Setup cho dự án NestJS - Phần 10: Indexes trong MongoDB 📑
Bài đăng này đã không được cập nhật trong 2 năm
Đây là bài viết nằm trong Series NestJS thực chiến, các bạn có thể xem toàn bộ bài viết ở link: https://viblo.asia/s/nestjs-thuc-chien-MkNLr3kaVgA
Cụm từ "Đánh Index" đã không còn quá xa lạ với các lập trình viên chúng ta, nó được đồn thổi là tăng query performance giúp API chạy nhanh và hiệu quả hơn 📈. Vậy rốt cuộc Index là gì, mình sẽ cùng các bạn tìm hiểu chi tiết về nó thông qua bài viết này.
Đặt vấn đề 📜
Giả sử chúng ta có model sau
class Room {
name: string;
description?: string;
...
}
Và được đánh index cho field name: 1, các bạn đoán xem câu query sau có sử dụng index hay không:
this.room_model.find({ description: "Room description" }).sort({ name: 1 })
Câu trả lời sẽ nằm ở mục Single Field Index phía dưới
Vẫn là mục tiêu chính của series chúng ta, thay vì chỉ dùng index theo cách mì ăn liền, chúng ta sẽ cùng tìm hiểu về cấu trúc cũng như cách thức hoạt động của nó, để có thể hiểu rõ và từ đó tận dụng nó một cách tối ưu.
Lý thuyết 📚
Đầu tiên chúng ta sẽ đến với 2 khái niệm về scan hay gặp là:
- Collection scan: câu truy vấn sẽ scan toàn bộ dữ liệu trong collection.
- Index scan: câu truy vấn trước tiên sẽ scan trong index (dữ liệu được lưu trong index sẽ là một phần của document gốc trong collection) và dùng kết quả tìm được lấy ra các document trong collection thay vì phải scan toàn bộ collection.
- In-memory sort: quá trình sort khi MongoDB fetch document, sẽ mất một khoảng thời gian nhất định.
1. Indexes là gì? 🤔
Index là việc cấu trúc dữ liệu, lưu trữ theo một cơ chế chuyên biệt để tìm ra các record một cách nhanh chóng. - lxquan
Để làm rõ hơn khái niệm về Index chúng ta sẽ cùng đi đến ví dụ trong quá trình dùng từ điển. Khi xem từ điển các bạn sẽ thường thấy các chỉ mục (index) theo bảng chữ cái như bên dưới:

Giả sử quyển từ điển trên chỉ là một quyển sách đơn thuần, không có thứ tự, mục lục và chỉ mục. Nếu chúng ta muốn tìm các từ bắt đầu bằng He thì phải làm thế nào? Tất nhiên câu trả lời chỉ có thể là lục tìm từ đầu đến cuối quyển sách vì chúng ta không biết được có bao nhiêu từ thỏa mãn điều kiện.
➡️ Cách làm trên chính là Collection Scan trong MongoDB 📉
Thay vì phải lục tìm toàn bộ, chúng ta có thể khoanh vùng bằng cách sắp xếp và tạo chỉ mục như trên hình. Khi đó các từ sẽ được gôm lại theo chỉ mục và chúng ta chỉ cần tìm trong chỉ mục đó (ở đây là H) thì sẽ nhanh hơn nhiều so với cách tìm thông thường.
➡️ Còn đây sẽ là Index Scan trong MongoDB 🗂️
Cách hoạt động là sắp xếp và đánh chỉ mục cho các document bằng 1 hoặc 1 vài field (tùy theo loại Indexes) của document đó. Khi tiến hành các câu query (filter/sort) có liên quan tới các field được Index thì trước tiên sẽ tìm trong dữ liệu được index rồi mới lấy kết quả từ đó fetch document trong collection.
Chúng ta cùng xét ảnh gif minh họa bên dưới từ MongoDB để hiểu rõ hơn. Lưu ý gif trên chia làm 2 ví dụ là "Querying top 3 sales with index" và "Querying top 3 sales without index"
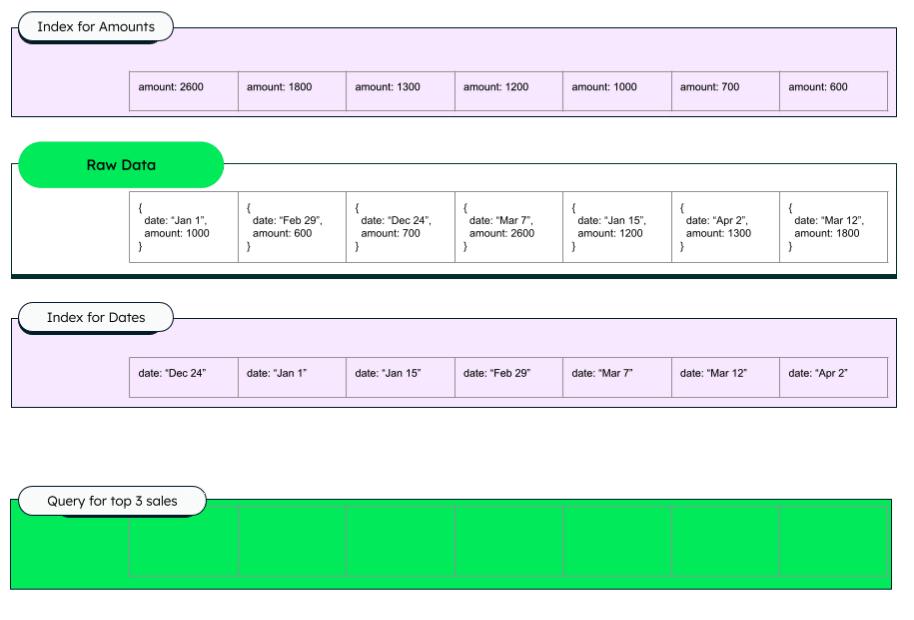
Giải thích:
- Raw data: document trong collection.
- Index for amounts/dates: dữ liệu được đánh index dựa vào
Raw data. dữ liệu sẽ chỉ gồm trường amount/date và được sắp xếp theo thứ tự giảm dần. - Có thể thấy ở trường hợp
Querying top 3 sales without index, chúng ta phải lần lượt scan qua từng phần tử trongRaw datasau đó sắp xếp lại để tìm ra top 3 amount lớn nhất vì chúng ta không biết document đang được scan qua có phải nằm trong top 3 hay không, chỉ biết được top 3 khi đã scan qua toàn bộ phần tử - Trường hợp ngược lại,
Querying top 3 sales with indexthì đầu tiên sẽ scan trongIndex for Amountsvà vì index đã được sort theo thứ tự nên việc tìm ra top 3 khá dễ dàng và nhanh chóng. Khi đã có thông tin của top 3, MongoDB sẽ fetch data từRaw Datavà trả về cho user.
Vậy Indexes lưu trữ các dữ liệu đó theo cấu trúc như thế nào? Được lưu ở đâu và liệu nó có tạo collection mới để lưu hay không? Chúng ta sẽ cùng tìm hiểu ở phần tiếp theo
2. Cách Index lưu trữ dữ liệu 🫙
Theo như tài liệu mình tìm hiểu được thì có thể trả lời các câu hỏi trên như sau:
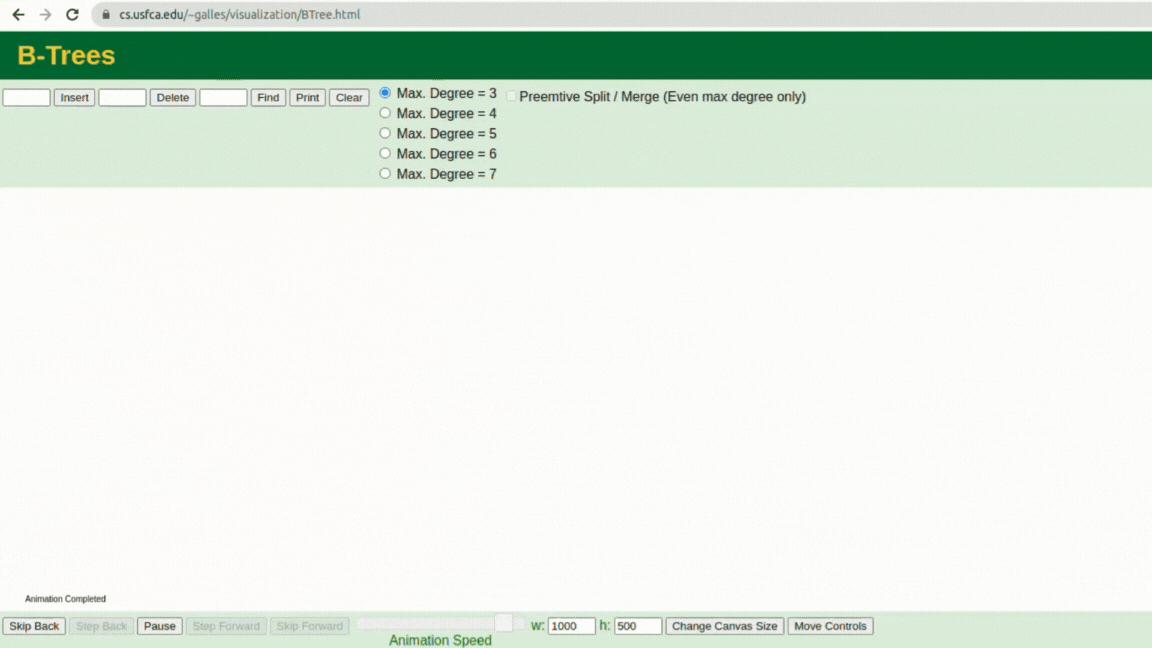
- Index được lưu trữ theo cấu trúc dữ liệu B-Tree (Balanced Tree). Gif bên dưới minh họa cách dữ liệu được lưu với Max.degree=3
![]()
- Cấu trúc B-Tree:
- Root node – node đầu tiên đứng vị trí cao nhất trong cây
- Child nodes – nodes con được trỏ từ Parent nodes
- Parent nodes – nodes cha trong cây mà có trỏ sang các Child nodes
- Leaf nodes – nodes lá, không trỏ đến bất kì nodes nào khác, có vị trí thấp nhất trong nhánh của cây.
- Cách hoạt động của B-Tree cũng tương tự với Binary Tree, tuy nhiên khác nhau ở chỗ:
- Node của B-Tree sẽ có thể có nhiều value - số lượng value tùy thuộc vào một hằng số cho trước gọi là bậc (degree).
- Các node của B-Tree cũng có thể có nhiều hơn hai nhánh con so với Binary Tree.
- Lợi ích của việc dùng B-Tree:
- Tối ưu được disk I/O do độ cao của cây được giảm xuống. Từ đó việc search và insert hiệu quả hơn so với Binary Tree.
- Duy trì được trạng thái cân bằng tốt hơn Binary Tree (trường hợp xấu nhất Binary Tree có thể trở thành dạng linked-list)
- Cấu trúc B-Tree:
Chúng ta sẽ không đi sâu vào data structure B-Tree để tránh lạc đề, các bạn có thể tham khảo thêm ở đây.
- Dữ liệu được lưu trữ bởi Index sẽ tương tự như ở Collection, trước tiên là lưu vào RAM và sẽ thường xuyên được ghi vào disk sau khoảng thời gian rất nhỏ để tối ưu performance và tránh làm mất dữ liệu.
3. Covered Queries là gì? ☂️
Covered queries là những query có kết quả trả về lấy dữ liệu trực tiếp từ Index mà không cần phải fetch từ collection, từ đó giúp cho việc xử lý trở nên nhanh và hiệu quả hơn. Cách triển khai Covered queries cần phải thỏa mãn các điều kiện sau:
- Tất cả các field trong query là một phần của index và kết quả trả về cũng vậy.
Ví dụ chúng ta có index { username: 1, point: 1, created_at: -1 } thì câu query sau sẽ đáp ứng covered queries this.user_model.find({username: 'johndoe' }, { username: 1, point: 1, created_at: 1 })
- Không có trường nào trong truy vấn bằng
null(tức là{"field" : null}hoặc{"field" : {$eq : null}} ).
