
Sinh tín hiệu hình sine với mô hình GAN
Bài đăng này đã không được cập nhật trong 4 năm
Giới thiệu
Các ứng dụng về GAN ở domain về ảnh thì vô cùng nhiều nhưng trong domain tín hiệu time-series thì chưa có nhiều. Với ý tưởng là các tín hiệu phức tạp thì theo fourier có thể phân tách được nhiều tín hiệu dạng sin. Nên khi mô hình có thể tạo ra được tín hiệu sin thì theo nguyên lý sẽ tạo được các tín hiệu phức tạp hơn, vì vậy trong bài này mình sẽ xây dựng mô hình GAN để sinh tín hiệu sin.
Mạng sinh đối nghịch GAN
GAN - Generative Adversarial Networks là một trong những chủ đề nhận được khá nhiều sự quan tâm trong lĩnh vực Deep learning. GAN lần đầu tiên được giới thiệu vào năm 2014 bởi Ian Goodfellow , là một phương pháp khôn khéo tận dụng sức mạnh của các mô hình phân biệt để có được mô hình sinh tốt, với mục tiêu chính là tạo ra dữ liệu giả giống với thật.
GAN có thể dịch ra là một mạng sinh đối nghịch, sở dĩ nó có tên gọi như vậy bởi nó bao gồm hai mạng có mục tiêu đối nghịch nhau đó là Generator và Discriminator. Khác với những mô hình sinh trước đó, khối Generator sẽ tạo ra dữ liệu dựa trên những điểm nhiễu tuân theo phân phối Gaussian hoặc Uniform và học để tạo ra dữ liệu tốt hơn dựa trên phản hồi của khối Discriminator. Trong khi đó, khối Discriminator sẽ học phân phối của dữ liệu thật và đưa ra đầu ra dạng true-false để biết rằng dữ liệu đầu vào là thật hay giả từ đó cung cấp được tín hiệu cho mô hình sinh. Điều này giúp cải thiện khối Generator cho tới khi nó sinh ra thứ gì đó giống với dữ liệu thực
Generator
Khối Generator về bản chất là một mô hình sinh nhận đầu vào là một tập hợp các vector nhiễu z được khởi tạo ngẫu nhiên theo phân phối Gaussian. Ở một số mô hình GAN tiên tiến hơn, đầu vào này có thể là một dữ liệu chẳng hạn như một bức ảnh, một đoạn văn bản hay một đoạn âm thanh. Nhưng ở trong mô hình ở bài viết này vẫn sẽ sử dụng GAN với đầu vào là vector nhiễu như đã được giới thiệu trong bài báo gốc. Như vậy, từ tập vector đầu vào ngẫu nhiên, khối Generator là một mạng học sâu có tác dụng biến đổi đầu vào đó thành một bức ảnh hoặc một tín hiệu đầu ra. Sau đó, đầu ra này sẽ được sử dụng làm đầu vào cho khối Discriminator.
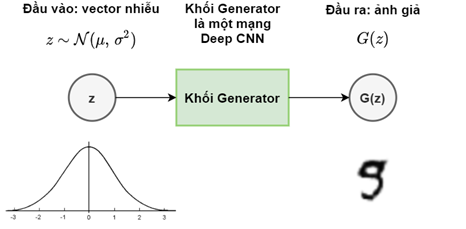
Discriminator
Khối Discriminator sẽ có tác dụng phân biệt ảnh đầu vào là thật hay giả. Nhãn của mô hình sẽ là thật nếu ảnh đầu vào của khối được lấy từ tập mẫu huấn luyện và là giả nếu được lấy từ đầu ra của khối Generator. Về bản chất đây là một bài toán phân loại nhị phân (binary classification) thông thường. Để tính xác suất đầu ra cho khối này hàm kích hoạt sigmoid sẽ được sử dụng ở lớp cuối cùng.
