Sự khác nhau giữa Key-value stores (S3, redis, dynamodb) vs Document databases (mongodb)
Bài đăng này đã không được cập nhật trong 2 năm
Hôm trước mình bất ngờ gặp được câu hỏi từ một a.e DEV "DynamoDB thuộc Key-value stores hở, tưởng giống Document databases như mongodb ?". Cũng hơi giật mình phân vân, nên mò mẫn tìm hiểu được 1 chút, share để mọi người được nắm rõ hơn 😁
Document databases
Database sử dụng cấu trúc này : MongoDB
Hẵn đây là database được khá nhiều bạn biết tới và có sử dụng, ẩn sau là cấu trúc collection and document , được lưu dưới dạng json, với mỗi document có khả năng chứa một tập hợp các cặp key-value.
Cấu trúc database này có những đặc điểm chính sau:

- Model: Dữ liệu được lưu trữ trong các documents (khác với các cơ sở dữ liệu khác lưu trữ dữ liệu trong các cấu trúc như tables hoặc graphs). Documents tương ứng với các object trong hầu hết các ngôn ngữ lập trình phổ biến, cho phép các nhà phát triển phát triển ứng dụng của họ một cách nhanh chóng.
- Flexible schema: Document databases có flexible schema, không phải mọi document trong collection có cùng số field. Nhận thấy một số document databases hỗ trợ schema validation
- Distributed and resilient: Document databases hỗ trợ việc phân phối theo chiều rộng (distribute data nhiều node), điều này cho phép horizontal scaling (cấp phát và phân phối server sẽ rẻ hơn vertical scaling) and data distribution. Document databases provide resiliency through replication.
Key-value stores
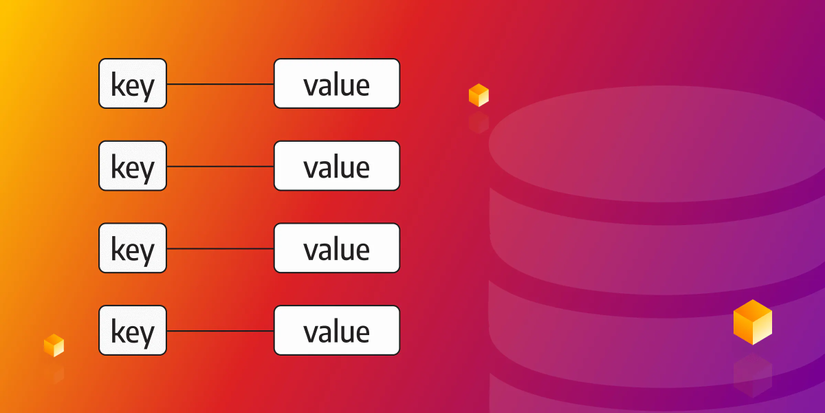
Một key-value database là một loại cơ sở dữ liệu phi quan hệ, NoSQL sử dụng phương pháp key-value đơn giản để lưu trữ dữ liệu. Các cơ sở dữ liệu key-value có thể phân vùng cao (partitionable) và cho phép mở rộng theo chiều ngang (horizontal scaling) ở một cấp độ mà các loại cơ sở dữ liệu khác không thể đạt được.
Horizontal scaling bằng key:
Loại cơ sở dữ liệu NoSQL này thực thi một bảng băm (hash table) để lưu trữ các key cùng với các con trỏ đến các giá trị dữ liệu tương ứng.
Hàm băm (hash function) sẽ có cấu trúc đơn giản như sau:
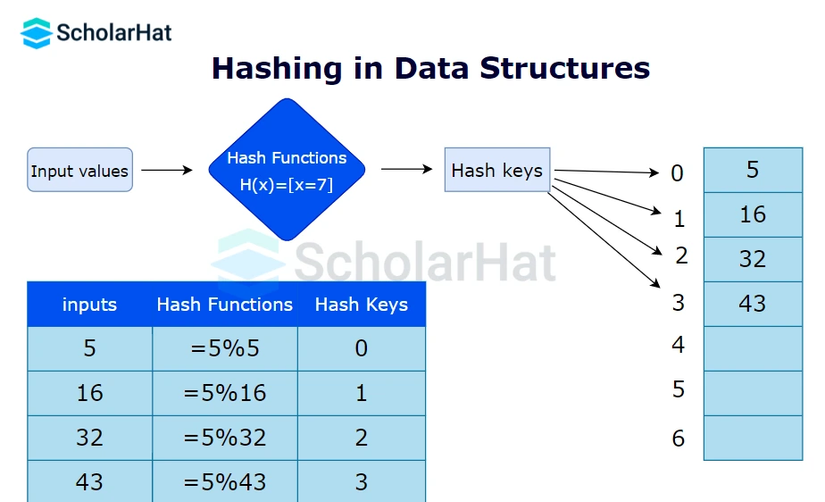
💡 Hash Function:
h(key) -> location
Với một khóa cho trước, hàm băm h tính toán vị trí trong cấu trúc dữ liệu nơi giá trị tương ứng được lưu trữ. Quá trình này thường có độ phức tạp là O(1).
def search_in_kvs(kvs, key):
location = h(key)
return kvs[location]
Ordered Key-Value Store
Cấu trúc lưu trữ (OKVS) sẽ giữ các cặp key-value được sắp xếp theo một thứ tự của key.