Lấy ví dụ về Index chúng ta vừa tạo ở bài trước {vocabulary: 1, _id: 1}, nếu không có Covered queries thì kết quả sẽ như hình dưới:
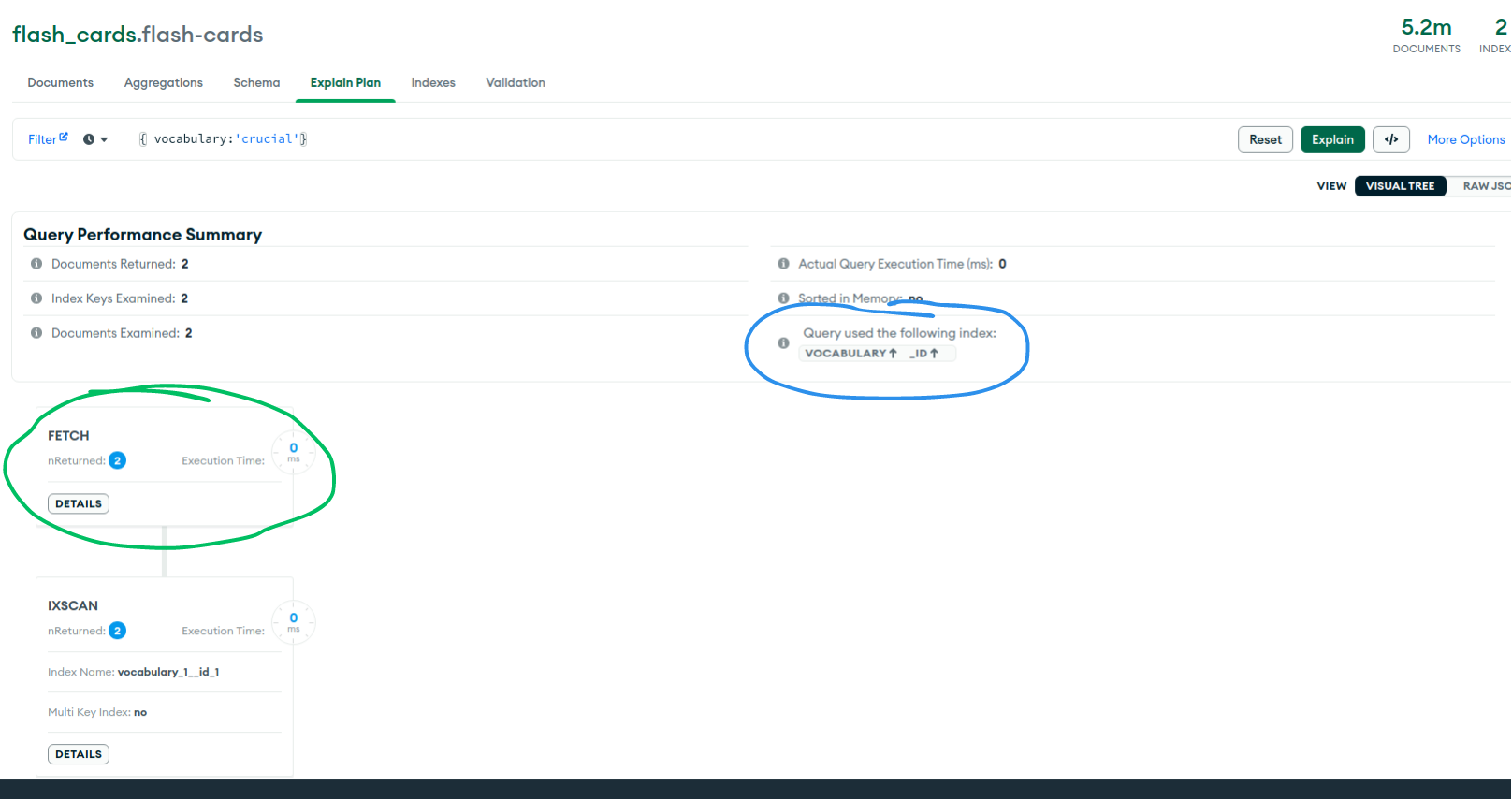
Chỗ mình khoanh tròn cho thấy state FETCH đang thực hiện fetch data từ collection dựa vào index. Tuy nhiên nếu chúng ta sử dụng Covered queries kết quả sẽ như sau:
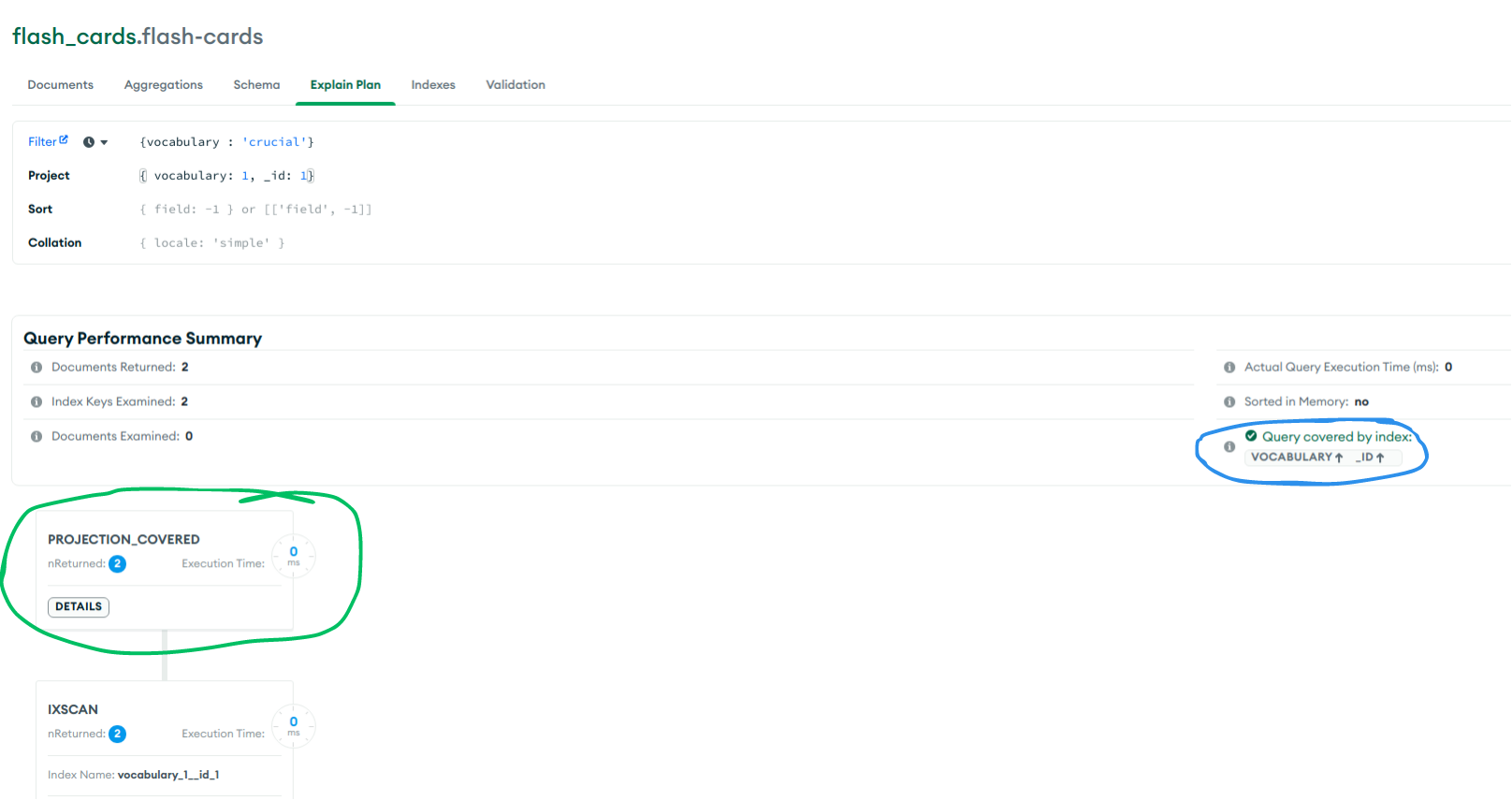
Có thể thấy ở summary có xuất hiện dòng Query covered by index và state đã thay đổi từ FETCH sang PROJECTION_COVERED. Ở đây do dữ liệu của chúng ta chưa đủ nhiều nên không thấy được sự khác biệt về Query execution time, nếu lượng dữ liệu đủ lớn các bạn sẽ thấy sự chênh lệch thời gian khá rõ ràng.
4. Advantages ✅️
Ở bài viết Phần 9: Pagination trong MongoDB mình cũng đã minh họa cho các bạn thấy với collection có khoảng 5 triệu document thì việc dùng Index sẽ nhanh hơn vài lần so với khi không dùng như thế nào.
Chúng ta cùng điểm qua các lợi ích mà Indexes mang lại để xem tại sao nên sử dụng:
- Improved Query Performance & Reduced Number of Scanned Documents: nhờ vào Index mà chúng ta chỉ cần scan các document cần thiết từ đó giúp tiết kiệm resource và tăng performance.
- Faster Sorting: giúp tăng tốc sort bằng cách sắp xếp trước tài liệu dựa trên các field được đánh index mà không cần tới in-memory sort (trường hợp
Querying top 3 sales without indextrong gif ở đầu bài mỗi khi lấy ra document thì sẽ sort lại, quá trình sort đó gọi là in-memory sort). - Enhanced Aggregation Performance: các aggregation operation trong MongoDB như grouping và data processing, có thể nhanh hơn với Indexes vì nó có thể nhanh chóng truy cập vào dữ liệu liên quan.
- Support for Unique Constraints: Indexes có option unique giúp chúng ta config document có field hoặc nhóm các field đó là duy nhất trong collection. Điều này giúp duy trì tính toàn vẹn của dữ liệu và tránh các mục trùng lặp.
- Covered Queries: như đã nói ở trên.
- Support for Multikey Indexes: ở MongdoDB chúng ta có thể đánh index cho field là array, giúp cho truy vấn trên các phần tử mảng trở nên hiệu quả hơn.
Có thể còn nhiều lợi ích khác trong thực tế nữa, nhờ các bạn góp ý để mình bổ sung vào.
5. Disavantages 📛
Các bất lợi có thể kể đến như:
- Increased Storage: đây là điều hiển nhiên vì chúng ta cần nơi để lưu trữ dữ liệu được đánh index.
- Write Performance: khi tiến hành insert/update/delete thì MongoDB phải cập nhật lại dữ liệu tương ứng trong Indexes, từ đó ảnh hưởng đến write operations. Vì thế chúng ta cân nhắc khi đánh Index cho các field thường xuyên có thay đổi.
- Index Selection: trong một số trường hợp, nếu chúng ta indexes không hợp lí không những không tăng performance mà còn làm cho nó tệ hơn. Vì thế việc dùng indexes thế nào cho hiệu quả là điều cực kỳ quan trọng
- Unique Index: khi sử dụng unique index thì sẽ MongoDB sẽ phải tốn thêm thời gian để kiểm tra xem có bị trùng hay chưa.
- Index Size Impact: Large indexes can have an impact on backup and restore operations, as well as on the time it takes to copy or move your database. (Phần này mình chưa kiểm chứng thực tế)
