TensorRT - Sự vượt trội với bài toán tối ưu mô hình Deep Learning
Bài đăng này đã không được cập nhật trong 2 năm
Phần mở đầu
TensorRT là một thư viện được phát triển bởi NVIDIA và là một phần của NVIDIA Deep Learning Accelerator (NVIDIA), dùng để tối ưu hóa mô hình AI, học máy chạy trên GPU -> Giúp cải thiện tốc độ và hiệu suất khi triển khai môi hình trên các hệ thống nhúng và máy tính.
Khi xây dựng các mô hình AI, chúng có thể trở nên rất nặng và tốn kém tài nguyên tính toán. TensorRT giúp khắc phục vấn đề đó: giảm thiểu tài nguyên tính toán và bộ nhớ cần thiết để chạy các mô hình AI một cách hiệu quả, cải thiện hiệu suất về thời gian chạy mô hình.
Cùng tìm hiểu khái quát về mô hình học sâu (Deep Learning) là gì và cách chúng ta thực hiện như thế nào nhé!
Mô hình Deep Learning

Deep Learning là một tập hợp con của Machine Learning, về cơ bản là một mạng nơ-ron có 3 lớp trở lên. Mạng nơ-ron nhân tạo (Neural network) chính là động lực chính để phát triển Deep Learning. Các mạng now0ron sâu (Deep Neural Network) bao gồm nhiều lớp khác nhau, có khả năng thực hiện các tính toán có độ phức tạp rất cao.
Cấu trúc của mô hình Deep Learning
Một mô hình học sâu được biểu diễn bằng một biểu đồ (đồ thị) tính toán. Biểu đồ này được tạo thành từ các inputs thay đổi trong quá trình hoạt động, parameters hoặc weights và kernels.
- Inputs: Dữ liệu được đưa vào mô hình (có thể là image, text, audio ...).
- Architecture: Kiến trúc của mô hình được biểu diễn là một biểu đồ (đồ thị).
- Weights: Trọng số là các parameters của mô hình và chúng được điều chỉnh (update) khi huấn luyện mô hình.
- Kernels: được đề cập tới trong các lớp của mô hình ví dụ như: conv, relu, …, là phép tính toán logic trong mô hình.
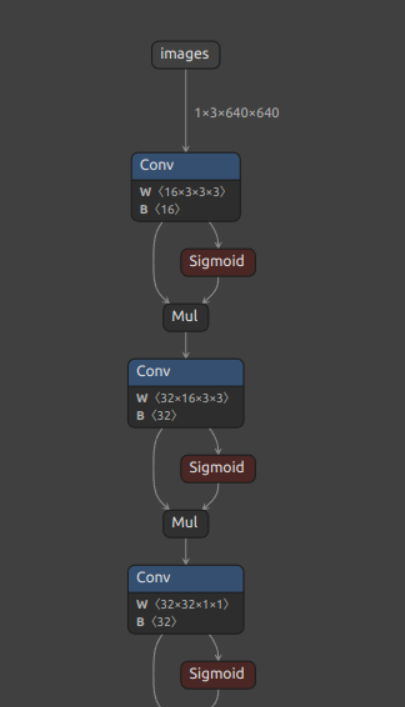
Biểu diễn biểu đồ tính toán của mô hình yolov8
Biểu đồ cho thấy dữ liệu đầu vào có thể là hình ảnh hoặc là video. Các node đại diện cho các hoạt động (các lớp), các parameters trong mô hình.
Triển khai với mô hình học sâu
Triển khai mô hình học sâu là quá trình sử dụng DNN, được đào tạo để đưa ra dự đoán về dữ liệu mới. DNN gồm đầu vào là dữ liệu mới và đầu ra là dự đoán của mô hình.
Một mô hình học sâu được huấn luyện tốt là mô hình đưa ra dự đoán chính xác về hình ảnh đầu vào với nhãn tương ứng. Một mô hình DNN hoàn chỉnh sẽ chứa rất nhiều tham số. Mạng càng lớn thì cần càng nhiều tài nguyên tính toán, không gian lưu trữ.
