữa trong convolutions là stride size ( bước trượt), nó định nghĩa bạn muốn các bộ lọc có bước trượt dài bao nhiêu. Trong các ví dụ phía trên ta thấy stride size là 1, và các bộ lọc sẽ cho ra output lớn, lặp lại nhiều. Với bước trược lớn hơn thì sẽ tạo ra ít hơn các output ( ở đây mình không nó là số lượng output ít hơn thì sẽ tốt hơn). Phía dưới ví dụ khi áp dụng stride size 1,2 vào cùng một đầu vào.
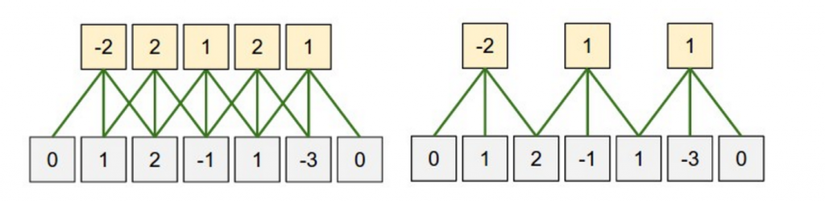 Có thể bạn sẽ hay nhìn thấy stride size là 1, nhưng nếu áp dụng bước trượt lớn hơn thì nó cho phép bạn xậy dựng model tương tự như mạng thần kinh.
Có thể bạn sẽ hay nhìn thấy stride size là 1, nhưng nếu áp dụng bước trượt lớn hơn thì nó cho phép bạn xậy dựng model tương tự như mạng thần kinh.
Pooling Layers
Một khía cạnh nữa của Convolutional Neural Networks là các lớp pooling, thông thường nó sẽ được áp dụng sau các lớp convolutional. Phần lớn cách để tập hợp chính là áp dụng lấy max của các kết quả mỗi bộ lọc. Và chúng ta không cần phải pool cho ma trận output sau mỗi colvolution layer mà có thể áp dụng ngay trên từng bộ lọc.
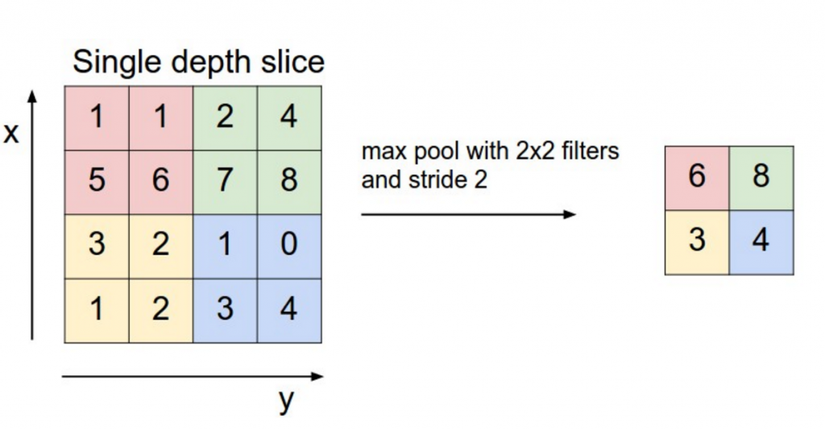
Vậy tại sao chúng ta cần phải gộp, phải hợp các output lại. Có hai lí do đấy là:
- Pooling sẽ hỗ trợ việc cố định kích thước ma trận đầu ra. Ví dụ khi bạn có 1000 bộ lọc, bạn áp dụng tối đa pooling cho mỗi bộ lọc thì nó sẽ tạo ra 1000 chiều output, không cần quan tâm kích thước các bộ lọc hoặc kích thước đầu vào nhưng nó sẽ lấy được cùng kích thước output đầu ra.
- Pooling còn giảm chiều của ma trận đầu ra "nhưng" vẫn giữ được thông tin nổi mật nhất của output từng bộ lọc, ở đây dùng từ "NHƯNG" vì trong thực tế chưa chắc là đúng. Bạn hãy suy nghĩ nếu mỗi bộ lọc nhận ra được một tính năng cụ thể, chả hạn nếu phát hiện trong câu có chứa cụm từ tiêu cực như "not amazing", nếu cụ từ này xảy ra ở nơi nào trong cầu, thì kết quả khi áp dụng bộ lọc tại vùng đó sẽ mang giá trị lớn, và nó sẽ đưa ra giá trị thấp với các vùng khác không xuất hiện. Bằng việc thực hiện thao tác tối đa, bạn đang giữ được thông tin về việc có hay không việc xuất hiện của tính năng đấy trong mệnh đề input, nhưng đồng thời bạn cũng sẽ mất thông tin về nơi nào nó xuất hiện. Nhưng việc biết thông tin nơi xuất hiện có thực sự hữu ích. Điều này có phần tương tự như trong n-grams model đang sử dụng. Bạn mất thông tin global về vị trí ( nơi mệnh đề xuất hiện), nhưng bạn đang giữ thông tin về những gì bộ lọc đưa ra ( ví dụ nhận biết được "not amazing" khác so với "amazing not") Trong nhận dạng ảnh, pooling cũng hỗ trợ các phép cố định là dịch và xoay. Khi bạn đang kết hợp các vùng nhận diện, các output sẽ giữ nguyên độ chênh lệch nếu như bạn dịch hoặc xoay image với một vài pixels, bởi vì thao tác lấy max sẽ giúp bạn chọn ra cùng một giá trị.
