Trò chuyện với Lê Viết Quốc(Quoc Le), chuyên gia trí tuệ nhân tạo phía sau sự thành công của Google AutoML
Bài đăng này đã không được cập nhật trong 7 năm
Bài viết được dịch theo bài báo A Conversation With Quoc Le: The AI Expert Behind Google AutoML của nhà báo Tony Peng và biên tập viên Michael Sarazen.

Là một thành viên sáng lập của Google Brain cũng là người đứng đằng sau sự thành công của AutoML- một sự đột phá trong công nghệ trí tuệ nhân tạo, Quốc Lê được biết đến là một chuyên gia yêu thích học máy và thích tự động hóa mọi thứ.
Khi còn là tiến sĩ của đại học Stanford năm 2011, ông đã sử dụng hàng triệu ảnh thu nhỏ từ Youtube để phát triển hệ thống học không giám sát giúp nhận ra mèo từ ảnh, một trong những cột mốc khởi đầu trong thành công của Deep learning.
Năm 2014, với việc sử dụng các kỹ thuật Deep learning và hệ thống chuyển đổi tự động một từ/đoạn văn thành vector, ông đã nâng cao được hiệu suất dịch máy(Google translate) và đặt nền tảng cho các đột phá tiếp theo của Google trong dịch máy neural.

Cũng từ năm 2014, ông bắt đầu nghiên cứu về phương pháp học máy tự động(AutoML), với mục tiêu có thể tự động hóa việc xây dựng các mô hình học tập sử dụng mạng neural. Các nhà nghiên cứu cố gắng xây dựng các mô hình học máy khác nhau và tối ưu tham số cho các mô hình đó, đánh giá hiệu năng trên 1 tập dữ liệu sau đó lại tiếp tục quay lại tối ưu lại tham số cho đến khi thu được mô hình tốt nhất. Ông thấy đây là một vấn đề trial-and-error(thử và sai) và có thể giải quyết bằng Machine learning.
Năm 2016, ông đã hợp tác với một nhà nghiên cứu khác tại Google Brain và công bố tài liệu nghiên cứu Neural Architecture Search with Reinforcement Learning. Ý tưởng cốt lõi giống như việc xây dựng các blocks: Máy tính thực hiện việc chọn các thành phần cần thiết từ một không gian xác định để xây dựng mạng thần kinh và sau đó cải thiện độ chính xác của nó bằng việc sử dụng sử dụng kỹ thuật trial-and-error, đó chính là việc học tăng cường. Kết quả là đầy hứa hẹn vì máy tính có thể tạo ra mô hình phù hợp có hiệu suất ngang bằng hiệu suất của con người trong 1 số nhiệm vụ.
Nghiên cứu của ông đã góp phần tạo ra Google Cloud AutoML, một nhóm các công cụ cho phép các nhà phát triển có kiến thức hạn chế về học máy có thể đào tạo các mô hình chất lượng cao. Không quá ngạc nhiên khi AutoML nhanh chóng trở thành chủ đề phố biến với những gã khổng lồ về công nghệ và các start-up theo dấu chân của Google và đặt cược vào công nghệ mới.
 Google Cloud released AutoML vision earlier this year, followed by AutoML translation and language.
Google Cloud released AutoML vision earlier this year, followed by AutoML translation and language.
Trong một buổi phỏng vấn, chuyên gia AI 36 tuổi đến từ Việt Nam đã nói về cảm hứng của ông và kỹ thuật đằng sau cũng như con đường phía trước của AutoML, vai trò quan trọng của nó trong lĩnh vực học máy.
Nguồn cảm hứng
Khi nào ông bắt đầu nghĩ về việc thiết kế một kiến trúc mạng neural mới và điều gì đã truyền cảm hứng cho ông?
Tôi là một kỹ sư về học máy. Khi bạn làm việc với mạng neural thự sự nhiều, bạn sẽ nhận thấy là rất nhiều thành phần trong số chúng yêu cầu sự điều chỉnh thủ công, những gì mọi người vẫn gọi là tối ưu siêu tham số- số lớp trong mạng thần kinh, tốc độ học tập và loại lớp nào được cho vào các mạng này.
Các nhà nghiên cứu về AI có khuynh hướng bắt đầu với một số nguyên tắc và sau đó, theo thời gian, các nguyên tắc dần bị phá vỡ và họ cố gắng thử mọi cách khác nhau. Tôi đã quan sát một số nhà phát triển trong các cuộc thi ImageNet và tôi đã thấy sự phát triển của mạng Inception tại Google.
