Setup Boilerplate cho dự án NestJS - Phần 9: Các chiến thuật Pagination với MongoDB 📖
Bài đăng này đã không được cập nhật trong 2 năm
Đây là bài viết nằm trong Series NestJS thực chiến, các bạn có thể xem toàn bộ bài viết ở link: https://viblo.asia/s/nestjs-thuc-chien-MkNLr3kaVgA
Có bao giờ trong quá trình tự mình phát triển hoặc truy cập các website các bạn nhận thấy rằng việc di chuyển qua các trang chậm lại khi số trang ngày càng lớn 🧐 hay khi chuyển trang thì item ở trang trước bị lặp lại thêm lần nữa ở trang sau.

Đó là vấn đề mà đa số các website gặp phải khi tiến hành pagination một cách không hiệu quả 😤. Hôm nay chúng ta sẽ cùng tìm hiểu đôi chút về vấn đề này nói chung và cụ thể dùng trong MongoDB nói riêng.
Đặt vấn đề 📜
Pagination là chức năng mà các bạn thường thấy trong hầu hết các ứng dụng, giúp chia số lượng data trả về thành nhiều trang giúp hạn chế payload cũng như tăng trải nhiệm của người dùng.
1️⃣ Nguyên nhân của vấn đề đầu tiên mà mình đề cập ở trên là do khi chúng ta tiến hành dùng skip trong MongoDB để di chuyển đến các trang sau, nó sẽ không vì chúng ta nhập vào skip: 10000, limit: 10 mà bỏ qua 10000 item trước đó và lấy 10 item, thay vào đó nó sẽ lấy ra luôn cả 10000 item đó kèm với 10 item nữa là 10010 item.
Lấy ví dụ ở page Quản lí Flash card của admin mỗi trang chúng ta trả về 20 Flash card. Quá trình chuyển trang diễn ra như sau:
- Ở trang 1 query sẽ có dạng
find().skip(0).limit(20), database sẽ tìm 20 documents và trả về 20 documents cho chúng ta. - Khi chuyển qua trang 2 query sẽ thay đổi thành
find().skip(20).limit(20), database sẽ tìm 40 documents và trả về 20 documents cho chúng ta. - Tương tự khi chuyển đến trang 1000 query sẽ là
find().skip(20000).limit(20), database sẽ tìm 20020 documents và trả về 20 documents.
✴️ Đó chính là cách skip và limit hoạt động trong MongoDB (offset và limit trong SQL cũng sẽ tương tự). Nhìn qua thì các bạn cũng đã hiểu tại sao kết quả ở các trang sau lại tốc độ chậm hơn các trang trước.
2️⃣ Nguyên nhân của vấn đề thứ hai liên quan tới tính consistency, ví dụ admin đang query dữ liệu ở trang 1 như trên và được sort theo vocabulary (giả sử vocabulary là unique với tất cả user), trong kết quả trả về Flash card thứ 20 là Apple. Tuy nhiên trong lúc đó có một user nào đó thêm vào một Flash card mới có vocabulary là Above và nó làm cho Apple bị đẩy sang vị trí thứ 21 (vì về mặt thứ tự thì Above sẽ đứng trước Apple), do đó khi admin chuyển sang trang thứ 2 thì Apple lại xuất hiện thêm một lần nữa. Tương tự với trường hợp sửa hoặc xóa cũng có thể làm cho dữ liệu hiển thị không được đồng nhất.
Thông tin package 📦️
- Mongodb version 6
- Mongoose: ^7.0.3
Source code của phần này sẽ nằm ở branch part-9-pagination-in-mongo-db, các bạn có thể tải về ở đây
Lý thuyết 📚
Chúng ta sẽ cùng điểm sơ qua các cách pagination thông dụng hiện nay.
1. Offset, limit pagination
Đây là cách dùng phổ biến trong đa số các website, dùng skip, limit (hayoffset, limit trong SQL) để phân trang. Chúng ta vẫn hay thường dùng như bên dưới trong MongoDB:
// Cách 1️⃣: Offset, limit pagination
const flash_cards = await this.flash_cards_repository.find()
.sort({ _id: 1 }).skip(20).limit(20)
// Hoặc
const flash_cards = await this.flash_cards_repository.find({},
'projection', { sort: { _id: 1 }, skip: 20, limit: 20 })
Ưu điểm ✅
- Dễ triển khai: Back-end có thể đọc docs và dùng ngay mà không cần phải chỉnh sửa. Front-end cũng dễ tích hợp vào UI.
- Dễ đọc hiểu: khi nhìn vào có thể dễ dàng hiểu ngay.
