System Recovery - Mô hình hệ thống
Bài đăng này đã không được cập nhật trong 7 năm
Trong các phần trước, ta đã nói về các nguyên nhân cơ bản, một số mô hình phục hồi hệ thống và giới thiệu về khôi phục CSDL. Trong phần này, ta sẽ nói về một Mô hình hệ thống để có thể hiểu rõ hơn về các kỹ thuật, thuật toán sẽ được nhắc đến trong các phần sau. Bắt đầu thôi!
Khóa giả định
Từ quan điểm về các giao dịch, hệ thống khôi phục là một phần của hệ thống lưu trữ để xử lý các thao tác đọc, ghi, cam kết và hủy bỏ. Hệ thống khôi phục tạo một số giả định về các giao dịch sử dụng dịch vụ của nó.
Giao dịch chính là giao dịch chịu trách nhiệm thiết lập các khóa trước khi thực hiện các thao tác đọc và ghi vào hệ thống lưu trữ và nó giữ các khóa ghi của nó cho đến khi giao dịch cam kết hoặc hủy bỏ. Trong khi một giao dịch giữ một khóa ghi trên bất kỳ dữ liệu nào mà nó cập nhật cho đến khi nó cam kết hoặc hủy bỏ, không có giao dịch nào khác có thể đọc hoặc ghi dữ liệu đó khi đó. Điều này tránh ba tình huống phục hồi lộn xộn. 
Tình huống lộn xộn đầu tiên - không đảm bảo khả năng phục hồi. Giả sử một giao dịch được cho phép giải phóng ổ khóa trước khi nó cam kết hoặc hủy bỏ. Xem xét một giao dịch T2 đọc một mục dữ liệu được cập nhật lần cuối bởi một giao dịch đang hoạt động T1, và T2 cam kết trong khi T1 vẫn hoạt động. Nếu T1 sau đó hủy bỏ, việc thực hiện sẽ như sau:
E = w1[x] r2[x] commit2 abort1
Trình quản lý dữ liệu hiện đang bị kẹt. Nó nên hủy bỏ T2, bởi vì T2 đã đọc dữ liệu mà bây giờ không còn hợp lệ; nhưng nó không thể vì T2 đã cam kết. Tức là, trình quản lý dữ liệu đang ở trong trạng thái mà dữ liệu không thể phục hồi. Do đó điều quan trọng là một giao dịch không được cam kết nếu nó đọc bất kỳ dữ liệu nào được cập nhật lần cuối bởi một giao dịch vẫn còn hoạt động. Nghĩa là, hoạt động cam kết của giao dịch T phải tuân thủ theo cam kết của mỗi giao dịch mà T đọc từ đó. Giữ khóa ghi cho đến khi một giao dịch cam kết hoặc hủy giải quyết vấn đề này; một giao dịch không thể đọc dữ liệu được cập nhật lần cuối bởi một giao dịch vẫn đang hoạt động, bởi vì nó đang giữ một khóa ghi trên dữ liệu đó.
Tình huống lộn xộn thứ hai - hủy bỏ tầng. Xem xét tình huống tương tự như trong đoạn trước đó, nơi T2 đọc dữ liệu được cập nhật lần cuối bởi một giao dịch đang hoạt động T1. Nhưng lần này, giả sử T1 hủy trong khi T2 vẫn hoạt động. Việc thực hiện sẽ như sau:
E' = w[1] r[2] abort1
Cũng như trước, T2 cũng phải hủy bỏ, vì đầu vào của nó sẽ không còn hợp lệ. Đây được gọi là hủy bỏ tầng, kể từ khi hủy bỏ một dòng giao dịch (T1) đến hủy bỏ giao dịch khác (T2). TÌnh huống này chắc chắn còn tốt hơn trong tình huống ở đoạn trước, vì ít nhất nó có thể hủy bỏ T2 (vì T2 vẫn hoạt động, chưa cam kết). Nhưng hệ thống vẫn cần theo dõi các giao dịch nào phụ thuộc vào các giao dịch khác - cần "sổ sách kế toán" không cần thiết. Chúng ta có thể tránh sổ sách kế toán này bằng cách yêu cầu một giao dịch chỉ đọc dữ liệu được cập nhật lần cuối bởi một giao dịch đã cam kết. Trình quản lý dữ liệu có thể tránh việc hủy bỏ tầng bằng cách đảm bảo rằng mọi giao dịch giữ khóa ghi của nó cho đến khi nó cam kết hoặc hủy bỏ.