Tôi bắt đầu suy nghĩ không rõ ràng về những gì tôi muốn làm. Tôi thích các mạng Convolutional, nhưng tôi không thích thực tế rằng trọng số trong một mạng convolutional không được chia sẻ với nhau. Vì vậy, tôi nghĩ rằng có lẽ tôi nên phát triển một cơ chế để làm như nào các trọng số được chia sẻ với nhau trong cùng 1 mạng.
Những gì các nhà nghiên cứu làm là họ lấy một loạt các khối mạng hiện có sau đó thử chúng. Họ thấy một số cải thiện về độ chính xác và sau đó họ nói: "Được rồi, có lẽ tôi vừa có một ý tưởng hay. Làm thế nào để giữ những thứ tốt trong cải tiến này lại và thay thế một số chỗ chưa được cải tiến bằng cái gì đó mới hơn?" Họ tiếp tục quá trình đó và có thể thử hàng trăm kiến trúc khác nhau.
Khoảng năm 2016, tôi bắt đầu nghĩ răng nếu có quá trình đòi hỏi quá nhiều phép thử và sai, chúng ta nên tự động hóa việc đó bằng việc sử dụng học máy bởi bản thân học máy cũng dựa trên phép thử và sai.
Tôi không ngờ rằng nó sẽ thành công như vậy. Tôi nghĩ rằng điều tốt nhất chúng tôi có thể làm là có thể bằng khoảng 80% khả năng của con người và đó sẽ là một thành công. Nhưng người bạn hợp tác với tôi làm tốt đến mức anh ấy thực sự có thể bằng với hiệu năng của con người.
Rất nhiều người nói với tôi: "Anh đã dành nhiều thời gian và công sức ra chỉ để máy có thể bằng khả năng của con người?" Nhưng những gì tôi thấy từ thí nghiệm đó là việc học tự động hiện nay là có thể. Nó chỉ còn là vấn đề về khả năng mở rộng. Vì vậy, nếu bạn mở rộng hơn, bạn sẽ có kết quả tốt hơn, chúng tôi tiếp tục tham gia dự án thứ hai và chúng tối đã mở rộng hơn và làm việc trên ImageNet và sau đó kết quả bắt đầu trở nên thực sự đầy hứa hẹn.
Sự khác nhau giữa việc tìm kiếm 1 kiến trúc mạng như trước đây với nghiên cứu hiện tại của ông là gì?
Nó khác với những gì tôi đã làm trước đây trong lĩnh vực thị giác máy tính. Cuộc hành trình đến từ 1 ý nghĩ và lớn lên theo thời gian. Tôi cũng có một số ý tưởng sai lầm. Ví dụ tôi muốn tự động hóa và xây dựng lại các convolution, nhưng điều đó đã là ý tưởng tồi. Có lẽ tôi nên chấp nhận các convolution và sau đó sử dụng chúng để xây dựng cái gì khác. Đó là một quá trình học tập của tôi, nhưng nó không quá tệ.
Về công nghệ
Các nhà nghiên cứu hay kĩ sư cần xây dựng một mô hình mạng neural bằng việc lựa chọn các thành phần nào?
Nó có sự thay đổi một chút giữa các ứng dựng với nhau, vì vậy hãy thu hẹp xuống bài toán thị giác máy tính trước- và ngay cả trong thị giác máy tính, vẫn còn rất nhiều thứ đang diễn ra. Thông thường trong một mạng convolution bạn có đầu vào là hình ảnh và sau đó là đến lớp convolution và rồi đến lớp pooling, batch normalization. Và sau đó có một hàm kích hoạt, bạn quyết định thực hiện kết nối tới một lớp khác hoặc những thứ tương tự.
Trong các khối convolution, bạn có thể có nhiều quyết định bổ sung. Ví dụ trong convolution, bạn phải quyết định size của filter là 1x1, 3x3 hay 5x5. Bạn cũng phải quyết định trong pooling layer và batch norm. Về skip connection, bạn có thể chọn từ layer 1 đến layer 10 hoặc từ layer 1 đến layer 2. Vì vậy, có rất nhiều quyết định được đưa ra và một số lượng lớn các kiến trúc có thể có. Có thể có một nghìn tỷ khả năng nhưng con người bây giờ chỉ nhìn vào một phần nhỏ của những thứ có thể.
