Tổng quan: Các thành phần cấu tạo nên Transformer (Phần 1)
Bài đăng này đã không được cập nhật trong 3 năm
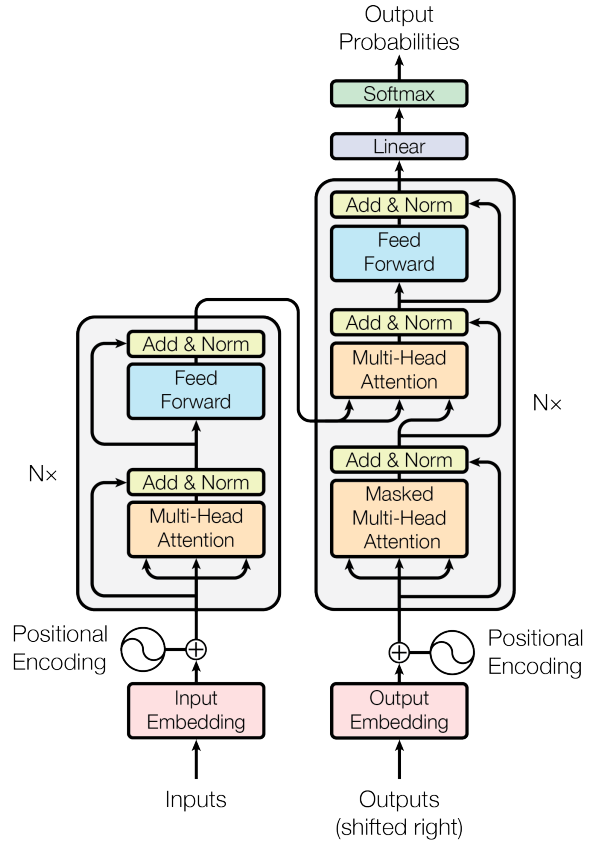
Transformer - một kiến trúc state-of-the-art được giới thiệu bởi Vaswani và cộng sự tại Google Brain vào năm 2017. Đã có rất nhiều những bài viết, tutorial để giải thích các thành phần của Transformer theo các mức độ chi tiết khác nhau. Tuy nhiên sau khi mình đọc thì vẫn chưa hiểu rõ từng thành phần trong kiến trúc này để làm gì hoặc tại sao nó lại ở đó 🫣 (có thể là do chưa đọc đến nơi đến trốn 🤪)
CHÍNH VÌ THẾ, SERIES NÀY MỤC ĐÍCH MÌNH VIẾT RA ĐỂ CÓ THỂ VỪA TÌM HIỂU RÕ VÀ SÂU HƠN VÀ CODE LẠI CÁC THÀNH PHẦN CẤU TẠO NÊN TRANSFORMER, CŨNG NHƯ ĐỂ LƯU LẠI VÀ CHIA SẺ CHO MỌI NGƯỜI, HỀ HỀ.
Nhưng trước khi đi vào từng thành phần một, cũng phải nói lại một chút tổng quan về kiến trúc của Transformer (cái hình đầu tiên ấy 🤨)
"Người máy biến hình" - Transformer
Trong paper gốc thì transformer được sử dụng chính trong bài toán dịch máy (như ở ví dụ dưới đây sẽ là từ tiếng việt sang tiếng anh chẳng hạn)

Transformer về cơ bản là một mô hình có dạng encoder-decoder. Một khối (block) encoder được sử dụng để trích xuất các đặc điểm theo ngữ cảnh từ 1 chuỗi đầu vào, và một khối decoder sử dụng các đặc điểm đó để tạo ra một chuỗi đầu ra. Kiến trúc của nó được các tác giả mô tả như trong hình đầu tiên, với Nx ở 2 bên của encoder và decoder, tượng trưng cho việc stack các block encoder và decoder lên nhau để tạo nên một kiến trúc tổng thể. Để dễ dàng hơn thì mình sẽ copy and paste vẽ lại như sau:
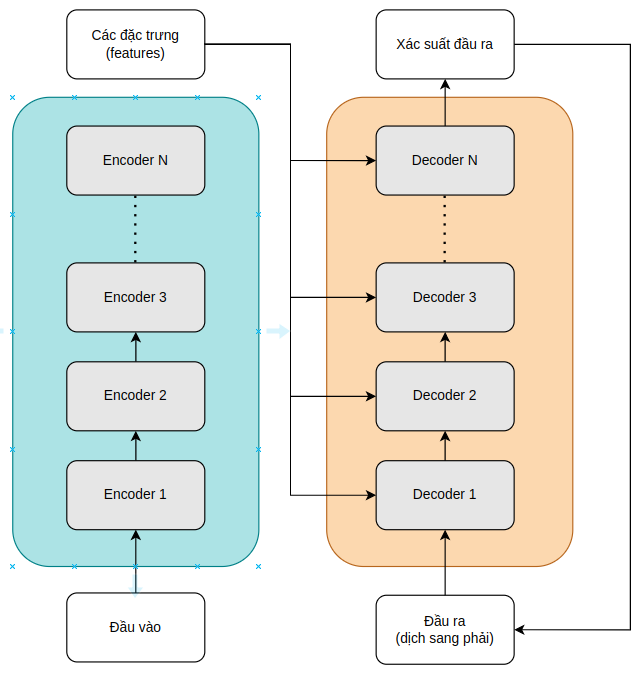
Về cơ bản, đầu ra của mỗi encoder layer sẽ là đầu vào của encoder tiếp theo, và đầu ra cuối cùng của encoder block sẽ được đưa vào mỗi decoder layer. Cuối cùng, đầu ra được tạo ra bằng cách sử dụng các thông tin này cùng với 1 đầu vào cho decoder (chúng ta sẽ tìm hiểu sau về phần này)
