Tổng quan chuyên sâu về DeepSeek‑OCR (DeepSeek OCR)
1. Tổng quan concept
- DeepSeek-OCR được công bố ngày 21/10/2025 với tiêu đề: “Contexts Optical Compression”. (arXiv)
- Mục tiêu: Không chỉ là một mô hình OCR thông thường, mà thay đổi cách tiếp cận “thông tin dài” (long context) cho các LLM/VLM — bằng cách chuyển khối thông tin văn bản/trang tài liệu thành biểu diễn hình ảnh / vision tokens (nói cách khác: render page thành ảnh → vision encoder → giảm số lượng token rất lớn so với biểu diễn text thuần). (Medium)
- Khái niệm chính: Context Optical Compression — dùng hình ảnh để “nén” thông tin (văn bản + bố cục + hình ảnh/biểu đồ) thành số lượng token thấp hơn nhiều so với nếu chỉ dùng text tokens. (DeepSeek AI)
- Ví dụ: Một trang tài liệu có thể cần hàng nghìn text-token nếu encode theo văn bản, nhưng với vision encoder có thể chỉ cần vài trăm vision-token để chứa đủ thông tin để decoder có thể sinh lại text/bố cục với độ chính xác cao. (Medium)

2. Kiến trúc chính
Từ các nguồn, DeepSeek-OCR có cấu trúc hai giai đoạn encoder → decoder, với các điểm nổi bật như sau:
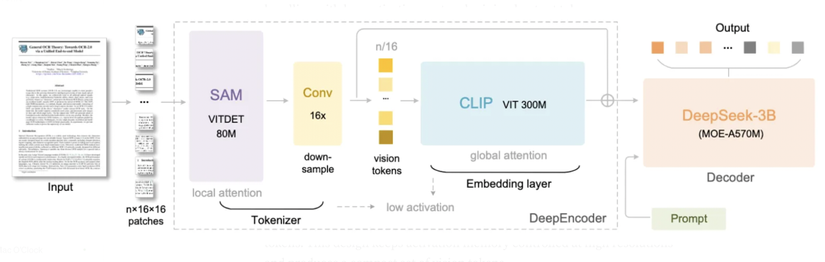
2.1 Bộ mã hóa (Encoder) – gọi là DeepEncoder
-
Nhận đầu vào là ảnh tài liệu (ví dụ resolution 1024×1024, hoặc các chế độ đa độ phân giải). (Medium)
-
Kiến trúc gồm:
- Một block transformer dạng “windowed self‐attention” (ví dụ lấy cảm hứng từ SAM – Segment Anything Model) để tập vào chi tiết cục bộ. (Medium)
- Sau đó là một block transformer toàn cục (ví dụ kiểu CLIP large) để nắm bắt toàn bộ bố cục/quan hệ toàn trang. (Analytics Vidhya)
- Ở giữa hai block này là module convolutional down-sampling: giảm số lượng token hình ảnh (patches) xuống rất nhiều. Ví dụ: 1024×1024 → 4096 patches → compression → chỉ còn 256 vision tokens. (Medium)
-
Hỗ trợ nhiều chế độ độ phân giải đầu vào (Tiny, Small, Base, Large, và chế độ “Gundam” dynamic) với số vision-token khác nhau tùy độ phân giải. (GitHub)
2.2 Bộ giải mã (Decoder) – gọi là DeepSeek‑3B‑MoE hoặc tương đương
- Là một mô hình ngôn ngữ (language model) dạng Mixture-of-Experts (MoE): tổng số các expert, nhưng mỗi bước chỉ kích hoạt một vài expert, để đạt hiệu quả cao nhưng chi phí thấp. (Medium)
- Tham số: khoảng “3B parameter model” (hoặc ít hơn active parameters). Ví dụ: 64 experts, mỗi token active khoảng 6 experts → số active para ~570 M. (Analytics Vidhya)
- Nhận input là các vision tokens từ encoder, và sinh ra văn bản (có thể markdown, hoặc văn bản thuần, giữ bố cục, công thức, bảng biểu, đa ngôn ngữ). (Medium)
Ví Dụ Minh Họa: Attention Pattern
Xét một window 3×3 patches đơn giản:
┌─────────────────┐
│ 0.02 0.05 0.02│
│ 0.05 0.70 0.05│ ← Center query
│ 0.02 0.05 0.02│
└─────────────────┘
🔍 Giải thích
- Center patch (query) có attention weight cao nhất đến chính nó (0.70)
- Immediate neighbors nhận attention mức trung bình (0.05)
- Patches ở góc nhận attention thấp hơn (0.02)
- Tổng weights = 0.98 ≈ 1.0 (normalized)
Điều này cho thấy windowed attention ưu tiên thông tin gần (locality bias), phù hợp với OCR tasks nơi context gần (ký tự liền kề) quan trọng hơn.