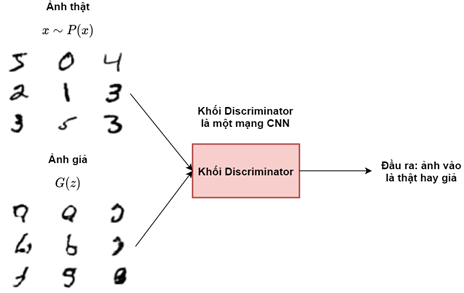
Minibatch Discrimination
Kĩ thuật Minibatch Discrimination được đề xuất nhằm giúp khối Generator tránh việc chỉ học được một đáp án duy nhất để “lừa” khối Discriminator hay là hiện tượng Mode Collapse - là hiện tượng sau quá trình huấn luyện khối Generator có thể học chỉ tạo ra một đầu ra duy nhất với bất kì nhiễu đầu vào nào. Bởi vì khối Discriminator xử lý mỗi dữ liệu một cách độc lập nên nó không thể nhận biết các dữ liệu mà khối Generator sinh ra khác nhau như thế nào. Do đó, tất cả đầu ra của khối Generator sẽ trở thành một dữ liệu duy nhất mà khối Discriminator cho rằng là thật nhất. Với MBD, tất cả các dữ liệu sinh ra sẽ được kiểm tra và “phạt” khối Discriminator nếu các dữ liệu đó giống nhau. Chi tiết về kĩ thuật này các bạn có thể tham khảo trong bài Improved Techniques for Training GANs.
Hàm mất mát
Kí hiệu:
- Nhiễu đầu vào khối Generator là
- Dữ liệu thật từ tập huấn luyện là
- Khối Generator là
- Khối Discriminator là
- Dữ liệu được sinh ra từ Generator là
- Giá trị dự đoán của Discriminator với đầu vào là dữ liệu thật là
- Giá trị dữ đoán xem dữ liệu sinh ra từ Generator là thật hay giả là
Vì mô hình GAN có hai khối Generator và Discriminator với hai mục tiêu khác nhau, nên cần thiết kế hai hàm mất mát cho mỗi khối. Discriminator thực hiện bài toán phân loại nhị phân nên hàm mất mát khối sử dụng sẽ là binary cross-entropy loss với hàm kích hoạt sigmoid. Vậy giá trị đầu ra của khối sẽ trong khoảng nên Discriminator sẽ được huấn luyện để đầu vào dữ liệu trong tập huấn luyện cho đầu ra gần , còn với đầu vào là dữ liệu sinh ra từ Generator sẽ cho đầu ra gần , hay và . Nói cách khác là hàm mất mát của khối Discriminator muốn tối đa giá trị và tối thiểu giá trị , việc tối thiểu tương đương với tối đa giá trị . Do đó hàm mất mát của khối Discriminator có thể được viết thành:
Khối Generator sẽ học để đánh lừa Discriminator rằng dữ liệu nó sinh ra là thật, hay . Tương tự, hàm mất mát muốn tối đa giá trị , tương đương với tối thiểu . Ta có, hàm mất mát của khối Generator:
Do đó, hàm mất mát của cả mô hình GAN có thể viết gộp lại thành:
Tuy nhiên, trong thực nghiệm hàm mất mát trên tỏ ra không hiệu quả cho khối Generator bởi trong giai đoạn đầu của quá trình huấn luyện, khi mà chất lượng dữ liệu sinh ra bởi Generator quá thấp, Discriminator có thể dễ dàng nhận biết. Dẫn đến việc bị bão hòa, do đó tác giá của mô hình đã đề xuất việc huấn luyện Generator để tối đa giá trị .
