
Tips! Tips! Tips sử dụng pandas vừa nhanh vừa hữu ích khi EDA dữ liệu.
Bài đăng này đã không được cập nhật trong 5 năm
Chào mọi người, ở một bài trước đây mình đã từng viết về một số tips khi sử dụng Jupyter-Notebook còn ở bài viết này mình sẽ chia sẻ một số function mình nghĩ là sẽ hữu ích khi bạn xử lý dữ liệu ở dạng bảng biểu. Bây giờ thì cùng bắt đầu thôi nào!
1. read, save function
Thực chất là hàm này thì lúc đọc dữ liệu mình nghĩ hầu hết mọi người đều biết tuy nhiên là muốn sử dụng được các hàm tiếp theo thì mình phải đọc dữ liệu trước đúng hàm nào?
read_csv
Theo như mình thấy đa phần dữ liệu dạng bảng biểu người ta cung cấp dưới dạng csv khá là nhiều, vậy làm sao để đọc được dữ liệu khi lưu dưới dạng csv?
Mình sẽ sử dụng data = pd.read_csv() như đoạn code dưới đây nhé 
import pandas as pd
data = pd.read_csv(filepath)
read_excel
Còn khi dữ liệu được lưu dưới dạng excel thì chúng ta dùng hàm pd.read_excel() nhé.
Khi save dữ liệu thì sao?
Khi bạn muốn lưu dữ liệu lại dưới dạng csv thì chúng ta thực hiện như sau:
data.to_csv(filepath_to_save_dataframe, index=False)
2. describe vs info
info
Khi mà chúng ta muốn show lên số lượng data, hiển thị kiểu dữ liệu của data hoặc số lượng data null, nonnull mà bạn đang có thì chúng ta sử dụng pd.info().
data.info()
describe
Khi bạn muốn xem thống kê tổng quan về dữ liệu bạn đang có thì sử dụng pd.describe()
data.describe()
3. drop
dropna
Khi bạn muốn drop những phần tử nan trong data của bạn bạn sử dụng hàm:
data.dropna()
drop_duplicates()
Trong dữ liệu thực tế hẳn sẽ không thiếu những trường hợp mà dữ liệu của bạn bị duplicates lên thì chúng ta sẽ xử lý như thế nào?
df = pd.DataFrame({"A":["foo", "foo", "foo", "bar"], "B":[1,1,1,1], "C":["A","A","B","A"]})
df

Hình 1: ví dụ duplicates
Ở hình 1 các bạn có thể nhận thấy ở đây có giá trị ở hàng 0 và 1 đang bị trùng nhau. Như vậy chúng ta sẽ xử lý ví dụ trên một cách cực kỳ nhanh chóng như sau:
df = df.drop_duplicates()
 Hình 2: sau khi xử lý xong
Hình 2: sau khi xử lý xong
4. indexing
reset_index
Như ở hình 2 sau khi bạn loại bỏ các giá trị bị trùng nhau thì index của chúng ta đang khá là lộn xộn vì vậy chúng ta sẽ sắp xếp một chút
df.reset_index(drop=True)
 Hình 3: sau khi reset_index
Hình 3: sau khi reset_index
5. select_dtypes
Từ đây trở đi mình sẽ dùng data của titanic để ví dụ cho liền mạch nha mọi người
data_titanic = pd.read_csv("train_titanic.csv")
data_titanic.info()
 Hình 3: info của data titanic
Ở hình 3 chúng ta có thể nhận thấy rằng có 3 kiểu dữ liệu là: float64, int64, object.
Vậy nếu mình muốn chọn các columns có kiểu dữ liệu là float64 thì sẽ như thế nào? Bạn dựa vào hình 3 để chọn theo cách thông thường như:
Hình 3: info của data titanic
Ở hình 3 chúng ta có thể nhận thấy rằng có 3 kiểu dữ liệu là: float64, int64, object.