Tình huống lộn xộn thứ ba là không thể hủy bỏ một giao dịch đơn giản bằng cách khôi phục các giá trị dữ liệu đã được ghi trước. Điều này phát sinh nếu một giao dịch có thể ghi đè lên các dữ liệu được ghi của giao dịch chưa cam kết khác. Ví dụ, nếu T1 không giữ khóa ghi của nó cho đến khi nó cam kết hoặc hủy bỏ, thì một giao dịch khác có thể ghi đè dữ liệu được T1 ghi. Hệ quả là khá khó chịu, như minh họa bằng cách thực hiện sau đây:
E'' = w1[x] w2[x] abort1 abort2
Khi thực hiện E’’, khi giao dịch T1 hủy bỏ, hệ thống không thể đơn giản khôi phục lại giá trị x trước khi w1[x], vì đó sẽ quét sạch kết quả của hoạt động ghi T2, w2[x]. Tại thời điểm này, hệ thống không biết liệu T2 sẽ cam kết hay hủy bỏ. Nếu T2 sau đó cam kết, cập nhật của nó cho x sẽ bị mất. Vì vậy, trình quản lý dữ liệu không nên làm gì khi T1 hủy bỏ. Bây giờ, khi T2 hủy bỏ, hệ thống không thể khôi phục lại giá trị x trước khi w2[x], vì đó sẽ cài đặt lại giá trị được viết bởi T1, giao dịch mà đã bị hủy bỏ. Vì vậy, khi T2 hủy bỏ hệ thống sẽ khôi phục lại giá trị x trước khi w1[x]. Đây là một phân tích khá phức tạp để khôi phục, và điều này chỉ là cho hai bản cập nhật của hai giao dịch. Nếu nhiều giao dịch tham gia, việc phân tích thực sự rất khó khăn. Tất cả các hệ thống chúng ta biết đều tránh nó bằng cách cho phép một giao dịch ghi một mục dữ liệu chỉ khi giao dịch trước đó cập nhật dữ liệu đã cam kết. Việc này diễn ra vô cùng nghiêm ngặt. Điều này thường được thực hiện bằng cách yêu cầu khóa ghi được giữ cho đến khi giao dịch cam kết hoặc hủy bỏ. Nó đảm bảo rằng trình quản lý dữ liệu có thể hủy bỏ giao dịch đơn giản bằng cách khôi phục các giá trị dữ liệu trước đó mà giao dịch đã ghi.
Nói tóm lại, nhiều vấn đề về khôi phục trở nên đơn giản hơn nhiều nếu hệ thống khôi phục có thể giả định rằng một giao dịch giữ khóa ghi của nó cho đến khi nó cam kết hoặc hủy bỏ. Tất cả các hệ thống chúng ta biết đều dựa vào giả định này.
Trang hoạt động chi tiết
 Khóa chi tiết là một khía cạnh khác của khóa tác động đến sự phức tạp của cơ chế phục hồi. Các thuật toán khôi phục đơn giản hơn khi trang khoá chi tiết được sử dụng. Đây là lý do tại sao.
Khóa chi tiết là một khía cạnh khác của khóa tác động đến sự phức tạp của cơ chế phục hồi. Các thuật toán khôi phục đơn giản hơn khi trang khoá chi tiết được sử dụng. Đây là lý do tại sao.
Các hoạt động thực sự đáng tin cậy duy nhất mà một trình quản lý dữ liệu có sẵn là ghi một trang vào một đĩa. Đĩa cứng sẽ lưu trữ cẩn thận việc thực hiện một hoạt động nguyên tử (tức là tất cả hoặc không có gì) liên quan đến lỗi hệ thống. Nghĩa là, nếu hệ thống lỗi, sau đó khôi phục, và sau đó một chương trình đọc một trang P từ đĩa, nội dung của P phản ánh lần ghi hoàn chỉnh cuối cùng vào P trước khi hệ thống lỗi.
Mặc dù phần cứng được thiết kế để làm cho đĩa ghi nguyên tử, lỗi vẫn có thể. Ví dụ, nếu đĩa bị trục trặc, nó vẫn có thể thực hiện một phần thao tác ghi trên trang P. Trong trường hợp đó, thao tác tiếp theo để đọc P có thể phát hiện ra lỗi, ví dụ như là một checksum sai trên trang. Đây là lỗi truyền tải.
