Tìm hiểu về Content-based Filtering - Phương pháp gợi ý dựa theo nội dung (Phần 1)
Bài đăng này đã không được cập nhật trong 7 năm
Dạo gần đây mình có tìm hiểu về hệ gợi ý - recommendation system. Và hôm nay mình sẽ chia sẻ với các bạn một số nội dung mà mình tìm hiểu được xung quanh phương pháp Content-based Filtering, phương pháp gợi ý dựa trên nội dung.
1. Tổng quan về Hệ gợi ý
1.1. Khái niệm
Hệ gợi ý (Recommender Systems - RS) là một dạng của hệ thống lọc thông tin (information filtering), nó được sử dụng để dự đoán sở thích (preferences) hay xếp hạng (rating) mà người dùng có thể dành cho một mục thông tin (item) nào đó mà họ chưa xem xét tới trong quá khứ (item có thể là bài hát, bộ phim, đoạn video clip, sách, bài báo,..).
Thực ra thì đây cũng không phải một bài toán quá xa lạ gì với chúng ta phải không? Như những gợi ý cho chúng ta trên Lazada, Youtube, Facebook,... hay rõ ràng nhất là trong hệ thống Viblo cũng có mục gợi ý cho bạn các bài viết mà có khả năng bạn sẽ quan tâm.
1.2. Các thành phần của một hệ gợi ý
Hệ gợi ý rất quen thuộc và gần gũi, vậy để xây dựng được một hệ gợi ý, chúng ta cần có:
- Dữ liệu: Đầu tiên chúng ta cần có dữ liệu về users, items, feedback
Trong đó,
users là danh sách người dùng
items là danh sách sản phẩm, đối tượng của hệ thống. Ví dụ như các bài viết trên trang viblo, các video trên youtube,... Và mỗi item có thể kèm theo thông tin mô tả.
feedback là lịch sử tương tác của user với mỗi item, có thể là đánh giá của mỗi user với một item, số ratings, hoặc comment, việc user click, view hoặc mua sản phẩm,...
- Ma trận user-item: Utility matrix
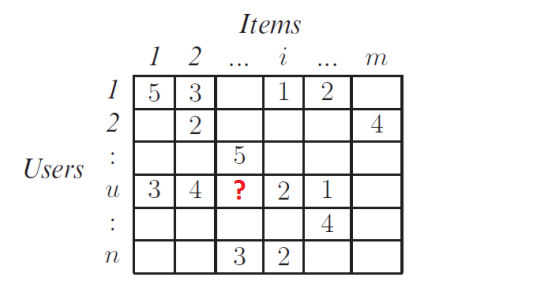
Đây là ma trận biểu diễn mức độ quan tâm (rating) của user với mỗi item. Ma trận này được xây dựng từ dữ liệu (1). Nhưng ma trận này có rất nhiều các giá trị miss. Nhiệm vụ của Hệ gợi ý chính là dựa vào các ô đã có giá trị trong ma trận trên (dữ liệu thu được từ trong quá khứ), thông qua mô hình đã được xây dựng, dự đoán các ô còn trống (của user hiện hành), sau đó sắp xếp kết quả dự đoán (ví dụ, từ cao xuống thấp) và chọn ra Top-N items theo thứ tự rating giảm dần, từ đó gợi ý chúng cho người dùng.
-
Phương pháp gợi ý: Có 2 phương pháp gợi ý chính, thường được sử dụng để xây dựng hệ gợi ý, đó là:
- Content-based Filtering: Gợi ý các item dựa vào hồ sơ (profiles) của người dùng hoặc dựa vào nội dung/thuộc tính (attributes) của những item tương tự như item mà người dùng đã chọn trong quá khứ.
![]()
- Collaborative Filtering: Gợi ý các items dựa trên sự tương quan (similarity) giữa các users và/hoặc items. Có thể hiểu rằng đây là cách gợi ý tới một user dựa trên những users có hành vi tương tự.
![]()
Và trong bài viết này, chúng ta sẽ cùng tìm hiểu về phương pháp Content-based Filtering nhé

- Content-based Filtering: Gợi ý các item dựa vào hồ sơ (profiles) của người dùng hoặc dựa vào nội dung/thuộc tính (attributes) của những item tương tự như item mà người dùng đã chọn trong quá khứ.
2. Phương pháp gợi ý dựa theo nội dung (Content-based Filtering)
2.1 Ý tưởng
Ý tưởng của thuật toán này là, từ thông tin mô tả của item, biểu diễn item dưới dạng vec-tơ thuộc tính. Sau đó dùng các vec-tơ này để học mô hình của mỗi user, là ma trận trọng số của user với mỗi item.