6. Các loại indexes thường dùng 💠
6.1 Single Field Indexes
Loại Index cơ bản nhất được tạo bằng một field bất kì trong document. Ví dụ syntax khi tạo Index cho field name của model Topic theo thứ tự tăng dần như sau:
const schema = SchemaFactory.createForClass(Topic);
// ⏬
schema.index({ name: 1 }); // 1 = acsending, -1 = descending
export const TopicSchema = schema;
Sau khi Index được tạo các câu query liên quan tới name có thể áp dụng index như bên dưới:
// ✅ TH1: query = `name`
this.topic_model.find({ name: 'School' })
// ✅ TH2: sort = `name`
this.topic_model.find().sort({ name: 1 })
// ✅ TH3: sort, query = `name`
this.topic_model.find({ name: 'School' }).sort({ name: -1 })
// ✅ TH4: sort = `name` nhưng query = field khác
this.topic_model.find({ description: "Topic description" }).sort({ name: 1 })
// ✅ TH5: sort = field khác nhưng query = `name`
this.topic_model.find({ name: 'School' }).sort({ description: 1 })
// ✅ TH6: sort = `name` và n field bất kỳ, query = `name`
this.topic_model.find({ name: 'School' }).sort({ description: 1, name: 1 })
// ✅ TH7: sort = `name` và n field bất kỳ, query = `name` và n field bất kỳ
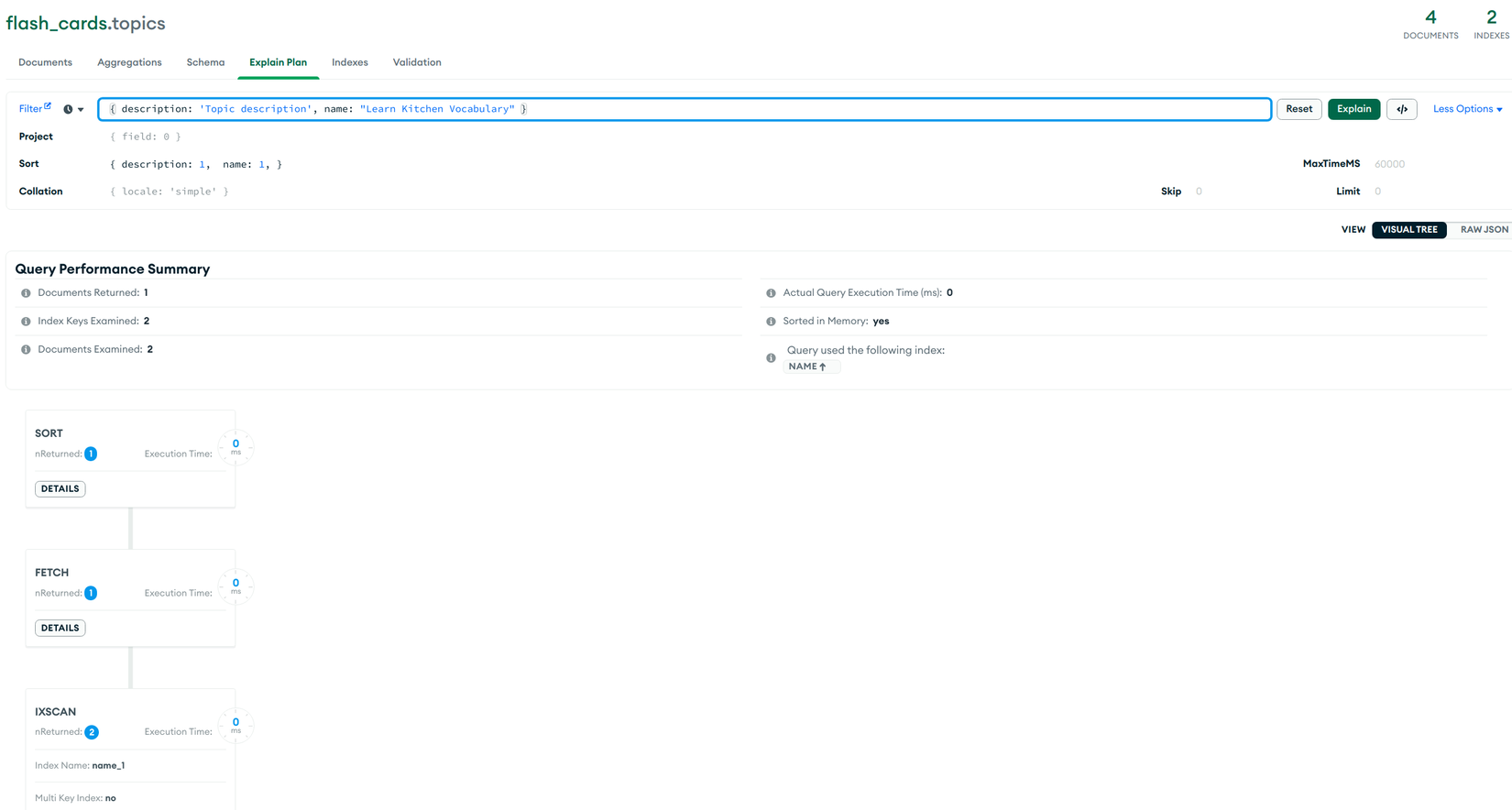
this.topic_model.find({ description: 'Topic description', name: "Learn Kitchen Vocabulary" }).sort({ description: 1, name: 1 })
Giải thích:
TH1 find({ name: 'School' }):MongoDB sẽ tìm trực tiếp trong Index (IXSCAN) sau đó dùng key đểFETCHtoàn bộ thông tin document về:
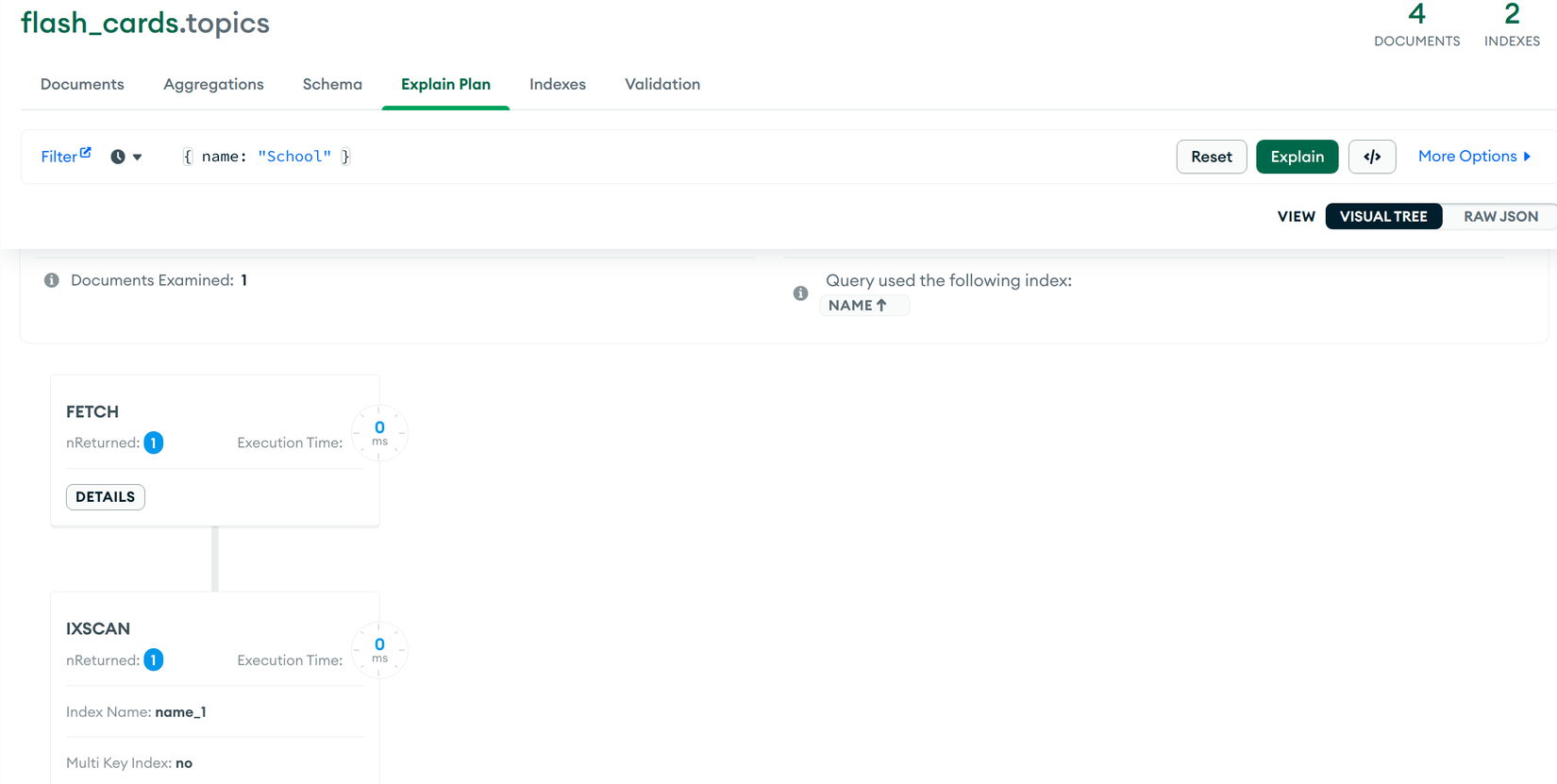
TH2 find().sort({ name: 1 }):Vì dữ liệu trong Index đã được sort sẵn nên chỉ cần lấy ra vàFETCHdocument:
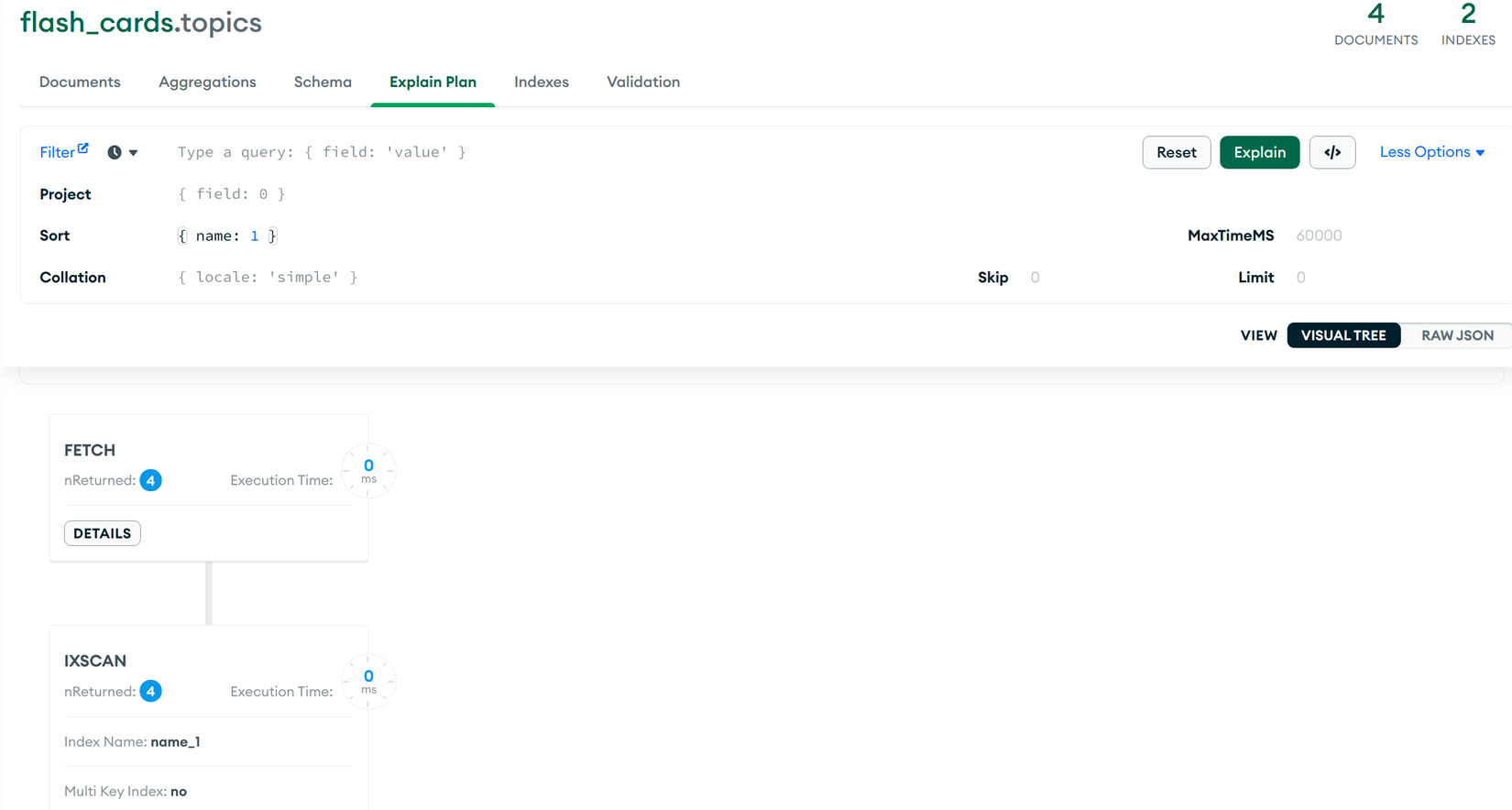
TH3 find({ name: 'School' }).sort({ name: -1 }):Tìm kiếm và trả về do dữ liệu đã được sort từ trước.TH4 find({ description: "Topic description" }).sort({ name: 1 }):Trả về dữ liệu đã được sort sẵn trong Index (Sorted In Memory: no) sau đó làFETCHdocument dựa theodescription:

Trường hợp này đã giải quyết được vấn đề chúng ta đặt ra ở đầu bài viết.
TH5 find({ name: 'School' }).sort({ description: 1 }):Do trong filter query cónamenên sẽ bắt đầu tìm kiếm trong Index, sau đóFETCHdocument về và cuối cùng làSORTlại trước khi trả về (Sorted In Memory: yes)
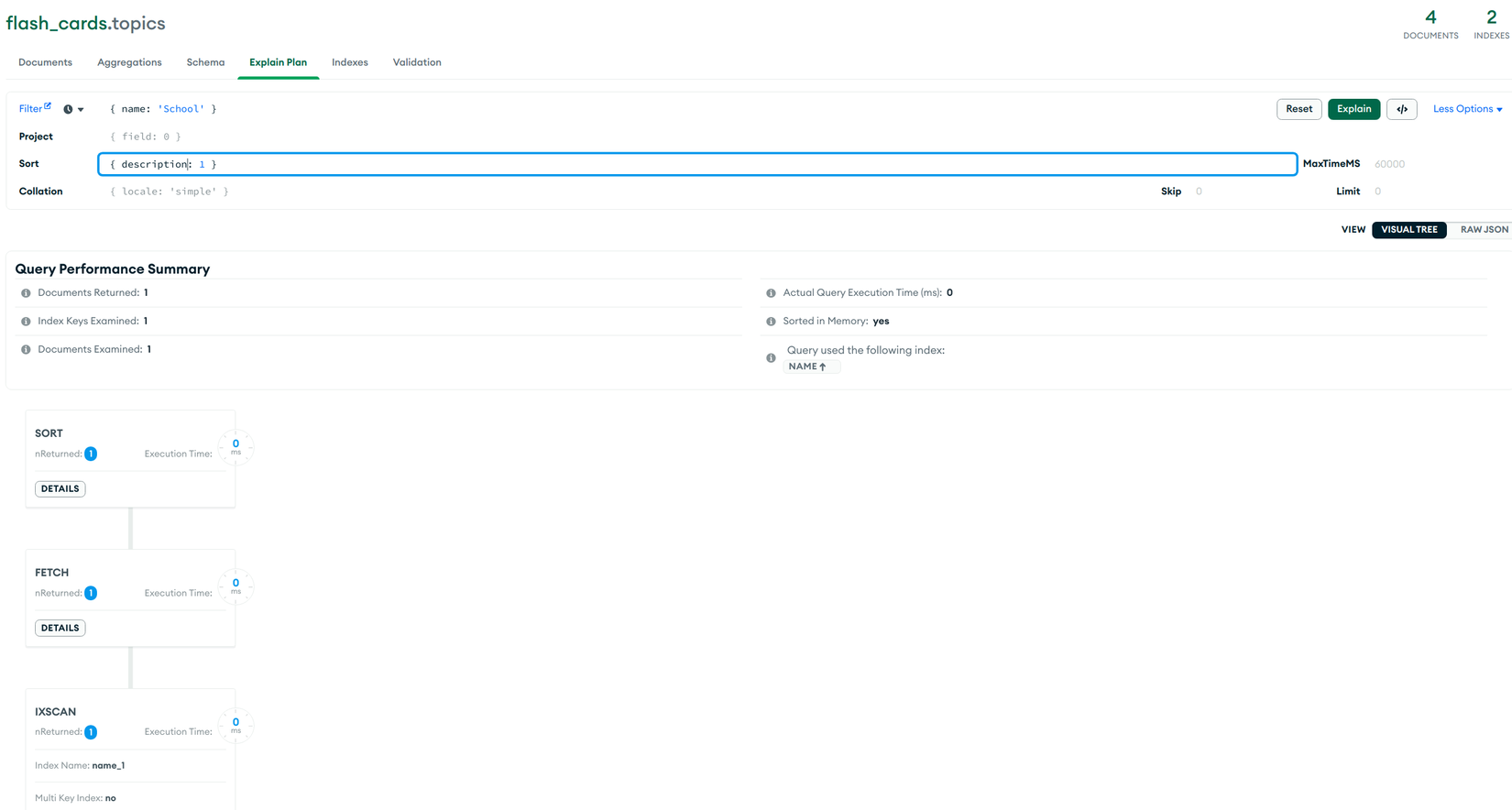
TH6 find({ name: 'School' }).sort({ description: 1, name: 1 }):Tương tự trường hợp 5, sau khi đã tìm kiếm trong Index thìFETCHdocument về và phảiSORTlại ở memory để trả về (Sorted In Memory: yes)
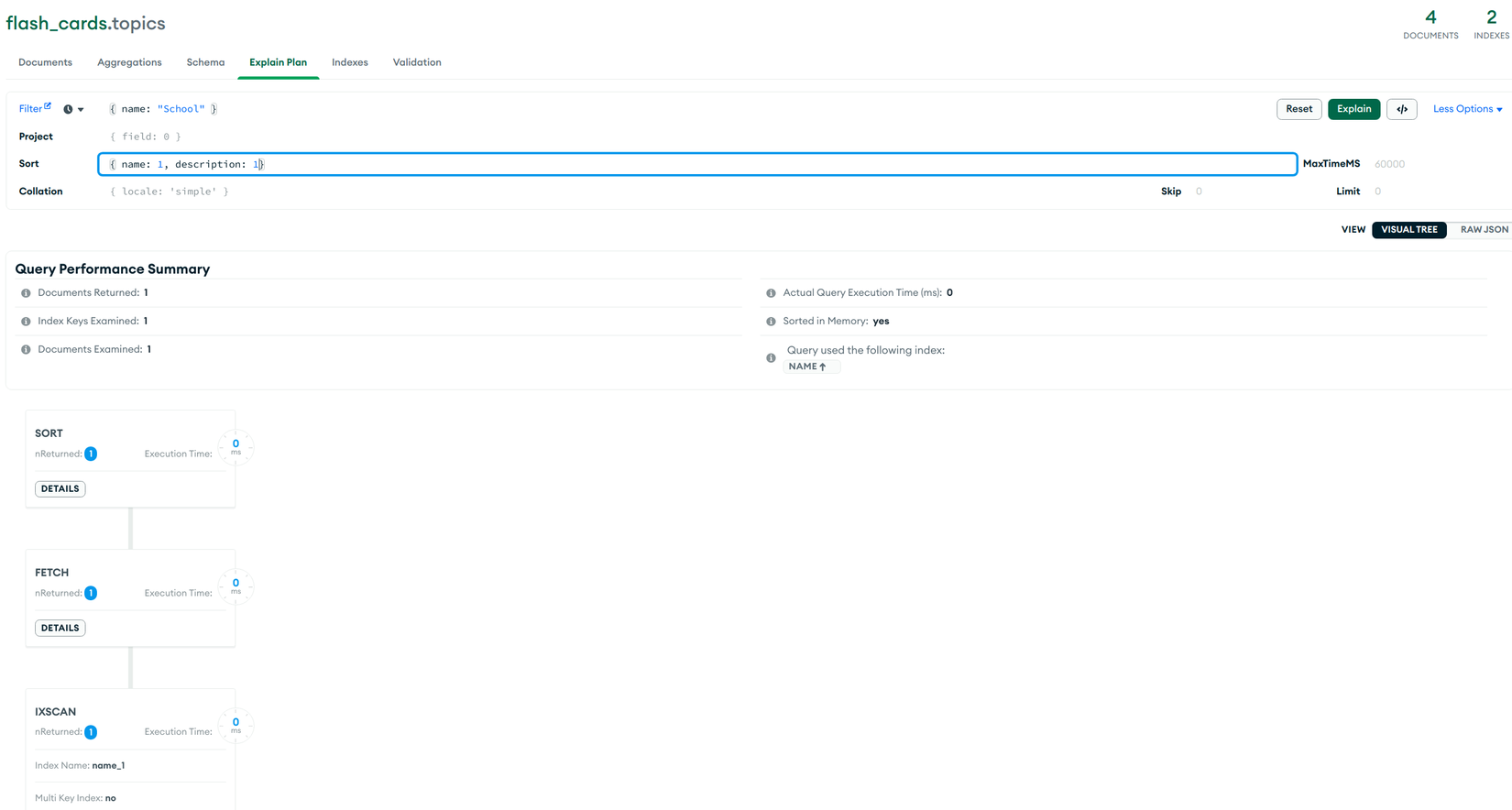
TH7 .find({ description: 'Topic description', name: "Learn Kitchen Vocabulary" }).sort({ description: 1, name: 1 }):Ở trong câu query có 2 field trong đónameđã được Index nên trước tiên sẽ tìm các giá trị thỏa mãnname='Learn Kitchen Vocabulary', từ kết quảIXSCANchúng ta có 2 giá trị thỏa mãn. Sau đó ở bướcFETCHsẽ lọc lại theodescriptionđồng thời lấy đầy đủ thông tin của document. Cuối cùng làSORTở memory và trả về (Sorted In Memory: yes).