Vậy nếu mình muốn chọn các columns có kiểu dữ liệu là float64 thì sẽ như thế nào? Bạn dựa vào hình 3 để chọn theo cách thông thường như:
data_titanic[['Age', 'Fare']]
Cách này cũng khá okay đấy nhưng nếu như bạn có tầm 10, 20, 50 columns có type là float64 thì bạn sẽ làm gì? Tất nhiên là không thể làm như trên được rồi , vậy thì pandas có cung cấp cho chúng ta function pd.select_dtypes
data_titanic.select_dtypes(include="float64")
6. Slicing
Nếu như chúng ta muốn lấy ra tất cả các hàng mà có "Age" >= 22 chẳng hạn thì sẽ làm như sau:
Age_gt22 = data_titanic[data_titanic.Age >=22]
7. isin
Khi mình muốn lấy mọi người có giới tính male và đều lớn hơn 22 tuổi mình có thể sử dụng hàm isin:
male = data_titanic[data_titanic.Sex == 'male']
Age_gt22[Age_gt22['Sex'].isin(male.Sex)]
Còn khi muốn lấy những người có giới tính là female và lớn hơn 22 tuổi thì :
Age_gt22[~Age_gt22['Sex'].isin(male.Sex)]
8. lambda
map
map() chỉ được định nghĩa trên Series hoặc dict Hàm map() có thể ánh xạ chuỗi theo tương ứng đầu vào. Nó sẽ thật sự hữu ích khi chúng ta phải thay thế một chuỗi bằng giá trị khác. Kích thước input = output Giống như dữ liệu ở bài này nếu mình muốn đổi giá trị 'male' : 0, 'female' :1. Mình có thể dùng hàm map() như dưới đây
data_titanic['gt'] = data_titanic['Sex'].map({'male':0, 'female':1})
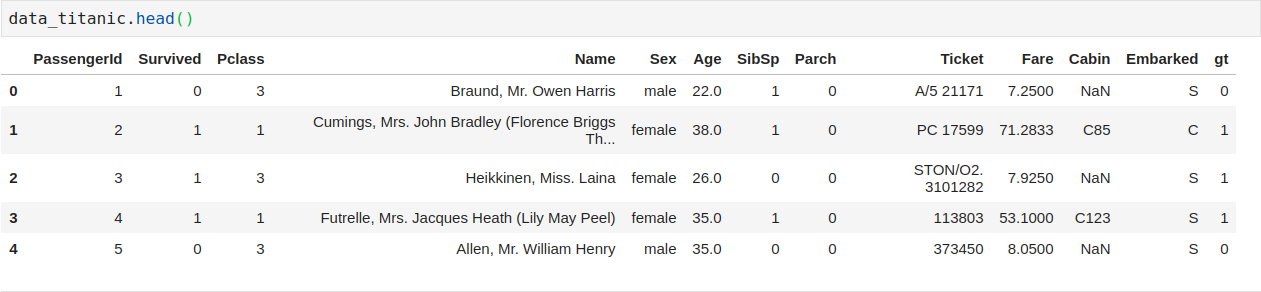
Chúng ta có thêm column gt chứa các giá trị 0, 1 thay vì "male" hay là "female".
hoặc chúng ta có thể sử dụng lambda như cách dưới đây:
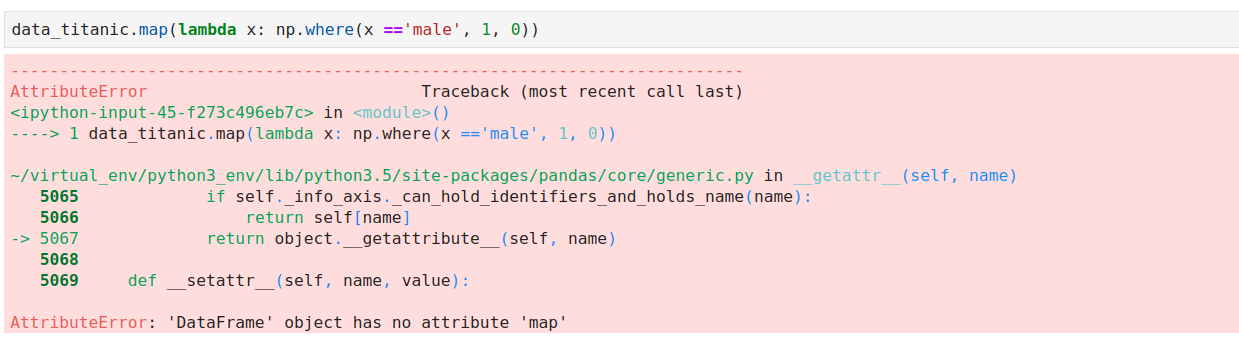
data_titanic['gt'] = data_titanic['Sex'].map(lambda x: np.where(x =='male', 0, 1))
np.where ở đây mình muốn lấy giá trị x == 'male' sẽ gán bằng 0 và ngược lại sẽ gán là 1
Khi bạn sử dụng hàm map() cho dataframe sẽ báo lỗi như hình ảnh ở sau đây:
apply
apply() kết hợp cả Dataframe & Series. apply() function có thể áp dụng với mọi cột, hàng của dataframe trả về một bản sao sửa đổi của dataframe: Giống như ví dụ ở map() function chúng ta cũng có thể sử dụng apply để tạo thêm column gt1 chứa các giá trị 0, 1 thay vì "male" hay là "female".
data_titanic['gt1'] = data_titanic['Sex'].apply(lambda x: np.where(x =='male', 0, 1))
 Còn đối với apply() function chúng ta có thể sử dụng nó với dataframe:
Còn đối với apply() function chúng ta có thể sử dụng nó với dataframe:
data_titanic.apply(lambda x: np.where(x =='male', 1, x)).head()

concat
Khi bạn muốn gộp 2 dataframe lại khi chúng có cùng số columns thì hàm pd.concat rất hữu ích Ví dụ như khi mình có 2 dataframe age lớn hơn 22 và dataframe age nhỏ hơn 20.
Age_gt22 = data_titanic[data_titanic.Age >=22]
Age_lt20= data_titanic[data_titanic.Age <= 20]
Mình muốn nối 2 dataframe này lại với nhau.
pd.concat([Age_gt22, Age_lt20])
Kết Luận
Trên đây là một số function mình cảm thấy hữu ích khi xử lý dữ liệu dạng table, mình đặc biệt cảm thấy lambda cực kỳ vi diệu và nhanh một cách chóng mặt nếu so với vòng for thì ... à mà thôi. Cảm ơn mọi người đã đọc bài viết của mình, mong nhận được sự góp ý của mọi người ạ!
Reference
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html
All rights reserved