Một giải pháp cải thiện tốc độ cũng nhỉ tối ưu mô hình DNN là TensorRT. TensorRT có thể chạy trên edge devices, thường được tích hợp trên cloud. Chúng ta đã phần nào nắm được cách thức hoạt động và hướng phát triển của một mô hình DNN, tiếp theo hãy cũng đi sâu và TensorRT để xem nó xử lý như nào nhé!
TensorRT
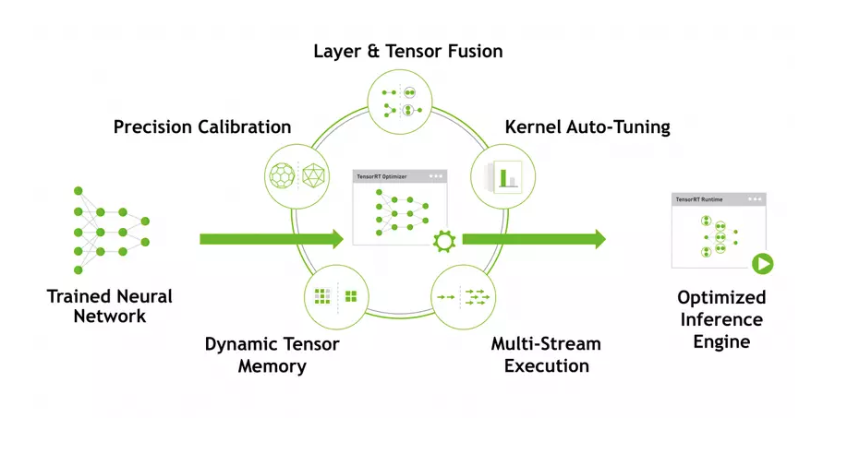
TensorRT sẽ thực hiện các loại tối ưu để tăng hiệu suất inferences:
- Precision Calibration
- Layer and Tensor Fusion
- Kernel Auto-Tuning
- Dynamic Tensor Memory
- Multi-Stream Execution
Precision Calibration
Precision Calibration trong TensorRT là một quá trình quan trọng để tối ưu hóa mô hình và cải thiện độ chính xác khi triển khai mô hình AI bằng TensorRT trên các thiết bị có cấu hình thấp.
Khi một mô hình AI được xây dựng và huấn luyện trên một máy tính có GPU mạnh, thông thường mô hình sẽ sử dụng các kiểu dữ liệu có dấu chấm động (floating-point) để đạt được độ chính xác cao nhất trong quá trình huấn luyện. Tuy nhiên khi triển khai các mô hình trên hệ thống nhúng hoặc máy tính có cấu hình thấp hơn, sử dụng kiểu dữ liệu dấu chấm động có thể gây ra sai số và giảm đáng kể hiệu suất của mô hình.
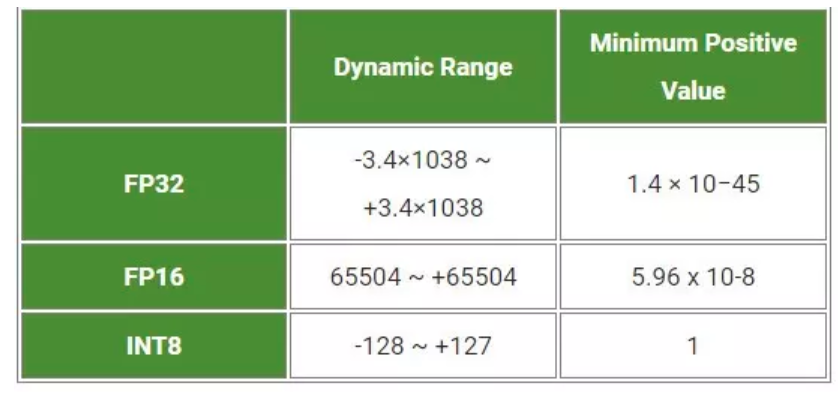
Precision Calibration (hiệu chuẩn độ chính xác) giúp giải quyết vấn đề trên bằng cách tùy chỉnh độ chính xác sao cho phù hợp với khả năng tính toán của thiết bị triển khai. Quá trình này đòi hỏi mô hình được kiểm tra trên dữ liệu test, và TensorRT sẽ tự động tìm kiếm giá trị tối ưu cho kiểu dữ liệu.
