Thiết kế hệ thống URL Shortening giống Bit.ly chịu tải 6 tỷ click 1 tháng
Bài đăng này đã không được cập nhật trong 7 năm
Chắc hẳn ai trong số chúng ta cũng đã từng dùng 1 số dịch vụ URL Shortening (rút gọn link) như Bitly hay TinyURL.
Đối với 1 engineer thì việc dùng là 1 chuyện, nhưng làm thế nào để thiết kế được 1 hệ thống chịu tải hàng tỉ click mỗi tháng chắc hẳn cũng nhiều người quan tâm.
Hôm nay mình viết bài này để đào sâu vào những hệ thống đó xem họ đã thiết kế như thế nào nhé.
Mục tiêu của bài viết:
- Sẽ giúp các bạn có cái nhìn tổng quan về cách thiết kế hệ thống hàng triệu người dùng, hàng tỉ click mỗi tháng nó như thế nào. Từ cách tư duy đến cách tiếp cận bài toán.
- Có thể tự mình xây dựng được 1 hệ thống URL Shortening giống Bitly, TinyURL.
- Giúp các bạn có kinh nghiệm đi phỏng vấn vào vị trí system design.
Hệ thống URL Shortening là gì?
Chắc hẳn cũng có 1 số bạn chưa từng dùng dịch vụ rút gọn link bao giờ. Vậy để mình giải thích ngắn gọn xem URL Shortening là gì đã nhé.
URL Shortening (rút gọn link) là 1 dịch vụ giúp chúng ta có thể làm ngắn link gốc lại được.
Ví dụ như link gốc của chúng ta là: https://nghethuatcoding.com/2019/05/06/cac-ki-su-grab-da-thiet-ke-he-thong-dan-hoi-su-dung-circuit-breaker-nhu-the-nao/
Sau khi dùng qua rút gọn link thì nó sẽ trở thành thế này: http://bit.ly/2VXBAw4
Bây giờ nếu chúng ta mở link http://bit.ly/2VXBAw4 ở trình duyệt thì nó sẽ chuyển hướng đến link gốc.
Tại sao cần dùng rút gọn link?
Đây chắc hẳn là câu hỏi mà nhiều người quan tâm. Ví dụ như: cứ gửi link gốc cho người xem chứ cần gì phải rút gọn link làm gì cho nó mất thời gian? Rồi bây giờ có ai phải tự nhập link bằng tay nữa đâu mà phải làm mất công? …
Công nhận những thắc mắc đó của mọi người không sai.
Mục đích chính của việc dùng rút gọn link là:
- Nhìn link ngắn gọn trông đẹp mắt hơn.
- Có thể thống kê lượng người click vào link để phân tích, đánh giá kết quả. Phục vụ cho marketing.
- Có thể ẩn 1 số link tiếp thị liên kết với mục đích là kiếm tiền (Đây là 1 ví dụ Kiếm tiền với link rút gọn)
Yêu cầu về mặt chức năng hệ thống
Hầu hết các hệ thống rút gọn link phải đáp ứng được những yêu cầu sau:
Yêu cầu về mặt chức năng:
- Đầu vào là 1 link gốc, hệ thống sẽ rút gọn link gốc đó thành 1 dạng link ngắn hơn và duy nhất
- Khi người dùng access vào link rút gọn, hệ thống sẽ chuyển nó đến link gốc
- Người dùng có thể lựa chọn customize link rút gọn của mình theo ý muốn.
- Link rút gọn sẽ hết hạn sau 1 khoảng thời gian mặc định nào đó. Tuy nhiên người dùng có thể điều chỉnh cái khoảng thời gian này.
Yêu cầu phi chức năng:
- Hệ thống có tính available (sẵn sàng) cao. Vì sao phải cần cái này? Vì nếu hệ thống die thì toàn bộ link rút gọn lúc đó cũng die theo.
- Khi click vào link rút gọn để chuyển sang link gốc, thì thời gian redirection đó phải tối thiểu (minimal latency).
- Link rút gọn không thể đoán được.