Các query sau sẽ không áp dụng Index
// ❌ TH8: query != `name`
this.topic_model.find({ description: 'School' })
// ❌ TH9: sort = `name` và n field bất kỳ, query != `name` (ngược lại với TH6)
this.topic_model.find({ description: 'Some description' }).sort({ description: 1, name: 1 })
Để giải thích hết các trường hợp trên thì hơi khó, các bạn dùng MongoDB Compass và chuyển qua tab Explain để test và xem các stage trả về trong kết quả thì sẽ phần nào hiểu tại sao nó work ✅.
6.1.1 Index on an Embedded Field
MongoDB cung cấp cho chúng ta khả năng tạo index cho cả Embedded Field.
Các bạn lưu ý phân biệt giữa Embedded Field và Embedded Document.
Ví dụ ở model User chúng ta có data như sau:
{
_id: ObjectId('6445b9d38095a7adc6514db7'),
first_name: 'Michael',
last_name: 'Smith',
email: 'michaelsmith@example.com',
address: {
city: 'TP HCM',
country: 'Viet Nam',
},
...
},
{
_id: ObjectId('6445b9d38095a7adc6514db8'),
first_name: 'John',
last_name: 'Doe',
email: 'johndoe@example.com',
address: {
city: 'New York',
country: 'America',
},
...
},
{
_id: ObjectId('6445b9d38095a7adc6514db9'),
first_name: 'Richal',
last_name: 'Kloop',
email: 'rechalkloop@example.com',
address: {
city: 'New Delhi',
country: 'India'
},
...
}
Có thể tạo index như bên dưới
user_schema.index({ 'address.country': 1 });
Index sẽ được tạo ra trong MongoDB với tên mặc định address.country_1:
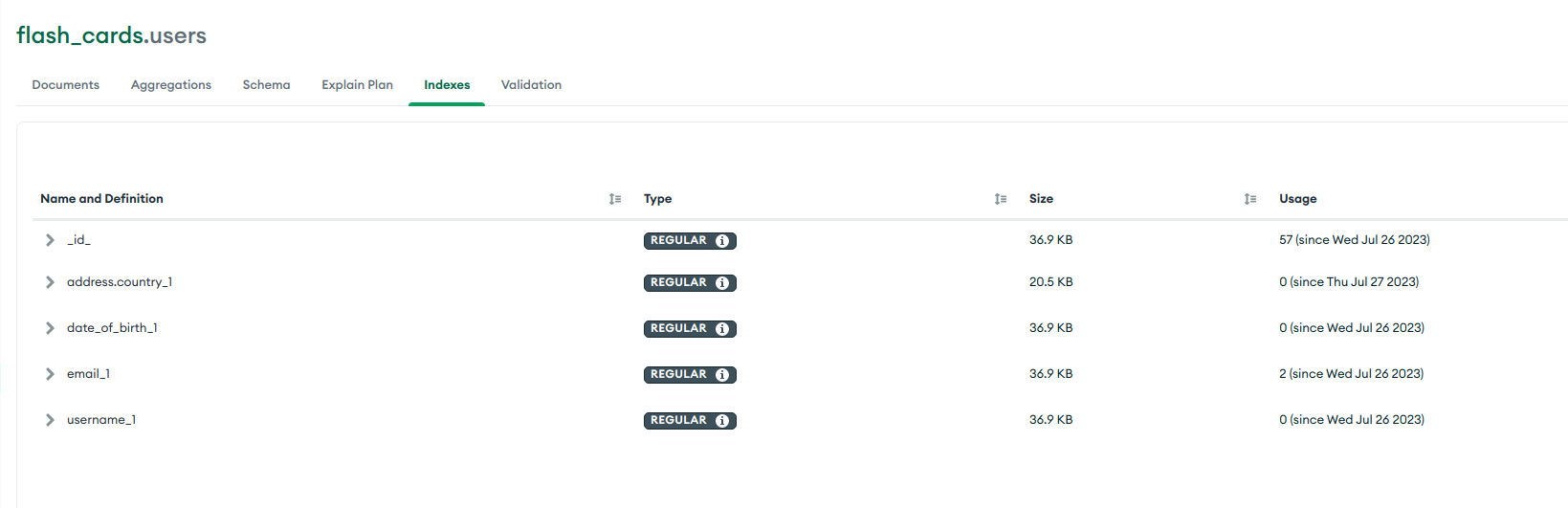
Các index còn lại (ngoại trừ _id) mình tạo để test các bạn đừng để ý 😅
Và sẽ được lưu trữ dưới dạng:

Sao khi được đánh index thì các câu query sau có thể áp dụng:
// ✅
this.user_model.find({ 'address.country': 'Viet Nam' })
// ✅
this.user_model.find({ 'address.country': 'Viet Nam', 'address.city': 'TP.HCM' })
// ✅ bao gồm các trường hợp liên quan tới sort mà chúng ta đã liệt kê ở phần trên
Câu query bên dưới sẽ không áp dụng index:
// ❌
this.user_model.find({ 'address.city': 'TP.HCM' })
// ❌
this.user_model.find({ 'address.city': 'TP.HCM' }).sort({'address.city': -1, 'address.country': 1})
6.1.2 Index on an Embedded Document
Khác với Embedded Field, chúng ta sẽ đánh index cho cả embedded document.
user_schema.index({ 'address': 1 });
Index address_1 sẽ được tạo trong MongoDB như hình dưới:
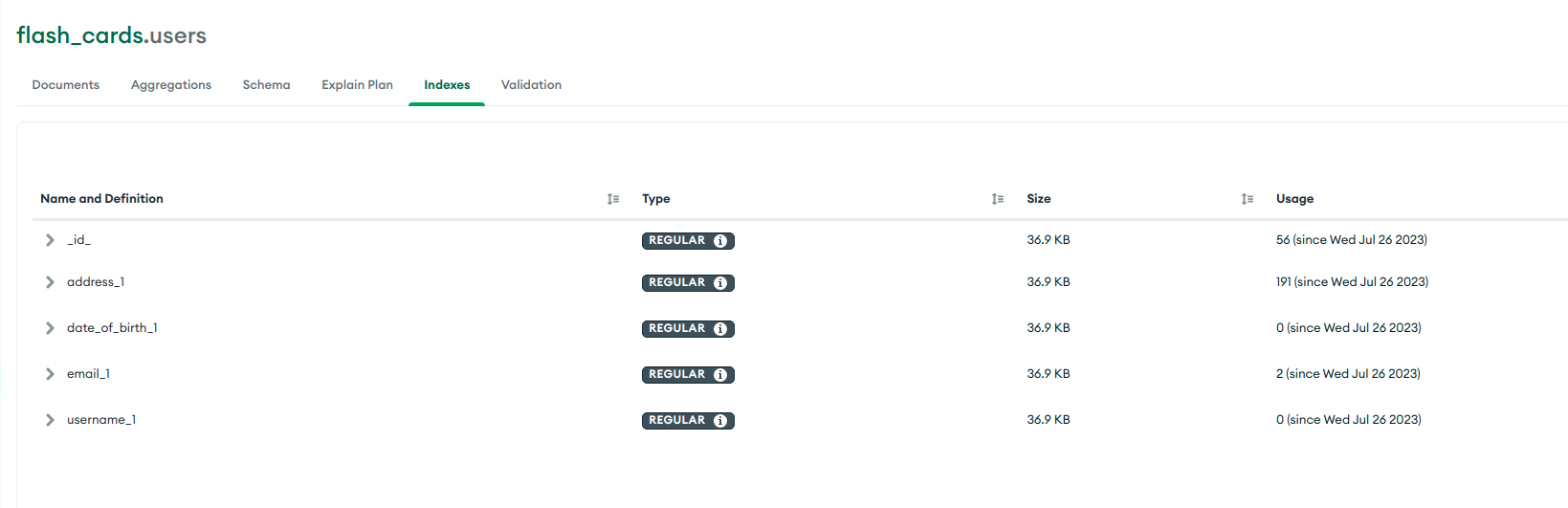
Cùng với ví dụ trên chúng ta sẽ có Index được lưu trong MongoDB như sau:

Trường hợp bên dưới sẽ sử dụng index scan:
// ✅ TH1: Trả về giá trị
this.user_model.find({ 'address': { 'city': 'TP.HCM', 'country': 'Viet Nam' }})
Kết quả:
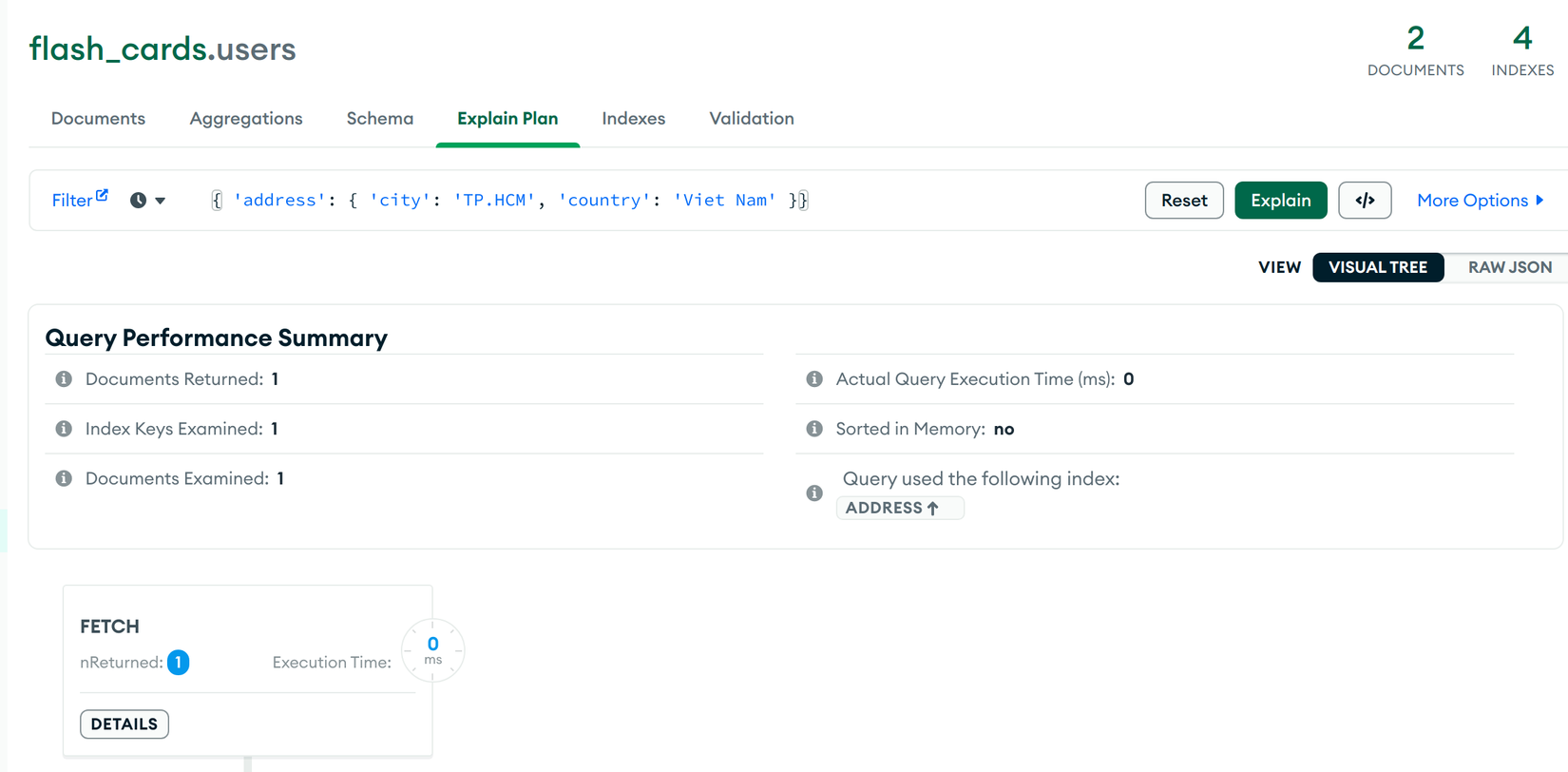
2 trường hợp bên dưới vẫn dùng index scan nhưng không trả về giá trị do:
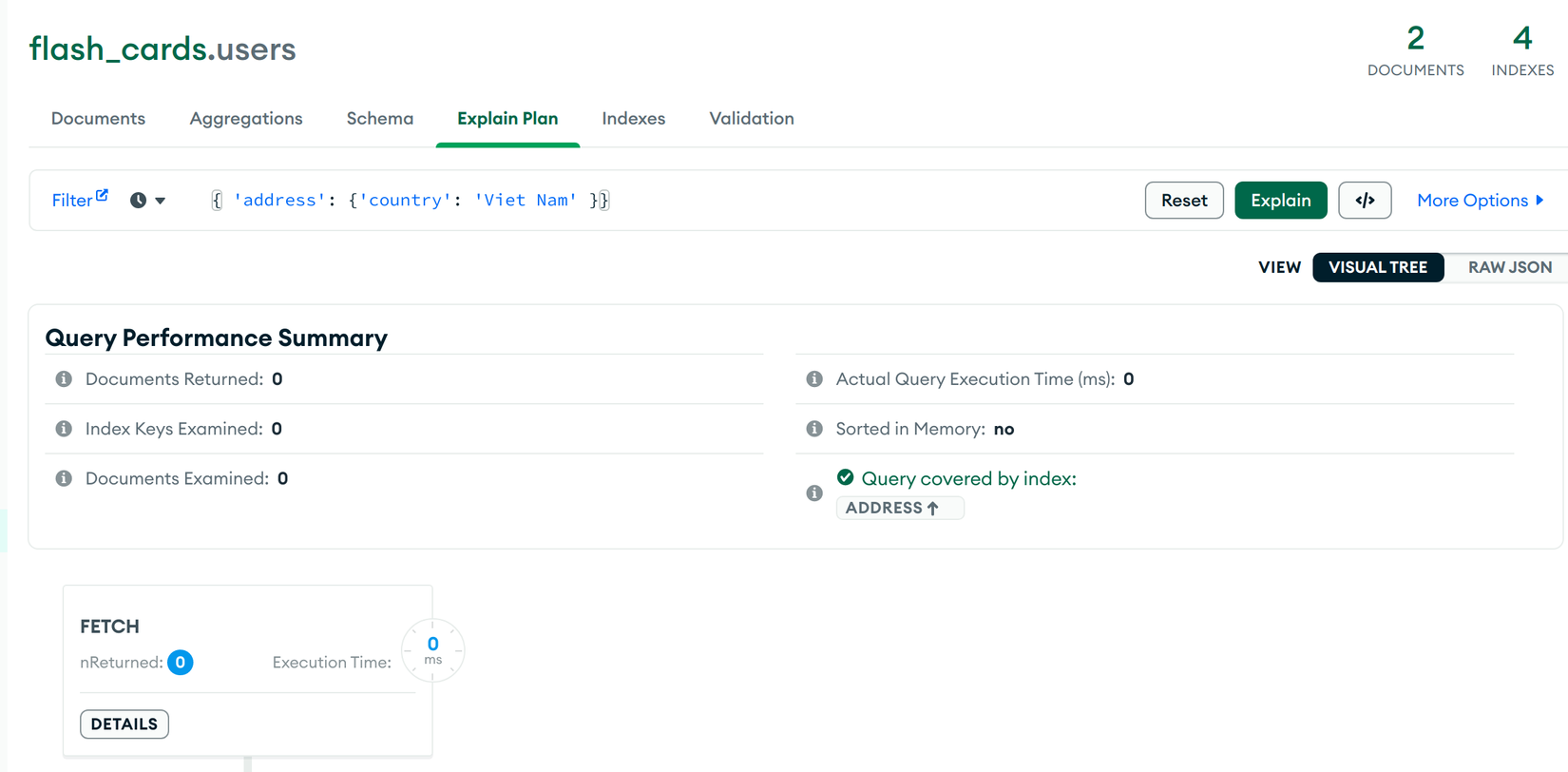
// ❌ TH2: Index scan nhưng không trả về giá trị do thiếu field
this.user_model.find({ 'address': {'country': 'Viet Nam' }})
Kết quả:
// ❌ TH3: Index scan nhưng không trả về giá trị do thứ tự các field không chính xác
this.user_model.find({'address': { 'country': 'Viet Nam', 'city': 'TP.HCM'}})
Kết quả:
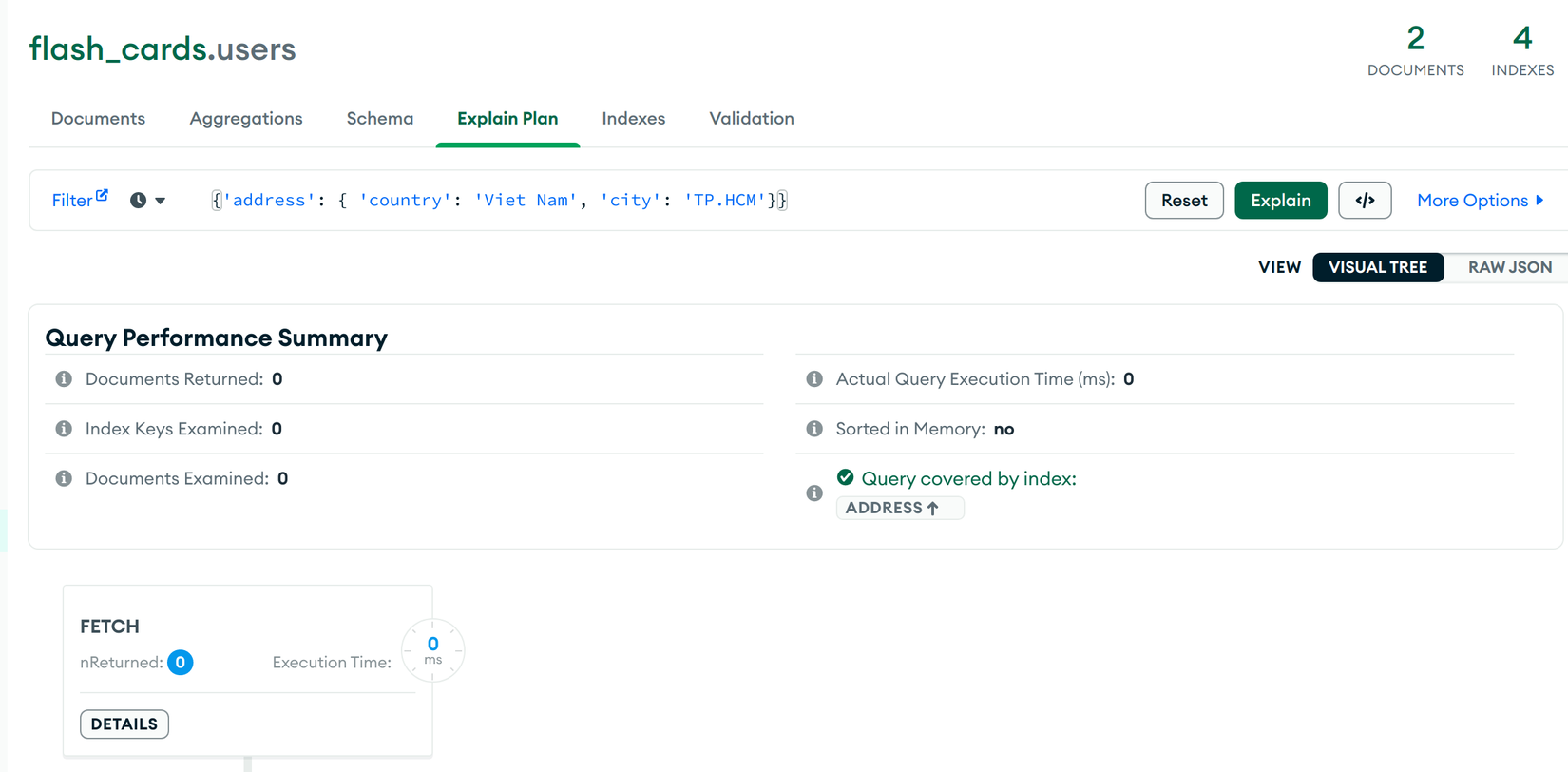
Có thể thấy được ở trường hợp 2 & 3 mặc dù vẫn dùng index scan nhưng không nhận được giá trị do thiếu field hoặc thứ tự (order) các field không chính xác. Do đó chúng ta phải thật cẩn trọng khi dùng Indexes với Embedded Document.