Trong suốt quá trình training, các parameters và activation function có độ chính xác trong khoảng FP32 (floating-point 32) sẽ được convert về khoảng FP16 hoặc INT8. Việc tối ưu nó sẽ giúp tăng tốc inferences nhưng độ chính xác sẽ bị ảnh hưởng nhưng không dù không nhiều. Trong nhận diện real-time thì việc đánh đổi độ chính xác để lấy tốc độ inferences là cần thiết.
Layer and Tensor Fusion
Layer and Tensor Fusion tron TensorRT là các kỹ thuật tối ưu hóa mô hình AI để cải thiện hiệu suất thời gian chạy, bằng cách kết hợp nhiều lớp (layers) và tensors lại với nhau để giảm thiểu số lượng phép tính và tối ưu hóa tính toán song song GPU.
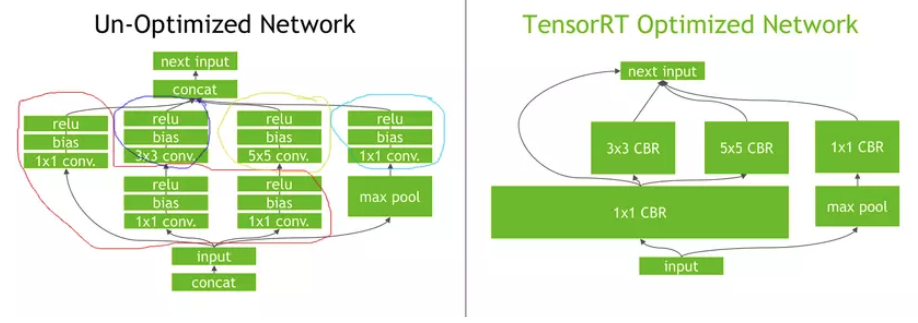
Layer Fusion (Gộp lớp): là quá trình kết hợp nhiều lớp trong mô hình thành một lớp duy nhất có chức năng tương đương. Khi một mô hình AI được xây dựng bằng các framework deep learning như Tensorflow hay Pytorch nó thường được biểu diễn dưới dạng một chuỗi các layers liên tiếp. Mỗi layer sẽ có phép tính toán cụ thể và truyền kết quả đến lớp tiếp theo. Tuy nhiên, một số lớp có thể có chức năng tương đương hoặc có thể kết hợp thành một lớp duy nhất, giúp giảm số lượng phép tính và tối ưu hóa mô hình. Khi TensorRT phát hiện các cấu trúc tương tự này, nó sẽ thực hiện Layer Fusion để gộp các lớp lại thành một lớp duy nhất. Quá trình này giảm thiểu chi phí tính toán và làm cho mô hình chạy nhanh hơn trên GPU.
Ví dụ với convolutional layer và activation function là relu, TensorRT sẽ kết hợp cả 2 lớp này thành một lớp duy nhất đó là ConvolutionalActivation Layer -> Quá trình này giúp giảm số lượng phép tính và cải thiện hiệu suất.
Tensor Fusion (Gộp Tensor): là quá trình kết hợp các phép tính trên tensor lại với nhau để giảm số lượng phép tính cần thiết. Khi có một mô hình AI, các phép tính trên các tensor thường được thực hiện một cách riêng biệt, mỗi phép tính sẽ tạo ra một tensor trung gian và được sử dụng trong phép tính tiếp theo. Tuy nhiên một số phép tính có thể được kết hợp lại thành một phép tính duy nhất để giảm số lượng tensor trung gian và phép tính trên GPU. Quá trình này sẽ giúp chúng ta giảm thiểu độ phức tạp tính toán.
Ví dụ với convolutional layer và batch normalization, TensorRT có thể kết hợp cả 2 lớp này thành một lớp duy nhất là ConvolutionalBatchNorm layer -> Quá trình này giúp giảm số lượng tensor trung gian và cải thiện hiệu suất.
