System Recovery - Một số mô hình phục hồi hệ thống
Bài đăng này đã không được cập nhật trong 7 năm
Mỗi hệ thống phần mềm trên thực tế đều phải chịu một số sự cố không mong muốn, và những sự cố này có thể ảnh hưởng to lớn đến công việc kinh doanh, điều hành, công việc của chính phủ, .... Chính vì vậy, để tồn tại thì các hệ thống phải có khả năng phục hồi sau các thất bại (không hoạt động hoặc hệ thống hoạt động sai, thiếu tin cậy). Ở bài viết trước, tôi đã nói về các nguyên nhân cơ bản của lỗi hệ thống. Trong phần này, chúng ta sẽ thảo luận làm thế nào để đối phó với sự thất bại và phục hồi hệ thống. Chúng ta sẽ xem xét sự thất bại và phục hồi các hệ thống quản lý tài nguyên, đặc biệt là các hệ thống cơ sở dữ liệu sau.
Một số mô hình phục hồi hệ thống
1 Phát hiện tiến trình thất bại
Các tiến trình hệ điều hành là tách biệt với các tiến trình của ứng dụng. Nên một tiến trình của ứng dụng thất bại thì hệ điều hành vẫn có thể tiếp tục, vì vậy chỉ cần khởi động lại tiến trình hoạt động của ứng dụng. Điều này làm giảm MTTR so với một hệ thống mà sự thất bại ứng dụng cần khởi động lại hệ điều hành. Vì vậy, hầu hết các hệ thống TP được xây dựng nhiều tiến trình.
Khi có hoạt động thất bại, phải có một số tiến trình ngoài quan sát thực tế đó và yêu cầu tạo lại hoạt động bị thất bại. Thông thường đó được thực hiện bởi hệ điều hành, hệ thống cơ sở dữ liệu, hoặc trung gian giao dịch. Các trung gian giao dịch hoặc hệ thống cơ sở dữ liệu thường có một hoặc nhiều quá trình giám sát theo dõi khi quá trình ứng dụng hoặc cơ sở dữ liệu thất bại. Có một số cách thường được sử dụng để phát hiện lỗi:
- Mỗi tiến trình có thể định kỳ gửi thông điệp "I’m alive" tới trình giám sát (xem hình 1); sự vắng mặt của một thông báo như vậy cảnh báo cảnh trình giám sát của một thất bại có thể.
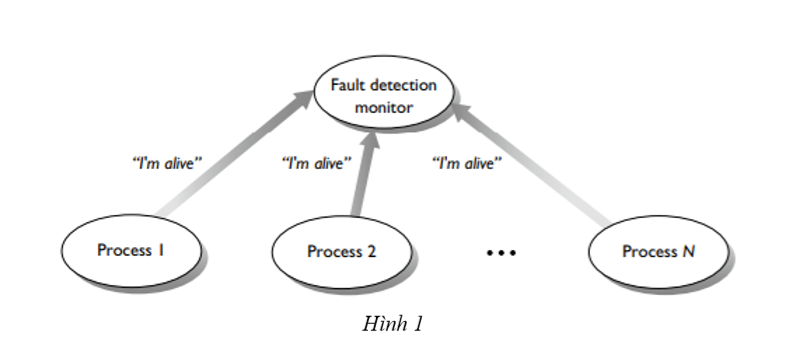
- Trình giám sát có thể thăm dò các quá trình khác bằng các tin nhắn "Are you alive?"
- Mỗi tiến trình có thể sở hữu một khóa hệ điều hành; nếu tiến trình không thành công, hệ điều hành sẽ giải phóng khóa của tiến trình, cung cấp cho trình giám sát, tiến trình giám sát sẽ đưa ra thông báo về tiến trình thất bại.
Cho dù cách tiếp cận nào được thực hiện, điều quan trọng là phải tối ưu hóa thời gian để tiến trình giám sát phát hiện sự thất bại, vì thời gian đó góp phần vào MTTR. Trong tất cả các trường hợp này, triệu chứng cung cấp một lý do chính đáng để nghi ngờ rằng quá trình thất bại, nhưng nó không phải là bảo đảm rằng quá trình thực sự đã thất bại. Trong hai trường hợp đầu tiên, quá trình này chỉ có thể chỉ đáp ứng chậm. Trong trường hợp thứ ba, hệ điều hành có thể phát hành các khóa của tiến trình vẫn còn hoạt động. Sự nghi ngờ về sự thất bại có nhiều khả năng đúng nếu máy dò được thực hiện trên cùng một hệ điều hành như tiến trình đang được giám sát. Trong chương này ta giả định rằng tất cả các phát hiện thất bại đều là chính xác.