Để huấn luyện mô hình này, nó yêu cầu tập corpus (gọi là kho dữ liệu đi) song song để cho model "ăn và học" (ở ví dụ trên là cả tiếng Việt và tiếng Anh). Cả 2 bộ corpus này sẽ được sử dụng đồng thời trong quá trình huấn luyện, giúp mô hình có thể "hiểu" hơn về mối quan hệ giữa các ngôn ngữ.
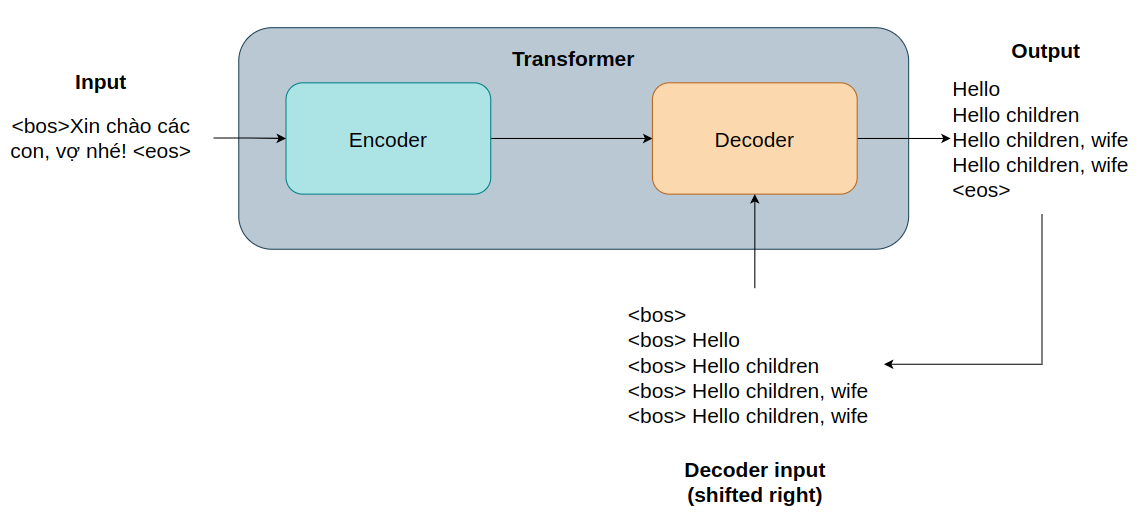
Sau khi huấn luyện xong, trong quá trình suy luận (inference), đầu vào của mô hình sẽ là 1 câu tiếng Việt ví dụ như sau "<bos>Xin chào các con, vợ nhé! <eos>", nó sẽ được mã hóa bởi các cục Encoder, sau đó, phiên bản mã hóa này sẽ được truyền đến tất cả các cục decoder . Block decoder sẽ được "nhắc" là bắt đầu suy luận đi bằng token thông báo bắt đầu câu (beginning-of-sequence <bos>), rồi dùng bản mã hóa của câu đó (output của block encoder) để dự đoán từ tiếng Anh đầu tiên, và cứ thế tiếp tục cho đến khi nó dự đoán được token kết thúc câu (end-of-sequence <eos>). Vì là câu bắt đầu bằng <bos> token, vì thế đầu ra được coi là dịch sang bên phải 1 từ vì <bos> không được coi là 1 phần của kết quả được dự đoán. Quá trình này được tóm tắt lại như sau:
Các thành phần chính
Trước khi encoder và decoder được sử dụng, chuỗi đầu vào của model cần được biến đổi thành các vector embedding (phần 2 của series này) và sử dụng cả positional encoding (phần 3) để bổ sung càng nhiều thông tin về ngữ cảnh của từng từ càng tốt. Chuỗi này được cho đi tiếp qua multi-head attention layer (phần 4) rồi đến feed-forward network (phần 5). Các layer này có nhiệm vụ extract các thông tin và sự liên quan của source và target trong quá trình training. Một điều quan trọng nữa là sau khi đi qua các layer này, layer normalization (phần 6) và residual (ResNet) cũng được thực hiện.
Multi-Head attention
Theo như tutorial của KiKaBeN, multi-head attention layer được sử dụng để làm "phong phú" thêm các token trong vector embedding theo các thông tin về ngữ cảnh trong toàn bộ chuỗi. Trong nhiều ngôn ngữ, 1 từ có thể có nhiều nghĩa dựa vào ngữ cảnh của nó. Vì vậy, theo KiKaBeN cho rằng, "cơ chế self-attention sử dụng multi-heads (8 phép attentions song song) để mô hình có thể liên hệ token với các embedding subspaces khác nhau".