Thông thường, OKVS có một lược đồ cố định (fixed schema) cho các khóa nhưng có thể có các giá trị linh hoạt. Việc sắp xếp các khóa cung cấp cấu trúc và cho phép truy vấn phạm vi (range queries) hiệu quả.
Hàm băm (hash function)
Binary Search Algorithm
Với dữ liệu được sắp xếp, một thuật toán tìm kiếm nhị phân có thể được sử dụng để tìm vị trí của khóa trong cấu trúc dữ liệu. Thuật toán tìm kiếm nhị phân hoạt động bằng cách chia nhỏ đoạn tìm kiếm thành hai đợt cho đến khi khóa được tìm thấy hoặc đoạn tìm kiếm trở thành trống.
def binary_search(okvs, key):
left = 0
right = len(okvs) - 1
while left <= right:
mid = (left + right) // 2
if okvs[mid].key == key:
return okvs[mid].value
elif okvs[mid].key < key:
left = mid + 1
else:
right = mid - 1
return None
Ở đây, thuật toán tìm kiếm nhị phân có độ phức tạp thời gian là O(log n), trong đó n là số lượng phần tử trong OKVS. Vì dữ liệu được sắp xếp dựa trên các khóa, thuật toán này hiệu quả trong việc tìm kiếm khóa mong muốn hoặc xác định sự vắng mặt của nó.
Tổng kết sự khác nhau của 3 cấu trúc này
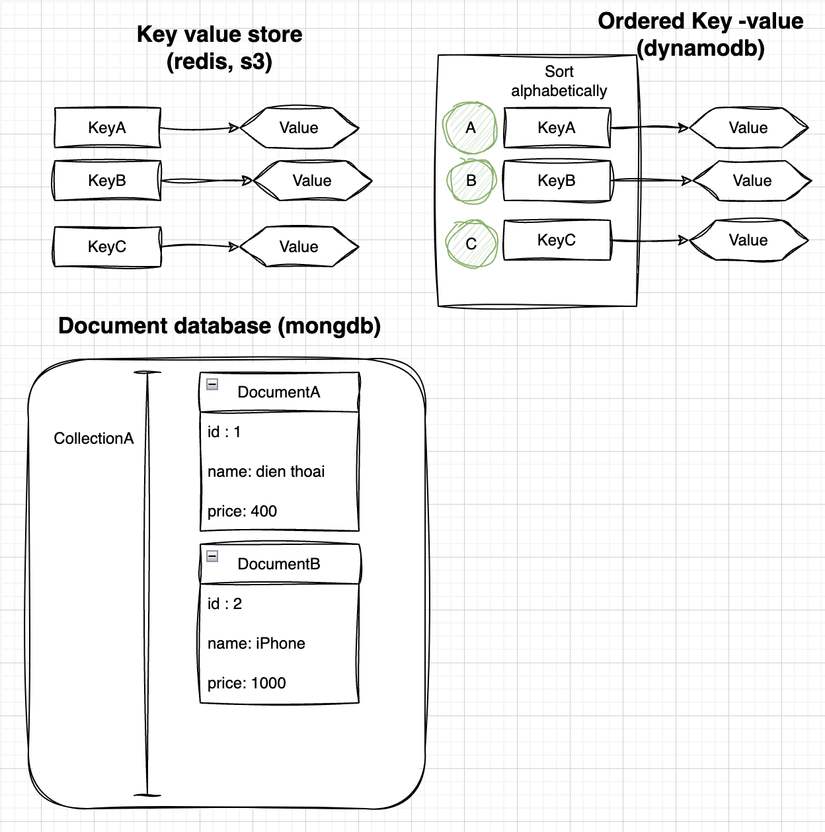
-
Data Model:
- Các [Document databases] lưu trữ dữ liệu dùng định dạng như JSON hoặc BSON. Mỗi document chứa các cặp khóa-giá trị, trong đó các giá trị có thể là các loại dữ liệu đơn giản, mảng, hoặc tài liệu lồng nhau (nested documents).
- Các [Key-Value Stores] lưu trữ dữ liệu dưới dạng collection của key-value pairs, trong đó giá trị thường là (không rõ ràng) và kiểu đơn giản như string đối với cơ sở dữ liệu.
- Các [Ordered Key-Value Stores] được sắp xếp giữ dữ liệu theo thứ tự sắp xếp dựa trên các khóa (key), cho phép truy vấn phạm vi hiệu quả cùng với việc truy xuất dựa trên khóa.
-
Performance:
- Key-value stores đặc tạo ra với độ ưu tiên về IO (high-throughput), các hành động với độ trễ thấp (low-latency operations), phù hợp với các usecase đòi hỏi read, write nhanh cho lưu session đăng nhập, cache ...
- Document databases phù hợp với các ứng dụng cần nhiều query nâng cao hơn, có business phức tạo, hệ thống tăng tốc độ dựa trên các index giống các hệ sql như mysql.
- Ordered Key-Value Stores giống với Key-value stores nhưng phục vụ thêm query dựa trên range time (do có cấu trúc key đã được order), các use case phổ biến như time-series data, logs, and leaderboard systems
Luận bàn thế là đủ rồi , hy vọng a.e dev chúng ta hiểu thêm 1 tí về các cấu trúc database, để áp dụng một cách phù hợp nhé 😘
All rights reserved