Lưu ý: các bạn cần phân biệt giữa Query Embedded Document và Nested Document:
- Query on Embbeded Document:
this.user_model.find({ 'address': { 'city': 'TP.HCM', 'country': 'Viet Nam' }})
- Query on Nested Document:
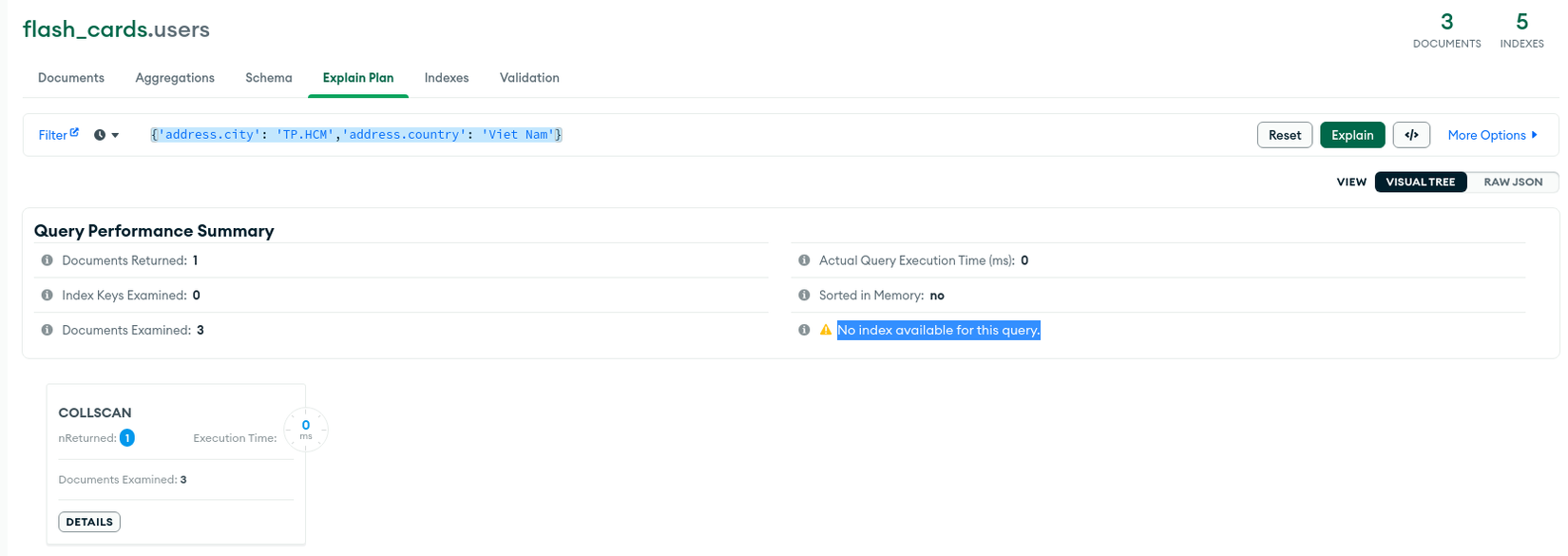
this.user_model.find({ 'address.city': 'TP.HCM','address.country': 'Viet Nam' })Indexes cho Embedded Document chỉ áp dụng với Query on Embedded Document, nếu dùng Query on Nested Document sẽ không áp dụng và có kết quả như bên dưới:
6.2 Compound Indexes
Compound Indexes nói một cách dễ hiểu là chúng ta sẽ đánh index cho nhiều field thay vì chỉ 1 field như Single Field Indexes. Ví dụ ở model User chúng ta sẽ đánh indexes cho cả first_name và point để phục vụ mục đích thống kê.
...
user_schema.index({ first_name: 1, point: -1 });
...
Và dữ liệu chúng ta có như sau:
{
_id: ObjectId('6445b9d38095a7adc6514db7'),
first_name: 'Michael',
last_name: 'Smith',
point: 100
...
},
{
_id: ObjectId('6445b9d38095a7adc6514db8'),
first_name: 'John',
last_name: 'Doe',
point: 520
...
},
{
_id: ObjectId('6445b9d38095a7adc6514db9'),
first_name: 'John',
last_name: 'Cena',
point: 120
...
},
{
_id: ObjectId('6445b9d38095a7adc6514db9'),
first_name: 'Anna',
last_name: 'Belle',
point: 999
...
},
{
_id: ObjectId('6445b9d38095a7adc6514db9'),
first_name: 'Zeke',
last_name: 'Jeager',
point: 2000
...
},
{
_id: ObjectId('6445b9d38095a7adc6514db9'),
first_name: 'John',
last_name: 'Doe',
point: 333
...
},
Dữ liệu sẽ được tạo trong index như sau:

Giải thích:
- Quá trình sắp xếp sẽ bắt đầu từ
first_nametheo thứ tự tăng dần căn cứ vào value là 1. - Nếu như tồn tại các record có cùng
first_namethì tiếp theo sẽ căn cứ vàopointđể sắp xếp và thứ tự sẽ là giảm dần do value là -1. Trên hình các user cófirst_namelàJohnsẽ được sort dựa theopointgiảm dần.
Mình sẽ lấy ví dụ sâu hơn là đánh index cho cả first_name, last_name và point, khi đó dữ liệu trong index sẽ là:

Giải thích: tương tự ở trên, đầu tiên sẽ sắp xếp theo first_name, nếu trùng sẽ đến last_name, cuối cùng nếu last_name vẫn tiếp tục trùng thì chúng ta sẽ xét đến point.
Lưu ý: hiện tại Compound indexes chỉ support tối đa 32 fields trong một lần index.
6.2.1 Sort Order
Khác với Single Field Indexes, thứ tự sắp xếp (sort order) của các field trong Compound Indexes là điều chúng ta cần quan tâm. Lấy index bên dưới làm ví dụ, nếu chúng ta muốn sort áp dụng index thì bắt buộc username và point phải cùng giống hoặc cùng khác với giá trị khai báo trong index.
// Index được tạo như sau
user_schema.index({ username: 1, point: 1 });
// ✅ TH1: Working
this.user_model.find().sort({ username: 1, point: 1 })
// ✅ TH2: Also working
this.user_model.find().sort({ username: -1, point: -1 })
// ❌ TH3: Not working
this.user_model.find().sort({ username: -1, point: 1 })
// ❌ TH4: Also not working
this.user_model.find().sort({ username: 1, point: -1 })
Kết quả TH1 ✅:
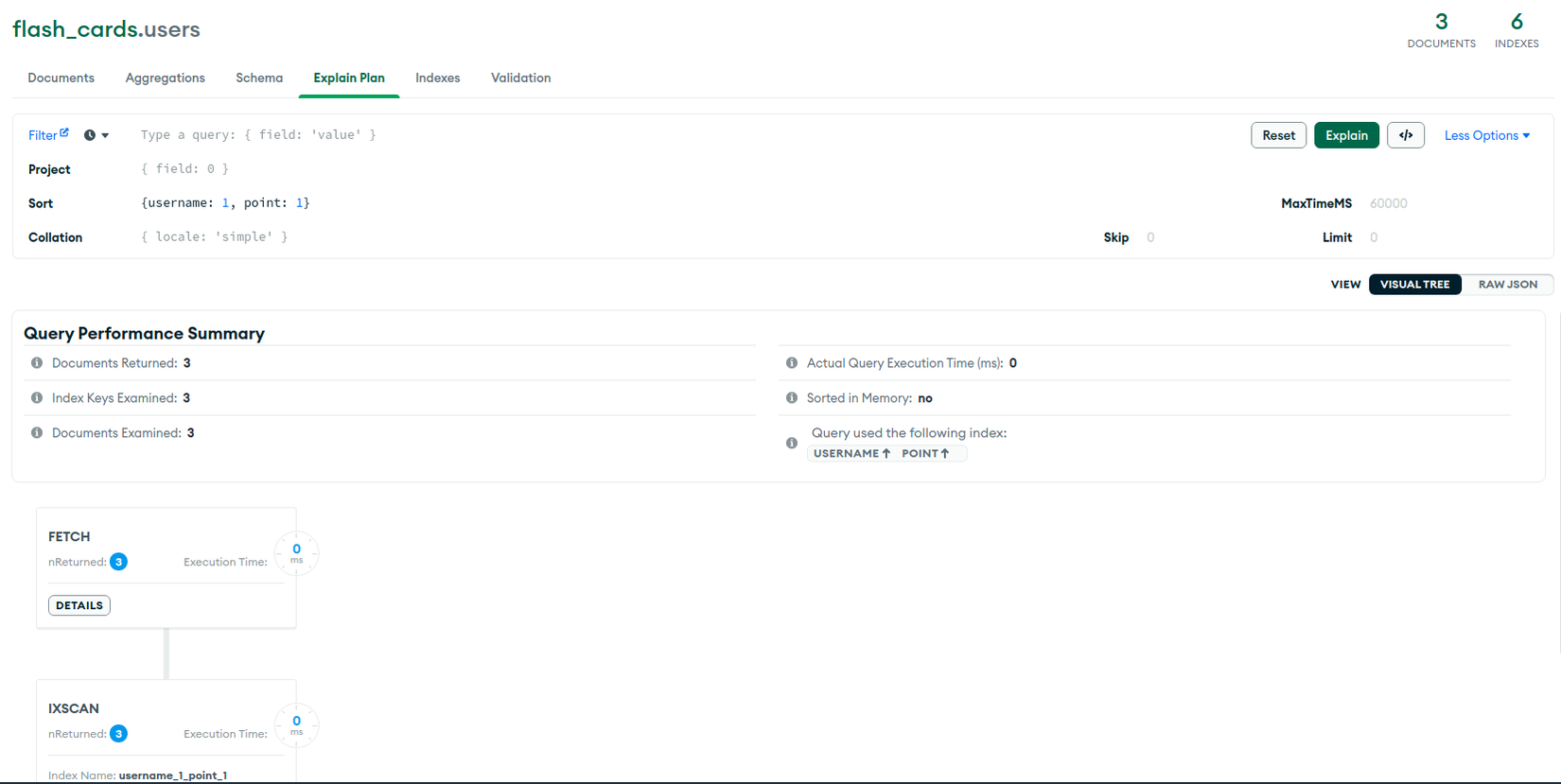
Kết quả của TH4 ❌:
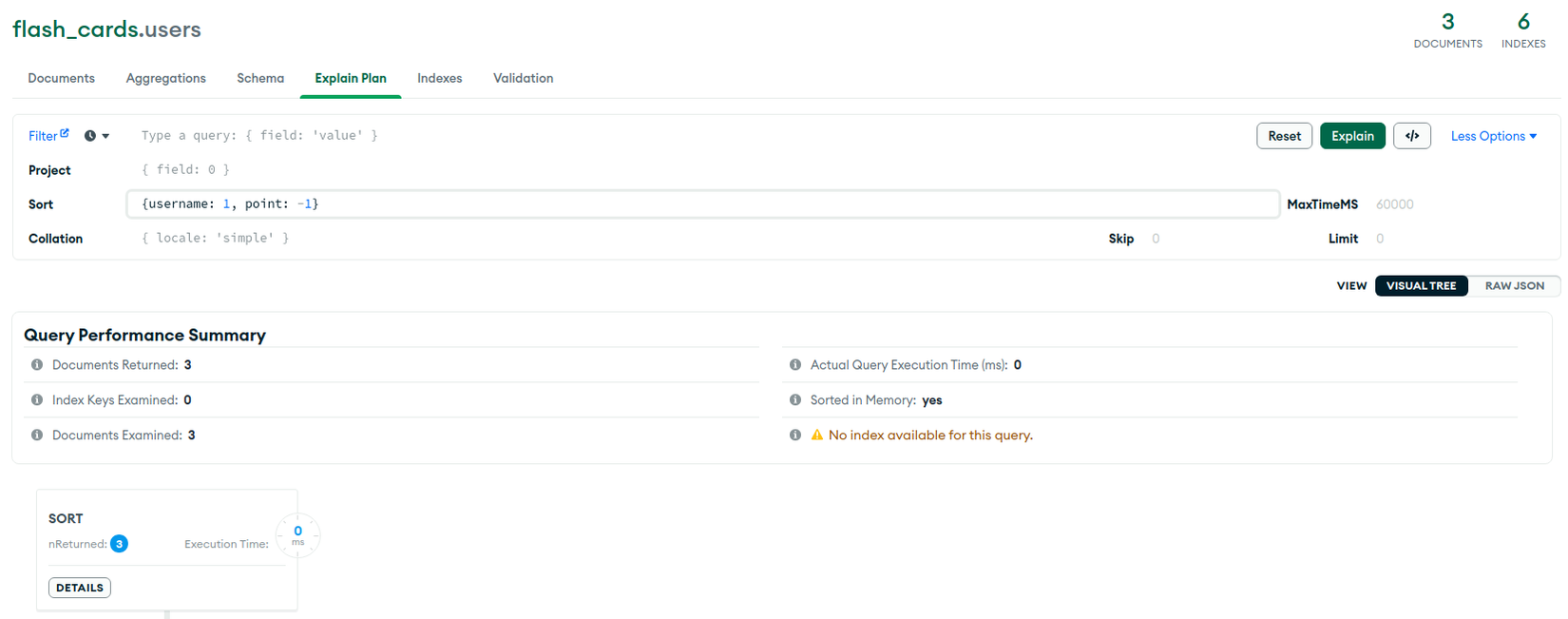
Từ kết quả trên ta có thể thấy được, nếu như khai báo sort không đúng cách thì sẽ không thể sử dụng index mà thay vào đó là in-memory sort.