Mạng Position-Wise Feed-Forward (FFN)
FFN bao gồm 2 linear layers với ReLU activation function giữa chúng. Nó cũng được coi là expand-and-contract network (mạng mở rộng và thu gọn 🤔🤔🤔) vì layer đầu tiên sẽ có số chiều lớn (high dimensionality) và layer thứ 2 sẽ trả về số chiều gốc (original dimensionality). Bằng cách sử dụng FFN, transformer đưa phép phi tuyến tính vào trong mô hình bằng hàm ReLU, giúp cho mô hình có thể nắm bắt được các mối quan hệ và sự phụ thuộc giữa các token của chuỗi đầu vào.
Nhánh Residual
Nhánh này lấy các vector embedding trước khi nó được đưa vào layer, rồi cộng nó với output của layer đó. Điều này giúp cho embedding vectors có được nhiều thông tin hơn từ multi-head attention cùng với FFN layers. Cùng với đó tránh được các vấn đề về vanishing gradient.
Layer Normalization
Quá trình chuẩn hóa layer duy trì giá trị trung bình và độ lệch chuẩn của từng embedding hoặc các token, để giúp ngăn ngừa các vấn đề có thể xảy ra trong qúa trình gradient descent.
Kết luận
Qua bài lày, mình đã nhắc lại các ý chính cũng như nói sơ qua về các thành phần cấu tạo nên Transformer. Trong các phần tiếp theo, mình sẽ cố gắng giải thích chi tiết từng phần, cùng với đó là thử code lại với ví dụ gì đấy nho nhỏ để hiểu rõ hơn. Vì nếu đọc lý thuyết mà không có thực hành thì cũng sẽ rất khó có thể nhớ được lâu. Theo kế hoạch thì các phần sau sẽ được đi vào chi tiết và code như sau:
- Giới thiệu tổng quát
- Embedding layer
- Positional Encoding
- Multi-Head Attention
- Position-Wise Feed-Forward Network
- Layer Normalization
- The Encoder
- The Decoder
- Kết hợp lại thành mô hình hoàn chỉnh
Vì vậy, hãy follow và chờ đón các phần tiếp theo các bạn nhá 👀👀👀
All rights reserved
