SQL Database Performance Tuning for Developers (Part 1)
Bài đăng này đã không được cập nhật trong 6 năm
Điều chỉnh performance SQL (SQL performance tuning) là một nhiệm vụ cực kỳ khó khăn, đặc biệt là khi làm việc với dữ liệu lớn, trong đó ngay cả một thay đổi nhỏ nhất cũng có thể có tác động mạnh mẽ (tích cực hoặc tiêu cực) đến performance.
Trong các công ty cỡ vừa và lớn, hầu hết việc điều chỉnh performance SQL sẽ được xử lý bởi Quản trị viên cơ sở dữ liệu (DBA). Nhưng thực tế lại có rất nhiều developers phải thực hiện nhiệm vụ này giống như DBA. Nhưng cách giải quyết các vấn đề từ hai vị trí này lại thường khác nhau, điều này có thể dẫn đến sự bất đồng giữa các đồng nghiệp.
Trên hết, cấu trúc doanh nghiệp cũng có thể đóng một vai trò. Giả sử nhóm DBA được đặt ở tầng 10 với tất cả các cơ sở dữ liệu của họ, trong khi các developer ở tầng 15, hoặc thậm chí trong một tòa nhà khác dưới một cấu trúc báo cáo hoàn toàn riêng biệt. Trong bài viết này, chúng ta cùng làm rõ hai điều:
- Cung cấp cho các developer một số kỹ thuật để điều chỉnh hiệu năng SQL.
- Giải thích cách các developer và DBA có thể làm việc cùng nhau một cách hiệu quả.
SQL Performance Tuning (in the Codebase): Indexes
Nếu bạn là một người mới hoàn toàn làm quen với cơ sở dữ liệu và thậm chí tự hỏi mình SQL performance tuning là gì?, Bạn nên biết rằng index là một cách hiệu quả để điều chỉnh cơ sở dữ liệu SQL của bạn, nhưng lại thường bị bỏ qua trong quá trình phát triển. Theo các thuật ngữ cơ bản, một index là một data structure giúp cải thiện tốc độ của các hoạt động truy xuất dữ liệu trên bảng cơ sở dữ liệu, bằng cách cung cấp tra cứu ngẫu nhiên nhanh chóng và truy cập hiệu quả các bản ghi theo thứ tự. Điều này có nghĩa là một khi bạn đã tạo một index, bạn có thể select hoặc sort các rows của mình nhanh hơn trước.
Các index cũng được sử dụng để xác định một khóa chính hoặc index duy nhất sẽ đảm bảo rằng không có columns nào khác có cùng giá trị. Nếu bạn mới sử dụng index, thì khuyên bạn nên sử dụng sơ đồ sau để cấu trúc các truy vấn của mình:
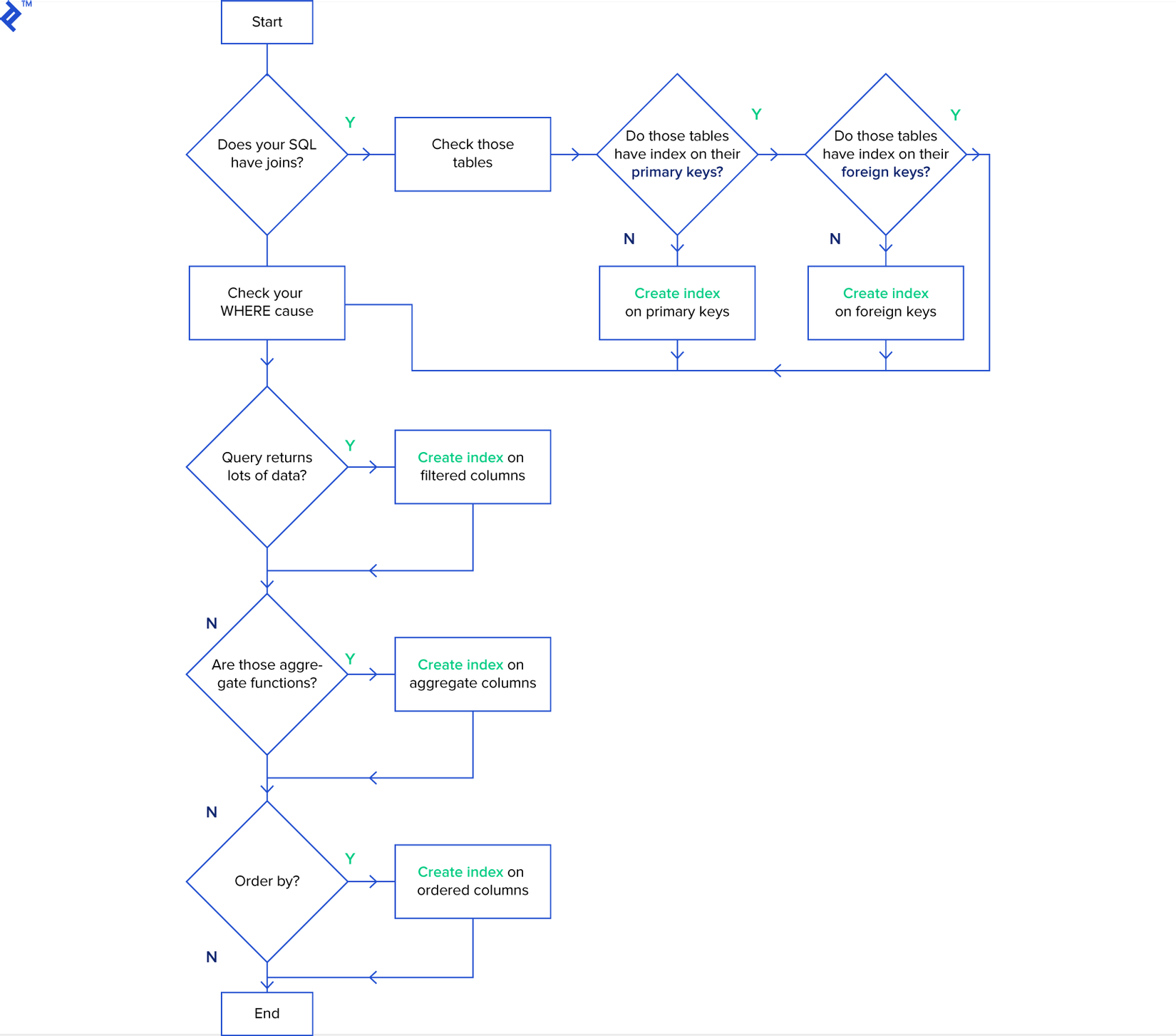
Về cơ bản, mục tiêu là đặt index cho các columns tìm kiếm và order.
