Tự xây dựng hệ thống chặn bình luận rác đơn giản
Bài đăng này đã không được cập nhật trong 6 năm
Bình luận rác (bình luận spam url, bình luận có nội dung khiếm nhã, bình luận có chứa thông tin cá nhân nhạy cảm,…) là vấn đề mà các website từ tin tức, thương mại điện tử, rao vặt, blog,… phải đối mặt hàng ngày. Do đó, nếu chúng ta có thể xây dựng một hệ thống chặn/cảnh báo những bình luận rác này thì vấn đề sẽ được giải quyết nhẹ nhàng hơn rất nhiều.
Bài viết gốc được đăng trên blog cá nhân của mình: Tự xây dựng hệ thống chặn bình luận rác đơn giản

Trong bài viết này, mình xin chia sẻ kinh nghiệm tự xây dựng một hệ thống hỗ trợ chặn bình luận rác theo cách cực kỳ đơn giản nhưng lại có hiệu quả khá cao. Hơn hết, nó có thể dễ dàng triển khai cho các sản phẩm nhỏ mà không tốn kém chi phí, công sức là bao.
Nhìn nhận vấn đề bình luận rác
Để nhìn nhận bài toán này chi tiết hơn, chúng ta cần phân tách từng loại bình luận rác. Phân tích đặc điểm của chúng để đưa ra cách giải quyết hợp lý. Dưới đây là một cách nhìn nhận đơn giản:
Có một loại bình luận spam với mục đích cố gắng đặt link website của họ lên web của bạn. Với loại này, nội dung bình luận chắc chắn sẽ có url. Do đó, bạn có thể dụng thông tin này để kiểm tra. VD:
-
Các bình luận để lại thông tin cá nhân nhạy cảm, thì thường các thông tin đó cũng có cấu trúc; chẳng hạn như email, số điện thoại. Các thông tin này chúng ta cũng có thể kiểm chứng bằng các luật được. (Mục đích là không để lộ thông tin cá nhân của khách hàng, bảo vệ khách hàng).
-
Một loại phổ biến nhất là các bình luận mang nội dung nhạy cảm, tục tĩu. Các bình luận này thường chứa các từ ngữ bậy bạ, tục tĩu kèm theo.
-
Một loại khó nhằn khác là các bình luận mỉa mai, hàm ý chê bai, chửi bới nhưng không có các từ tục tĩu 🙂 Nhưng loại này thường ít hơn.
Với 2 loại đầu tiên, chúng ta hoàn toàn có thể sử dụng regular expression để kiểm tra một cách đơn giản bằng bất kỳ ngôn ngữ lập trình phổ biến nào. Còn với thể loại cuối cùng thì mình xin phép không bàn tới trong bài viết này. Mình đã từng tiếp cận loại mỉa mai, châm biếm này theo phương pháp phân lớp sử dụng fasttext nhưng nó không hiệu quả. Không rõ giờ đây với sự phát triển của deeplearning và context embedding thì nó có giải quyết được bài toán này không. Nhưng nhìn chung là khá khó và mình chưa có cơ hội thử 😀
Do đó, phần còn lại của bài viết sẽ trình bày về phương pháp để xử lý loại bình luận rác thứ 3 ở trên
Bài toán có những khó khăn nào?
-
Nếu áp dụng theo phương pháp học máy, bài toán phân lớp văn bản (text classification), khó khăn lớn nhất của bài toán chính là dữ liệu phải được gán nhãn (mỗi bình luận cần phải biết trước nó có phải bình luận rác hay không). Bản thân mình cũng có thử tiếp cận theo hướng này bằng cách gán nhãn theo một vài quy tắc thông qua quan sát dữ liệu. Tuy nhiên mình đã thất bại theo hướng này. Nguyên nhân thì chắc do còn non và xanh quá. Tuy nhiên, theo góc nhìn của mình thì nếu bạn có tiền làm dữ liệu thì có thể theo hướng này, hoặc thử bằng cách tối ưu mô hình phân lớp qua nhiều lần vậy.
-
Dữ liệu bình luận rất là rác, rác ở đây mình muốn nói là sai chính tả rất nhiều. Từ cách viết tắt, gõ không dấu, sử dụng teencode (cách viết của giới trẻ),… là những khó khăn lớn đối với bài toán này. Và nó là vấn đề bạn cần giải quyết nếu bạn dùng phương pháp học máy ở ý trên.
-
Bài toán muốn triển khai được phải đảm bảo độ chính xác cao, bạn hiểu câu “thà giết nhầm còn hơn bỏ xót” chứ. Thực tế cũng vậy, bạn không được phép bỏ lọt bình luận rác đặc biệt là những nội dung nhạy cảm với hệ thống của bạn. Nó chính là việc bạn phải tăng recall nếu áp dụng mô hình phân lớp cho bài toán này.
Giải pháp chặn bình luận rác
Như mình có phân tích với bình luận loại 3 ở trên, chúng sẽ kèm theo các từ/cụm từ nhạy cảm, và loại này là loại bình luận rác xuất hiện nhiều nhất cũng như có mức độ nguy hiểm cao nhất cần phải loại trừ. Do đó, hướng tiếp cận của mình là sử dụng từ điển để loại bỏ: Kiểm tra một bình luận, nếu trong bình luận đó có từ nhạy cảm thì kết luận đó là bình luận rác.