Yêu cầu mở rộng:
- Có thể phân tích được bao nhiêu lần click vào link rút gọn?
- Cung cấp API cho bên thứ 3 có thể dùng được.
Phân tích hệ thống
Ở phần này mình sẽ trình bày cho các bạn cách ước lượng số lượng request hàng tháng, dung lượng disk, dung lượng memory cần dùng, băng thông mạng tiêu tốn là bao nhiêu …
Đa số những hệ thống rút gọn link này sẽ có lượng access khá là cao.
Giả sử như hệ thống chúng ta thiết kế sẽ có tỉ lệ read:write là 100:1. (Các bạn nhớ tỉ lệ này nhé vì nó dùng trong suốt bài viết)
Trong đó:
- tỉ lệ read ở đây tức là số lượng người click vào link rút gọn
- tỉ lệ write là số người tạo ra link rút gọn.
Ước lượng traffic
Giả sử như hệ thống của chúng ta có 500 triệu link rút gọn trong 1 tháng.
Với tỉ lệ read:write là 100:1 thì khi đó số lượng read sẽ là: 500M * 100 = 50B (M là milion, B là bilion)
Số lượng write trong 1 giây là bao nhiêu?
500M / (30 days * 24 hours * 3600 seconds) = 200 URL/s
Số lượng read trong 1 giây là bao nhiêu?
200 * 100 = 20K URL/s (vì tỉ lệ read:write là 100:1)
Ước lượng storage
Giả sử như chúng ta sẽ lưu tất cả link rút gọn trong 5 năm.
Do chúng ta có 500M link rút gọn trong 1 tháng, khi đó 5 năm chúng ta sẽ có:
500M * 12 months * 5 years = 30B URLs
Giả sử mỗi 1 link rút gọn chúng ta sẽ dùng mất 500 bytes để lưu nó trong storage. Dung lượng ổ đĩa lưu 500M URL trong 5 năm sẽ là:
30B * 500 bytes = 15TB
Ước lượng bandwith (băng thông mạng)
Trước tiên mình giải thích qua về bandwith (băng thông mạng) là gì.
Băng thông mạng là thuật ngữ chỉ lượng truyền dữ liệu (data size) trong khoảng thời gian 1 giây.
Trong đó lượng truyền dữ liệu sẽ bao gồm 2 loại là incoming data với outgoing data:
incoming data là lượng dữ liệu truyền đến server (giống như kiểu upload ấy) outgoing data là lượng dữ liệu từ server trả về cho người dùng (giống như download) Vì hệ thống của chúng ta có 200 URL mới trong 1 giây thì khi đó:
total incoming data = 200 * 500 bytes = 100 KB/s
Với read request thì hệ thống của chúng ta có 20K URL/s thì khi đó:
total outgoing data = 20K * 500 bytes = 10MB/s
Ước lượng memory
Để hệ thống có thể chạy nhanh hơn thì giải pháp tốt nhất đó là cache lại những cái link rút gọn nào mà có nhiều người dùng click.
Vậy chúng ta sẽ cần bao nhiêu memory?
Nếu chúng ta đi theo quy tắc 80:20 nghĩa là 20% số lượng link rút gọn tạo ra 80% traffic hệ thống. (Hiểu đơn giản là chỉ có 20% số lượng link rút gọn là nhiều người dùng access, còn lại 80% ko có ai access cả. Nên 20% link rút gọn sẽ tạo ra 80% traffic là vì lí do đó).
Vì chúng ta có tổng cộng 20K URL/s (hay 20K requests/s) thì khi đó 1 ngày sẽ có:
20K * 3600 seconds * 24 hours = 1.7B request/day
Để cache được 20% số request này thì chúng ta sẽ cần:
0.2 * 1.7B * 500 bytes = 170GB memory
Tóm tắt lại kích thước hệ thống
Hệ thống của chúng ta có 500M URL trong 1 tháng, và có tỉ lệ read:write là 100:1. Khi đó đặc tả về hệ thống của chúng ta sẽ như sau:
- 200 URL được tạo ra mỗi giây
- Số lượng access: 20K request/s
- Incoming data (giống như upload): 100KB/s
- Outgoing data (giống như download): 10MB/s
- Dung lượng ổ đĩa trong 5 năm: 15TB
- Dung lượng memory dùng cho cache: 170GB
Thiết kế API
Chúng ta có thể dùng SOAP hoặc là REST APIs để thiết kế API của hệ thống.