Kernel Auto-Tuning
Kernel Auto-Tuning trong TensorRT là quá trình tự động tìm kiếm và tối ưu các tham số và cấu hình của các kernel(nhân) tính toán trên GPU để đạt được hiệu suất tối đa cho mô hình trí tuệ nhân tạo khi triển khai bằng TensorRT. Khi mô hình AI được chuyển đổi và tối ưu hóa bằng TensorRT để triển khai trên GPU, TensorRT sẽ chạy các nhân tính toán trên GPU để thực hiện các phép tính trong mô hình, mỗi nhân sẽ có một số lượng lớn các tham số và cấu hình khác nhau.
Kernel Auto-Tuning tự động tối ưu hóa các tham số và cấu hình này bằng cách thử nghiệm một loạt các giá trị khác nhau để tìm ra các giá trị tối ưu cho mô hình và GPU cụ thể. TensorRT chọn các hạt nhân tối ưu dựa trên các thông số của mô hình, ví dụ: batch_size, filter-size, input data size.
Dynamic Tensor Memory
Dynamic Tensor Memory là tính năng trong TensorRT cho phép mô hình trí tuệ nhân tạo sử dụng quản lý bộ nhớ động cho các tensor, giúp tiết kiệm tài nguyên và tăng tính linh hoạt khi triển khai mô hình trên các hệ thống có tài nguyên hạn chế.
Chỉ phân bổ bộ nhớ cần thiết cho mỗi tensor và chỉ trong suốt thời gian sử dụng của nó và giảm dung lượng bộ nhớ và cải thiện việc sử dụng lại bộ nhớ.
Multiple-Stream Execution
Multiple stream execution (thực thi đa luồng) trong TensorRT là một tính năng cho phép mô hình AI được triển khai trên TensorRT chạy đồng thời trên nhiều luồng của GPU, giúp cải thiện hiệu suất và tăng tốc độ thời gian chạy của mô hình.
Khi mô hình được triển khai trên GPU, một trong những hạn chế chính là là thời gian thực hiện các phép tính. Trong môi trường đơn luồng (single thread). các phép tính phải được thực hiện một các tuần tự, dẫn đến hiệu suất giảm khi phải chờ các phép tính trước đó hoàn thành.
Multi stream execution cho phép chạy nhiều luồng độc lập trên GPU, trong đó mỗi luồng thực hiện các phép tính của mô hình một cách đồng thời. Điều này giúp tăng tính song song và giảm thời gian trễ khi thực hiện các phép tính, từ đó cải thiện hiệu suất của mô hình.
Cơ chế hoạt động của TensorRT
TensorRT cung cấp nhiều kĩ thuật tối ưu hóa để giảm thiểu số lượng phép tính cần thiết để tính toán kết quả và tăng tốc độ chạy của mô hình.
- Lượng tử hóa (Quantization): Giảm kích thước của các tham số của mô hình bằng cách giảm số lượng bit được sử dụng để biểu diễn các tham số đó. Việc giảm lượng dữ liệu này giúp giảm lượng dữ liệu tính toán và tăng tốc độ dữ liệu được truyền qua mạng
- Tối ưu (Pruning): Loại bỏ các trọng số không cần thiết trong mô hình bằng cách đặt chúng bằng 0. Các trọng số không cần thiết này được xác định bằng cách sử dụng các thuật toán như LK1 regularization hoặc Taylor approximation. Việc loại bỏ các trọng số không cần thiết giúp giảm số lượng phép tính cần tính toán và chạy nhanh hơn trên các thiết bị nhúng. Pruning có thể ảnh hưởng tới hiệu suất thời gian chạy của mô hình tùy thuộc vào mức độ Pruning và khả năng tương thích với TensorRT.
- Kết hợp (Fusion): Kỹ thuật này kết hợp các phép tính nhỏ thành một phép tính lớn để giảm số lượng phép tính phải thực hiện. Fusion có thể thực hiện tính toán với các phép tính như: Element-wise, Convolutional, Batch Normalization, Element-wise activation, Multi-Head Attention. Việc sử dụng Fusion trong TensorRT thường được thực hiện tự động trong quá trình tối ưu hóa mô hình. Khi chúng ta convert mô hình sang định dạng TensorRT thì TensorRT sẽ tự động áp dụng kỹ thuật Fusion để giảm số lượng phép tính có trong mô hình và tối ưu hóa hiệu suất. Điều này giúp triển khai mô hình có hiệu suất cao hơn trên NVIDIA GPU.