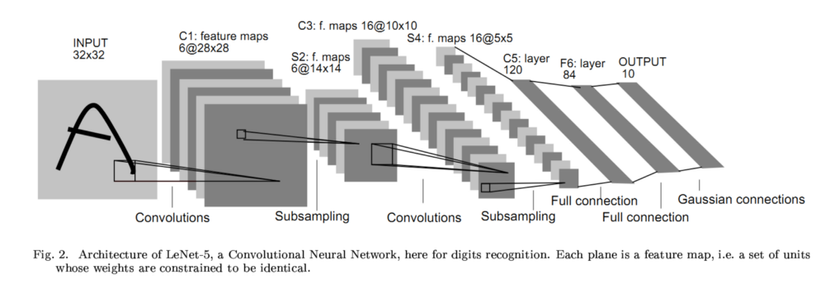
Bài viết đầu tiên của ông về AutoML là Neural Architecture Search (NAS) with Reinforcement Learning được công bố vào năm 2016. Kể từ đó nhóm của ông đã sử dụng các thuật toán tiến hóa và bắt đầu sử dụng tìm kiếm kiến trúc thần kinh cấp tiến. Ông có thể giải thích về những cải tiến này không?
Trong bài báo gốc, chúng tôi bắt đầu với việc học tăng cường bởi vì chúng tôi thấy việc này giống như con người làm, bạn có thể thử và sai. Chúng tôi đã làm rất nhiều thí nghiệm và đạt được một số thành công và nhận ra rằng quá trình này có thể được thực hiện bằng cách sự dụng sự tiến hóa, vì vậy chúng tôi đã thay đổi thuật toán cốt lõi.
Một trong những thay đổi lớn là việc sử dụng ENAS(Efficient Neural Architecture Search). Khi bạn tạo ra nhiều kiến trúc, mỗi kiến trúc được đào tạo và đánh giá độc lập so với phiên bản trước. Vì vậy, bạn thường không chia sẽ bất kỳ kiến thức hoặc thông tin nào trước đó. Nhưng giả sử bạn phát triển một cơ chế chia sẻ và bạn có thể kế thừa một số trọng số từ mạng neural được đào tạo trước đó thì việc huấn luyện của bạn sẽ nhanh hơn rất nhiều. Vì vậy chúng tôi đã làm điều đó.
Về cơ bản ý tưởng là bạn tạo một mạng khổng lồ có tất cả các khả năng trong đó và sau đó tìm kiếm một đường dẫn trong mạng để tối đa hóa hiệu năng đạt được, đó là một kiến trúc mạng mà bạn đang tìm kiếm. Một số trọng số được sử dụng lại trong các thử nghiệm tiếp theo. Vì vậy, có rất nhiều sự chia sẻ trọng số được diễn ra. Thuật toán NAS ban đầu là cách linh hoạt hơn, nhưng nó lại khá tốn kém chi phí tính toán. Về cơ bản, đây là một thuật toán mới và nhanh hơn, nhưng nó cũng hạn chế hơn một chút.
Thuật toán NAS ban đầu có thể tạo ra các kiến trúc tốt hơn cũng như các siêu tham số tốt hơn, các chiến lược thêm dữ liệu tốt hơn, một hàm kích hoạt tốt hơn, một sự khởi tạo tốt hơn và bất cứ thứ gì khác. Cho đến nay chúng tôi đã chỉ quản lý để sử dụng thuật toán ENAS mới cho kiến trúc, không phải ví dụ để mở rộng dữ liệu cũng như không phải trình tối ưu hóa.
Điều đó có nghĩa là các thành phần khác được tạo bởi con người?
Chúng tôi đã xác định kiến trúc và data augmentation là 2 lĩnh vực chính rất khó để các chuyên gia thiết kế. Vì vậy bạn nhận được rất nhiều lợi thế khi bạn có được 2 điều đó một cách tự động. Hầu hết thời gian của bạn chỉ sử dụng các phương pháp tối ưu phổ biến và chuẩn hóa thông dụng. Chúng tôi chỉ tập trung vào tự động hóa các thành phần mang lại nhiều lợi ích nhất.
Hiện tại ENAS vẫn đang được phát triển. Vẫn còn nhiều thử nghiệm cần được nghiên cứu đang diễn ra nhanh chóng.
Tôi đã nghe một start-up đang sử dụng một kỹ thuật gọi là generative synthesis. Cũng có lẽ GANs. Những ưu và khuyết điểm của các thuật toán tìm kiếm khác nhau là gì?
Tôi không chắc chắn về việc ai đang thực sự sử dụng GAN để tạo ra kiến trúc mạng. Tôi nghĩ điều đó là có thể, mặc gì tôi không quen với điều đó.