Trong một hệ thống phân phối mà tiến trình giám sát chạy trên một máy khác với máy có tiến trình đang được theo dõi, rất có thể việc phát hiện thất bại là do một sự thất bại truyền thông chứ không phải là một tiến trình thất bại.
Một quá trình có thể thất bại bằng cách trả lại các giá trị không chính xác. Đó có thể do việc không đáp ứng được các đặc điểm kỹ thuật của hệ thống. Cho ví dụ, dữ liệu mà nó trả về có thể đã bị hỏng do bộ nhớ bị lỗi, đường truyền bị lỗi hoặc lỗi ứng dụng. Chúng ta không xem xét các lỗi như vậy ở đây.
Khi một tiến trình thất bại được phát hiện, các tiến trình quản lý phải tạo lại tiến trình thất bại. Hệ điều hành thường được thiết kế chỉ để tạo lại các tiến trình cần thiết để giữ cho nó hoạt động. Nó thường không tự động tạo lại các tiến trình ứng dụng. Do đó, trung gian giao dịch và các hệ thống cơ sở dữ liệu phải tham gia để phát hiện sự thất bại của ứng dụng và các tiến trình của hệ thống cơ sở dữ liệu, khi chúng không thành công sẽ tạo lại chúng.
2 Client Recovery – Phục hồi máy khách
Trong phần này, giả sử mô hình hệ thống là mô hình client-server cơ bản: một tiến trình client liên lạc với một tiến trình máy chủ và máy chủ sử dụng các tài nguyên cơ bản, chẳng hạn như đĩa hoặc đường truyền thông.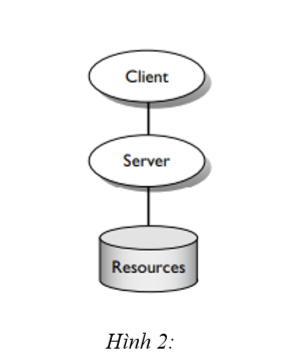
Có một số điểm có thể thất bại trong hệ thống này: máy khách, kết nối client-server, máy chủ, kết nối máy chủ và tài nguyên. Nếu client thất bại và sau đó phục hồi, nó cần phải kết nối lại với máy chủ và có thể bắt đầu gọi lại. Hoặc, nếu khách hàng mất liên lạc với máy chủ, hoặc vì đường truyền hoặc máy chủ không thành công, lỗi cuối cùng sẽ được sửa chữa và khách hàng sau đó sẽ thiết lập lại việc liên lạc và tiếp tục gọi máy chủ. Trong cả hai trường hợp, vấn đề chính cho client là để thiết lập lại trạng thái của nó liên quan đến máy chủ.
Trạng thái của máy khách liên quan đến máy chủ bao gồm các thiết lập các cuộc gọi của nó đến máy chủ. Vì thế, để phục hồi trạng thái của nó, cần phải xác định những điều sau:
- Các cuộc gọi nào đã xảy ra ở thời điểm nó bị lỗi hoặc bị mất kết nối với máy chủ?
- Điều gì đã xảy ra với những cuộc gọi đó trong khi nó đang tạm dừng hoặc không giao tiếp với máy chủ?
- Cần phải làm gì để hoàn thành các cuộc gọi đó trước khi thực hiện các cuộc gọi mới?
Đây là những vấn đề "Xử lý hàng đợi giao dịch". Nếu có hàng đợi liên tục giữa client và server, sau đó client có thể tìm ra trạng thái của tất cả các cuộc gọi bằng cách kiểm tra hàng đợi. Nếu không, thì nó phải sử dụng kỹ thuật cụ thể, chẳng hạn như nhìn vào trạng thái cơ sở dữ liệu trên máy chủ để xác định xem các cuộc gọi trước của máy khách đã hoàn thành hay cấp lại cuộc gọi với cùng một số sê-ri và dựa vào máy chủ để loại bỏ các cuộc gọi trùng lặp.
Các vấn đề còn lại tập trung vào sự sẵn có của máy chủ, đây là chủ đề của phần còn lại trong phần này.
3 Server Recovery – Phục hồi máy chủ
Sau khi máy chủ hoạt động trở lại, nó sẽ chạy thủ tục phục hồi để tái tạo lại trạng thái của nó trước khi bắt đầu các cuộc gọi mới. Nếu máy chủ mới được tạo và chạy lần đầu tiên, thì thủ tục khôi phục là không đáng kể, máy chủ chỉ cần khởi tạo trạng thái của nó.