Lợi Ích Của Windowed Attention Trong OCR
1. Efficiency
- Giảm complexity từ
O(n²)xuốngO(n⋅w), vớiwlà window size - Cho phép xử lý high-resolution images trên single GPU (<8GB VRAM)
2. Local Feature Focus
- Tập trung vào chi tiết văn bản cục bộ: character shapes, font styles, kerning
- Đặc biệt hiệu quả cho OCR tasks nơi neighboring pixels/patches có semantic correlation cao
3. Parallelization
- Các windows độc lập → có thể xử lý song song
- Với 16 windows, có thể tận dụng multi-GPU / multi-core processing
4. Memory Efficiency
- Memory footprint tuyến tính với số windows
- Không còn quadratic với tổng số patches
- Cho phép 200,000+ pages/day trên single A100 GPU
3. Những điểm toán học / kỹ thuật đáng chú ý
Dưới đây là các thành phần kỹ thuật + toán học mà mình tóm lại. (Lưu ý: paper công bố mới nên có thể thiếu vài chi tiết hoặc chưa tiết lộ hết.)
3.1 Compression ratio (tỷ lệ nén)
- Khái niệm: số lượng text tokens chơi nếu encode bằng văn bản vs số lượng vision tokens sau encoder. Ví dụ: nếu một trang văn bản cần 2000 text-tokens, còn encoder chỉ tạo ra 200 vision-tokens → tỉ lệ ≈ 10×.
- Điểm quan trọng: theo paper, khi compression ratio < 10×, mô hình đạt ~97% độ chính xác trong OCR task. (arXiv) Khi ratio lên ~20×, độ chính xác vẫn khoảng ~60%. (arXiv)
- Toán học ngầm: đây là một dạng information bottleneck — encoder phải “nén” thông tin trong ảnh (chữ, bố cục, hình ảnh đi kèm) sao cho decoder vẫn có thể tái tạo lại văn bản với sai số thấp. Nếu số token quá thấp, mất thông tin → độ chính xác giảm.
3.2 Vision tokenization & patch compression
- Input ảnh được chia thành patches (ví dụ 1024×1024 → 4096 patches nếu mỗi patch 16×16).
- Sau đó có module convolutional down-sample (16× compression trong ví dụ) để giảm token count.
- Toán học: nếu N_patches ban đầu, sau down-sampling thành N_tokens = N_patches / k (k là factor – như 16). N_tokens chính là số vision tokens mà decoder nhận.
- Có trade-off: càng giảm N_tokens → càng tiết kiệm memory/compute nhưng càng dễ mất thông tin chi tiết (chữ nhỏ, biểu đồ, bảng, công thức).
3.3 Mixture-of-Experts decoder
- MoE: M total experts, mỗi token chỉ sử dụng E active experts (E < M).
- Thông thường, mỗi expert có riêng các tham số; nhờ đó tổng số tham số rất lớn nhưng hiệu số tham số hoạt động/forward mỗi bước thấp hơn nhiều.
- Toán học: nếu M=64 và E≈6 → chỉ ~6/64 ≈ 9.4% các expert được active mỗi token. Điều này giúp tăng khả năng mô hình học đa dạng trong khi giữ chi phí inference thấp.
- MoE đòi hỏi routing mechanism (chọn expert nào với token nào) — tuy nhiên paper có thể không công bố chi tiết routing.
3.4 Layout + multimodal encoding
- Khác với OCR truyền thống chỉ nhận diện chữ: DeepSeek-OCR phải giữ được bố cục, biểu đồ, công thức, bảng – tức là một dạng “tài liệu phức tạp”.
- Vì thế encoder không chỉ nhìn chữ mà còn học quan hệ không gian giữa chỗ các từ, dòng, cột, hình ảnh. Toán học: attention mechanism (self-attention) trong transformer cho phép model học tương quan giữa patches ở các vị trí khác nhau.