Qua những yêu cầu ở bên trên, thì ta thấy hệ thống của chúng ta ít nhất cần 2 api sau:
createURL
Đầu tiên là cần API để tạo ra link rút gọn.
createURL(api_dev_key,
original_url,
custom_alias=None,
expire_date=None)
Trong đó:
- api_dev_key (string): là API developer key của người dùng đã đăng kí tài khoản. Key này được sử dụng để định danh người dùng, giới hạn số lượng request của người dùng (hay còn gọi là rate-limiting) original_url (string): link gốc
- custom_alias (string – optional): customize key cho URL
- expire_date (string – optional): ngày hết hạn của link rút gọn
Giá trị trả về (string):
- Nếu thành công sẽ insert vào trong cơ sở dữ liệu và trả về link rút gọn
- Nếu thất bại sẽ trả về error code.
deleteURL
API thứ 2 cũng khá cần thiết đó là xoá đi link rút gọn đã đăng kí.
deleteURL(api_dev_key, url_key)
Trong đó:
- api_dev_key (string) là API developer key của người dùng đã đăng kí tài khoản
- url_key (string): là link rút gọn.
Giá trị trả về (string):
- Nếu thành công sẽ trả về link rút gọn đã bị xoá.
- Nếu thất bại sẽ trả về error code.
Làm thế nào ngăn chặn hacker?
Hacker có thể dùng api để tạo ra thât nhiều link rút gọn vượt quá thiết kế hệ thống hiện tại. Với mục đích cho hệ thống của chúng ta “đắp chiếu luôn”.
Ví dụ như hệ thống hiện tại của chúng ta đang thiết kế đáp ứng 1 tháng 500 triệu URL được tạo ra.
Và hacker tấn công sẽ tạo gấp 100 lần hiện tại là khoảng 50 nghìn tỉ URL để hệ thống sẽ tiêu thụ nhiều tài nguyên hơn, dùng nhiều memory hơn, tốn nhiều ổ đĩa hơn. Khi đó chắc chắn hệ thống sẽ bị down. Và toàn bộ link rút gọn sẽ bị tan biến.
Vậy làm thế nào để giải quyết đc bài toán này? Cách đơn giản nhất là sẽ hạn chế số lần call api thông qua api_dev_key (kĩ thuật này được gọi là rate-limiting mà Grab đang xử dụng). Ví dụ như mỗi api_dev_key sẽ chỉ cho tạo tầm 100 link rút gọn trong 1 ngày chẳng hạn.
Tuy không phải là cách hoàn hảo 100% nhưng ít nhiều cũng hạn chế được 1 số vấn đề.
Thiết kế database
Yêu cầu về database của chúng ta sẽ như sau:
- Cần lưu hàng tỉ record
- Mỗi 1 object sẽ lưu càng nhỏ càng tốt (tầm dưới 1KB)
- Không cần mối quan hệ dữ liệu giữa các record.
- Hệ thống có tỉ lệ read khá cao
Database schema:
Chúng ta sẽ cần 2 bảng chính: 1 bảng lưu thông tin người dùng, và 1 bảng lưu thông tin về URL.
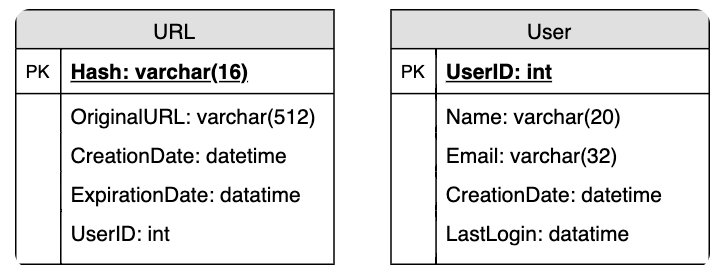
Loại Database nào nên sử dụng?