Nhược điểm 📛
Thật ra nếu như các bạn đọc tài liệu chính gốc từ MongoDB sẽ thấy có nhắc đến vấn đề này:
The skip() method requires the server to scan from the beginning of the input results set before beginning to return results. As the offset increases, skip() will become slower.
- Hiệu năng kém: cơ chế hoạt động
skiplà lấy tất cả các document được trả về từ kết quả của chaining method trước đó (ở trên làfind) và scan từ đầu cho đến khi đến vị trískipsẽ trả về số lượng documents tương ứng chứ không phải nhập vào 20 làskipchỉ scan 20 documents. - Dữ liệu không nhất quán: như đã đề cập ở phần trên, khi admin đang gọi API nếu có user thao tác add hoặc delete thì dữ liệu trả về có thể bị duplicate (do add) hoặc hiển thị thiếu (do delete).
2. Keyset pagination (Cursor-based pagination)
Về mặt khái niệm thì Keyset pagination dùng page trước đó để trả về page tiếp theo, hay nói cách khác là dùng item cuối cùng để trả về page tiếp theo sau item đó.
Tùy theo các property được sort mà chúng ta sẽ có cách dùng tương ứng với các property đó. Ví dụ sort theo _id MongoDB thì dùng _id của item cuối cùng của trang trước kết hợp với limit và FilterQuery (hay where trong SQL).
Có thể các bạn chưa biết: MongoDB ObjectId là một cấu trúc 12 byte dữ liệu bao gồm:
- 4-byte biểu thị số giây kể từ Unix epoch.
- 5-byte giá trị ngẫu nhiên được tạo một lần cho mỗi quá trình. Giá trị ngẫu nhiên này là unique cho machine và process.
- 3-byte machine identifier.
- 2-byte process id.
- 3-byte incrementing counter, được khởi tạo thành một giá trị ngẫu nhiên.
Do thành phần của nó có liên quan tới timestamp nên chúng ta có thể tiến hành sort ObjectId.
Ví dụ ở page trước chúng ta có item thứ 20 có _id=64ab87fab9e86239671aded5 thì chúng ta lấy 20 items tiếp theo như sau:
const flash_cards = await this.flash_cards_repository
.find({ _id: { $gt: ObjectId('64ab87fab9e86239671aded5') } })
.limit(20)
// Hoặc
const flash_cards = await this.flash_cards_repository
.find({ _id: { $gt: ObjectId('64ab87fab9e86239671aded5') } })
'projection', { limit: 20 })
Ưu điểm ✅
- Hiệu tăng cao: do không còn dùng
skipnên sẽ không cần scan quá nhiều document.
Nhược điểm 📛
- Triển khai phức tạp: nếu chúng ta sort bằng property khác
_idhoặc nhiều hơn 2 property thì sẽ khó khăn trong việc triển khai do cần phải tiến hành sort, đến phần ví dụ ở dưới chúng ta sẽ nói rõ hơn. - Không thể truy cập ngẫu nhiên vào một trang bất kỳ: vì page tiếp theo được lấy dữ liệu từ item của page trước đó nên nếu chúng ta muốn vào trang 30 thì phải cần trang 29, tương tự trang 29 cần 28,...
Thực hành 💡
Để làm rõ hơn chúng ta sẽ lấy ví dụ với dự án Flash card đang làm, ứng dụng cả 2 cách để kiểm tra xem độ phức tạp trong cách triển khai cũng như so sánh về tốc độ giữa các phương thức pagination. Giúp các bạn có cái nhìn tổng quan về 2 phương pháp pagination trên.