Như vậy, thuật toán content-based gồm 2 bước:
- Bước 1: Biểu diễn items dưới dạng vec-tơ thuộc tính - item profile
- Bước 2: Học mô hình của mỗi user
2.2. Xây dựng Items Profile
Trong các hệ thống content-based, chúng ta cần xây dựng một bộ hồ sơ (profile) cho mỗi item. Profile này được biểu diễn dưới dạng toán học là một "feature vector" n chiều. Trong những trường hợp đơn giản (ví dụ như item là dữ liệu dạng văn bản), feature vector được trực tiếp trích xuất từ item. Từ đó chúng ta có thể xác định các item có nội dung tương tự bằng cách tính độ tương đồng giữa các feature vector của chúng.
Một số phương pháp thường được sử dụng để xây dựng feature vector là:
- Sử dụng TF-IDF
- Sử dụng biểu diễn nhị phân
- Sử dụng TF-IDF: Giải thích một chút:
TF(t, d) = ( số lần từ t xuất hiện trong văn bản d) / (tổng số từ trong văn bản d)
IDF(t, D) = log_e( Tổng số văn bản trong tập mẫu D/ Số văn bản có chứa từ t )
Ví dụ: Giả sử chúng ta tìm kiếm về "IoT and analytics" trên Internet và tìm được những bài báo dưới đây:
 Trong các bài báo, 5000 chứa analytics, 50.000 chứa data và số lượng tương tự dành cho các từ khác. Chúng ta hãy giả sử rằng tổng số tài liệu là 1 triệu (10 ^ 6).
Trong các bài báo, 5000 chứa analytics, 50.000 chứa data và số lượng tương tự dành cho các từ khác. Chúng ta hãy giả sử rằng tổng số tài liệu là 1 triệu (10 ^ 6).
-
Tính TF: Ta sẽ tính TF cho mỗi từ trong mỗi bài báo
Ví dụ, TF(analytics) = 1 + lg21 = 2.322

- Tính IDF:
IDF được tính bằng cách lấy nghịch đảo logarit của tần số tài liệu trong toàn bộ kho tài liệu. Vì vậy, nếu có tổng số 1 triệu tài liệu được trả về bởi truy vấn tìm kiếm của chúng tôi và trong số các tài liệu đó, ví dụ: nếu từ smart xuất hiện trong 0,5 triệu lần trong tài liệu, giá trị IDF của nó sẽ là: Log10 (10 ^ 6/5000000) = 0,30.

- Tính trọng số TF-IDF: Đầu tiên chúng ta sử dụng công thức sau để tính tf-df:
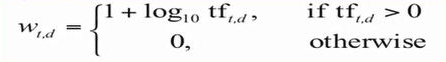
Sau đó, chuẩn hóa feature vector bằng cách chia vector cho độ dài của chính nó.
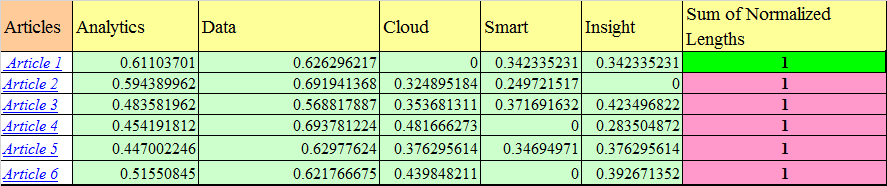
Như vậy, ta có thể có được các vector đặc trưng cho từng bài báo. Sau đó chúng ta có thể sử dụng độ tương đồng cosin để tính khoảng cách giữa chúng.
- Sử dụng biểu diễn nhị phân: Ví dụ:
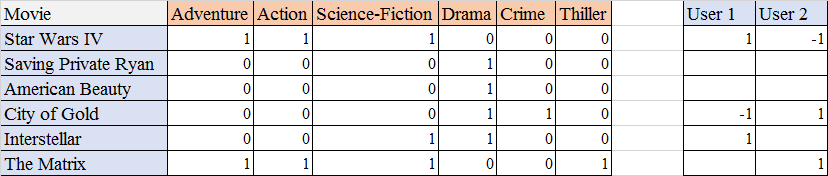
Trên đây là danh sách 6 bộ phim. Mỗi giá trị 0/1 thể hiện bộ phim đó không/có thuộc thể loại ở cột tương ứng. Bên cạnh đó, một hồ sơ người dùng cũng được tạo ra, với 1 là quan tâm, -1 là không, và null là chưa đánh giá. Như trong ví dụ trên, User 1 có quan tâm bộ phim Star Wars IV, còn User 2 thì không.
2.3 Học mô hình biểu diễn của user
Trong bài viết này, mình sẽ xét ví dụ với mô hình tuyến tính.
Giả sử ta có:
- N users
- M items
- Y ma trận user-item. Trong đó, y(i,j) là mức độ quan tâm (ở đây là số sao đã rate) của user thứ i với sản phẩm thứ j mà hệ thống đã thu thập được. Ma trận Y bị khuyết rất nhiều thành phần tương ứng với các giá trị mà hệ thống cần dự đoán.