Vì chúng ta đã dự đoán trước là sẽ lưu đến hàng tỉ record, hơn nữa các bảng không có mối quan hệ nào với nhau cả nên việc dùng loại NoSQL key-value có lẽ sẽ là lựa chọn tốt nhất. Ví dụ như DynamoDB, Cassandra mình thấy đều ok cả.
Thuật toán và thiết kế hệ thống cơ bản
Vấn đề cần giải quyết ở đây là làm thế nào có thể tạo ra được 1 link rút gọn và nó duy nhất từ 1 link gốc.
Trong phần đầu tiên mình đã lấy ra 1 ví dụ về link rút gọn: http://bit.ly/2VXBAw4
Thì phần này chúng ta sẽ đi thiết kể để tạo ra được phần rút gọn, chính là 2VXBAw4.
Encoding URL
Chúng ta có thể sử dụng 1 số hàm băm (như MD5 hay SHA256) để băm giá trị đầu vào URL. Sau đó sẽ dùng 1 số hàm mã hoá để hiển thị. Ví dụ như base36 ([a-z, 0-9]), hoặc base62 ([a-z, A-Z, 0-9]) và base64 ([a-z, A-A, 0-9, -, .]).
1 câu hỏi được đặt ra ở đây là chúng ta sẽ dùng độ dài key là bao nhiêu? 6,8 hay là 10?
- Nếu dùng base64 cho 6 kí tự thì tổng chúng ta có 64^6 = 68.7B URL
- Nếu dùng base64 cho 8 kí tự thì tổng chúng ta có 64^8 = 281 nghìn tỉ URL
Do hệ thống của chúng ta có 500M URL được tạo ra mỗi tháng, hệ thống dùng trong 5 năm sẽ có tổng:
500M * 12 months * 5 = 30B URLs / 5 years.
Do đó với 68.7B URL (với 6 kí tự) là có thể dùng được trong 5 năm rồi.
Nếu chúng ta dùng thuật toán MD5 như hàm băm, thì khi đó nó sẽ tạo ra giá trị hash có chứa 128 bit. Sau đó base64 để encode giá trị băm, nó sẽ tạo ra ít nhất 21 kí tự (vì mỗi kí tự base64 sẽ encode 6 bits giá trị hash).
Trong khi đó không gian khoá của chúng ta chỉ cần 6 kí tự thôi. Vậy làm thế nào có thể chọn ra khoá? Chúng ta có thể chọn ra 6 kí tự đầu tiên cũng được. Mặc dù có trường hợp nó trùng nhau. nhưng mà xác suất chỉ tầm 1/(64^6). Nó rất là nhỏ. Nên có thể chấp nhận được.
Nếu an toàn thì mỗi lần generate ra thì sẽ check trong DB xem có hay chưa? Nếu chưa có thì ok, còn nếu có rồi thì sẽ thêm xâu random nào vào trước URL và lại lặp lại cho đến khi sinh ra unique thì thôi.
※ Cách lấy 6 kí tự đầu tiên này chỉ là 1 giải pháp thôi nhé. Các bạn có thể tự cài đặt cho mình thuật toán khác, miễn nó sinh ra được 6 kí tự unique là được.
Đây là 1 ví dụ về trường hợp lấy 6 kí tự đầu tiên:
const crypto = require('crypto');
module.exports = {
generateShortURL: (longURL, startIndex, endIndex) => {
const hash = crypto.createHash('md5').update(longURL).digest('base64');
return hash.substring(startIndex, endIndex + 1);
},
};
Giải pháp của chúng ta đang gặp vấn đề gì?
- Nhiều người dùng có thể cùng dùng chung 1 link gốc, do đó link rút gọn sẽ bị trùng lặp. Và điều này không thể chấp nhận được.