1. Chuẩn bị 📃
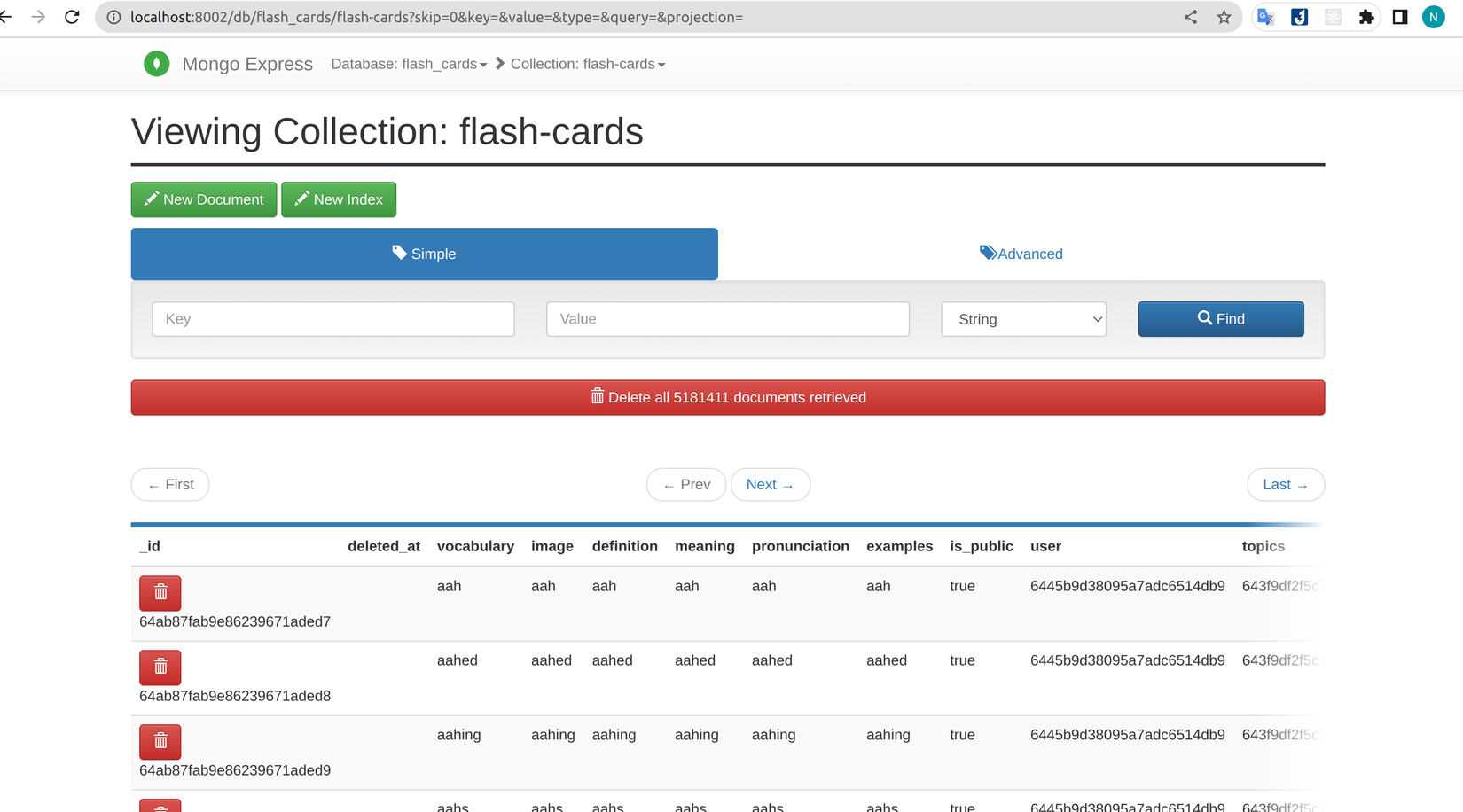
Để thuận tiện cho việc test mình sẽ tải về file JSON chứa danh sách khoảng 370.000 từ vựng và tạo API seed Flash card dựa vào số từ vựng đó. Sau khi có API chúng ta sẽ gọi để seed dữ liệu lên khoảng 5 triệu flash-card để dễ test.
2. Triển khai kiểm tra hiệu năng 📊
Skip-limit pagination
Chúng ta sẽ bắt đầu với cách pagination đầu tiên, chỉnh sửa lại method findAll trong FlashCardsService. Để ví dụ liên quan thực tế hơn, mình sẽ kết hợp sort bằng 2 field là vocabulary và _id vì chúng ta muốn dữ liệu được hiển thị phải theo thứ tự.
Lưu ý 1: Mặc dù có thể thấy field
_idđã tự động sort (do cấu trúc của nó có timestamp) khi chúng ta insert data, nhưng theo như đa số tài liệu mình đọc khuyến khích nên thêm sort cho_idđể đảm bảo thứ tự.
Lưu ý 2: Khi thêm sort vào sẽ ảnh hưởng rất nhiều đến tốc độ query nếu như số trang quá lớn và không dùng index.
...
export class FlashCardsService extends BaseServiceAbstract<FlashCard> {
...
async findAll(
filter: object,
options: { offset: number; limit: number },
): Promise<FindAllResponse<FlashCard>> {
return await this.flash_cards_repository.findAll(filter, {
skip: options.offset,
limit: options.limit,
sort: { vocabulary: 1, _id: 1 },
});
}
...
Thêm vào pagination ở FlashCardsController nếu bạn nào chưa thêm ở các bài trước. Ngoài ra, thêm vào LoggingInterceptor (đã được viết ở các bài trước) để dùng cho việc tính thời gian xử lý request.
import { ApiDocsPagination } from 'src/decorators/swagger-form-data.decorator';
...
export class FlashCardsController {
...