6.2.2 Prefixes
"Index prefixes are the beginning subsets of indexed fields."
Đây là một trong những tính năng hay của compound index, giúp chúng ta hạn chế được việc tạo các Indexes không cần thiết. Ví dụ chúng ta có indexes như sau:
user_schema.index({ username: 1, point: 1, email: 1 })
Thì nhờ vào Index Prefix (ở đây là field user) chúng ta có thể coi như có các Index sau:
{ username: 1 }
{ username: 1, point: 1 }
{ username: 1, point: 1, email: 1 }
{ username: 1, email: 1 }
Khi đó MongoDB sẽ hỗ trợ query trên các index prefix với các trường sau:
usernamefieldusernamevàpointfieldusernamevàemailfieldusername,pointvàemailfield
6.2.3 Cách tạo Compound Indexes hiệu quả
"What is the recommended order of fields in a compound index?" - một câu hỏi khá hay trong MongoDB University mà mình từng đọc qua.
Vậy chúng ta nên sắp xếp thứ tự các field như thế nào để hợp lý? Vẫn là trích dẫn câu trả lời từ MongoDB University:
The recommended order of indexed fields in a compound index is Equality, Sort, and Range. Optimized queries use the first field in the index, Equality, to determine which documents match the query. The second field in the index, Sort, is used to determine the order of the documents. The third field, Range, is used to determine which documents to include in the result set.
Nói một cách dễ hiểu là ưu tiên các phép so sánh bằng (equality conditions, $eq) sau đó đến sort và cuối cùng là filter trong phạm vi cụ thể (với các operator như $gt, $lt,...).
Khi chúng ta tạo một chỉ mục với thứ tự này, nó sẽ cover nhiều query pattern khác nhau và cho phép MongoDB đáp ứng được nhiều câu query hơn chỉ bằng cách sử dụng index mà không cần truy cập vào các document trong collection (hay còn được gọi là Covered queries).
Phần này thì cần nhiều thời gian practice mới có thể áp dụng hiệu quả được, trong các bài viết tới nếu có cơ hội chúng ta sẽ nhắc lại.
Xem thêm từ tài liệu MongoDB về ESR tại đây
6.3 Multiple Indexes
Từ đầu đến giờ chúng ta đã tạo được Index cho các field có kiểu dữ liệu là string và integer, vẫn còn một kiểu dữ liệu mà chúng ta chưa dùng tới đó là Array. Khi chúng ta đánh index cho một field dạng Array sẽ tạo ra được Multikey Index.
Để giải thích cho tên gọi Multikey Index chúng ta sẽ tìm hiểu ví dụ sau:
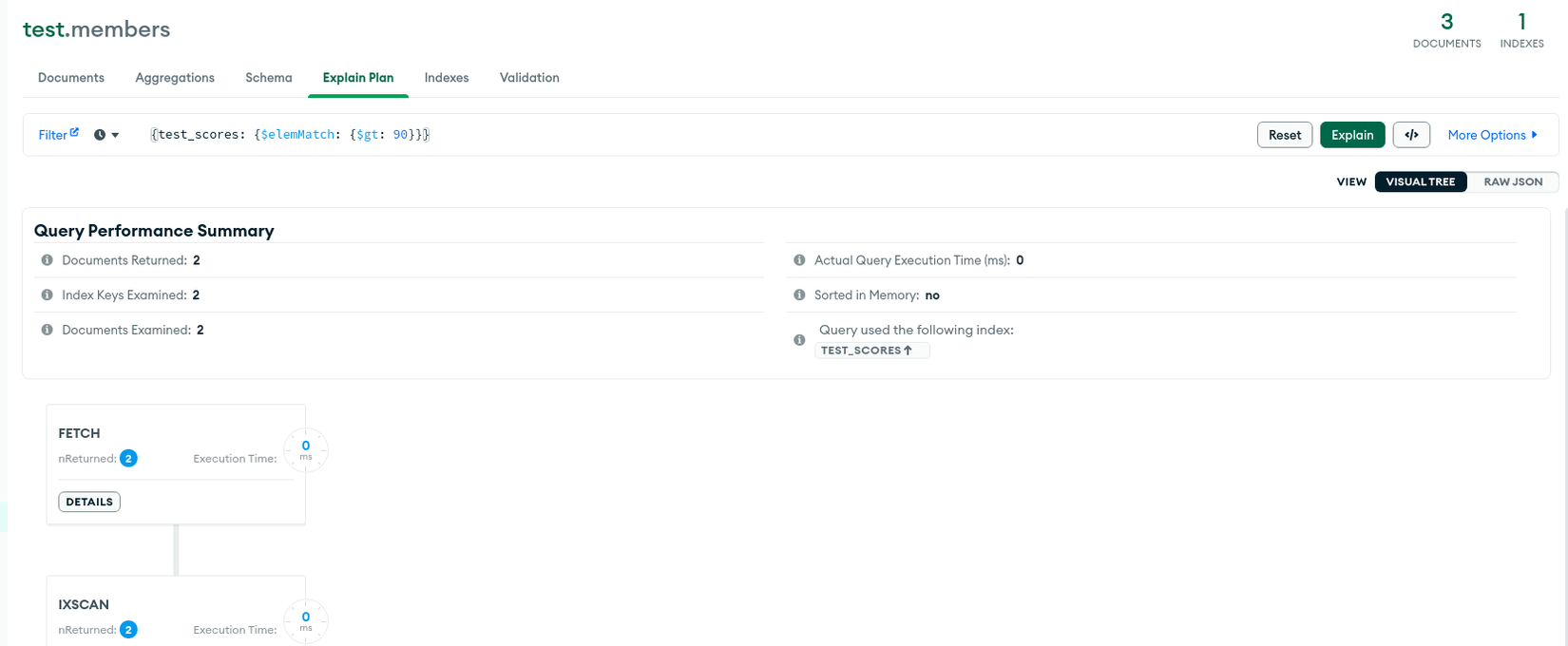
Giả sử chúng ta có collection Member chứa thông tin user và số điểm đã làm được cho các bài test mà họ tham gia.
db.members.insertMany( [
{
"name": "John Doe",
"test_scores": [ 88, 97 ]
},
{
"name": "John Wick",
"test_scores": [ 62, 73 ]
},
{
"name": "Anna Belle",
"test_scores": [ 92, 89 ]
}
] )
Tiến hành tạo Index với field test_scores bằng lệnh db.members.createIndex({ test_scores: 1 }) sẽ cho chúng ta kết quả Index được lưu như hình dưới:

Có thể thấy được các element bên trong array của document sẽ lần lượt được tạo Index. Vì thế một document có thể được nhiều Index key trỏ tới và đó là lý do tại sao nó được đặt tên là Multikey Index.
Tiến hành query để kiểm tra kết quả:
6.3.1 Index với Embedded Field trong Arrays
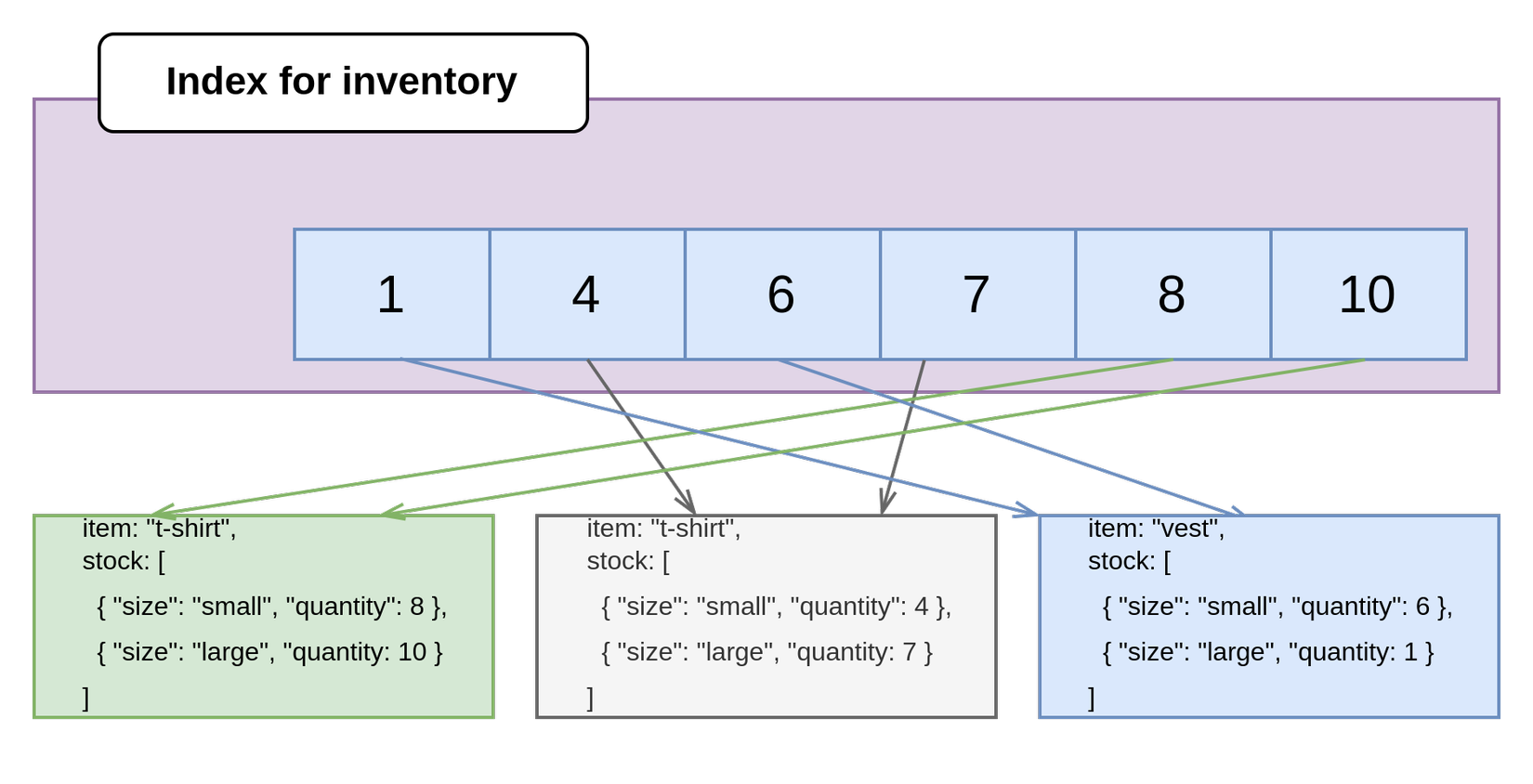
Nếu element bên trong Array là embedded document thì chúng ta cũng có thể tạo Index và nó sẽ được lưu trữ tương tự như ở trên. Chúng ta sẽ lấy ví dụ từ tài liệu MongoDB Official
db.inventory.insertMany( [
{
"item": "t-shirt",
"stock": [
{
"size": "small",
"quantity": 8
},
{
"size": "large",
"quantity": 10
},
]
},
{
"item": "sweater",
"stock": [
{
"size": "small",
"quantity": 4
},
{
"size": "large",
"quantity": 7
},
]
},
{
"item": "vest",
"stock": [
{
"size": "small",
"quantity": 6
},
{
"size": "large",
"quantity": 1
}
]
}
] )
Dễ dàng thấy được collection inventory có field stock chứa embedded field size và quantity. Ví dụ yêu cầu chúng ta cần là query ra các item có quantity < 5 để tiến hành nhập thêm hàng.