Xây dựng và huấn luyện mô hình GAN tạo tín hiệu sine
Tạo bộ dữ liệu hình sine
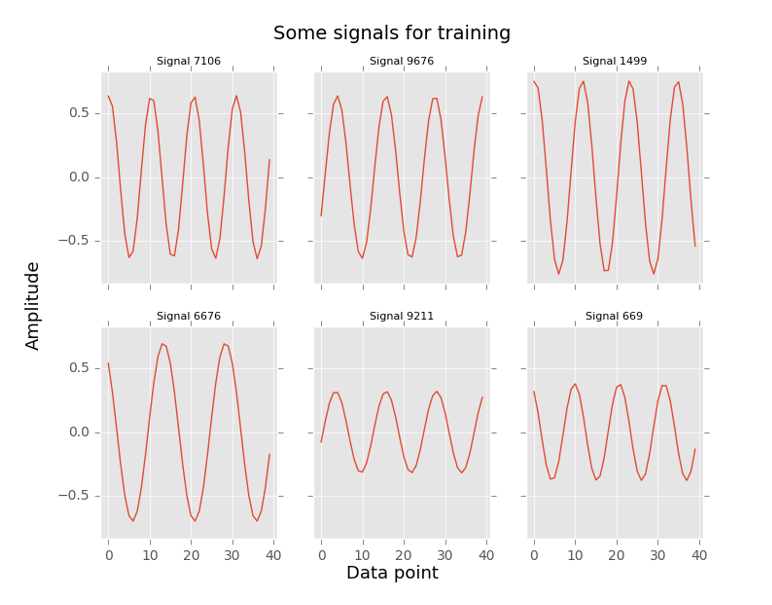
Với tín hiệu sine, bộ dữ liệu được tạo cho quá trình huấn luyện bao gồm 10000 tín hiệu và 3000 tín hiệu cho bộ dự liệu để đánh giá mô hình với các đặc điểm về tần số, pha và biên độ như sau:
- Tần số: Ngẫu nhiên trong khoảng (20 Hz – 40 Hz)
- Biên độ: Ngẫu nhiên trong khoảng (0.2 – 0.9)
- Pha: Ngẫu nhiên trong khoảng (0 – 2π)
Với các đặc điểm như vậy, các tín hiệu sine này được lấy mẫu với , trong khoảng thời gian 0.1 giây. Như vậy, mỗi tín hiệu sẽ bao gồm 40 điểm dữ liệu là đầu vào của các khối Discriminator và Generator trong mô hình GAN.
Xây dựng mô hình và huấn luyện
Mô hình LSTM-GAN là sự kết hợp của LSTM và CNN, với khối Generator bao gồm hai lớp LSTM và cuối cùng là lớp Fully Connected với hàm kích hoạt tanh. Số lượng trạng thái ẩn trong cell của LSTM sẽ là 16. Với tín hiệu sine, đầu vào của khối Generator là nhiễu với kích thước , chiều thứ nhất là kích thước của một batch, chiều thứ hai kích thước độ dài của tín hiệu sine (timestep), chiều thứ ba là giá trị tín hiệu tại timestep đó.
def make_generator_model():
model = tf.keras.Sequential()
model.add(LSTM(16,return_sequences=True, use_bias=True,
input_shape=(signal_length,features)))
model.add(LSTM(16,return_sequences=True, use_bias=True))
model.add(Dense(1, activation='tanh'))
return model

Khối Discriminator sau bộ ba lớp convolution, ReLU và max pooling là lớp flatten, mục đích của lớp là thay đổi kích thước đầu vào thành dạng một chiều. Tiếp đến là lớp Minibatch Discrimination, tại đây ngoài những đặc tính từ các lớp trước thì các thông tin phụ để đánh giá sự giống nhau của dữ liệu đầu vào sẽ được thêm vào. Cuối cùng là hai lớp fully connected, lớp đầu tiên sẽ dùng hàm kích hoạt ReLU, còn lớp thứ hai sẽ dùng hàm kích hoạt sigmoid để đảm bảo đầu ra là giá trị xác suất từ 0-1.