- Điều gì sẽ xảy ra nếu như 1 phần nào đó trong URL bị mã hoá. Ví dụ như http://example.com/index.php?id=design và http://example.com/index.php%3Fid%3Ddesign là 2 URL hoàn toàn giống nhau nhưng mà 1 phần URL đã bị mã hoá.
Giải quyết vấn đề trên như thế nào?
Có 2 cách tiếp cận có thể giải quyết được vấn đề này.
- Chúng ta có thể sử dụng 1 số nguyên tăng dần và gắn vào đầu mỗi link gốc. Khi đó nó sẽ luôn đảm bảo link gốc của chúng ta là duy nhất, kể cả có nhiều người cùng điền vào 1 link duy nhất đi chăng nữa thì link rút gọn sẽ luôn khác nhau. Và sau khi tạo xong link rút gọn thì số nguyên này sẽ tăng thêm 1. Nhưng mà có 1 vấn đề là nếu tăng mãi thì có thể số nguyên này sẽ bị tràn số. Hơn nữa việc xử lý tăng dần này cũng ảnh hưởng đến hiệu suất của hệ thống.
- Cách khác là chúng ta có thể thêm user_id vào đầu mỗi URL. Tuy nhiên nếu người dùng chưa đăng nhập mà muốn tạo link rút gọn, khi đó chúng ta phải yêu cầu nhập vào 1 khoá nữa. Và khoá này phải duy nhất (Nếu khoá nhập vào không duy nhất sẽ yêu cầu nhập lại, đến khi nào duy nhất thì thôi).
Và dưới đây sẽ là flow của hệ thống:
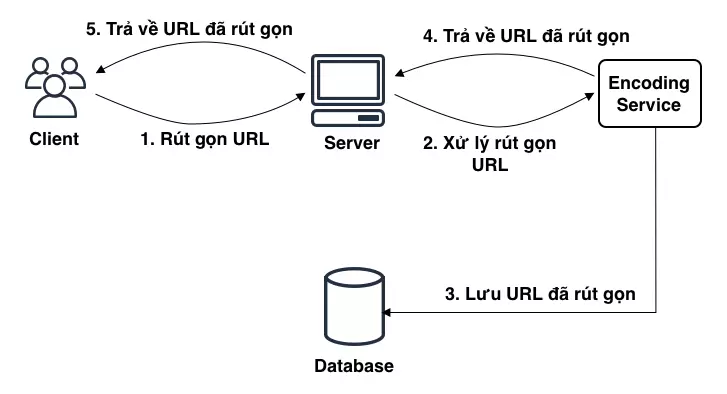
Đầu tiên người dùng nhập link muốn rút gọn, và ấn Enter. Khi đó request sẽ được gửi đến Server.
Ở Server sẽ nhận request và chuyển nó đến bộ phận chuyên xử lý việc rút gọn link. Mình gọi đó là Encoding Service đi.
Encoding Service sẽ thực hiện xử lý rút gọn URL:
- Nếu như URL đó chưa tồn tại trong hệ thống thì sẽ xử lý, lưu link đã rút gọn vào trong database đồng thời trả về cho server kết quả.
- Nếu như URL đó đã tồn tại trong hệ thống (tức là có ai đó đã sử dụng URL này rồi). Thì khi đó nó sẽ thêm 1 sequence (số nguyên tăng dần) vào đầu URL và thực hiện rút gọn link. Sau đó lưu link đã rút gọn vào trong database đồng thời trả kết qủa về cho server.
Phía Server nhận kết quả và sẽ trả về cho người dùng.
Data Partitioning and Replication
Nếu chúng ta lưu tất cả 30 tỉ URL vào trong DB, và có tới 20K request/s call vào DB. Thì khi đó có thể DB sẽ chịu tải khá lớn và dẫn đến down. Để giải quyết vấn đề này thì có 2 giải pháp:
- Phân vùng dữ liệu trong database (Data Partitioning). Tức là chúng ta sẽ tách DB ra thành nhiều con DB khác nhau. Mỗi con sẽ chứa 1 phần dữ liệu.
