
Thử áp dụng mô hình dịch máy vào bài toán tự động sửa lỗi tiếng Việt
Bài đăng này đã không được cập nhật trong 4 năm
Toàn bộ phần mã nguồn của bài toán các bạn có thể tham khảo github của mình nhé: VietnameseOcrCorrection
1. Mục đích bài toán.
Bài toán sửa lỗi tiếng Việt hiện tại đã được nhiều ông lớn trong làng công nghệ sử dụng trong nhiều ứng dụng quen thuộc mà các bạn có thể đã từng dùng như: tính năng phát hiện lỗi sai trong Google Docx hay Mircosoft Word , .... Vậy công nghệ này sẽ giúp ích như thế nào ?:
- Dùng trong hậu xử lý OCR: bài toán OCR hay bài toán nhận diện chữ từ ảnh. Để mô hình nhận diện chữ có thể đạt độ chính xác tuyệt đối rất khó do đó để tăng cường độ chính xác cho mô hình, chúng ta hoàn toàn có thể tích hợp một module sửa lỗi tiếng Việt để sửa lỗi chuỗi kết quả OCR.
- Phát hiện lỗi sai về cú pháp trong văn bản: Chức năng này tương tự như chức năng gợi ý, phát hiện lỗi sai trong Microsoft Word hoặc Google Docx.
2. Mô hình Seq2Seq.
Trong nghiên cứu thử nghiệm lần này, mình có sử dụng mô hình quen thuộc Seq2Seq gồm ba phần: encoder, decoder và attention. Do mô hình này đã quá quen thuộc nên mình sẽ không giới thiệu các phần lý thuyết liên quan nữa. Bạn đọc có thể tìm hiểu phần lý thuyết tham khảo ở một số bài báo khác sau đây:
- Mô hình dịch máy với attention: Machine Translate với Attention trong Deep Learning
- Tổng quan về attention: [Machine Learning] Attention, Attention, Attention, ...!
- Một số kiến thức cơ bản về lớp GRU, LSTM sử dụng trong encoder-decoder: Long short term memory (LSTM)
Chắc nhiều bạn cũng đặt câu hỏi lý do tại sao chọn mô hình Seq2Seq đơn giản thay cho các mô hình có độ chính xác vượt trội như Transformer ? Vì thực tế mình tìm hiểu bài toán này chủ yếu với mục đích là tăng cường độ chính xác cho mô hình OCR. Do mô hình OCR phía trước cũng đã tận dụng được các đặc trưng từ ảnh khá tốt rồi và kích thước cũng tương đối to do đó mình quyết định dùng mô hình Seq2Seq như mình đã đề cập để có thể ứng dụng vào trong bài toán thực tế.
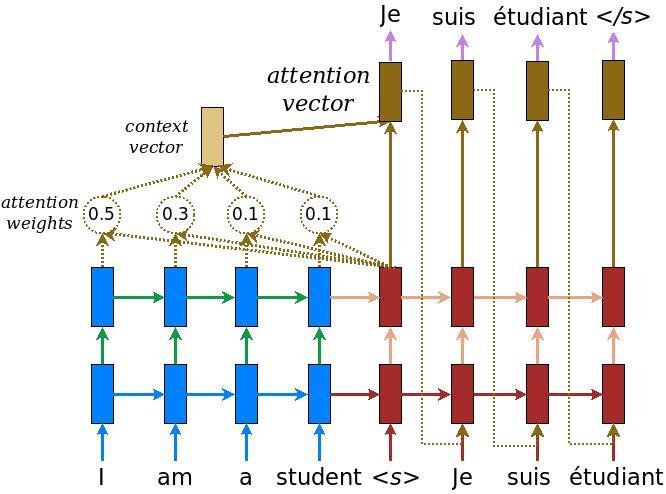 Ảnh minh họa mô hình Seq2Seq. (Nguồn Internet)
Ảnh minh họa mô hình Seq2Seq. (Nguồn Internet)
3. Dữ liệu.
Dữ liệu hiện tại mình đang dùng được từ 111 triệu câu từ kho dữ liệu Binhvq News Corpus . Các bạn có thể tham khảo và tải về bằng câu lệnh sau đây:
import gdown
url = 'https://drive.google.com/u/0/uc?id=1ovLbpvzSGrS4NDxZu8Ftdgc73uHzNQJf&export=download'
output = 'corpus-full.7z'
gdown.download(url, output, quiet=False)
3.1. Xử lý dữ liệu
Mục tiêu của bước này là tách đoạn văn được lấy từ kho dữ liệu bên trên thành các câu gồm n từ khác nhau. Để tăng cường hơn nữa về mặt ngữ nghĩa thì các câu này là chính là một ý hay được ngăn cách bằng các dấu ngắt câu như dấu chấm phẩy, dấu phẩy, dấu chấm,.... Để thực hiện điều đó, chúng ta sẽ dùng đoạn lệnh sau đây:
def extract_phrases(text):
return re.findall(r'\w[\w ]+', text)
Ví dụ:
Đoạn văn đầu vào:
Trên cơ sở kết quả kiểm tra hiện trạng, Tòa án nhân dân tối cao xem xét, lập phương án sắp xếp lại.