Channels
Khía cạnh cuối cùng đó là các kênh, Kênh chính là các chế độ xem khách nhau đối với tập dữ liệu của bạn. Ví dụ, khi nhận diện hình ảnh, bạn thường có các kênh RGB. Bạn có thể áp dụng "convolutions" qua các kênh có trọng lượng khác hoặc giống nhau. Trong xử lí ngôn ngữ tự nhiên, bạn có thể hình dung các kênh khác nhau như khi bạn có một kênh cho các từ khác nhau (word2vec hay Glove), hoặc bạn có một kệnh cho cùng một câu đại diện trong nhiều ngôn ngữ khác nhau, hoặc cách thể hiện khách nhau của cùng một từ.
Convolutional Neural Networks applied to NLP
Những mô hình thích hợp nhất với CNNs, thường là các chức năng phân loaijm chẳng hạn như Sentiment Analysis(phân tích cảm xúc), Spam Detection (phân tích chủng loại) or Topic Categorization (phân tích chủ đề). Như trên đã nói Convolution và Pooling sẽ mất thông tin về vị trí xuẩ hiện của từ, do đó việc gắn thẻ theo thứ tự như trong Pos Tagging hoặc Entity Extraction khó phù hợp với cấu trúc CNN, mặc dùng chúng ta có thể gắn thẻ nếu thêm các tính năng định vị tại đầu vào.
 Để có thể thấy được cách áp dụng cũng như đánh giá chúng ta cần xem kết quả của từng pager dưới đây:
Rất tiếc trong này mình chưa biết trình bày sao cho từng paper này, có lẽ phần sau mình đi dần vào demo hoặc follow từng pager và cùng chia sẻ với mọi người. Thân
Để có thể thấy được cách áp dụng cũng như đánh giá chúng ta cần xem kết quả của từng pager dưới đây:
Rất tiếc trong này mình chưa biết trình bày sao cho từng paper này, có lẽ phần sau mình đi dần vào demo hoặc follow từng pager và cùng chia sẻ với mọi người. Thân
[1] Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), 1746–1751. [2] Kalchbrenner, N., Grefenstette, E., & Blunsom, P. (2014). A Convolutional Neural Network for Modelling Sentences. Acl, 655–665. [3] Santos, C. N. dos, & Gatti, M. (2014). Deep Convolutional Neural Networks for Sentiment Analysis of Short Texts. In COLING-2014 (pp. 69–78). [4] Johnson, R., & Zhang, T. (2015). Effective Use of Word Order for Text Categorization with Convolutional Neural Networks. To Appear: NAACL-2015, (2011). [5] Johnson, R., & Zhang, T. (2015). Semi-supervised Convolutional Neural Networks for Text Categorization via Region Embedding. [6] Wang, P., Xu, J., Xu, B., Liu, C., Zhang, H., Wang, F., & Hao, H. (2015). Semantic Clustering and Convolutional Neural Network for Short Text Categorization. Proceedings ACL 2015, 352–357. [7] Zhang, Y., & Wallace, B. (2015). A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification, [8] Nguyen, T. H., & Grishman, R. (2015). Relation Extraction: Perspective from Convolutional Neural Networks. Workshop on Vector Modeling for NLP, 39–48. [9] Sun, Y., Lin, L., Tang, D., Yang, N., Ji, Z., & Wang, X. (2015). Modeling Mention , Context and Entity with Neural Networks for Entity Disambiguation, (Ijcai), 1333–1339. [10] Zeng, D., Liu, K., Lai, S., Zhou, G., & Zhao, J. (2014). Relation Classification via Convolutional Deep Neural Network. Coling, (2011), 2335–2344. [11] Gao, J., Pantel, P., Gamon, M., He, X., & Deng, L. (2014). Modeling Interestingness with Deep Neural Networks. [12] Shen, Y., He, X., Gao, J., Deng, L., & Mesnil, G. (2014). A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval. Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management – CIKM ’14, 101–110. [13] Weston, J., & Adams, K. (2014). # T AG S PACE : Semantic Embeddings from Hashtags, 1822–1827. [14] Santos, C., & Zadrozny, B. (2014). Learning Character-level Representations for Part-of-Speech Tagging. Proceedings of the 31st International Conference on Machine Learning, ICML-14(2011), 1818–1826. [15] Zhang, X., Zhao, J., & LeCun, Y. (2015). Character-level Convolutional Networks for Text Classification, 1–9. [16] Zhang, X., & LeCun, Y. (2015). Text Understanding from Scratch. arXiv E-Prints, 3, 011102. [17] Kim, Y., Jernite, Y., Sontag, D., & Rush, A. M. (2015). Character-Aware Neural Language Models.
All rights reserved