- R là ma trận rated or not thể hiện việc một user đã rated một item hay chưa. Cụ thể, rij = 1 nếu item thứ i đã được rated bởi user thứ j, ngược lại rij = 0 nếu item thứ i chưa được rated bởi user thứ j.
Áp dụng mô hình tuyến tính:
Giả sử rằng ta có thể tìm được một mô hình có thể tính được mức độ quan tâm của mỗi user với mỗi item bằng một hàm tuyến tính:
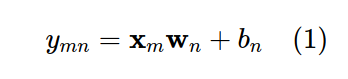
trong đó, x(m) là vector đặc trưng của item m.
Mục tiêu của chúng ta sẽ là học ra mô hình của user, tức là tìm ra w(n) và b(n).
Xét một user thứ n bất kỳ, nếu ta coi training set là tập hợp các thành phần đã được điền của yn, ta có thể xây dựng hàm mất mát tương tự như sau:
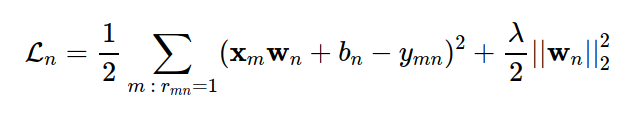
Trong đó, thành phần thứ hai là regularization term và λ là một tham số dương. Chú ý rằng regularization thường không được áp dụng lên bn. Trong thực hành, trung bình cộng của lỗi thường được dùng, và mất mát nên Ln được viết lại thành:
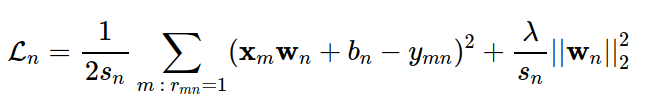
Trong đó sn là số lượng các items mà user thứ n đã rated. Nói cách khác, sn là tổng các phần tử trên cột thứ n của ma trận rated or not R:
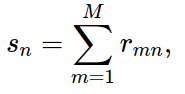
Vì hàm mục tiêu chỉ phụ thuộc vào các items đã được rated, ta có thể rút gọn nó bằng cách đặt ^yn là sub vector của y được xây dựng bằng cách trích các thành phần khác dấu? ở cột thứ n, tức đã được rated bởi user thứ n trong ma trận Y. Đồng thời, đặt X^n là sub matrix của ma trận feature X, được tạo bằng cách trích các hàng tương ứng với các items đã được rated bởi user thứ n. Khi đó, biểu thức hàm mất mát của mô hình cho user thứ n được viết gọn thành công thức (*):
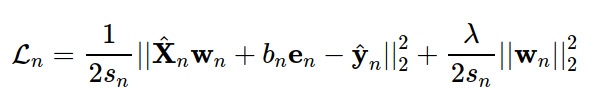
trong đó, en là vector cột chứa sn phần tử 1.
Đây chính là bài toán Ridge Regression, đã có sẵn trong thư viện sklearn.linear_model.Ridge của klearn. Ở bài tiếp theo, chúng ta sẽ sử dụng thư viện này để tìm w(n) và b(n) cho mỗi user. Còn bây giờ chúng ta sẽ xét một ví dụ về cách xây dựng mô hình cho mỗi user.
Ví dụ:
Xét bài toán: Ta có 5 items, vector đặc trưng của mỗi item được biểu diễn bởi một hàng:
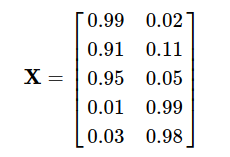
Đồng thời, chúng ta có thông tin về user 5, đã đánh giá các item 1 và 4:
![]()
Đầu tiên, tiền xử lý để thu được sub vector:
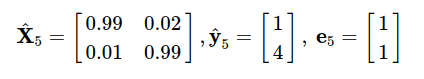
Sau đó áp dụng công thức (*), ta sẽ được hàm mất mát:
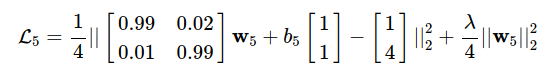
Cuối cùng, chúng ta có thể sử dụng Stochastic Gradient Descent (SGD), hoặc Mini-batch GD để tìm ra w(5) và b(5).
Ở phần tiếp theo, mình sẽ trình bày ví dụ cụ thể về cách xây dựng một mô hình gợi ý sử dụng content-based. Hẹn gặp lại các bạn ở bài tiếp theo.
Để tìm hiểu sâu hơn, bạn có thể tham khảo thêm các tài liệu và souce code trong các link sau:
Content-based Recommendation Systems - Vũ Hữu Tiệp
Beginners Guide to learn about Content Based Recommender Engines
All rights reserved