Mặc dù phần cứng được thiết kế để làm cho đĩa ghi nguyên tử, lỗi vẫn có thể xảy ra. Ví dụ: nếu đĩa bị trục trặc, nó có thể thực hiện một phần thao tác ghi trên trang P. Trong trường hợp đó, thao tác tiếp theo để đọc P có thể phát hiện lỗi, ví dụ như hoạt động tổng kiểm tra lỗi (checksum) trên trang. Đây là một thất bại truyền thông.
Tùy thuộc vào phần cứng, một số lỗi truyền thông có thể không được phát hiện. Ví dụ, hãy xem xét sự cố của đĩa, nơi nó thực hiện hoàn toàn thao tác ghi, nhưng lưu trữ dữ liệu ở vị trí sai. Nghĩa là, một thao tác đã được đưa ra để ghi trang P, nhưng đĩa đã ghi nó đến một vị trí khác, Q. Trong trường hợp này, khi một ứng dụng đọc trang P, giá trị nó đọc có vẻ chính xác. Tuy nhiên, do viết sai trước đây, giá trị của P không phản ánh hoạt động ghi cuối cùng đến P, mà là một phiên bản trước đó. Hơn nữa, lần đọc tiếp theo của trang Q sẽ trả lại giá trị có vẻ chính xác (vì nó phản ánh hoàn toàn thao tác ghi), nhưng nó cũng không chính xác vì nó chứa giá trị cuối cùng được ghi vào trang P chứ không phải trang Q. Lỗi thứ hai có thể được phát hiện nếu checksum trên Q là một hàm của cả địa chỉ của Q và nội dung của nó.
Chúng ta giả định rằng tất cả sự phức tạp này được ẩn giấu bởi phần cứng và phần mềm, hệ thống I/O thực hiện các hoạt động đọc và ghi. Đó là, mỗi thao tác ghi hoặc sẽ ghi đè lên trang dự định hoặc không làm gì cả. Và mỗi thao tác đọc trả về một trang hoàn chỉnh hoặc một lỗi cho biết rằng trang bị hỏng. Các thuật toán phục hồi cho lỗi hệ thống sử dụng rất nhiều thuộc tính này của các đĩa, rằng các hoạt động của trang là nguyên tử. Vì vậy, nếu các giao dịch đọc và ghi các trang hoàn chỉnh, tính nguyên tử của ghi trang cung cấp một mô hình sạch mà chúng ta có thể sử dụng để lý giải về trạng thái của cơ sở dữ liệu sau khi thất bại
Giả sử một trang có thể chứa nhiều bản ghi, giao dịch ghi các bản ghi chứ không phải các trang và trình quản lý dữ liệu sử dụng các khóa cấp độ bản ghi. Trong trường hợp đó, nhiều giao dịch có thể khóa và cập nhật các bản ghi khác nhau trong một trang. Nếu họ làm như vậy, thì tại thời điểm khôi phục, một trang có thể chứa các bản ghi được cập nhật gần đây bởi các giao dịch khác nhau, chỉ một số trong đó đã được cam kết. Tùy thuộc vào trạng thái của trang, một số cập nhật đã cam kết có thể cần được áp dụng lại, trong khi những cập nhật khác cần được hoàn tác. Việc ghi sổ để sắp xếp việc này khá khó khăn. Sự phức tạp này là một vấn đề đáng để giải quyết, nhưng chúng ta sẽ không bàn đến chúng ở đây. Thay vào đó, để giữ cho mọi thứ đơn giản, chúng ta sẽ sử dụng trang chi tiết cho mọi thứ:
- Cơ sở dữ liệu bao gồm một tập hợp các trang.
- Mỗi lần cập nhật bởi một giao dịch chỉ áp dụng cho một trang
- Mỗi bản cập nhật của một giao dịch ghi cả một trang (không chỉ là một phần của trang).
- Khóa được đặt trên các trang.
Mức độ chi tiết của trang đơn giản hóa cuộc thảo luận, nhưng nó không hiệu quả đối với các hệ thống có hiệu năng cao. Sau khi mô tả cách khôi phục bằng cách sử dụng giả định này, chúng ta sẽ chỉ ra điều gì sẽ xảy ra khi cho phép cập nhật chi tiết hơn và khóa trên bản ghi
Mô hình lưu trữ
Mô hình lưu trữ gồm hai khu vực: lưu trữ ổn định (thường là đĩa) và lưu trữ tạm thời (thường là bộ nhớ chính).