@Get()
@UseInterceptors(LoggingInterceptor)
@ApiDocsPagination(FlashCard.name)
findAll(
@Query('offset', ParseIntPipe) offset: number,
@Query('limit', ParseIntPipe) limit: number,
) {
return this.flash_cards_service.findAll({}, { offset, limit });
}
Tiến hành gọi API để kiểm tra xem thời gian xử lí request là bao lâu:
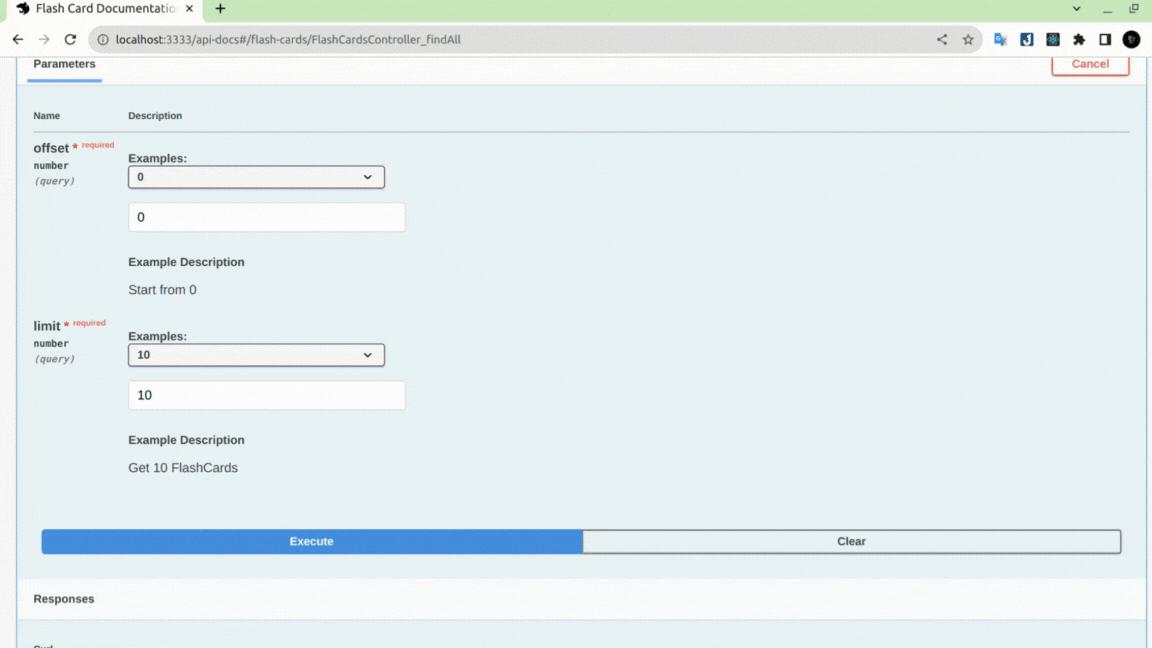
Có thể thấy được khi chúng ta dùng skip=0 thì sẽ mất khoảng 3813ms để lấy 10 items, nhưng khi skip=4000000 thì thời gian tăng lên gấp hơn 3 lần 12469ms mặc dù số lượng vẫn là 10 items. Các bạn có thể thử test với các giá trị khác để kiểm chứng xem có phải khi giá trị skip càng lớn thì tốc độ sẽ càng chậm hay không.
