System Recovery - Các nguyên nhân cơ bản của các lỗi hệ thống
Bài đăng này đã không được cập nhật trong 7 năm
Mỗi hệ thống phần mềm trên thực tế đều phải chịu một số sự cố không mong muốn, và những sự cố này có thể ảnh hưởng to lớn đến công việc kinh doanh, điều hành, công việc của chính phủ, .... Chính vì vậy, để tồn tại thì các hệ thống phải có khả năng phục hồi sau các thất bại (không hoạt động hoặc hệ thống hoạt động sai, thiếu tin cậy). Ở bài viết này, tôi sẽ nói về các nguyên nhân cơ bản của lỗi hệ thống trước.

Nguyên nhân của các lỗi hệ thống
Một yêu cầu quan trọng đối với hầu hết các hệ thống xử lý giao dịch (TP) là tính có sẵn rất cao hay còn gọi là hệ thống "24/7" (hoặc 24x7) vì chúng chạy 24 giờ mỗi ngày, 7 ngày mỗi tuần. Làm rõ hơn, một hệ thống sẵn có nếu nó chạy đúng và cho kết quả mong đợi. Vì vậy, một hệ thống có sẵn cao là một hệ thống hầu hết thời gian chạy đúng và cho kết quả mong đợi.
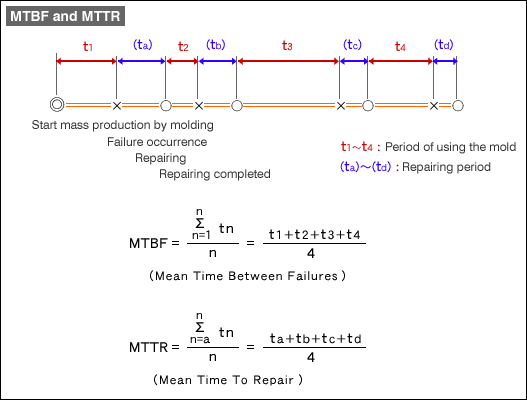
Tính khả dụng của hệ thống bị ảnh hưởng bởi hai yếu tố. Một là tỷ lệ mà hệ thống xử lý không thành công - hệ thống trả lời sai hoặc không trả lời. Nếu hệ thống thường xuyên lỗi, thì tính có sẵn thấp. Yếu tố thứ hai là thời gian phục hồi. Nếu hệ thống cần thời gian để sửa chữa hệ thống sau khi nó gặp lỗi lâu, thì tính sẵn có càng ít. Những khái niệm này được gọi bằng hai thuật ngữ kỹ thuật: thời gian trung bình giữa các lỗi (Mean time between failures - MTBF) và thời gian trung bình để phục hồi (Mean time to repair - MTTR). MTBF là thời gian trung bình mà hệ thống chạy trước khi nó bị thất bại, đây là thước đo độ tin cậy của hệ thống. MTTR là khoảng thời gian để sửa chữa hệ thống sau khi bị thất bại. Sử dụng hai biện pháp này, chúng ta có thể xác định tính sẵn có chính xác = MTBF / (MTBF + MTTR), đó là một phần của thời gian hệ thống chạy. Do đó, tính sẵn có được cải thiện khi thời gian giữa các lỗi (MTBF) tăng và thời gian sửa chữa (MTTR) giảm.
Trong nhiều thiết lập thực tế, hệ thống được thiết kế để đáp ứng một thỏa thuận mức dịch vụ (Service level agreement - SLA), thường là sự kết hợp của tính khả dụng, thời gian đáp ứng và thông lượng. Như vậy hệ thống không phải là luôn sẵn sàng. Nó cũng phải có hiệu suất thỏa đáng. Tất nhiên, hiệu suất kém có thể phát sinh từ nhiều nguồn, chẳng hạn như do hệ thống cơ sở dữ liệu, mạng hoặc hệ điều hành. Các vấn đề về hiệu suất đôi khi là riêng biệt với từng giao dịch. Thường xuyên hơn, chúng là cho các thành phần khác trong công nghệ. Những vấn đề này là rất quan trọng, nhưng vì chúng không cụ thể cho các khía cạnh của hệ thống, nên sẽ không xem xét chúng ở đây. Thay vào đó ta đi sâu về các nguyên nhân sau.