- Cache lại URL nào mà hay gọi để giảm thiểu query đến DB (mình sẽ giải thích cái này trong phần tiếp theo)
Đối với Data Partitioning thì sẽ có 2 loại:
Range Based Partitioning
Loại phân vùng này sẽ dựa vào chữ cái đầu tiên trong URL hoặc hash key để phân chia dữ liệu.
Ví dụ như những URL (bỏ qua phần https:// hay http://) mà bắt đầu bằng từ “a” thì sẽ cho vào DB loại “a”. Những URL nào bắt đầu bằng chữ “b” sẽ cho vào trong database loại “b”.
Nếu như phân vùng dựa vào chữ cái đầu tiên này thì chúng ta sẽ cần 26 con database khác nhau (từ a -> z)
Nhưng mà giải pháp này có thể gặp vấn đề là giả sử chúng ta cho tất cả URL bắt đầu bằng chữ “f” vào trong database loại “f”. Nhưng chẳng may tất cả URL bắt đầu bằng chữ “f” này lại là những URL có access lớn nhất. Khi đó con DB loại “f” này lại chịu tải khá lớn.
Chú ý: Kiểu phân vùng dựa vào chữ cái đầu tiên này chỉ là 1 ví dụ thôi nhé, các bạn có thể tự nghĩ ra thuật toán riêng cho mình để phân vùng dữ liệu cho hợp lí và hiệu quả. Chứ không nhất thiết cứ phải chọn chữ cái đầu tiên để phân vùng.
Hash-Based Partitioning
Loại này chúng ta sẽ lấy giá trị hash của object đang được lưu trữ. Sau đó sẽ tính toán xem phân vùng nào sẽ được xử dụng dựa vào hàm băm. Chúng ta có thể lấy giá trị hash của primary key, hoặc là link gốc để xác định xem phân vùng nào sẽ được lưu trữ dữ liệu.
Cache
Đối với hệ thống hàng tỉ click mỗi tháng thì cache server là thứ không thể thiếu được.
Lí do tại sao chúng ta cần 1 cache server?
Flow chuẩn sẽ là:
- Bước 1: người dùng accees đến link rút gọn
- Bước 2: chúng ta phải vào DB để lấy ra link gốc từ link rút gọn
- Bước 3: chuyển hướng người dùng đến link gốc.
Nếu không có cache server thì cứ mỗi lần như vậy sẽ phải vào trong DB để lấy kết quả. Và dẫn đến DB sẽ phải chịu tải khá lớn. Để giảm thiểu query đến DB, chúng ta sẽ cache lại kết quả truy vấn trước đó. Để từ lần sau nếu người dùng có truy cập vào link rút gọn thì lúc này chúng ta chỉ cần vào cache lấy ra là xong, mà không phải query vào DB để lấy kết quả nữa.
Vì Cache Server sẽ luôn lưu dữ liệu trên memory. Nên so với việc lấy kết quả từ DB thì việc lấy kết quả từ memory sẽ nhanh hơn rất nhiều lần.
Chúng ta cần dùng Cache Server nào?
Hiện nay thì có rất nhiều cache server như Redis, Memcache. Mình thấy nó khá nổi tiếng và cũng đang được dùng khá rộng rãi trên các hệ thống lớn trên thế giới.
Trước mình làm công ty về Game và hệ thống bên mình lúc đó dùng Redis và mình thấy nó khá ổn và support rất nhiều chức năng. Ví dụ như tự động xếp hạng ranking kết quả, có thể sync dữ liệu giữa memory và storage để phòng tránh mất dữ liệu…
Nên nếu bạn nào chưa biết nên dùng cái nào thì mình khuyên nên tìm hiểu và implement thằng Redis này.
Chúng ta cần bao nhiêu GB memory?
Như phần trước mình đã tính toán là hệ thống này sẽ dùng đến 170GB memory để cache 20% URL. Mà hiện nay server có 256GB memory cũng khá nhiều nên thừa sức giải quyết vấn đề này.