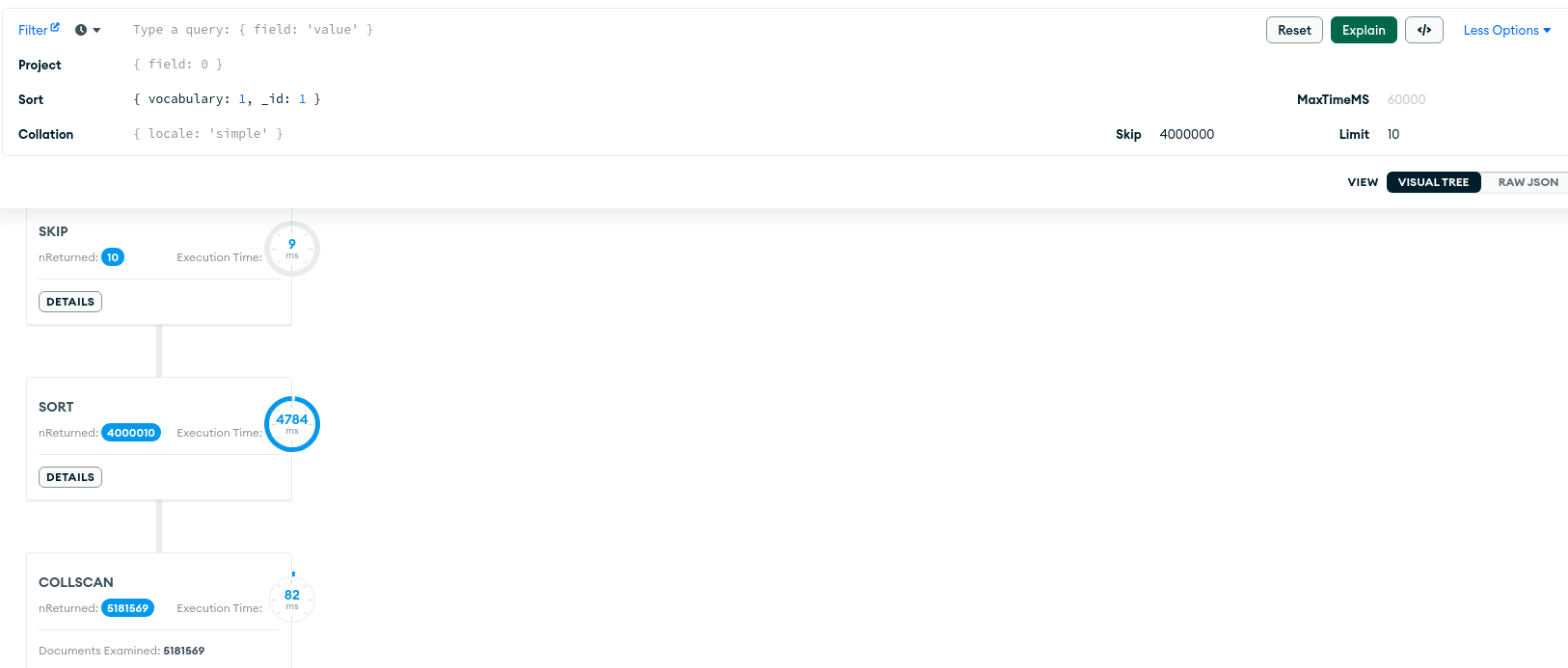
Giải thích thêm một tí về một phần nguyên nhân làm cho nó chậm đi là vì sort. Ví dụ
skip=4000000vàlimit=10thì nó sẽ phải tốn thời gian để lấy ra toàn bộ document (5181569 items) sau đó tiến hành sort và return4000010items, sau đó mới lấy ra10item và trả về.
Vậy liệu keyset pagination có đem lại hiệu quả tốt hơn không, chúng ta cùng đến với phần tiếp theo.
Keyset pagination (cursor-based pagination)
Chúng ta sẽ tạo thêm API findAllUsingKeysetPagination để cùng kiểm chứng vấn đề trên. Dựa theo lý thuyết thì trong trường hợp này chúng ta sort với 2 fields là vocabulary và _id nên khi tiến hành paginate từ trang thứ 2 trở đi sẽ cần vocabulary cuối cùng của trang trước và id của nó. Tiến hành triển khai như bên dưới:
...
export class FlashCardsService extends BaseServiceAbstract<FlashCard> {
...
async findAllUsingKeysetPagination(
filter: object,
{ last_id, last_vocabulary }: { last_vocabulary: string; last_id: string },
options: { limit: number },
): Promise<FindAllResponse<FlashCard>> {
const pagination_query = {};
if (last_id && last_vocabulary) {
pagination_query['$or'] = [
{
vocabulary: {
$gt: last_vocabulary,
},
},
{
vocabulary: last_vocabulary,
_id: {
$gt: last_id,
},
},
];
}
return await this.flash_cards_repository.findAll(
pagination_query,
{
limit: options.limit,
sort: { vocabulary: 1, _id: 1 },
},
);
}
Giải thích:
-
Sở dĩ có sự xuất hiện của
$orvới 2 điều kiện bên trong là dovocabularycủa các user có thể bị trùng nhau. Nếu chỉ có điều kiệnvocabulary: { $gt: last_vocabulary }thì sẽ làm các vocabulary giống nhau nhưng nằm ở trang sau sẽ bị miss. Ví dụ có 2 từ "above" của 2 user khác nhau và 1 từ nằm ở vị trí 10, từ còn lại 11, quá trình gọi pagination sẽ diễn ra như sau:- Bước 1: Khi gọi 10 từ đầu tiên sẽ có "above" thứ 10 xuất hiện ở page 1.
- Bước 2: Dùng
last_vocabulary="above"để gọi tiếp trang tiếp theo. Khi check điều kiện trên sẽ bỏ qua từ "above" vị trí 11 và bắt đầu với từ ở vị trí 12.
=> Do đó, điều kiện thứ 2 được sinh ra giúp chúng ta lấy ra các từ bị trùng nhưng chưa được hiển thị.