Khi đó chúng ta có thể tăng tốc query bằng cách tạo index như sau:
inventory_schema.createIndex( { "stock.quantity": 1 } )
Index sao khi được tạo sẽ lưu trữ dữ liệu theo giá trị tăng dần của quantity:
Các bạn có thể tiến hành thử lệnh sau để kiểm tra tốc độ khi có và khi không có index:
db.inventory.find(
{
"stock.quantity": { $lt: 5 }
}
)
6.3.2 Multikey Index Bounds
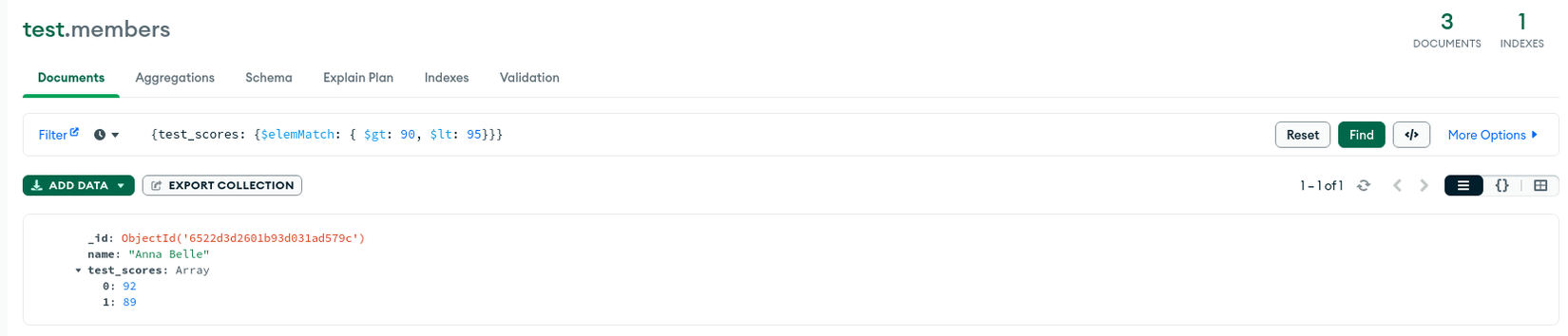
Có một điều cần lưu ý khi dùng Multikey Index là Multikey Index Bounds, nếu sử dụng không cẩn thận sẽ dẫn đến các lỗi không mong muốn. Chúng ta sẽ dùng lại ví dụ về collection members ở trên với yêu cầu liệt kê những user có test_scores nằm trong khoảng 90 đến 95. Nếu không cẩn thận chúng ta sẽ query { test_scores: { $gte: 90, $lte: 95 } }:
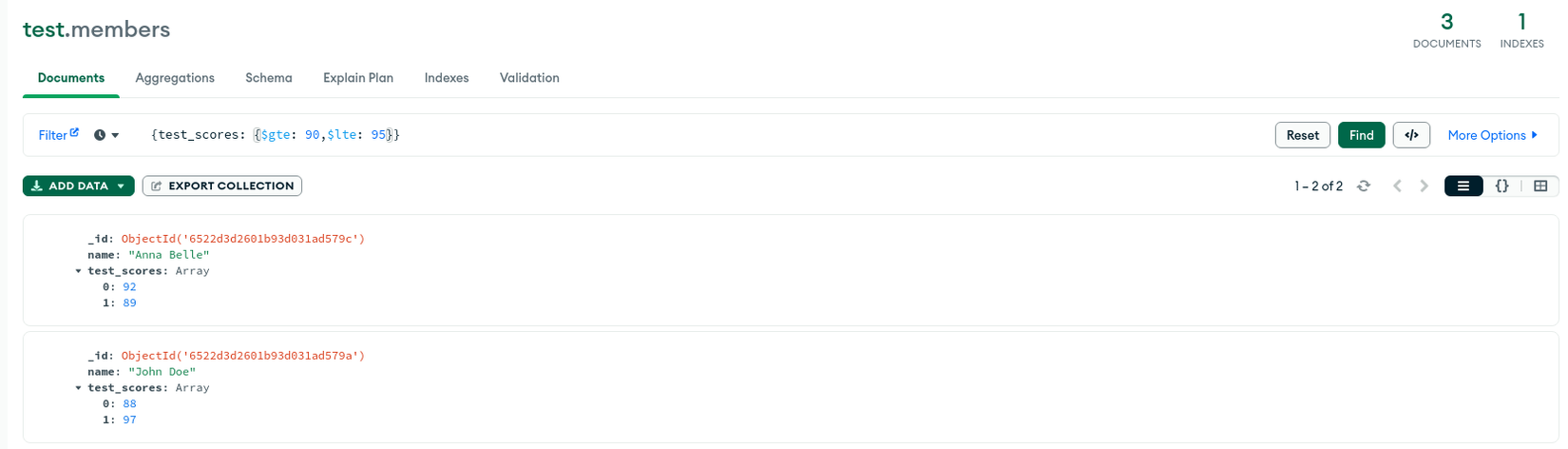
Rõ ràng khi nhìn vào kết quả user John Doe không thỏa điều kiện nhưng vẫn hiển thị ra. Nguyên nhân là do Index bounds được chúng ta sử dụng không đúng.
Index bounds define the range of index values that MongoDB searches when using an index to fulfill a query.
Với câu query ở trên chúng ta sẽ tạo ra Index bounds như sau:
[ [ 90, Infitity ] ]: thỏa điều kiện nếu ít nhất một element trong array >= 90[ [ -Infitity, 95 ] ]: thỏa điều kiện nếu ít nhất một element trong array <= 95
Và 2 điều kiện trên sẽ tồn tại song song chứ không được gộp lại, làm cho user John Doe vẫn được hiển thị (do đáp ứng 88 < 95 hay 97 > 90).
Để khắc phục vấn đề trên, chúng ta cần phải làm gì đó để 2 điều kiện trên gộp lại với nhau. Cách này gọi là Intersect the multikey index bounds.
MongoDB can intersect the multikey index bounds if an
$elemMatchoperator joins the query predicates.
$elemMatch chính là thứ chúng ta cần để giải quyết trường hợp này. Khi có nó trong câu query sẽ giúp gộp các index bounds lại với nhau. Cập nhật lại câu query thành { test_scores: { $elemMatch: { $gte: 90, $lte: 95 } } }, kết quả thu được sẽ đúng như những gì chúng ta cần:
Trên đây là 3 loại Index thông dụng mà chúng ta hay dùng, bên cạnh đó vẫn còn nhiều loại Index khác như: Text Index (sẽ có trong bài viết về Full Text Search sắp tới), Hashed Index, Wildcard Index và Geospatial Index mà chúng ta sẽ tìm hiểu trong các bài viết tiếp theo. Tiếp theo chúng ta sẽ cùng đi tới các syntax thường dùng để khi cần có thể tham khảo nhanh.
7. Index Properties 📖
Các phần trên chúng ta đã tìm hiểu về các loại index thông dụng, phần này chúng ta sẽ tìm hiểu về Index Properties. Nó có thể tác động đến các query planner sử dụng index cũng như documents được index sẽ được lưu như thế nào.
Chúng ta có 6 loại index properties trong MongoDB:
- Partial Indexes: chỉ index document nếu đáp ứng điều kiện lúc tạo index.
- Sparse Indexes: chỉ index document nếu field được chỉ định tồn tại.
- TTL Indexes: khi áp dụng index này document sẽ tự động bị xóa sau khoảng thời gian. Tuy nhiên chỉ áp dụng với field dạng date.
- Unique Indexes: field nào được đánh unique index thì khi insert không được phép trùng. Trong trường hợp collection đã có dữ liệu và field cần đánh unique index tồn tại dữ liệu trùng thì khi tạo unique index sẽ báo lỗi.
- Case Insensitive Indexes: thường dùng cho query bỏ qua phân biệt chữ hoa và chữ thường.
- Hidden Indexes: tạm thời ẩn các index chỉ định. Thường dùng để kiểm tra performance xem việc dùng index có hiệu quả hay không.
Trong 6 loại kể trên thì 4 loại đầu tiên mình thường sử dụng. Chúng ta sẽ cùng tìm hiểu chi tiết hơn về 4 loại trên.
7.1 Sparse Indexes
Spare Indexes thường được dùng để giảm dung lượng index, tránh index các document không cần thiết với project requirement.
Ví dụ dự án của chúng ta có collection sau:
class Car {
model: string;
owner: User | null;
}
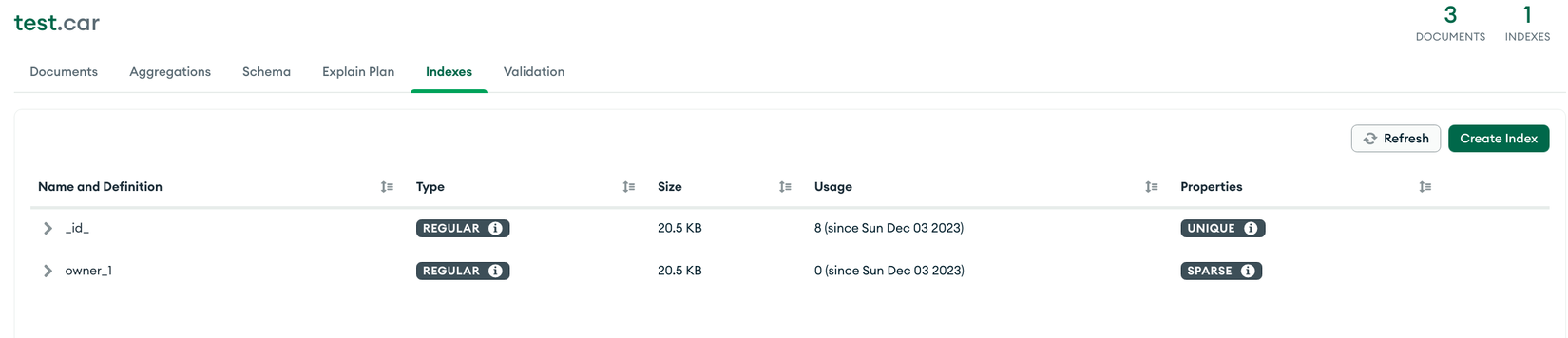
Và yêu cầu chỉ gần query các car đã có chủ sở hữu hay owner không tồn lại. Lúc này Sparse Indexes sẽ phát huy tác dụng, chúng ta sẽ tạo với syntax sau:
car_schema.index({ owner: 1 }, { sparse: true });
Khi đó nếu chúng ta insert dữ liệu, các index sẽ được tạo tương ứng:
db.car.insertMany( [
{ "model": "Aventador", "owner": "John Doe" }, // ✅
{ "model": "Urus" }, // ❌
{ "model": "Huracan", "owner": null } // ✅ Chỉ cần field có tồn tại, dù là `null` vẫn được index
] )
Với trường hợp
owner: nullvẫn sẽ tạo index vì như đã đề cập, Sparse Index sẽ index khi field tồn tại bất kể giá trị của nó là gì.
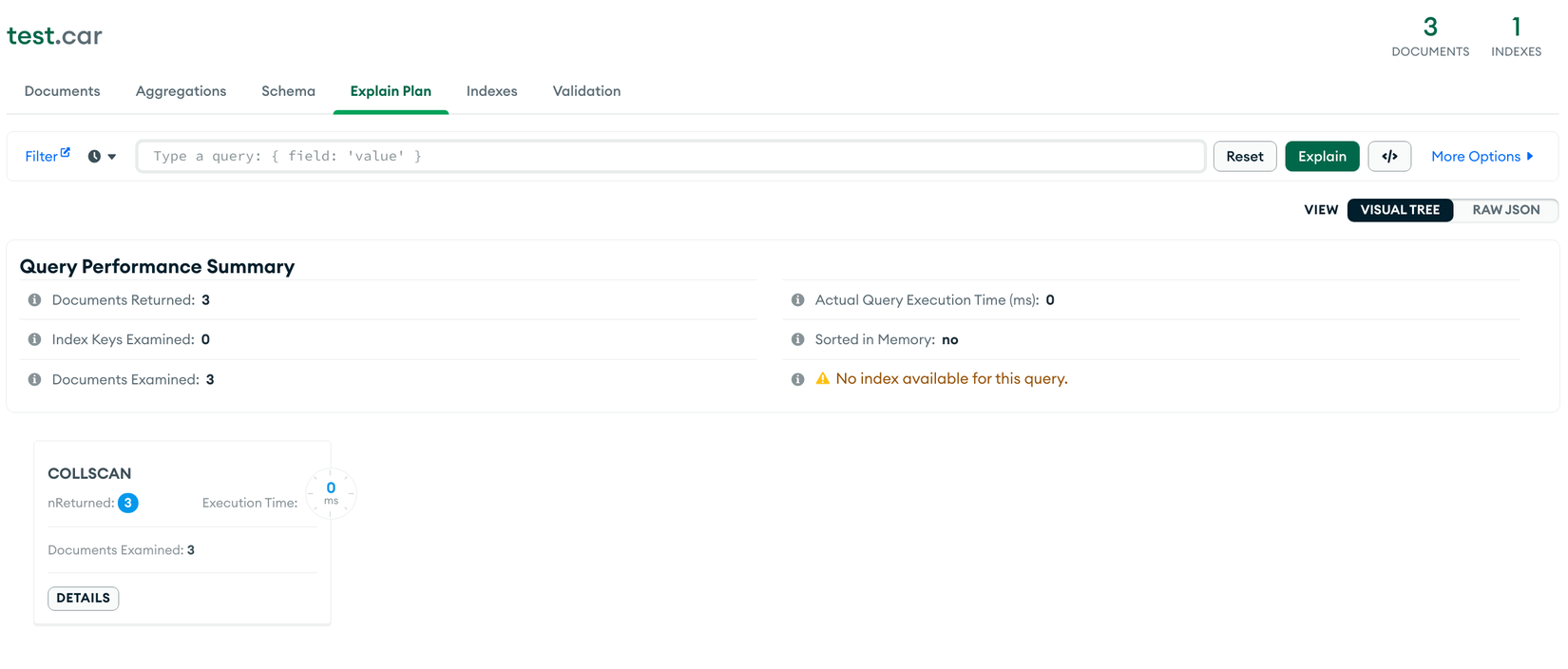
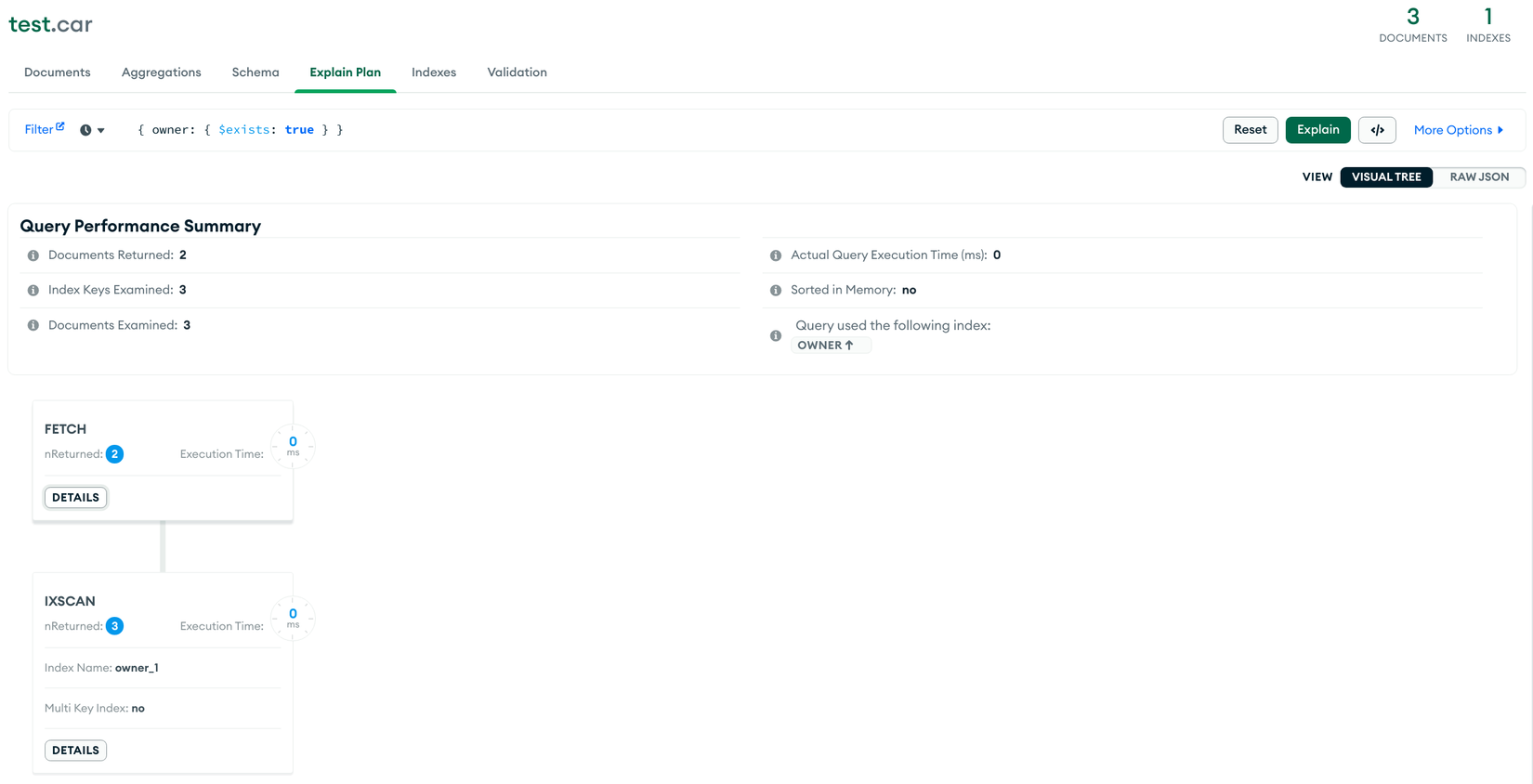
Để query với Sparse Index thì query planner cần phải liên quan đến sự tồn tại của field được index, ví dụ:
db.car.find() // ❌
db.car.find({ owner: { $exists: true } }) // ✅
db.car.find().sort({ owner: 1 }) // ❌
db.car.find().sort({ owner: 1 }).hint({ owner: 1 }) // ✅ Chỉ định dùng index,
// tuy nhiên giá trị trả về sẽ chỉ có dữ liệu được index
- TH1: ❌
![image.png]()
- TH2: ✅
![image.png]()
- TH3: ❌
![image.png]()
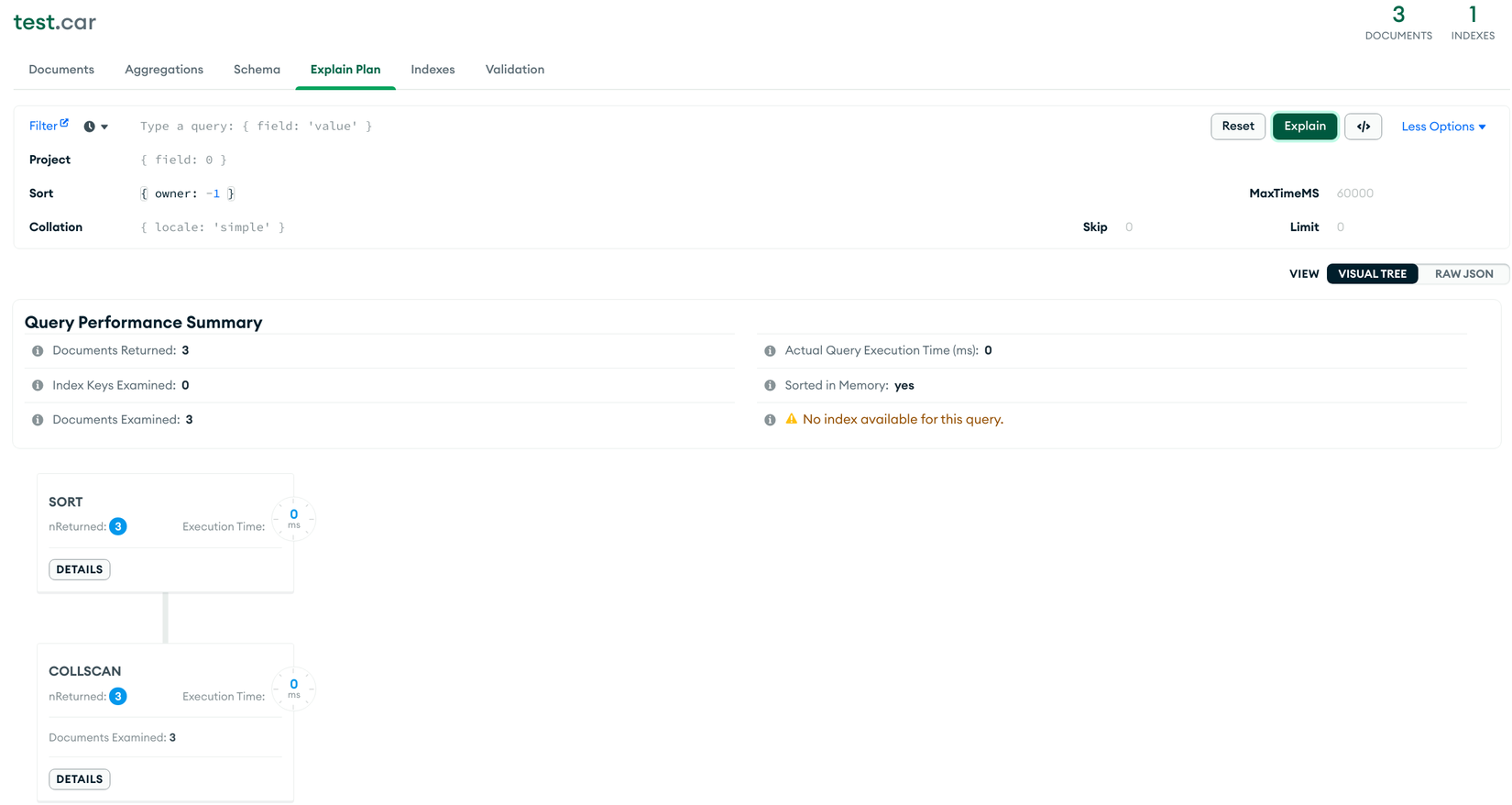
Tuy nhiên trong tài liệu của MongoDB chúng ta được prefer dùng Partial Indexes thay cho Sparse Indexes. Để tìm hiểu lý do chúng ta sẽ đến với phần tiếp theo.
7.2 Partial Indexes
By indexing a subset of the documents in a collection, partial indexes have lower storage requirements and reduced performance costs for index creation and maintenance. - MongoDB Official