Danh sách các câu được trích xuất
['Trên cơ sở kết quả kiểm tra hiện trạng',
'Tòa án nhân dân tối cao xem xét',
'lập phương án sắp xếp lại']
3.2. Giả lập lỗi sai.
Ở bước này, dựa trên câu đúng đầu vào, ta sẽ dùng một vài phương pháp để làm sai lệnh dữ liệu đúng. Trong đó dữ liệu sai sẽ làm input, dữ liệu đúng sẽ làm nhãn đầu ra.
Ở đây, mình sẽ giả thiết một số lỗi sai phổ biến có thể gặp sau khi qua mô hình OCR
3.2.1 Mất dấu tiếng Việt
Ở phần này mình sẽ làm mất dấu ngẫu nhiên các từ trong một câu theo một tỉ lệ ratio được chọn trước.
import unidecode
def remove_random_accent(text, ratio=0.15):
words = text.split()
mask = np.random.random(size=len(words)) < ratio
for i in range(len(words)):
if mask[i]:
words[i] = unidecode.unidecode(words[i])
break
return ' '.join(words)
Ví dụ
remove_random_accent("Trên cơ sở kết quả kiểm tra hiện trạng")
Kết quả là:
Trên co sở kết quả kiểm tra hiện trạng'
3.2.2 Sai dấu tiếng Việt
Ở đây mình giả sử các từ có hình dáng giống nhau thì mô hình OCR có xu hướng bị nhầm nhiều hơn nên mình tiến hành thay thế ngẫu nhiên thay thế các từ bên trái bằng loạt các từ bên phải.
chars_regrex = '[aàảãáạăằẳẵắặâầẩẫấậAÀẢÃÁẠĂẰẲẴẮẶÂẦẨẪẤẬoòỏõóọôồổỗốộơờởỡớợOÒỎÕÓỌÔỒỔỖỐỘƠỜỞỠỚỢeèẻẽéẹêềểễếệEÈẺẼÉẸÊỀỂỄẾỆuùủũúụưừửữứựUÙỦŨÚỤƯỪỬỮỨỰiìỉĩíịIÌỈĨÍỊyỳỷỹýỵYỲỶỸÝỴnNvVmMCG]'
same_chars = {
'a': ['á', 'à', 'ả', 'ã', 'ạ', 'ấ', 'ầ', 'ẩ', 'ẫ', 'ậ', 'ắ', 'ằ', 'ẳ', 'ẵ', 'ặ'],
'A': ['Á','À','Ả','Ã','Ạ','Ấ','Ầ','Ẩ','Ẫ','Ậ','Ắ','Ằ','Ẳ','Ẵ','Ặ'],
'O': ['Ó','Ò','Ỏ','Õ','Ọ','Ô','Ố','Ồ','Ổ','Ỗ','Ộ','Ơ','Ớ','Ờ','Ở','Ỡ','Ợ','Q'],
'o': ['ó', 'ò', 'ỏ', 'õ', 'ọ', 'ô', 'ố', 'ồ', 'ổ', 'ỗ', 'ộ', 'ơ','ớ', 'ờ', 'ở', 'ỡ', 'ợ', 'q'],
'e': ['é', 'è', 'ẻ', 'ẽ', 'ẹ', 'ế', 'ề', 'ể', 'ễ', 'ệ', 'ê'],
'E': ['É', 'È', 'Ẻ', 'Ẽ', 'Ẹ', 'Ế', 'Ề', 'Ể', 'Ễ', 'Ệ', 'Ê'],
'u': ['ú', 'ù', 'ủ', 'ũ', 'ụ', 'ứ', 'ừ', 'ử', 'ữ', 'ự', 'ư'],
'U': ['Ú', 'Ù', 'Ủ', 'Ũ', 'Ụ', 'Ứ', 'Ừ', 'Ử', 'Ữ', 'Ự', 'Ư'],
'i': ['í', 'ì', 'ỉ', 'ĩ', 'ị'],
'I': ['Í', 'Ì', 'Ỉ', 'Ĩ', 'Ị'],
'y': ['ý', 'ỳ', 'ỷ', 'ỹ', 'ỵ', 'v'],
'Y': ['Ý', 'Ỳ', 'Ỷ', 'Ỹ', 'Ỵ', 'V'],
'n': ['m'],
'N': ['N'],
'v': ['y'],
'V': ['Y'],
'm': ['n'],
'M': ['N'],
'C': ['G'],
'G': ['C']
}
def _char_regrex(text):
match_chars = re.findall(chars_regrex, text)
return match_chars
def _random_replace(text, match_chars):
replace_char = match_chars[np.random.randint(low=0, high=len(match_chars), size=1)[0]]
insert_chars = same_chars[unidecode.unidecode(replace_char)]
insert_char = insert_chars[np.random.randint(low=0, high=len(insert_chars), size=1)[0]]
text = text.replace(replace_char, insert_char, 1)
return text
def change(text):
match_chars = _char_regrex(text)
if len(match_chars) == 0:
return text
text = _random_replace(text, match_chars)
return text
def replace_accent_chars(text, ratio=0.15):
words = text.split()
mask = np.random.random(size=len(words)) < ratio
for i in range(len(words)):
if mask[i]:
words[i] = change(words[i])
break
return ' '.join(words)
Nao mình cùng thử một chút nhé.