-
Có cách dùng khác là rút gọn thành
{ vocabulary: { $gte: last_vocabulary }, _id: { $gt: last_id } }, nhưng cách này không hiệu quả sẽ dẫn đến lỗi do các từ thêm vào sau có_idlớn hơn nhưng vocabulary có thể xếp trước các từ trước đó.
Tiến hành khởi tạo API với FlashCardsController:
Lưu ý ở đây để lấy ví dụ nên mình mới tạo thêm API, trong dự án thực tế các bạn không nên tạo các API không cần thiết để tránh lặp lại code.
...
export class FlashCardsController {
...
@Get('keyset-pagination')
@UseInterceptors(LoggingInterceptor)
findAllUsingKeyset(
@Query('last_id') last_id: string,
@Query('last_vocabulary') last_vocabulary: string,
@Query('limit', ParseIntPipe) limit: number,
) {
return this.flash_cards_service.findAllUsingKeysetPagination(
{},
{ last_id, last_vocabulary },
{ limit },
);
}
Gọi API chúng ta vừa tạo để kiểm tra tốc độ xử lý có cải thiện hơn không:
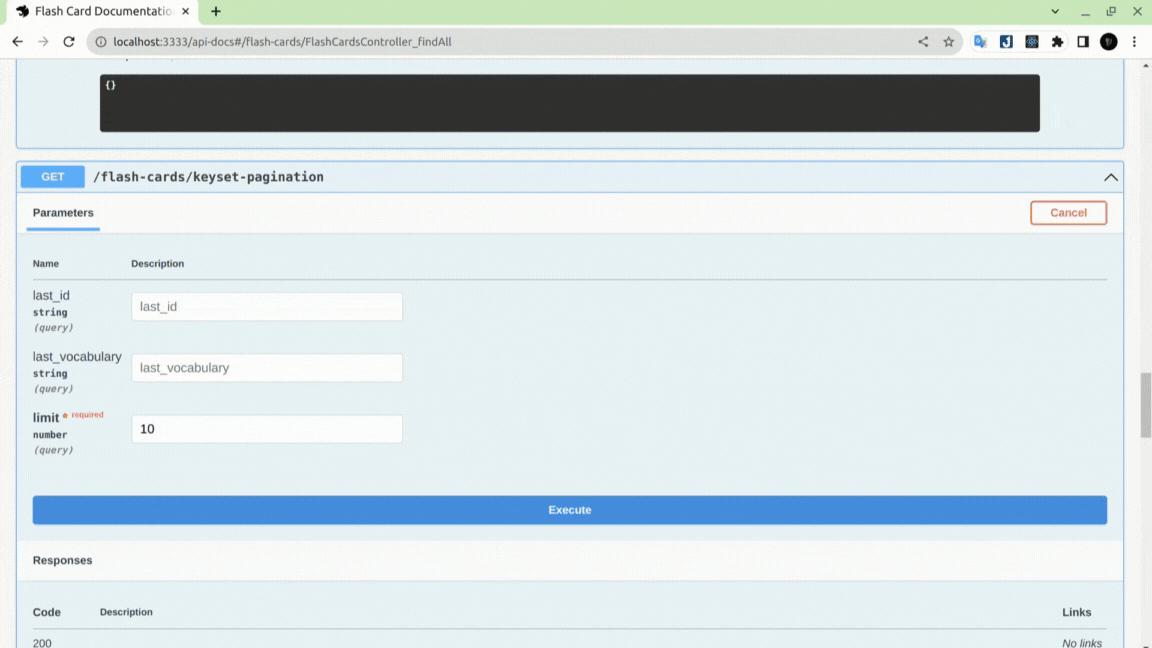
Từ ảnh trên chúng ta có thể thấy được tốc độ khi gọi page đầu tiên (giá trị last_id, last_vocabulary rỗng) và ở page thứ 400.000 (4.000.000/10) không có sự trên lệch đáng kể.
Vậy là từ 2 bài test trên chúng ta đã thấy được sự vượt trội của keyset pagination so với skip-limit pagination, tuy nhiên chúng ta cũng thấy được việc triển khai keyset pagination sẽ hơi phức tạp. Chúng ta sẽ cùng đi tìm hiểu sâu hơn cách dùng nó trong dự án thực tế ở phần tiếp theo.