Thất bại xảy ra do nhiều nguồn khác nhau. Chúng ta có thể phân loại chúng như sau: • Môi trường: Ảnh hưởng từ môi trường vật lý bao quanh hệ thống máy tính, chẳng hạn như điện, truyền thông, điều hòa không khí, hỏa hoạn, thiên tai. • Quản lý hệ thống: Những hoạt động để quản lý hệ thống, bao gồm cả các nhà cung cấp bảo trì và các nhà khai thác, vận hành hệ thống. • Phần cứng: Tất cả các thiết bị phần cứng bao gồm bộ xử lý, bộ nhớ, bộ điều khiển I/O, thiết bị lưu trữ, v.v. • Phần mềm: Hệ điều hành, hệ thống truyền thông, hệ thống cơ sở dữ liệu, giao dịch trung gian, phần mềm hệ thống, và phần mềm ứng dụng.
Chúng ta hãy nhìn vào từng loại nguyên nhân và xem chúng ta có thể làm giảm tần suất của chúng như thế nào.
1. Môi trường
Một phần môi trường của các hệ thống không thuộc quyền kiểm soát của người xây dựng hệ thống máy tính, chẳng hạn như truyền thông đường dài được cung cấp bởi một công ty viễn thông. Với một khách hàng của các dịch vụ truyền thông, đôi khi người ta có thể cải thiện bằng cách trả thêm tiền mua các đường dây tốt, đáng tin cậy. Nếu không, họ sẽ thuê nhiều đường truyền thông hơn mức cần thiết để đáp ứng các mục tiêu về chức năng và hiệu suất. Ví dụ, nếu cần một dây truyền thông, họ sẽ thuê hai, nếu một trong hai bị lỗi, đường truyền khác có lẽ sẽ vẫn được hoạt động.

Khía cạnh thứ hai của môi trường là năng lượng. Các doanh nghiệp thường có pin dự phòng cho hệ thống máy tính. Trong trường hợp mất điện, pin ít nhất có thể giữ bộ nhớ chính hoạt động để sao lưu, do đó, hệ thống có thể khởi động lại ngay lập tức sau khi điện được khôi phục mà không cần khởi động lại hệ điều hành, do đó giảm MTTR. Pin có thể chạy hệ thống trong một thời gian ngắn, hoặc để cung cấp dịch vụ hữu ích (tăng MTBF) như để ngủ đông hệ thống tiết kiệm bộ nhớ chính cho một thiết bị lưu trữ liên tục (có thể sẵn sàng phục hồi từ ngủ đông nhanh hơn khởi động lại). Để tiếp tục chạy trong thời gian cúp điện dài hơn, cần một nguồn cung cấp điện liên tục (UPS). Một UPS đầy đủ bao gồm một máy phát điện chạy bằng khí hoặc dầu diesel, có thể chạy hệ thống lâu hơn nhiều so với pin. Pin vẫn được sử dụng để giữ cho hệ thống chạy với một vài phút cho đến khi máy phát điện có thể thay thế.
Vấn đề môi trường thứ ba là điều hòa không khí. Khi một hệ thống máy tính làm việc sẽ sinh ra nhiều nhiệt và yêu cầu một môi trường không khí khô. Vì vậy cần có một hệ thống điều hòa không khí.
Các hệ thống có thể bị thất bại do thiên tai, chẳng hạn như lửa, lũ lụt, và động đất, hoặc do các bất thường khác bên ngoài, chẳng hạn như chiến tranh và phá hoại. Có những điều bạn có thể làm để bảo vệ chống lại một số sự kiện này: xây dựng các công trình ít bị ô nhiễm hơn, chịu được các tác động từ bên ngoài, có thể chịu được động đất mạnh và được bảo vệ chống lại xâm nhập trái phép. Mức độ nào thì phụ thuộc vào chi phí phòng vệ, lợi ích sẵn có, và chi phí thời gian chết cho doanh nghiệp khi gặp sự cố. Khi hệ thống thực hiện "nhiệm vụ quan trọng", như trong một số quân đội, tài chính, và các ứng dụng vận chuyển, một doanh nghiệp sẽ bảo vệ hệ thống đến độ phi thường để giảm xác suất những lỗi như vậy. Như một hệ thống hàng không nằm trong một hầm ngầm.