- Tự động tối ưu kernel (Kernel auto-tuning): Kỹ thuật này hỗ trợ tìm kiếm kernel tốt nhất để tính toán các phép tính trên GPU bằng cách thử nghiệm nhiều kernel với các thông số khác nhau và chọn kernel có tốc độ tính toán cao nhất. Kernel auto-tuning giúp cho mô hình học máy hoạt động tốt nhất trên các GPU khác nhau và trong các tình huống cụ thể
- Tinh chỉnh độ chính xác (Precision calibration): Kỹ thuật này tìm kiếm giá trị có độ chính xác tốt nhất để tính toán kết quả. Giúp cho mô hình giảm dung lượng bộ nhớ và tăng tốc độ tính toán, đặc biệt là khi triển khai trên thiết bị có tài nguyên hạn chế.
Có thể thấy TensorRT hoạt động bằng cách chuyển đổi, tối ưu hóa, và tinh chỉnh mô hình máy học để cải thiện hiệu suất tính toán trên GPU. Điều này giúp bạn triển khai mô hình máy học với hiệu suất cao hơn và tiêu tốn ít tài nguyên tính toán trên các thiết bị NVIDIA.
Tiến hành cài đặt và triển khai TensorRT
Có khá nhiều cách để giúp bạn cài đặt TensorRT, nhưng mình sẽ hướng dẫn bạn cài đặt theo cách mình hay làm nhất và mình đã thực hiện điều đó nhiều lần (Mình đã cài đi cài lại hàng chục lần vì khi build thì bị conflict tùm lum, có nhiều cái mình cũng không biết lý do tại sao 😂)
Cài đặt NVIDIA driver
ubuntu-drivers devices # check driver của card đồ họa
#example
#== /sys/devices/pci0000:00/0000:00:01.0/0000:01:00.0 ==
#modalias : pci:v000010DEd00001F95sv00001028sd0000097Dbc03sc02i00
#vendor : NVIDIA Corporation
#model : TU117M [GeForce GTX 1650 Ti Mobile]
#driver : nvidia-driver-440 - distro non-free recommended
#driver : xserver-xorg-video-nouveau - distro free builtin
sudo apt install nvidia-driver-440 # recommend version
Cài đặt CUDA-toolkit
Hãy vào trang chủ của NVIDIA để cài đặt cuda-toolkit cho nó uy tín nhé.
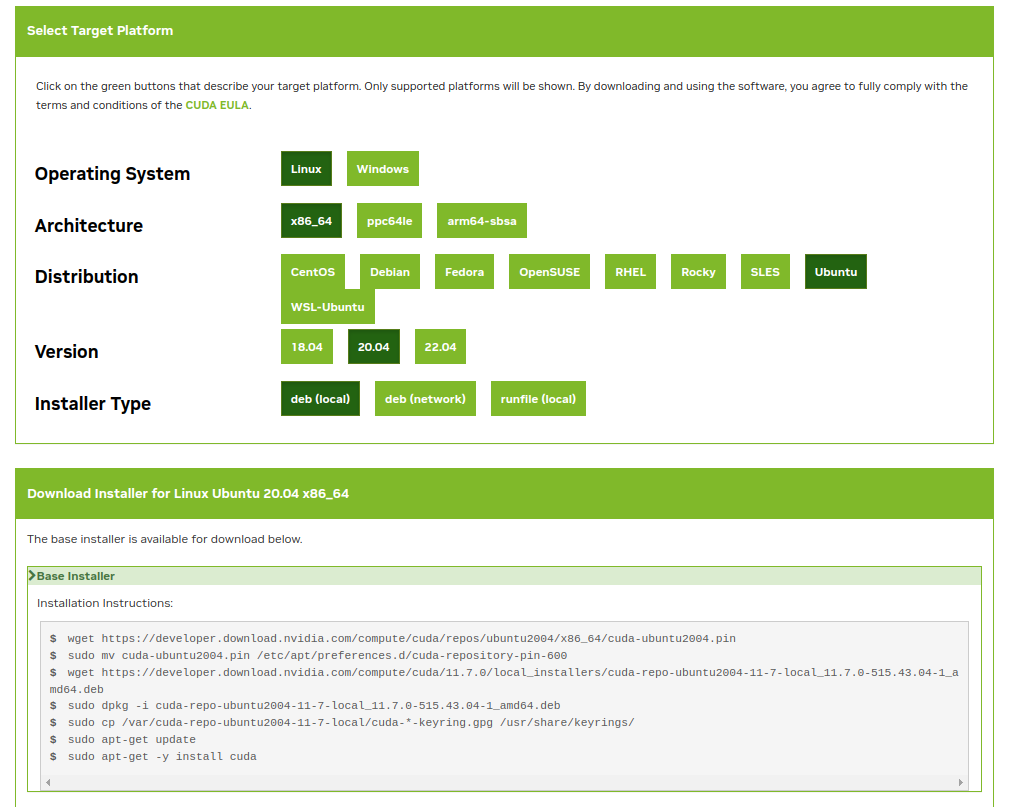