3. Cải tiến 🪵🪚🪑
Ở phần trên chúng ta so sánh điều kiện trong keyset pagination bằng pagination_query ở FilterQuery của method find. Trong thực tế đa số các API cũng sẽ có các query của riêng nó để đáp ứng yêu cầu dự án, nên chúng ta cần kết hợp cả 2 query đó lại. Ví dụ API của chúng ta cho phép admin lấy Flash card bằng cách search theo vocabulary:
...
async findAllUsingKeysetPagination(...): Promise<FindAllResponse<FlashCard>> {
const pagination_query = {}, api_query = {};
let final_query = {};
if (last_id && last_vocabulary) {
pagination_query['$or'] = [
{
vocabulary: {
$gt: last_vocabulary,
},
},
{
vocabulary: last_vocabulary,
_id: {
$gt: new Types.ObjectId(last_id),
},
},
];
}
if (filter.search) {
api_query['vocabulary'] = {
$regex: filter.search,
};
final_query['$and'] = [api_query, pagination_query];
} else {
final_query = pagination_query;
}
return await this.flash_cards_repository.findAll(final_query, {
limit: options.limit,
sort: { vocabulary: 1, _id: 1 },
});
Giải thích: để đáp ứng yêu cầu trên chúng ta chỉ cần dùng $and kết hợp 2 query lại, đảm bảo thỏa mãn tất cả các điều kiện. Các bạn có thể thử gọi API để kiểm tra kết quả.
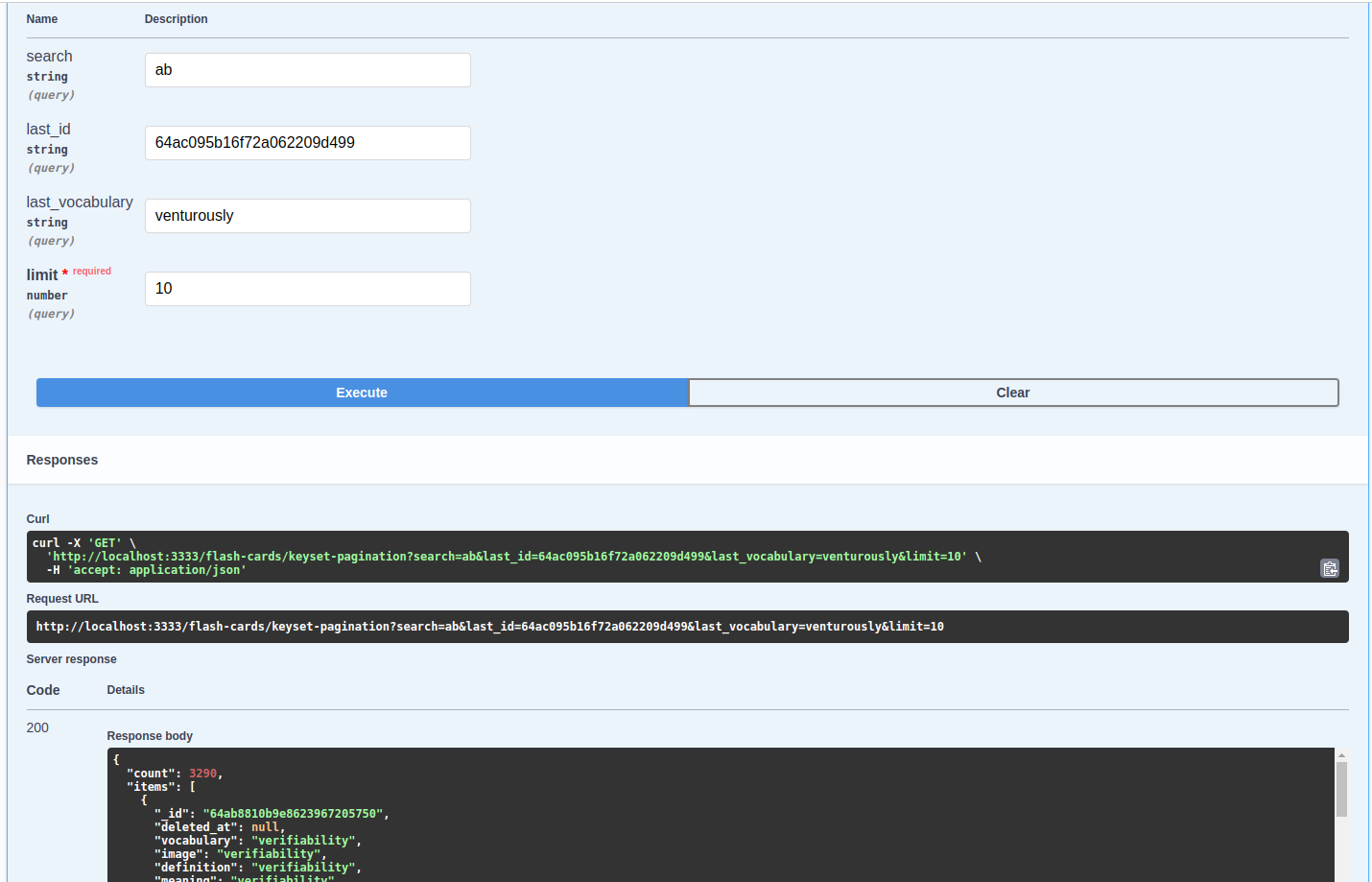
Ngoài ra, theo như log ở console chúng ta mất khoảng 3000ms đến 5000ms cho mỗi lần API execute, việc này khá chậm và ảnh hưởng đến trải nghiệm người dùng. Để cải tiến chúng ta có thể dùng Indexes để, cụ thể là dùng Compound Indexes:
...