Học máy tiến hóa và học tăng cường tương tự như nhau, nhưng một lần nữa, nếu bạn không đưa ra bất kì giả định nào, chúng ta có thể đi khá chậm. Vì vậy, mọi người đã phát triển ý tưởng về tìm kiếm kiến trúc thần kinh dựa trên sự tiến hóa, nơi họ bắt đầu tìm kiếm một thành phần nhỏ và sau đó tiếp tục thêm các thành phần mới vào. Đó là một ý tưởng mà tôi nghĩ là rất tốt.
 An overview of Neural Architecture Search.
An overview of Neural Architecture Search.
Nói về ENAS, về cơ bản ý tưởng cốt lõi là sự chia sẻ trọng số. Bạn phát triển một kiến trúc lớn và sau đó tìm một đường dẫn trong nó để tới kiến trúc tốt nhất. ENAS dựa trên một số ý tưởng khác như tìm kiếm kiến trúc một lần, cụ thể là bạn xây dựng mô hình và sau đó tìm cách chia sẻ trọng số giữa chúng. Tôi nghĩ những ưu điểm của phương pháp học tăng cường và thuật toán tiến hóa là chúng rất linh hoạt. Chúng có thể được sử dụng để tự động hóa bất kỳ thành phần nào trong đường ống học máy. Nhưng chúng cũng rất tốn kém. Các thuật toán đặc biệt như ENAS và tìm kiếm kiến trúc dựa trên sự tiến hóa tạo ra một số giả định, vì vậy chúng ít tổng quát và ít linh hoạt hơn, tuy nhiên chúng lại thường nhanh hơn.
Tôi không biết về GAN. Tôi nghĩ mọi người sử dụng GAN để tạo ra hình ảnh tốt hơn, nhưng tôi không nghĩ rằng chúng tốt trong việc tạo ra các kiến trúc tốt hơn.
Trong công nghệ AutoML, kỹ thuật transfer learning được sử dụng như thế nào?
Có hai loại transfer learning. Đầu tiên là transfer kiến trúc, điều đó có nghĩa là bạn tìm được một kiến trúc tốt trên một bộ dữ liệu tổng hợp hình ảnh và transfer sang bài toán phát hiện đối tượng. Một loại khác là transfer trọng số: Bạn có một mạng neural và sau đó bạn huấn luyện trước vào tập dữ liệu của riêng bạn, sau đó bạn lại dùng chúng cho một tập dữ liệu nhỏ khác.
Hãy tạo một kịch bản sau đây: Tôi muốn làm nhiệm vụ phát hiện hoa trong các bức hình. Và ImageNet có khoảng 1 triệu hình ảnh và tập dữ liệu về hoa có khoảng 1000 ảnh hoặc khoảng đó. Bạn có thể tìm thấy kiến trúc tốt nhất từ ImageNet và sau đó sử dụng lại trọng số của nó, hoặc bạn có thể sử dụng một mô hình tốt nhất như Inception V3 và huấn luyện trên ImageNet sau đó sử dụng transfer learning để làm tiếp trên tập dữ liệu về hoa. Phương pháp phổ biến chỉ là transfer trọng số vì hầu hết mọi người không tạo ra cấu trúc. Bây giờ bạn khởi tạo Inception V3 của bạn hoặc ResNet và huấn luyện trên ImageNet. Khi bạn đã huấn luyện xong, tiến hành tinh chỉnh.
Những gì tôi đang cố gắng tranh luận là trong thực tế bạn cần thực hiện transfer cả về kiến trúc lẫn trọng số, có thể được kết hợp như sau:
- Combination One: Bạn thực hiện transfer kiến trúc
- Combination Two: Kiến trúc được tìm kiếm trên bộ dữ liệu của bạn và bạn cố gắng lấy trọng số từ mô hình huấn luyện trên ImageNet
- Combination Three: Về cơ bản bạn sử dụng ResNet và trọng số của nó. Đây là kết quả tốt nhất.
- Combination Zero: Chỉ tìm kiếm kiến trúc mà không cần bất kỳ sự transfer nòa trên tập dữ liệu đích của bạn.
Mỗi kết hợp khác nhau giữa các tập dữ liệu vì đôi khi tập dữ liệu lớn hơn và đôi khi nhỏ hơn. Các sự kết hợp khác nhau hoạt động khác nhau ở các phần của dữ liệu.
Tôi dự đoán rằng vài năm tới Combination Zero, một sự tìm kiếm kiến trúc thuần túy sẽ tạo được mạng với chất lượng tốt hơn. Chúng tôi đã làm rất nhiều nghiên cứu xung quanh phần này và chúng tôi biết nó thực sự tốt hơn.
Những phần nào của AutoML vẫn yêu cầu sự can thiệp của con người?