Để tìm hiểu làm thế nào một máy chủ tái tạo lại trạng thái của nó, hãy bắt đầu từ nguyên tắc đầu tiên. Giả sử máy chủ là một trình tự xử lý các cuộc gọi và không có giao dịch ở đây Máy chủ chỉ nhận cuộc gọi từ máy khách, làm những gì được yêu cầu, và trả về một kết quả. Vào thời điểm thất bại, máy chủ có thể đang trong tiến trình xử lý một cuộc gọi như vậy.
Có thể xảy ra sự cố máy chủ (hoặc thông tin liên lạc) gây ra cuộc gọi bị mất, vì vậy nó phụ thuộc vào máy khách để xác định tình trạng của các cuộc gọi. Như chúng ta đã thảo luận trong phần trước về Phục hồi máy khách.
Thật không may, điều này không luôn luôn làm việc, bởi vì máy chủ có thể đã thực hiện một hoạt động non-idempotent trong khi nó đang xử lý cuộc gọi cuối cùng trước khi gặp sự cố. Ví dụ: đã chuyển tiền, ghi thay đổi vào tài khoản ngân hàng, rút tiền mặt, hoặc vận chuyển một sản phẩm. Nhưng client lại cho rằng máy chủ đã không thực hiện cuộc gọi, nó sẽ phát hành lại cuộc gọi để máy chủ làm lại công việc. Vì vậy, để hoạt động đúng thì máy chủ không được thực hiện lại cuộc gọi, thay vào đó, nó phải hoàn thành cuộc gọi và trả lại kết quả.
Các chi tiết của việc phục hồi cuộc gọi đã thực hiện một phần rất phức tạp và thường không được sử dụng trong các hệ thống hỗ trợ giao dịch. Tuy nhiên, mọi thứ sẽ rõ ràng và dễ dàng hơn nhiều khi giao dịch có sẵn. chúng ta hãy tìm hiểu xem máy chủ sẽ phải làm gì nếu nó không thể dựa vào các giao dịch.
4 Checkpoint-Based Recovery - Phục hồi dựa trên Checkpoint
Giả sử máy chủ thực hiện một cuộc gọi của máy khách và sau đó không thành công, các hoạt động mà máy chủ thực hiện được một phần là idempotent. Trong trường hợp đó, khi phục hồi, máy chủ có thể đơn giản xử lý lại cuộc gọi lại từ đầu. Thực hiện lại các hoạt động mà nó thực hiện trước khi thất bại không có hại, bởi vì tất cả những hoạt động đó là idempotent.
Giả sử máy chủ đã thực hiện các hoạt động non-idempotent cho cuộc gọi cuối cùng. Máy chủ phải khôi phục đến trạng thái sau lần thực hiện hoạt động non-idempotent cuối cùng trước khi thất bại. Ví dụ, nếu máy chủ in một séc trước khi thất bại, sau đó nó phải được phục hồi đến trạng thái sau khi nó in séc. Nếu máy chủ tiếp tục ở trạng thái trước khi nó in séc thì nó sẽ lặp lại hoạt động đó (nghĩa là in lại séc), đó là những gì không nên xảy ra. Để tái tạo lại trạng thái này đòi hỏi làm sổ sách kế toán, ghi chép hoạt động một cách cẩn thận trước khi thất bại, máy chủ phục hồi có thể dựa vào đó tra cứu những gì đã xảy ra vào thời điểm thất bại, tìm ra những gì nó nên làm.
Một cách tổng quát, để chuẩn bị cho loại phục hồi này cần lưu trạng thái bộ nhớ của nó trên bộ nhớ ngoài (ví dụ: đĩa) trước khi thực hiện thao tác non-idempotent. Bằng cách đó, khi khôi phục, máy chủ có thể khôi phục lại trạng thái (hình 3). Nhìn chung, checkpointing là bất kỳ hoạt động nào được thực hiện trong quá trình xử lý thông thường để giảm số lượng công việc phải làm lại sau khi khôi phục. Tiết kiệm RAM cảu hệ điều hành là một loại checkpointing, bởi vì nó đảm bảo rằng khi máy chủ phục hồi, nó sẽ không phải làm lại bất kỳ công việc nào mà nó đã làm trước khi thực hiện việc tiết kiệm RAM của nó.