Nhưng vấn đề đặt ra là lấy đâu một danh sách đầy đủ các từ/cụm từ nhạy cảm để mà sử dụng?
Nếu bạn đã từng sử dụng qua mô hình word embedding word2vec thì ắt hẳn bạn phải biết tới khái niệm “word similarity (từ tương đồng)”. Nó có thể coi là một cách đánh giá mô hình word2vec của bạn có thực sự tốt hay không!
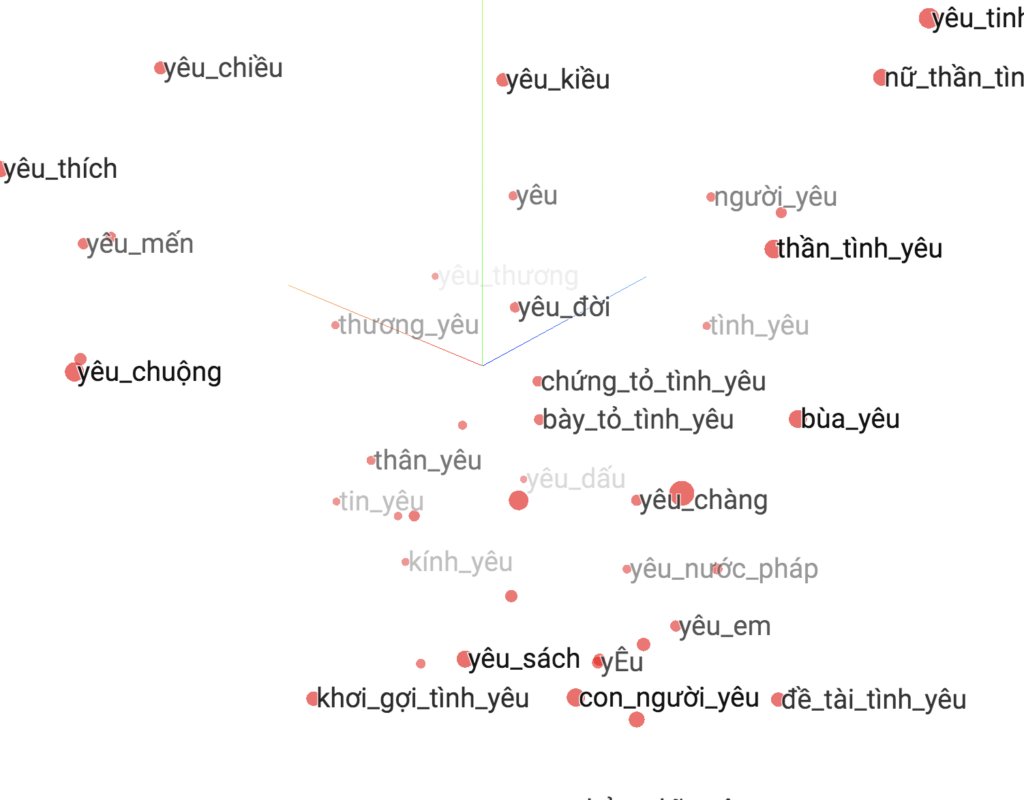
Hình ảnh mô phỏng biểu diễn của word2vec trong không gian, source: https://github.com/sonvx/word2vecVN
Trên thực tế, mô hình word2vec học bằng cách sử dụng các từ lân cận nó theo một cửa sổ từ cố định mà bạn chỉ định. Do đó, các từ đồng nghĩa hoặc có nghĩa gần giống nhau sẽ thường nằm trong cùng ngữ cảnh với nhau. Kết quả là sau khi mô hình học xong, giá trị vector của những từ gần nghĩa nhau sẽ có khoảng cách gần nhau. Nhìn vào các câu này bạn sẽ thấy ngay:
-
(1)
anhlà ai giữa cuộc đời này, (2)emlà ai giữa cuộc đời này -
(1) anh
yêuem, (2) anhnhớem -
(1) tao
đếchcần, (2) taođéocần
Từ bài toán tìm từ tương tự trên, mình đã nảy ra giải pháp cho bài toán xây dựng bộ từ điển từ nhạy cảm trong tiếng Việt như sau:
-
Xây dựng bộ từ điển nhạy cảm khởi tạo ban đầu. Cái này không cần đầy đủ, chỉ là càng nhiều càng tốt; Bạn có thể làm việc này bằng cách tự viết ra hoặc thu thập qua internet.
-
Huấn luyện mô hình word2vec với dữ liệu mạng xã hội, diễn đàn, hoặc wikipedia cũng là một kho dữ liệu rất phù hợp. Tránh sử dụng dữ liệu tin tức vì dữ liệu tin tức không có những từ nhạy cảm chúng ta cần. Tập dữ liệu của bạn càng lớn càng tốt, ít thì cũng nên cỡ vài GB trở lên.