Chúng tôi phải làm chút công việc để thiết kế không gian tìm kiếm. Chúng tôi phải xác định một không gian nơi có các khối mạng được xây dựng cho convolution network hoặc fully connected network. Có một số quyết định cần được đưa ra vì ngay bây giờ, AutoML có tính toán hạn chế. Chúng tôi không thể tìm kiếm mọi thứ vì không gian tìm kiếm qúa lớn. Vì lý do đó, chúng tôi phải thuyết kế một không gian tìm kiếm nhỏ hơn với tất cả các khả năng.
Thách thức và tương lai của AutoML
Ông thấy điều gì là thách thức lớn nhất trong nghiên cứu AutoML trong hiện tại?
Trong vài năm tới, tôi nghĩ thách thức lớn nhất là làm thể nào để tìm kiếm hiệu quả hơn bởi vì không có nhiều người muốn sử dụng hàng trăm GPU để giải quyết các vấn đề trên một tập dữ liệu nhỏ. Vì vậy, tìm ra cách để làm cho nó thậm chí tiêu tốn ít tài nguyên hơn nhưng không có bất kỳ sự mất cân bằng về chất lượng là một câu hỏi rất lớn.
Thách thức thứ hai sẽ là làm thế nào để cho không gian tìm kiếm được xây dựng bớt thủ công hơn. Bởi vì hiện giờ, không gian tìm kiếm đã có một số kiến thức trước đó trong đó, Vì vậy, mặc dù chúng tôi tuyên bố rằng chúng tối làm tất cả với AutoML, thực tế, một số kiến thức trước đó đã được cho vào không gian tìm kiếm. Tôi nghĩ tôi muốn cải thiện điều đó.
Nhưng tôi có thể nói với bạn rằng chất lượng của bản beta AutoML rất tuyệt vời và người dùng trên cloud cảm thấy rất vui. Tối không thể đi vào chi tiết sản phẩm, nhưng tôi nghĩ chất lượng đã rất tuyệt vời. Và việc tiếp nhận của mọi người cũng rất tuyệt vời.
Ông có nghĩ rằng AutoML có thể tạo ra kiến trúc mạng đột phá tiếp theo như Inception hoặc ResNet không?
Tối nghĩ điều đó là có thể. Gần đây chúng tôi đã sử dụng tìm kiến một kiến trúc mạng tốt hơn cho điện thoại di động. Đây là một bài toán khó và khó cho cả những người đang làm việc với nó. Thật khó để có thể đánh bại MobileNet V2 mà bây giờ đã trở thành tiêu chuẩn công nghiệp. Chúng tôi đã tạo ra một mạng tốt hơn đáng kể, tốt hơn 2% với cùng tốc độ trên điện thoại di động.
Và điều này chỉ là khởi đầu. Tôi nghĩ nó sẽ tiếp tục như thế này. Trong một vài năm, tôi dự đoán rằng các mạng tốt nhất, ít nhất là trong thị giác máy tính sẽ được tạo ra thay vì được thiết kế theo cách thủ công.
Rất ít nhà nghiên cứu đã liên tục thực hiện các đột phá trong học máy. Làm thế nào để ông duy trì sự sáng tạo của mình?
Trước hết, có rất nhiều nhà nghiên cứu tuyệt vời, những người cực kỳ sáng tạo và làm công việc tuyệt vời nên tôi sẽ không nói rằng tôi có bất cứ điều gì đặc biệt. Đối với bản thân mình, tôi có một số vấn đề mà tôi luôn tò mò muốn giải quyết, và tôi thực sự thích giải quyết chúng. Đó là sự kết hợp giữa sự tò mò và kiên trì. Tôi chỉ muốn đi theo sự tò mò của mình và tạo ra một tác động tích cực trên thế giới. Tôi cũng chơi bóng đá vào cuối tuần và tôi thích làm vườn - tôi không biết liệu điều đó có giúp ích cho nghiên cứu của tôi hay không nhưng nó giúp tôi thư giãn một chút!
Tôi có câu hỏi cuối cùng dành cho ông: làm thế nào để ông đối phó với thất bại?
Nếu bạn yêu một cái gì đó thì bạn sẽ tiếp tục cố gắng theo đuổi nó, đúng không? Vì vậy, tôi rất yêu học máy. Để giải quyết một vấn đề, thay vì viết chương trình, bạn dạy cho máy làm điều đó. Tôi thích khái niệm đó ở cấp độ cơ bản. Vì vậy, ngay cả khi có thất bại, tôi vẫn vui vẻ!
All rights reserved