Ngoài ra chúng ta có thể tổ hợp nhiều server nhỏ (mỗi server có 8GB memory chẳng hạn) để cache các URL đó lại cũng được cả.
Nếu cache full thì làm thế nào?
Đa số hệ thống cache đều thực hiện theo 1 số cơ chế như LRU (Least Recently Used) hay LFU (Least Frequently Used).
- LRU (Least Recently Used): bỏ đi các item trong cache ít được dùng gần đây nhất.
- LFU (Least Frequently Used): bỏ đi các item trong cache ít được sử dụng nhất.
Do có các cơ chế này nên cache sẽ luôn được làm mới để tránh việc dùng full.
Cơ chế hoạt động của Cache Server:
Mình sẽ giải thích qua về cơ chế của Cache Server nhé:
- Đầu tiên người dùng access đến link rút gọn.
- Khi đó, application server sẽ check xem có kết quả ở trong cache không?
- Nếu kết quả không có trong cache, thì nó sẽ thực hiện truy vấn đến DB để lấy kết quả và trả về cho người dùng. Đồng thời update kết quả vào trong cache để phục vụ cho lần sau.
- Nếu kết quả có trong cache thì sẽ lấy luôn kết quả và trả về cho người dùng.
Các bạn thấy cơ chế khá đơn giản phải không nào.
Load Balancer
Với hệ thống nhiều access như hệ thống này thì 1 web server chưa chắc đã chịu tải được. Để giải quyết bài toán này thì mình sẽ dùng nhiều web server. Mỗi web server sẽ chịu 1 phần request từ người dùng.
Câu hỏi đặt ra là làm thế nào có thể tự động phân request đến từng con web server khác nhau?
Và Load Balancer đã ra đời để giải quyết vấn đề này.
Ví dụ như dưới Load Balancer có 1 số con web server. Lần 1 request từ Client gửi đến Load Balancer sẽ được forward đến con web server 1. Lần 2 sẽ được gửi đến con web server 2 ….
Hiện nay 1 số nhà cung cấp server như AWS, Google hay Azure đều support Load Balancer cả. Nên các bạn không cần phải lo lắng về việc phải build 1 con load balancer. Chỉ việc cài đặt và dùng là xong.
Kiến trúc toàn bộ hệ thống
Sau khi đã hiểu qua hết các thành phần thì mình tổng hợp lại kiến trúc tổng thể của hệ thống như sau:
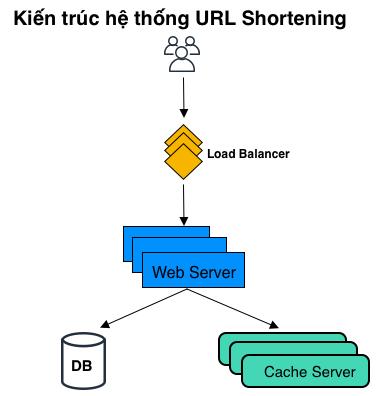
Kết luận
Đọc qua bài này chắc hẳn các bạn cũng có 1 chút tư duy trong việc thiết kế hệ thống lớn phục vụ hàng triệu người dùng nó như thế nào rồi phải không?
Sau khi đã có tư duy rồi thì mình nghĩ nếu gặp phải 1 hệ thống tương tự như thế thì các bạn cũng thừa sức để giải quyết.
Vì nhiều bạn mới ra trường hay những bạn chưa từng làm trong các hệ thống lớn chắc chưa hình dung được nên bắt đầu từ đâu, nên sử dụng công nghệ nào. Thì qua bài này hi vọng sẽ giúp các bạn giải đáp những thắc mắc đó.
Nguồn: https://nghethuatcoding.com/2019/05/13/thiet-ke-he-thong-url-shortening/
==============
Để nhận thông báo khi có bài viết mới nhất thì các bạn có thể like fanpage của mình ở bên dưới nhé:
👉👉👉 Nghệ thuật Coding Fanpage Facebook
Chúc các bạn 1 tuần thật vui vẻ.
All rights reserved