Bạn đã từng nghe cái tên cuda-toolkit chứ? Về cơ bản, đây là một nền tảng tính toán và lập trình với sứ mệnh thay đổi cách mà GPU NVIDIA hoạt động đó là chuyển từ cách thức tính toán tuần tự sang song song. Tiến hành cài đặt trong terminal:
#Install by apt
sudo apt install nvidia-cuda-toolkit
#Check cuda-toolkit
nvidia-smi
Cài đặt CuDnn
Truy cập trang tải xuống và chọn phiên bản phù hợp nhé! Mình recommend nên cài đặt phiên bản Local Installer for Ubuntu20.04 x86_64 (Deb)

# Cài file deb
sudo dpkg -i cudnn-local-repo-${OS}-8.x.x.x_1.0-1_amd64.deb
# Import the CUDA GPG key.
sudo cp /var/cudnn-local-repo-*/cudnn-local-*-keyring.gpg /usr/share/keyrings/
# Refresh the repository metadata.
sudo apt-get update
# Install the runtime library.
sudo apt-get install libcudnn8=8.x.x.x-1+cudaX.Y
Cài đặt TensorRT
Các bạn truy cập install guide thực hiện các bước như sau:
Tải TensorRT ở tensorrt-download (mình Recommend TensorRT 8, TensorRT 8.5 GA for Ubuntu 20.04 and CUDA 11.0, 11.1, 11.2, 11.3, 11.4, 11.5, 11.6, 11.7 and 11.8 DEB local repo Package)
Mở terminal và tiến hành cài đặt với Python:
os="ubuntuxx04"
tag="8.x.x-cuda-x.x"
sudo dpkg -i nv-tensorrt-local-repo-${os}-${tag}_1.0-1_amd64.deb
sudo cp /var/nv-tensorrt-local-repo-${os}-${tag}/*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get install tensorrt
sudo apt-get install python3-libnvinfer-dev
pip3 install tensorrt

Khi bạn import được tensorrt thì lúc đó mình xin chúc mừng bạn, bạn đã đi được nửa chặng đường rồi. Cài cắm đã xong, giờ mình sẽ thực hiện một ví dụ dễ như ăn kẹo để chúng ta cùng làm quen nhé.
Triển khai với mô hình Pytorch
Điều tiên quyết để bước vào bài blog này và thực hiện triển khai hay cài đặt thì máy tính hoặc laptop của bạn phải có GPU nhé, không lại cài mãi không được, lúc đó thì “dở khóc dở cười” lắm 😂
Mình thấy Yolov8 vừa mới được tung ra thị trường, hãy cùng mình thử nhé!