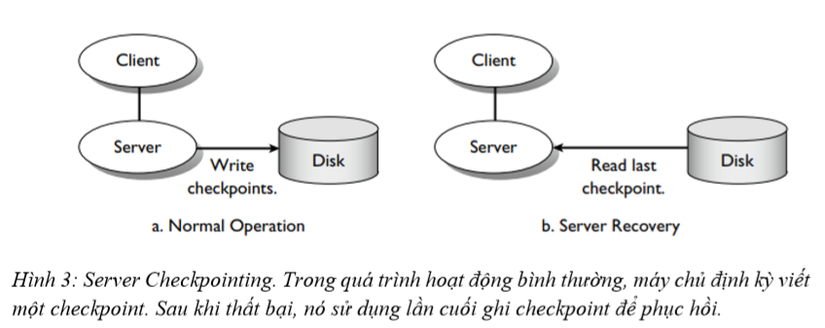
Tiết kiệm bộ nhớ máy chủ không phải là giá rẻ, đặc biệt nếu nó phải được thực hiện mỗi lần một nonidempotent hoạt động được thực hiện. Như chúng ta sẽ thấy trong giây lát, các giao dịch giúp giảm chi phí này. Để khôi phục lại sau khi thất bại, máy chủ khôi phục trạng thái kiểm tra cuối cùng đã lưu thành công (xem Hình 4). Sau đó phải kiểm tra xem hoạt động không idempotent sau điểm kiểm tra cuối cùng của nó thực sự chạy. Ví dụ: nếu máy chủ kiểm tra trạng thái của nó ngay trước khi in một kiểm tra, sau đó tại thời gian khôi phục phục hồi lại máy chủ yêu cầu xác định xem séc có được in hay không. Do đó, khi máy chủ phục hồi, nó phải xác định xem hoạt động nonidempotent đã chạy, và nếu như vậy nó có thể bỏ qua nó.

5 Transaction-Based Server Recovery - Phục hồi máy chủ dựa trên giao dịch
Giao dịch đơn giản hóa việc phục hồi máy chủ bằng cách tập trung sự chú ý của máy khách và máy chủ vào các giao dịch đã thực hiện bởi mỗi máy chủ, thay vì các cuộc gọi riêng lẻ trong một giao dịch. Máy khách nói với máy chủ để bắt đầu một giao dịch, sau đó thực hiện một số cuộc gọi đến máy chủ bên trong giao dịch đó, rồi nói với máy chủ thực hiện giao dịch.
Nếu một máy chủ hỗ trợ giao dịch thất bại và sau đó hồi phục, trạng thái của nó bao gồm ảnh hưởng của tất cả các giao dịch đã hoàn thành trước khi thất bại và không có ảnh hưởng của các giao dịch bị hủy bỏ khi đã hoạt động vào thời điểm thất bại. Việc này giống như máy chủ thực hiện một checkpoint mỗi khi nó hoàn thành một giao dịch, và thủ tục phục hồi loại bỏ tất cả các ảnh hưởng của các giao dịch bị hủy bỏ hoặc không đầy đủ. Khi phục hồi một máy chủ giao dịch, nó sẽ bỏ qua các cuộc gọi đã được thực hiện khi thất bại và tập trung vào các giao dịch được thực hiện khi nó thất bại.
Để làm được điều này, máy chủ phải có thể hoàn tác tất cả các hoạt động của giao dịch khi nó bị hủy bỏ. Điều này làm cho các hoạt động trong giao dịch thực hiện lại được. Nghĩa là, nếu một hoạt động đã được hoàn tác sẽ không có hại gì trong việc thực hiện lại nó sau này, ngay cả khi nó không phải là idempotent. Điều này tránh được một vấn đề đã xảy ra khi phục hồi dựa trên checkpoints - vấn đề quay trở lại trạng thái sau lần thực hiện nonidempotent cuối cùng.
Nếu tất cả các hoạt động trong một giao dịch phải được thực hiện lại, thì giao dịch không được bao gồm các non-idempotent - các thao tác mà chúng ta gặp trong phần trước (Phục hồi Máy chủ) chẳng hạn như in một séc hoặc chuyển tiền bạc. Để đối phó với một hoạt động non-idempotent, giao dịch nên thêm một tin nhắn có chứa các hoạt động.
6 Stateless Servers – Máy chủ phi trạng thái
Khi giao dịch được sử dụng, máy chủ thường được chia thành hai loại: xử lý các tiến trình ứng dụng và quản lý tài nguyên (hình 5). Một Application Process nhận yêu cầu từ máy khách, bắt đầu giao dịch, thực hiện các logic ứng dụng, và gửi thông báo đến trình quản lý tài nguyên giao dịch. Nó không trực tiếp truy cập các tài nguyên giao dịch, chẳng hạn như một cơ sở dữ liệu. Trình quản lý tài nguyên xử lý trạng thái được chia sẻ bằng giao dịch - cơ sở dữ liệu, hàng đợi thu hồi lại được, vân vân.