- Windowed attention (cục bộ) + Global attention (toàn trang) giúp cân bằng chi tiết và bố cục tổng thể.

3.5 Hiệu suất & benchmark
- Một GPU như Nvidia A100-40G có khả năng xử lý ~200 000 trang mỗi ngày trong môi trường production. (arXiv)
- Trên tập benchmark như Fox benchmark: tại ratio <10× đạt ~97% precision. (Analytics Vidhya)
- Trên OmniDocBench: với ~100 vision tokens/page, vượt các model trước dùng nhiều hơn tokens. (36Kr)
4. Những điểm mấu chốt cần lưu ý (và các hạn chế)
- Mặc dù “nén” rất mạnh, không phải hoàn toàn không mất thông tin — khi compression ratio lớn (ví dụ >20×) thì độ chính xác giảm rõ. (arXiv)
- Số lượng vision tokens vs độ phân giải vs độ phức tạp layout: tài liệu có bố cục phức tạp, chữ nhỏ, biểu đồ, bảng thì cần nhiều tokens hơn hoặc độ phân giải cao hơn. (Analytics Vidhya)
- Việc train encoder + decoder đồng bộ khá phức tạp — cần dữ liệu đa dạng: văn bản, bảng, hình ảnh, công thức, đa ngôn ngữ. Theo báo cáo: họ dùng dữ liệu “OCR 1.0” (30 triệu trang), “OCR 2.0” (biểu đồ, công thức) và cả text thuần. (36Kr)
- Có thể có trade-off giữa “token count thấp” và “tốc độ / memory / độ chính xác”: giảm token count giúp mở rộng “context window” (có thể nén tài liệu dài hơn vào một model) nhưng nếu quá mạnh nén → mất thông tin.
- Cần GPU mạnh và công nghệ như Flash-Attention để xử lý hiệu quả. Theo README: yêu cầu torch==2.6.0, CUDA11.8, flash-attn==2.7.3 … (GitHub)
- Đây là nền tảng ban đầu (initial exploration) — paper cũng nhấn mạnh đây là “an initial investigation into the feasibility of compressing long contexts via optical 2D mapping”. (arXiv)
5. Vì sao quan trọng / ứng dụng mở rộng
- Cho phép các mô hình ngôn ngữ (LLM) hoặc mô hình đa phương thức (VLM) nhìn thấy và xử lý “tài liệu dài” hiệu quả hơn: thay vì feed hàng triệu text tokens (mà memory/compute tăng tuyến tính) — có thể nén trước bằng hình ảnh → số token ít hơn → cost thấp hơn, mở ra khả năng “context window” lớn hơn.
- Giúp giữ lại thông tin bố cục & hình ảnh (tables, diagrams, formulas) mà nếu chỉ dùng text encoding có thể mất hoặc encode rất cồng kềnh.
- Ứng dụng trực tiếp: OCR tài liệu hàng loạt, trích xuất text + cấu trúc từ PDF, slide, báo cáo, nghiên cứu khoa học. Ngoài ra có thể làm bước tiền xử lý cho LLMs khi cần “nhập” tài liệu dài rồi hỏi về nó.
- Có tiềm năng cho “memory” trong mô hình: nếu mô hình có thể “nhớ” rất nhiều thông tin via vision tokens, thì khả năng xử lý context siêu dài (ở mức hàng trăm nghìn hoặc hơn) trở nên khả thi.
6. Những câu hỏi và hướng nghiên cứu mở
- Làm sao chính xác để routing experts trong MoE? Chi tiết này thường là “black-box”.
- Độ nén tối đa mà vẫn giữ thông tin có ý nghĩa — liệu có thể 50×, 100×? Hiện báo cáo ~20× duy trì ~60% accuracy.
- Khi nén bằng hình ảnh thì ảnh cũng có “lossy” (ví dụ nhỏ patches, mờ chữ nhỏ). Tương quan giữa độ phân giải ảnh, số vision tokens và độ chính xác là gì?
- Có thể áp dụng phương pháp này cho video, tài liệu đa trang hoặc hệ thống lưu trữ kiến thức lâu dài (long-term memory) cho LLM?
- So sánh chi tiết giữa nén text (ví dụ compaction text tokens, summarization) vs nén qua vision tokens — liệu có trường hợp text tokens hiệu quả hơn?
- Tác động đến latency, inference cost, memory footprint thực tế trong môi trường production.
All rights reserved