 Trình quản lý bộ đệm kiểm soát hoạt động của các trang giữa lưu trữ ổn định (cơ sở dữ liệu ổn định và nhật ký) và lưu trữ tạm thời (bộ đệm - cache).
Trình quản lý bộ đệm kiểm soát hoạt động của các trang giữa lưu trữ ổn định (cơ sở dữ liệu ổn định và nhật ký) và lưu trữ tạm thời (bộ đệm - cache).
Bộ nhớ ổn định chứa cơ sở dữ liệu ổn định, có một bản sao của mỗi trang cơ sở dữ liệu. Nó cũng chứa nhật ký, mà chúng tôi sẽ nói tới sau.
Lưu trữ tạm thời chứa cache cơ sở dữ liệu. Cache chứa các bản sao của một số trang cơ sở dữ liệu, thường là các trang được truy cập hoặc cập nhật gần đây bởi các giao dịch. Sử dụng cache tạo hiệu suất lớn, bởi vì nó giúp các giao dịch bỏ được thời gian truy cập đĩa cho các trang hay dùng.
Để phục hồi, không quan trọng những trang nào trong cache. Các trang trong cache có thể chứa các bản cập nhật chưa được ghi vào bộ nhớ ổn định. Các trang như vậy được gọi là “bẩn”. Xử lý các trang bẩn là một nhiệm vụ quan trọng của hệ thống phục hồi trong quá trình hoạt động thông thường. Trình quản lý bộ nhớ đệm theo dõi nội dung trong cache. Nó là một phần của lớp hệ thống tập tin định hướng trang của một trình quản lý dữ liệu, như thể hiện trong hình  Nó chia cache thành các slot, mỗi slot có thể chứa một trang cơ sở dữ liệu. Nó sử dụng một bảng để chứa các slot. Mỗi hàng của bảng chứa một bộ mô tả cache, xác định trang cơ sở dữ liệu nằm trong cache slot, địa chỉ bộ nhớ chính của cache slot, một bit để biết trang đó có bẩn hay không và một số pin.
Nó chia cache thành các slot, mỗi slot có thể chứa một trang cơ sở dữ liệu. Nó sử dụng một bảng để chứa các slot. Mỗi hàng của bảng chứa một bộ mô tả cache, xác định trang cơ sở dữ liệu nằm trong cache slot, địa chỉ bộ nhớ chính của cache slot, một bit để biết trang đó có bẩn hay không và một số pin. Trình quản lý bộ nhớ đệm hỗ trợ năm thao tác cơ bản:
Trình quản lý bộ nhớ đệm hỗ trợ năm thao tác cơ bản:
- Fetch(P): P là địa chỉ của một trang cơ sở dữ liệu. Đọc P vào một cache slot (nếu nó chưa có) và trả về địa chỉ của cache slot.
- Pin(P): Điều này làm cho cache slot của trang P không khả dụng để flush() (nó được "ghim xuống"). Thông thường, Pin(P) được gọi ngay sau khi tìm nạp (fetching) nó.
- Unpin (P): Giải phóng Pin(P) vừa được gọi. Trình quản lý bộ nhớ đệm duy trì số lượng pin cho mỗi trang, được gia tăng bởi mỗi hoạt động của Pin() và được giảm dần bởi mỗi Unpin. Nếu số pin là 0, trang có thể flush hoặc deallocate.
- Flush (P): Nếu trang cơ sở dữ liệu P nằm trong cache slot và bẩn, thì thao tác này sẽ ghi vào đĩa. Nó không quay trở lại cho đến khi đĩa xác nhận rằng thao tác ghi được thực hiện. Nói cách khách, flush là một sự đồng bộ ghi.
- Deallocates(P): Phân bổ lại P để cache slot của nó có thể được sử dụng lại bởi một trang khác. Không flush trang, ngay cả khi cache slot là bẩn. Tùy thuộc vào ứng dụng, trình quản lý bộ đệm sẽ fush một trang (nếu thích hợp) trước khi deallocate nó.
Mọi thứ khác xảy ra với các trang là tùy thuộc vào các giao dịch. Nếu một giao dịch đã tìm nạp (fetch) và ghim (pin) một trang, nó có thể làm những gì nó muốn với nội dung của trang đó, cho đến khi quản lý bộ nhớ đệm được quan tâm. Tất nhiên, chúng ta biết giao dịch sẽ có một khóa thích hợp để đọc hoặc ghi trang, nhưng một lớp cao hơn trình quản lý bộ đệm, chúng không cần biết về các khóa.