Về lợi ích thì nó tương tự như Sparse Indexes là giúp tối ưu về lưu trữ và hiệu năng khi tạo và maintain index. 2 lý do mà nó được prefer hơn là:
- Kiểm soát tốt hơn những tài liệu nào được index.
- Như là 1 superset của Sparse Indexes.
Với ví dụ ở Sparse Indexes chúng ta có thể viết lại như sau:
car_schema.index(
{ owner: 1 },
{ partialFilterExpression: { owner: { $exists: true } } }
);
Hoặc hơn nữa là index field này nhưng check điều kiện bằng field khác
car_schema.index(
{ model: 1 }, // ⏪️ Index `model`
{ partialFilterExpression: { owner: { $exists: true } } } // ⏪️ Check điều kiện `owner`
);
Tương tự như ở Sparse Indexes, khi chúng ta query thì phải liên quan tới điều kiện khi tạo Partial Indexes.
Có một số Restrictions chúng ta cần lưu ý khi sử dụng:
partialFilterExpressionoption không thể dùng vớisparseoption._idindexes không thể là Partial Indexes.- Shard key indexes cũng không thể là Partial Indexes.
7.3 TTL Indexes
TTL Indexes chỉ định một field dạng date và thời gian expire, MongoDB sẽ tự động xóa document sau khoảng thời gian đã khai báo. Việc này thông thường sẽ hữu ích cho chúng ta trong việc xóa các dữ liệu không cần dùng tới sau một khoảng thời gian nhất định như logs, sessions,...
Ví dụ chúng ta có document sau:
db.userBehaviorLogs.insertMany( [
{ userId: "65166f3caf82130f7043c4b9",
action: "view",
target: "product",
createdAt: "2023-12-03T08:00:00" },
] )
Để document tự động xóa sau 1 ngày chúng ta sẽ tạo TTL Indexes như sau:
user_behavior_logs_schema.index({ createdAt: 1 }, { expireAfterSeconds: 24 * 3600 })
Index được tạo sẽ có dạng:
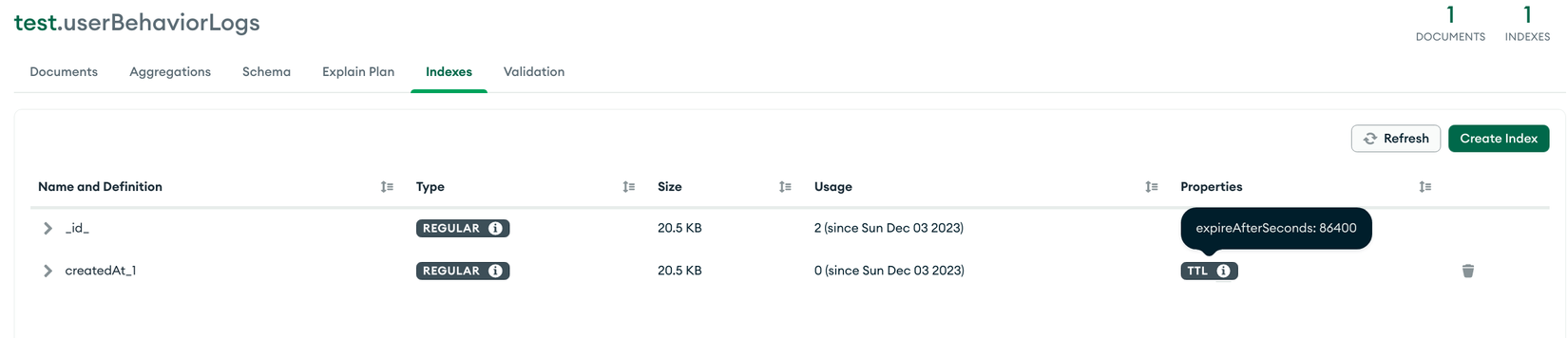
Các bạn thử tạo thời gian ngắn hơn để kiểm tra xem có tự động xóa không nhé, nếu không hoạt động thì xem lại múi giờ của máy/docker đang chạy MongoDB.
Cơ chế xóa
A background thread in
mongodreads the values in the index and removes expired documents from the collection.
Sẽ có một background thread được chạy mỗi 60 giây để kiểm tra và xóa các document expire, và vì 60 giây mới chạy một lần nên đôi lúc sẽ có delay trong khoảng đó để document bị xóa đi.
Một số lưu ý:
- Nếu field được TTL Indexes có dạng Array Date thì element có giá trị thấp nhất sẽ được dùng để kiểm tra.
- TTL Indexes là Single-Field Indexes nên sẽ không apply cho Compound Indexes, nếu cố tình thêm options
expireAfterSecondsnó sẽ bị ignore. _idfield không support TTL Indexes.- Không thể thay đổi
expireAfterSecondsbằngcreateIndex, nếu muốn thì phải dùngcollMod. - Nếu 1 non-TTL-single-field index (index không phải TTL Indexes) đã được tạo cho field đó, thì không thể tạo thêm TTL Indexes cho nó. Bắt buộc phải chuyển từ non-TTL-single-field index sang TTL index. Tham khảo cách chuyển ở đây.
- Nếu có nhiều document bị expire trong cùng một điểm có thể ảnh hưởng để hiệu năng.
7.4 Unique Indexes
Như tên gọi của nó, giúp chúng ta hạn chế insert các document trùng nhau dựa theo các field chỉ định. Tuy nhiên Unique Indexes không chỉ áp dụng cho Single-Field Indexes mà còn có thể dùng cho Compound Index, Multiple Index hoặc Compound Multikey Index,...
Xét ví dụ sau từ tài liệu Mongo:
db.collection.insertMany( [
{ _id: 1, a: [ { loc: "A", qty: 5 }, { qty: 10 } ] }
] )
Chúng ta sẽ tạo Compound Multikey Indexes
db.collection.createIndex( { "a.loc": 1, "a.qty": 1 }, { unique: true } )
Các giá trị sau sẽ insert được:
db.collection.insertMany( [
{ _id: 2, a: [ { loc: "A" }, { qty: 5 } ] },
{ _id: 3, a: [ { loc: "A", qty: 10 } ] }
] )
Còn các giá trị này sẽ không:
db.collection.insertMany( [
// ❌ Lỗi do `{ qty: 5 }` có loc: null, trùng ở record có _id=2
{ _id: 4, a: [ { loc: "B" }, { qty: 5 } ] }
// ❌ Lỗi do `{ loc: "A", qty: 5 }` trùng record có _id=1
{ _id: 5, a: [ { loc: "B" }, { loc: "A", qty: 5 } ] }
] )
Kết luận 📝
Vậy là chúng ta đã tìm hiểu qua về các loại Indexes có trong MongoDB và cách thức hoạt động của nó behind the scene. Chúng ta cũng biết về các options (index properties) mà chúng ta có thể apply khi tạo Indexes để đáp ứng các nhu cầu về tối ưu về mặt dữ liệu.
Cảm ơn các bạn đã giành thời gian đọc bài viết, hy vọng sẽ giúp ích cho các bạn trong quá trình triển khai dự án. Nếu có thắc mắc gì có thể comment bên dưới để mọi người cùng thảo luận 😁.
Tài liệu tham khảo 🔍
- What is a database index?: Examples of indices (no date) MongoDB. Available at: https://www.mongodb.com/basics/database-index (Accessed: 24 July 2023).
- Indexes (no date) Indexes - MongoDB Manual. Available at: https://www.mongodb.com/docs/manual/indexes/ (Accessed: 24 July 2023).
- More, G. (2020) How mongodb store indexes, MongoDB Developer Community Forums. Available at: https://www.mongodb.com/community/forums/t/how-mongodb-store-indexes/11919/4 (Accessed: 07 December 2023).
- https://kipalog.com/posts/Nghe-thuat-index-MongoDB--5-ke-sach-co-the-cac-ha-chua-biet (Accessed: 24 July 2023). Unavailable at 07 December 2023.
- Quan (2023) SỬ dụng index Trong Database Như Thế Nào Cho Hiệu quả?, Viblo. Available at: https://viblo.asia/p/su-dung-index-trong-database-nhu-the-nao-cho-hieu-qua-4P856q69lY3 (Accessed: 07 December 2023).
Change log 📓
- December 07, 2023: Init document
All rights reserved