Bước tiếp theo là nhân bản hệ thống, lý tưởng là đặt hệ thống ở một vị trí địa lý xa xôi mà các thảm hoạ môi trường không thể tác động tới các bản sao khác. Ví dụ, nhiều năm trước một ngân hàng ở California đã xây dựng thêm một cơ sở máy tính ở phía đông San Andreas Fault, vì vậy họ có thể vẫn hoạt động nếu cơ sở Los Angeles hoặc San Francisco của họ bị phá hủy bởi một trận động đất. Gần đây, nhân bản hệ thống đã trở thành thực tiễn phổ biến cho các trang web quy mô lớn. Vì một bản sao hệ thống rất hữu ích khi nó có dữ liệu cần thiết để tiến hành xử lý cho một hệ thống bị thất bại. Vì vậy việc sao chép dữ liệu là một điều quan trọng trong công nghệ.
2. Quản lý hệ thống
Mọi người đều là một phần của hệ thống. Họ đều có một ngày nghỉ hoặc thỉnh thoảng mất chú ý, ngay cả các nhà điều hành hệ thống tốt nhất nào đó. Đó là nguyên nhân để hệ thống thất bại.

Có một số cách để giảm thiểu vấn đề. Một là chỉ đơn giản để thiết kế hệ thống để nó không đòi hỏi phải bảo trì nhiều, chẳng hạn như sử dụng thủ tục tự động cho các chức năng mà thông thường sẽ yêu cầu nhà điều hành can thiệp. Ngay cả việc nâng cấp được thực hiện để tăng tính sẵn có bằng cách tránh sự cố sau đó cũng là một nguồn gây ra thời gian chết. Các thủ tục như vậy cần được thiết kế để thực hiện ngay cả khi hệ thống vẫn hoạt động.
Đơn giản hoá các thủ tục bảo trì cũng giúp cải thiện tính sẵn có nếu không thể loại bỏ hoàn toàn việc bảo trì. Vì vậy, không xây dựng dư thừa vào các thủ tục bảo trì.
Đào tạo là một yếu tố khác. Một nhà điều hành phải thực hiện ít nhất hai lỗi để làm cho hệ thống gặp sự cố (Recovery Testing). Điều này đặc biệt quan trọng đối với các quy trình bảo trì cần thiết không thường xuyên. Nó giống như có một cuộc tập trận lửa, nơi mà mọi người tập luyện cho các sự kiện hiếm hoi, vì vậy khi các sự kiện xảy ra, mọi người biết cần làm gì.
Việc cài đặt phần mềm thường là một nguồn làm hệ thống thất bại vì việc cài đặt nhiều phần mềm yêu cầu khởi động lại hệ điều hành. Phát triển các thủ tục cài đặt mà không yêu cầu khởi động lại là một cách để nâng cao hiệu năng của hệ thống.
Nhiều lỗi hoạt động liên quan đến việc cấu hình lại hệ thống. Đôi khi thêm máy mới vào hệ thống hoặc thay đổi các thông số trên một hệ thống cơ sở dữ liệu làm cho hệ thống bị trục trặc. Ngay cả khi nó chỉ làm giảm hiệu suất, thay vì làm hệ thống sụp đổ, hiệu quả có thể được phản ánh ngay từ quan điểm của người dùng cuối. Người ta có thể tránh những bất ngờ khó chịu bằng cách sử dụng các công cụ quản lý cấu hình để mô phỏng một cấu hình mới và chứng minh rằng nó sẽ hoạt động như dự đoán, hoặc có các thủ tục kiểm tra trên một hệ thống kiểm tra có thể chứng minh rằng một cấu hình thay đổi sẽ thực hiện như dự đoán. Hơn nữa, rất cần có các thủ tục tái cấu trúc để khi một sai lầm được thực hiện, người ta có thể trở lại cấu hình làm việc trước nhanh chóng.
Nếu hệ thống không bắt buộc phải là 24x7, thì thời gian chết có thể được sử dụng để xử lý nhiều các vấn đề, chẳng hạn như bảo trì, nâng cấp, cài đặt phần mềm yêu cầu khởi động lại, hoặc cấu hình lại một hệ thống. Tuy nhiên, theo quan điểm của nhà cung cấp, việc cung cấp các sản phẩm đòi hỏi thời gian chết như vậy sẽ hạn chế thị trường.
3. Phần cứng
Nguyên nhân thứ ba của sự thất bại là vấn đề phần cứng. Một lỗi phần cứng có thể là tạm thời hoặc vĩnh viễn.
Phần lớn các lỗi phần cứng là lỗi tạm thời. Nếu hành động không thành công, chỉ cần thử lại hoạt động thì có thể nó sẽ thành công. Vì lý do này, các hệ điều hành có sẵn nhiều thủ tục khôi phục sẵn để xử lý lỗi phần cứng tạm thời. Ví dụ, nếu hệ điều hành thực hiện một hoạt động I/O vào đĩa hoặc một thiết bị truyền thông và nhận được tín hiệu báo lỗi trở lại, nó thường thử lại thao tác đó nhiều lần trước khi nó thực sự báo lỗi cho người gọi.