Lưu ý rằng nếu các table của bạn liên tục bị khóa bởi INSERT, UPDATE và DELETE, bạn nên cẩn thận khi gắn index, bạn có thể sẽ giảm performance vì tất cả các index cần được modify sau các thao tác này.
Hơn nữa, các DBA thường drop các index SQL của họ trước khi thực hiện insert hàng triệu row nhằm tăng tốc độ quá trình insert. Sau khi insert thành công, thì họ sẽ tạo lại các index. Tuy nhiên, hãy nhớ rằng việc drop index sẽ ảnh hưởng đến mọi truy vấn đang chạy trong bảng đó; vì vậy phương pháp này chỉ được khuyến nghị khi làm việc với một lần insert lượng dữ liệu lớn.
SQL Tuning: Avoid Coding Loops
Hãy tưởng tượng một kịch bản trong đó 1000 truy vấn đập cơ sở dữ liệu của bạn theo trình tự. Giống như sau:
for (int i = 0; i < 1000; i++) {
SqlCommand cmd = new SqlCommand("INSERT INTO TBL (A,B,C) VALUES...");
cmd.ExecuteNonQuery();
}
Bạn nên tránh các vòng lặp như vậy trong code của bạn. Ví dụ: chúng ta có thể chuyển đổi đoạn code trên bằng cách sử dụng câu lệnh INSERT hoặc UPDATE duy nhất có nhiều hàng và giá trị:
INSERT INTO TableName (A,B,C) VALUES (1,2,3),(4,5,6),(7,8,9) -- SQL SERVER 2008
INSERT INTO TableName (A,B,C) SELECT 1,2,3 UNION ALL SELECT 4,5,6 -- SQL SERVER 2005
UPDATE TableName SET A = CASE B
WHEN 1 THEN 'NEW VALUE'
WHEN 2 THEN 'NEW VALUE 2'
WHEN 3 THEN 'NEW VALUE 3'
END
WHERE B in (1,2,3)
Đảm bảo rằng mệnh đề WHERE của bạn tránh cập nhật value được lưu nếu nó trùng với value hiện có. Tối ưu hóa đơn giản như vậy có thể tăng đáng kể hiệu năng truy vấn SQL bằng cách chỉ update hàng trăm hàng thay vì hàng nghìn. Ví dụ:
UPDATE TableName
SET A = @VALUE
WHERE
B = 'YOUR CONDITION'
AND A <> @VALUE -- VALIDATION
SQL Tuning: Avoid Correlated SQL Subqueries
Một truy vấn con kết hợp (Correlated subquery) là một truy vấn sử dụng các value từ truy vấn cha. Loại truy vấn SQL này có xu hướng chạy row-by-row, một lần cho mỗi row được trả về bởi outer query và do đó làm giảm performance truy vấn SQL. Các developer SQL mới thường cấu trúc các truy vấn của họ theo cách này vì nó thường là cách dễ dàng.
Dưới đây, một ví dụ về một truy vấn con kết hợp:
SELECT c.Name,
c.City,
(SELECT CompanyName FROM Company WHERE ID = c.CompanyID) AS CompanyName
FROM Customer c
Cụ thể, vấn đề là inner query (SELECT CompanyName…) được chạy cho mỗi row trả về bởi outer query (SELECT c.Name…). Nhưng tại sao lại đi qua Company nhiều lần cho mỗi row được xử lý bởi outer query?
Một kỹ thuật điều chỉnh performance SQL hiệu quả hơn sẽ là cấu trúc lại truy vấn con kết hợp dưới dạng join:
SELECT c.Name,
c.City,
co.CompanyName
FROM Customer c
LEFT JOIN Company co
ON c.CompanyID = co.CompanyID
Trong trường hợp này, chúng ta đi qua bảng Company chỉ một lần, khi bắt đầu và JOIN nó với bảng Customer. Từ đó trở đi, chúng ta có thể chọn các giá trị chúng ta cần (co.CompanyName) một cách hiệu quả hơn.
References
https://www.toptal.com/sql-server/sql-database-tuning-for-developers
All rights reserved