Trình quản lý bộ nhớ đệm được sử dụng nhiều bởi các thành phần quản lý dữ liệu đọc và ghi cơ sở dữ liệu. Đây thường là lớp quản lý bản ghi của trình quản lý dữ liệu (nghĩa là lớp Phương thức truy cập trong như trong hình),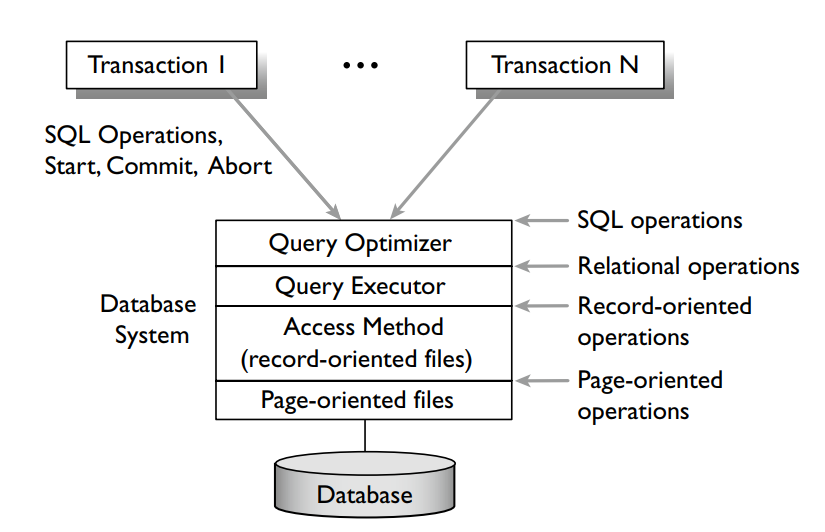 nó đọc, ghi các bản ghi và cung cấp, lập chỉ mục truy cập vào dữ liệu. Để đọc hoặc ghi dữ liệu trên trang P, nó Fetch (P) theo sau là Pin (P). Khi đọc xong hoặc cập nhật trang, nó sẽ gọi Unpin (P). Nó không gọi Flush (P).
nó đọc, ghi các bản ghi và cung cấp, lập chỉ mục truy cập vào dữ liệu. Để đọc hoặc ghi dữ liệu trên trang P, nó Fetch (P) theo sau là Pin (P). Khi đọc xong hoặc cập nhật trang, nó sẽ gọi Unpin (P). Nó không gọi Flush (P).
Có tới hai thành phần quản lý dữ liệu khác để gọi Flush (P). Một là thuật toán thay thế trang của trình quản lý bộ nhớ đệm. Nhiệm vụ của nó là tận dụng tối đa cache bằng cách chỉ lưu giữ những trang mà giao dịch có thể cần trong tương lai gần. Nếu một trang P không được tham chiếu trong một khoảng thời gian, nó sẽ giải phóng P khỏi vị trí trang của nó. Nếu P là bẩn, nó gọi Flush (P) trước Deallocate (P), để các bản cập nhật gần đây cho P không bị mất.
Một thành phần khác sử dụng Flush (P) là trình quản lý khôi phục, được mô tả trong phần tiếp theo.
Nhật ký (log)
 Nhật ký là một tệp tuần tự, thường được lưu trên đĩa, chứa một chuỗi các bản ghi mô tả các bản cập nhật được áp dụng cho cơ sở dữ liệu. Bản ghi mô tả một bản cập nhật bao gồm:
Nhật ký là một tệp tuần tự, thường được lưu trên đĩa, chứa một chuỗi các bản ghi mô tả các bản cập nhật được áp dụng cho cơ sở dữ liệu. Bản ghi mô tả một bản cập nhật bao gồm:
- Địa chỉ của trang đã được cập nhật
- Mã định danh của giao dịch đã thực hiện cập nhật
- Giá trị của trang đã được viết, được gọi là hình ảnh sau của nó
- Giá trị của trang trước khi được viết, được gọi là hình ảnh trước của nó
Như mô tả ở đây, mỗi bản ghi nhật ký dài hơn hai trang, điều này là kém hiệu quả. Giống như các giả định trang khác, chúng ta sẽ làm tối giản nó sau.