Một số lỗi phần cứng là vĩnh viễn. Những lỗi nghiêm trọng nhất khiến hệ điều hành bị lỗi, làm cho toàn bộ hệ thống không thể hoạt động. Trong trường hợp này, khởi động lại hệ điều hành có thể khiến hệ thống trở lại bình thường. Thủ tục khởi động lại sẽ phát hiện phần cứng hoạt động sai và cố gắng cấu hình lại nó. Nếu khởi động lại không thành công hoặc hệ thống không thành công ngay sau khi khởi động lại, thì bước tiếp theo thường là sao lưu đĩa bằng một phần mềm, trong trường hợp nó bị hỏng. Rồi sửa chữa hoặc thay thế phần cứng.

4. Phần mềm
Lỗi phần mềm là một nguyên nhân làm hệ thống thất bại. Loại lỗi nghiêm trọng nhất là làm kéo theo lỗi hệ điều hành, vì nó dừng lại toàn bộ hệ thống máy tính. Vì nhiều vấn đề phần mềm là tạm thời, nên khởi động lại máy là cách thường xuyên để giải quyết vấn đề. Điều này bao gồm việc khởi động lại hệ điều hành, chạy phần mềm sửa chữa trạng thái đĩa do nó có thể đã trở nên không nhất quán vì sự thất bại, phục hồi các phiên truyền thông với các hệ thống khác trong một phân phối hệ thống, và khởi động lại tất cả các chương trình ứng dụng. Các bước này làm tăng MTTR và do đó giảm tính khả dụng. Vì vậy, chúng nên được thực hiện càng nhanh càng tốt. Một số hệ điều hành được thiết kế cẩn thận để khởi động nhanh. Ví dụ, các hệ thống truyền thông có tính có sẵn rất cao có hệ điều hành khởi động lại dưới một phút.
Một số lỗi phần mềm làm suy giảm khả năng của hệ thống nhưng không làm hỏng hệ thống. Ví dụ, một ứng dụng cung cấp các chức năng cần truy cập vào một dịch vụ từ xa. Khi dịch vụ từ xa không có sẵn, những chức năng này ngừng làm việc. Tuy nhiên, nếu thiết kế ứng dụng tốt, chức năng các ứng dụng khác vẫn có thể hoạt động. Tức là, hệ thống sẽ giảm hiệu năng xuống một cách từ từ, dần dần khi các bộ phận của nó ngừng hoạt động. Một ví dụ thực chúng ta biết là một ứng dụng sử dụng một cơ sở dữ liệu giao dịch và một kho dữ liệu, nơi mà sau này rất cần nhưng không phải là nhiệm vụ quan trọng ngay. Nếu ứng dụng không được thiết kế để giảm hoạt động một cách từ từ, thì khi kho dữ liệu không thành công, toàn bộ ứng dụng trở nên không khả dụng, sẽ gây ra sự mất mát doanh thu lớn và không cần thiết.
Khi hoạt động ứng dụng hoặc hệ thống cơ sở dữ liệu thất bại, sự cố phải được phát hiện và khắc phục hoặc hoạt động hệ thống cơ sở dữ liệu phải được phục hồi. Đây là nơi cần kỹ thuật, công nghệ cụ thể có liên quan.
Các hậu quả của sự thất bại là rất lớn. Một doanh nghiệp có thể bị ảnh hưởng về tài chính, thương hiệu của họ có thể bị hư hỏng hoặc có thể xảy ra vi phạm về an ninh. Những rủi ro này luôn ở đó, bởi vì mỗi hệ thống đều bị thất bại. Không có công ty, sản phẩm hoặc phần mềm nào miễn nhiễm với "phá vỡ". Mức độ phục hồi thường xuyên được kiểm tra trực tiếp như thế nào khi chuẩn bị tổ chức cho thiên tai.
Ở bài biết tiếp theo mình sẽ giới thiệu một số mô hình phục hồi hệ thống với các bạn.
Tài liệu dịch và tham khảo - The book: 09_Philip A. Bernstein, Eric Newcomer. Principles of Transaction Processing (2nd edition). Morgan Kaufmann, 2009 - Chapter 7: System Recovery (trang 185-222).
All rights reserved