-
Mở rộng từ điển ở (1) bằng cách đưa từng từ vào mô hình word2vec đã huấn luyện ở (2) và lấy ra top các từ tương tự. Bạn cần review các từ tương tự mà mô hình word2vec cho ra để đảm bảo không lẫn với các từ mà bạn không mong muốn.
-
Làm lại bước (3) từ 2 đến 3 lần là bạn đã có bộ từ điển từ nhạy cảm mà bạn cần; Nếu có thể, bạn có thể huấn luyện các mô hình word2vec với dữ liệu mới để tìm kiếm các từ nhạy cảm mới.
Sau khi có từ điển thì việc còn lại của bạn là đem nó đi sử dụng cho hệ thống chặn bình luận rác tự động rồi. Tất nhiên là chúng ta có thể làm thêm một vài chức năng nữa để sử dụng bộ từ điển này một cách hiệu quả nhất.
Bạn có thể tham khảo bộ từ điển từ nhạy cảm này do mình xây dựng tại đây.
Đó, như vậy là chỉ với bài toán word similarity và chúng ta có thể giải quyết được phần gian nan nhất của bài toán chặn bình luận rác rồi. Thời gian để bạn có thể xây dựng bộ từ điển này không quá lâu, chắc vào khoảng 1 tuần hoặc ít hơn là có thể xong bài toán.
Ưu nhược điểm của phương pháp
Phương pháp nào cũng có những ưu điểm và nhược điểm của nó. Và phương pháp sử dụng từ điển mình đề xuất cũng không ngoại lệ. Dưới đây là những đánh giá của bản thân mình về phương pháp đề xuất.
Nhìn chung, giải pháp này giải quyết tương đối tốt trong khi thời gian và chi phí triển khai là không tốn kém là bao.
Về ưu điểm trước:
-
Đơn giản về chi phí và thời gian thực hiện. Do dữ liệu thì bạn có thể lấy từ wiki dump, từ social comment (comment youtube tiếng Việt khá dồi dào, dự án social-crawler của mình có lẽ có ích để làm việc này đấy). Dữ liệu chỉ việc lấy về và đưa vào mô hình word2vec, mình dùng fasttext word2vec để huấn luyện vì nó không đòi hỏi nhiều về phần cứng cũng như ưu điểm về thời gian huấn luyện rất nhanh. Fasttext cũng có cung cấp pretrain với dữ liệu wiki dump tiếng Việt rồi, có thể tải về và dùng luôn.
-
Loại được cả những thể loại bình luận có chứa từ nhạy cảm ở dạng teencode, viết tắt,… do mô hình word2vec học được cả những từ như vậy từ dữ liệu mà.
-
Đảm bảo tốc độ xử lý nhanh, do sử dụng từ điển nên việc kiểm tra không tốn nhiều chi phí tính toán.
-
Sử dụng từ điển có thể ngay lập tức thêm từ nhạy cảm vào; so với sử dụng phương pháp học máy bạn phải huấn luyện lại mô hình.
Về nhược điểm của phương pháp:
-
Không thể xử lý các bình luận khiếm nhã khi từ điển bị thiếu từ. Do đó, mình mới nhấn mạnh yếu tố “từ điển đầy đủ”.
-
Dạng bình luận viết không dấu khó mà phát hiện được.
-
Có thể bắt nhầm bình luận đẹp khi từ điển có các từ nhập nhằng, ví dụ từ chó 🙂
Đề xuất tối ưu bài toán
Hiện nay, mình đã không còn làm bài toán này nữa. Tuy nhiên, chúng ta vẫn có thể làm cho bài toán này tốt lên rất nhiều bằng một số đề xuất chủ quan của mình. Mình thực sự rất hoan nghênh bạn đọc nếu có ý tưởng hay cho bài toán này có thể chia sẻ ạ.
-
Nếu sử dụng phương pháp này làm phương pháp chính, nên thường xuyên cập nhật lại từ điển. Bởi vì từ điển tiếng Việt cũng phát triển theo thời gian mà 🙂
-
Nếu sử dụng phương pháp này làm phương pháp chính, với các từ nhập nhằng nên tìm cách loại bỏ hoặc hạn chế những nhập nhằng đó bằng cách mở rộng cửa sổ từ cho các từ nhập nhằng đó. Ví dụ: quả óc chó thì không có gì nhạy cảm hết.
-
Có thể tiền xử lý bình luận trước khi đưa vào kiểm tra (áp dụng cho cả phương pháp học máy và phương pháp từ điển): như xử lý teencode, danh sách một số từ teencode tiếng Việt phổ biến, và thêm dấu câu cho bình luận không dấu, tham khảo giải pháp ở đây để tăng độ chính xác của bài toán.
-
Sau khi triển khai giải pháp này, chúng ta nên đầu tư vào xây dựng mô hình học máy end2end để giải quyết bài toán giúp bài toán đạt kết quả tốt hơn và dễ quản lý, triển khai hơn.
Cảm ơn các bạn đã quan tâm, rất mong nhận được những ý kiến đóng góp từ các độc giả và các chuyên gia!
All rights reserved