Bản ghi nhật ký này được ghi bởi cùng một thành phần ghi vào cache. Đó là, bất cứ khi nào nó cập nhật một trang và trước khi nó bỏ ghim trang đó, nó sẽ ghi một bản ghi nhật ký mô tả bản cập nhật. Bằng cách đó, nhật ký luôn phù hợp với nội dung của cache.
Nhật ký cũng chứa các bản ghi báo cáo khi giao dịch được thực hiện hoặc hủy bỏ. Các bản ghi như vậy chỉ chứa định danh của giao dịch và một dấu hiệu cho biết giao dịch đã cam kết hay bị hủy bỏ.
Điều quan trọng là nhật ký phản ánh chính xác thứ tự các hoạt động xung đột đã được thực hiện. Đó là, nếu một bản cập nhật đi trước và xung đột với một bản cập nhật khác trong nhật ký, thì các bản cập nhật phải thực sự được thực hiện theo thứ tự đó. Lý do là sau một thất bại, hệ thống phục hồi sẽ thực hiện lại một số công việc đã xảy ra trước khi thất bại. Nó sẽ giả định rằng thứ tự của các hoạt động trong nhật ký là thứ tự nó sẽ phát lại công việc. Lưu ý rằng nhật ký không phản ánh chính xác thứ tự của tất cả các bản cập nhật, chỉ những bản ghi xung đột, đó là thứ duy nhất có thứ tự tương đối tạo ra sự khác biệt. Một số hệ thống khai thác sự khác biệt này bằng cách ghi nhật ký các bản cập nhật không xung đột song song trong các “sublogs” và hợp nhất các sublog sau đó, khi xảy ra xung đột.
Khóa cấp trang đảm bảo thứ tự này được thi hành. Nếu khóa cấp chi tiết hơn được sử dụng, thì hai giao dịch có thể cập nhật đồng thời một trang, vì vậy hệ thống cơ sở dữ liệu phải đảm bảo rằng nó cập nhật trang và viết bản ghi nhật ký thay cho một giao dịch trước khi thực hiện hai hành động này thay cho hành động khác. Điều này được thực hiện bằng cách đặt khóa độc quyền ngắn hạn trên trang, được gọi là chốt, điều đó có thể chỉ đơn giản là một chút không gian trong bộ mô tả bộ đệm. Các chốt đánh dấu các hoạt động cập nhật trang và ghi nhật ký cập nhật như trong hình, có được một chốt trên P sẽ đảm bảo rằng thứ tự các bản ghi nhật ký phù hợp với thứ tự cập nhật cho mỗi trang. Chốt đảm bảo rằng nếu một giao dịch khác đang cố gắng thực hiện cùng T, thì các hoạt động cập nhật và nhật ký của nó sẽ đi trước hoặc theo sau các giao dịch T.
Chốt đảm bảo rằng nếu một giao dịch khác đang cố gắng thực hiện cùng T, thì các hoạt động cập nhật và nhật ký của nó sẽ đi trước hoặc theo sau các giao dịch T.
Thiết lập và giải phóng các chốt được thực hiện thường xuyên hơn so với tthiết lập và giải phóng các khóa. Nên nó phải thực hiện rất nhanh. Do đó, trong hầu hết các hệ thống, không có phát hiện bế tắc được thực hiện dựa trên các chốt. Vì vậy, cần rất nhiều sự quan tâm để đảm bảo rằng những bế tắc như vậy không thể xảy ra.
Trong khi hầu hết các hệ thống lưu trữ hình ảnh trước và sau trong cùng một nhật ký, thì một số sử dụng nhật ký riêng biệt. Điều này được thực hiện bởi vì hình ảnh trước không cần thiết sau khi giao dịch được thực hiện và thường không cần thiết cho việc khôi phục. Do đó, chúng có thể bị xóa tương đối nhanh chóng, không giống như hình ảnh sau, cần thiết sau này. Tuy nhiên, điều này cũng có thể dẫn đến việc ghi nhật ký thêm, vì hiện tại có hai bản ghi để xử lý.
Rồi, cơ bản chỉ cần tới đây thôi. Hẹn gặp lại trong các phần tiếp theo.
Tài liệu dịch và tham khảo - The book: 09_Philip A. Bernstein, Eric Newcomer. Principles of Transaction Processing (2nd edition). Morgan Kaufmann, 2009 - Chapter 7: System Recovery
All rights reserved