replace_accent_chars("Trên cơ sở kết quả kiểm tra hiện trạng")
Kết quả là:
Trên cơ só kết quả kiểm tra hiện trạng
3.2.3 Thiếu dấu ngăn cách câu.
Trường hợp bị thiếu mỗi vài dấu ngăn cách giữa các từ khá phổ biến trong quá trình OCR nên mình cũng sẽ làm giả dữ liệu bằng cách bỏ ngẫu nhiên một vài dấu cách giữa các từ.
def remove_random_space(text):
words = text.split()
n_words = len(words)
start = np.random.randint(low=0, high=n_words, size=1)[0]
if start + 3 < n_words:
end = np.random.randint(low=start, high=start + 3, size=1)[0]
else:
end = np.random.randint(low=start, high=n_words, size=1)[0]
out = ' '.join(words[:start]) + ' ' + ''.join(words[start:end + 1]) + ' ' + ' '.join(words[end + 1:])
return out.strip()
Ví dụ:
remove_random_space("Trên cơ sở kết quả kiểm tra hiện trạng")
Kết quả là:
'Trên cơ sở kết quả kiểm trahiện trạng'
4. Thử nghiệm
Toàn bộ source code bao gồm cách huấn luyện mô hình và thử nghiệm mô hình, các bạn có thể vào trực tiếp github VietnameseOcrCorrectioncủa mình để theo dõi nhé. Sau khi quá trình huấn luyện kết thúc, mình thử test xem liệu kết quả có ngon ghẻ khum nhé. 
from predictor import Predictor
import time
from utils import extract_phrases
model_predictor = Predictor(device='cpu', model_type='seq2seq', weight_path='./weights/seq2seq_0.pth')
p = "Trên cơsở kếT quả kiểm tra hiện trạng, Tòa an nhân dân tối cao xẻm xét, lap phương án sắp xếp lại, xử lý \
các cơ sở nhà, đất thuộc phám vi Quản lý, gửi lấy ý kiến của Ủy ban nhân dân cấp tỉnh nơi có nhà, đất."
outs = model_predictor.predict(p.strip(), NGRAM=6)
Kết quả mô hình dự đoán:
Trên cơ sở kết quả kiểm tra hiện trạng, Tòa án nhân dân tối cao xem xét, lập phương án sắp xếp lại, xử lý các cơ sở nhà, đất thuộc phạm vi Quản lý, gửi lấy ý kiến của Ủy ban nhân dân cấp tỉnh nơi có nhà,đất.
5. Đánh giá.
Tuy mô hình đã giải quyết được các trường hợp chúng ta đã giả sử nhưng các trường hợp thực tế chúng ta cần gặp phải vô cùng đa dạng. Và trường hợp chuyển đúng thành sai cũng khó tránh khỏi.
Ví dụ như một câu: "Toi mời em ăn toi". Như vậy câu đúng là "tôi mời em ăn tối" hay là .... Đúng vậy có những trường hợp chúng ta cần phải ngữ cảnh toàn bộ câu chuyện ta mới biết câu đó như thế nào ? Nếu không mô hình sẽ dự đoán dựa trên đặc trưng bộ dữ liệu chúng được huấn luyện trên đó. Do đó theo cá nhân mình nghĩ việc sử dụng trực tiếp mô hình sửa lỗi sau OCR để đi vào thực tế phải còn phải tốn rất nhiêu công nghiên cứu nữa.
All rights reserved