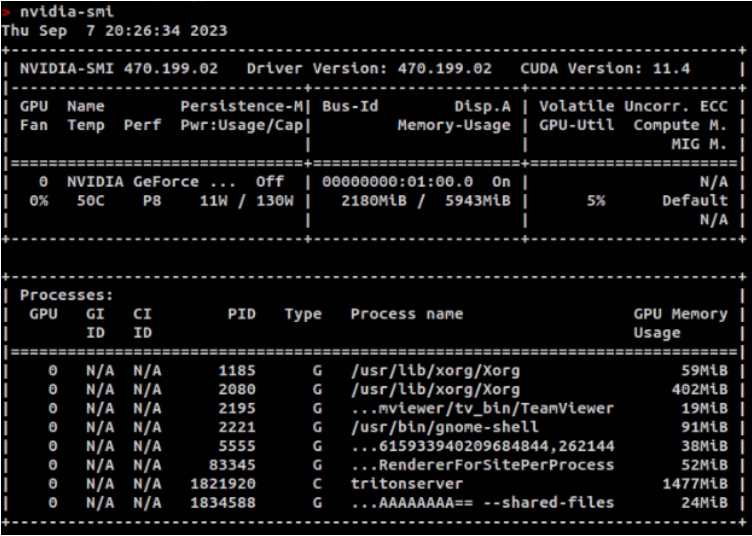
Trước tiên hãy cùng mình kiểm tra nvidia của bạn.
nvidia-smi
Hãy cài đặt thêm thư viện ultralytics để triển khai mô hình yolov8 nhé
# Cài đặt thư viện ultralytics
pip install ultralytics
# Kiểm tra thư viện ultralytics đã được cài đặt thành công chưa
python3
>>> import ultralytics
>>>
Sau khi đã tải xong thư viện, hãy cùng tham khảo CLI của utralytics để convert mô hình yolov8n sang tensorrt.
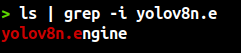
yolo mode=export model=yolov8n.pt format=engine device=0
Nếu kết terminal hiện như trên thì bạn đã convert xong rồi đó. Lúc này ta sẽ thu được file engine yolov8
Giờ thì hãy bắt đầu inference model nào Hãy cùng inference model nhé!
# Chạy thử với mô hình ONNX
import ultralytics
from ultralytics import YOLO
from matplotlib import pyplot as plt
import numpy as np
import cv2
model = YOLO('yolov8n.onnx') # tải mô hình ONNX
result=model('images/image003_4.jpg')[0] # Dự đoán ảnh từ thư mục
boxes = result.boxes.xywh.cpu().numpy() # lấy toa đô của boxes
probs = result.probs # lấy xác suất của các vât thể trong ảnh
image_drawed = result.plot()
cv2.imwrite("result.jpg",image_drawed) # lưu ảnh xuống máy
# Chạy thử với mô hình TensorRT
import ultralytics
from ultralytics import YOLO
from matplotlib import pyplot as plt
import numpy as np
import cv2
model = YOLO('yolov8n.engine') # tải mô hình ONNX
result=model('images/image003_4.jpg')[0] # Dự đoán ảnh từ thư mục
boxes = result.boxes.xywh.cpu().numpy() # lấy tọa độ của boxes
probs = result.probs # lấy xác suất của các vật thể trong ảnh
image_drawed = result.plot()
cv2.imwrite("result_tensorRT.jpg",image_drawed) # lưu ảnh xuống máy
Nhận thấy hình ảnh kết quả thu được đều chính xác. Vậy là bạn đã inference xong mô hình tensorrt rồi đó.
Đánh giá và kết luận
Qua bài viết này chúng ta đã cùng nhau tìm hiểu về cơ chế và tính chất của TensorRT. Có thể thấy TensorRT là một công cụ mạnh mẽ dùng để triển khai mô hình trên các thiết bị GPU. Với việc tối ưu hiệu suất vượt trội, với các kĩ thuật tối ưu hóa như đồng bộ hóa, tổng hợp, tinh chỉnh trọng số giúp cho mô hình đạt tốc độ tốt hơn. Không chỉ vậy TensorRT hỗ trợ trên nhiều kiến trúc GPU khác nhau và tích hợp dễ dàng, bạn có thể tạo vào và tối ưu hóa mô hình tùy chỉnh để đáp ứng với yêu cầu của bài toán.
Tham khảo
All rights reserved