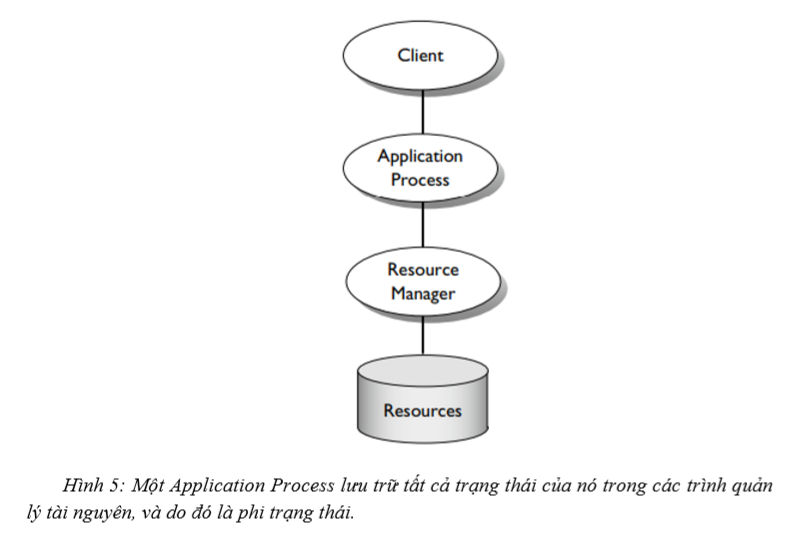
Trình quản lý tài nguyên hoạt động giống như một máy chủ giao dịch được mô tả trong phần trước (Transaction-Based Server Recovery). Tức là, nó thực hiện tất cả các cuộc gọi trong một giao dịch. Và thủ tục phục hồi của nó trả về trạng thái bao gồm tác động của tất cả các giao dịch đã thành công.
Một máy chủ xử lý tiến trình ứng dụng có thể sử dụng một thủ tục khôi phục đơn giản hơn so với các trình quản lý tài nguyên, bởi vì nó là phi trạng thái. Nghĩa là, nó không có bất kỳ trạng thái nào là cần thiết sau khi phục hồi. Nó nhận được một yêu cầu để chạy một giao dịch, bắt đầu giao dịch, thực hiện các thao tác với bộ nhớ cục bộ hoặc gọi một hệ thống cơ sở dữ liệu hoặc tiến trình ứng dụng khác, hoàn thành giao dịch và gửi kết quả lại cho máy khách. Tại đây, nó không có trạng thái nào đáng ghi nhớ. Nó đơn giản xử lý yêu cầu tiếp theo mà nó nhận được như thể nó được khởi tạo từ đầu.
Một máy chủ phi trạng thái không phải làm nhiều việc để phục hồi từ một thất bại. Nó chỉ cần khởi động lại và bắt đầu chạy lại giao dịch, hoàn toàn quên mất bất cứ điều gì nó đã làm trước khi thất bại. Vì nó duy trì tất cả trạng thái của nó trong trình quản lý tài nguyên giao dịch, các trình quản lý tài nguyên phải phục hồi lại trạng thái của chúng sau khi thất bại. Các trình quản lý tài nguyên phục hồi đến một trạng thái bao gồm tất cả các giao dịch hoàn thành và không có những giao dịch bị hủy bỏ đến thời điểm thất bại. Bây giờ tiến trình ứng dụng có thể bắt đầu xử lý các yêu cầu một lần nữa.
Các Application Process được điều khiển bởi trung gian giao dịch thường được thiết kế là các máy chủ phi trạng thái do đó chúng không cần bất kỳ mã khôi phục nào. Sự mơ hồ duy nhất là về trạng thái của yêu cầu cuối cùng mà một máy khách đã gọi trước khi thất bại. Nghĩa là, máy khách không phải là trạng thái, nó cần biết trạng thái của yêu cầu cuối cùng đó. Đây là nơi xếp hàng đợi yêu cầu xử lý được tiếp nhận - để tìm ra trạng thái của yêu cầu cuối cùng, từ đó xác định xem nó có để được chạy lại. Đối với Application Process đã được thực sự thực hiện yêu cầu, không có sự mơ hồ nào cả. Nó khởi động lại ở trạng thái sạch, như thể được khởi tạo lần đầu tiên.
Tài liệu dịch và tham khảo - The book: 09_Philip A. Bernstein, Eric Newcomer. Principles of Transaction Processing (2nd edition). Morgan Kaufmann, 2009 - Chapter 7: System Recovery
All rights reserved