def make_discriminator_model():
model = tf.keras.Sequential()
# Convolution layer 1
model.add(Conv1D(filters=10, kernel_size=3, strides=1, activation='relu', input_shape=(signal_length,1)))
model.add(MaxPooling1D(pool_size=3, strides=2))
# Convolution layer 2
model.add(Conv1D(filters=5, kernel_size=3, strides=1, activation='relu'))
model.add(MaxPooling1D(pool_size=3, strides=2))
# FC
model.add(Flatten())
model.add(MinibatchDiscrimination(2))
model.add(Dropout(0.3))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(1, activation='sigmoid'))
return model

Tiếp theo ta xây dựng hàm tính loss cho 2 khối:
def discriminator_loss(real_output, fake_output):
# add noise to label
real_label = 0.05*np.random.random(1) + tf.ones_like(real_output)
fake_label = 0.05*np.random.random(1) + tf.zeros_like(fake_output)
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
Và hàm huyến luyện mô hình:
def train_step(real_signals):
size = real_signals.shape[0]
noises = np.random.normal(0,1,[size,signal_length,features])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
# Generate signal from noise
generated_signals = generator(noises, training=True)
# Output form D
real_outputs = discriminator(real_signals, training=True)
fake_outputs = discriminator(generated_signals, training=True)
# G loss
gen_loss = generator_loss(fake_outputs)
# D loss
disc_loss = discriminator_loss(real_outputs, fake_outputs)
# total loss
loss = [gen_loss, disc_loss]
# Update parameter by gradient
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
return loss
Chi tiết code mọi người có thể tham khảo thêm ở đây
Kết quả
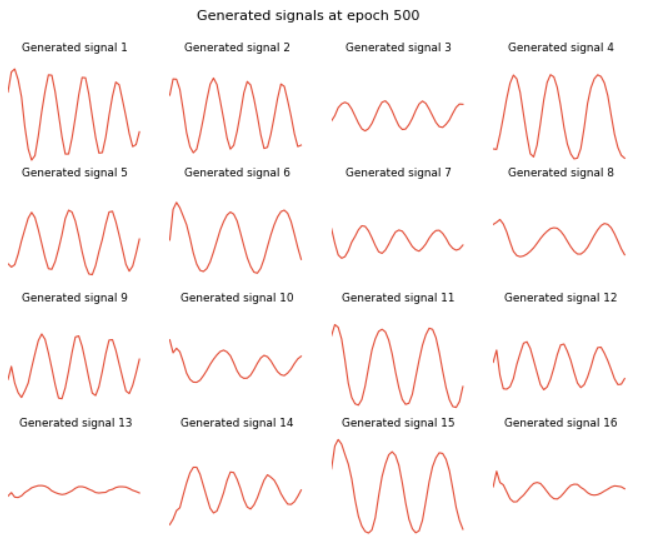
Ta huấn luyện mô hình sau 500 epochs thời gian train mỗi epoch khá nhanh (~2-3 giây), dưới đây là tín hiệu tạo ra bởi mô hình sau 10 epochs:
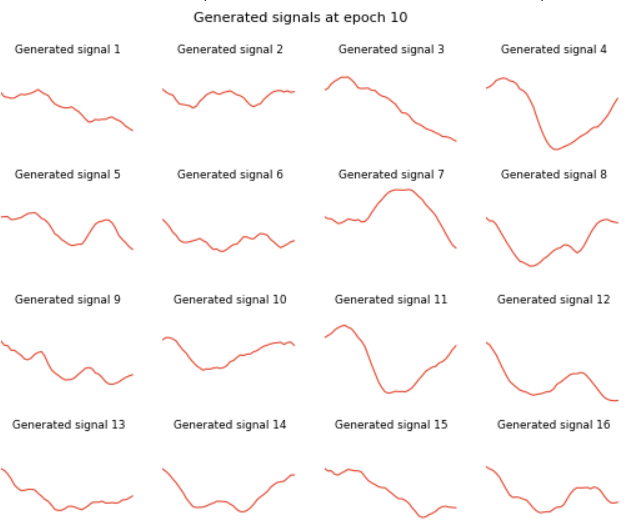
So sánh với các tín hiệu tạo ra bởi Generator sau 500 epochs. Ta thấy rằng tín hiệu tạo ra tuy vẫn chưa giống hoàn toàn hình sin nhưng đã cải thiện đáng kể, đã có những đặc điểm về tần số, pha và biên độ.
Kết luận
Qua bài này mình đã áp dụng mô hình GAN đơn giản cho việc tạo ra tín hiệu hình sin. Để có kết quả tốt hơn thì có lẽ cần phải áp dụng thêm nhiều kĩ thuật mới, chiến lược huấn luyện cho các khối từ đó có thể đạt được điểm cân bằng cho 2 khối Generator và Discriminator. Ngoài ra thì các phương pháp để đánh giá kết quả cũng rất quan trọng. Rất mong nhận được sự góp ý của mọi người để mình hoàn thiện bài viết và rút kinh nghiệm cho các bài tiếp theo!
Tài liệu tham khảo
https://www.tensorflow.org/tutorials/generative/dcgan
https://machinelearningmastery.com/what-are-generative-adversarial-networks-gans/
https://d2l.aivivn.com/chapter_generative-adversarial-networks/index_vn.html
All rights reserved