export class FlashCard extends BaseEntity { ... }
const schema = SchemaFactory.createForClass(FlashCard);
// Thêm compound indexes
schema.index({ vocabulary: 1, _id: 1 });
export const FlashCardSchema = schema;
Sau khi save lại chúng ta tiến hành gọi lại API lần nữa và xem kết quả ở console:

Tốc độ đã được cải thiện đáng kể, còn khoảng 150ms đến 300ms với mỗi lần API execute. Tuy nhiên các bạn cần lưu ý thứ tự các field trong Compound Indexes, nếu đổi ngược lại thành schema.index({ _id: 1, vocabulary: 1 }) thì sẽ không có tác dụng.
Để chi tiết hơn về Indexes trong MongoDB mình sẽ có 1 bài viết riêng, chúng ta sẽ tìm hiểu rõ hơn về cách nó hoạt động.
4. Hoàn thiện 🥇
Khi Front-end sử dụng API thì họ phải thủ công lấy vocabulary và _id từ item cuối cùng để gọi cho API tiếp theo, và đôi khi nếu họ gửi nhầm có thể dẫn đến lỗi phân trang. Chúng ta có thể handle việc đó ở API bằng cách trả về dữ liệu vocabulary và _id cần dùng cho page tiếp theo trong API response để giảm độ phức tạp và tránh các lỗi không mong muốn.
import { BaseEntity } from '@modules/shared/base/base.entity';
export function generateNextKey<T extends BaseEntity>( items: T[], sort_fields: any[] ) {
if (items.length === 0) { return null; }
// Lấy ra item cuối cùng
const item = items[items.length - 1];
// Nếu không truyền vào field nào thì mặc định là _id
if (sort_fields.length === 0) {
return { _id: item._id };
// Nếu chỉ có một field thì kết hợp với id và trả về
} else if (sort_fields.length === 1) {
return { _id: item._id, [sort_fields[0]]: item[sort_fields[0]] };
}
// Nếu có trên 2 field thì sẽ trả về object gồm các cặp key-value và kết hơp với _id
//
return {
_id: item._id,
...sort_fields.reduce(
(result, sort_field) => (result[sort_field] = item[sort_field]),
{},
),
};
}
Chỉnh sửa lại method findAllUsingKeysetPagination trong FlashCardsService, các bạn nhớ chỉnh lại FindAllResponse thêm next_key để tránh Typescript báo lỗi.
async findAllUsingKeysetPagination(...): Promise<FindAllResponse<FlashCard>> {
...
const { count, items } = await this.flash_cards_repository.findAll(
final_query,
{
limit: options.limit,
sort: { vocabulary: 1, _id: 1 },
},
);
return {
count,
items,
next_key: generateNextKey(items, ['vocabulary', 'meaning']),
};
Giải thích:
- Chúng ta sẽ dùng kết quả trả về từ api và thông tin các field cần sort để tạo ra next_key.
- Function trên sẽ support trên sort 1 hoặc nhiều property.
Kết quả trả về sẽ như bên dưới, phía front end chỉ cần lấy các key đó và gửi lên ở những lần pagination tiếp theo

Đến đây thì chúng ta đã hoàn thành gần như xong cho keyset pagination, mình nói là gần xong bởi vì chúng ta còn có một vấn đề bỏ lỡ. Nếu bạn nào để ý thì sẽ thấy giá trị biến count ở response mỗi lần trả về bị giảm xuống chứ không cố định việc đó làm cho chúng ta khó khăn khi hiển thị tổng số trang. Nguyên nhân là do filter của last_id và last_vocabulary thay đổi.
Chúng ta có thể fix vấn đề trên bằng cách tách count ra riêng với pagination_query:
async findAllUsingKeysetPagination(...): Promise<FindAllResponse<FlashCard>> {
...
const [{ items }, count] = await Promise.all([
this.flash_cards_repository.findAll(final_query, {
limit: options.limit,
sort: { vocabulary: 1, _id: 1 },
}),
this.flash_cards_repository.count(api_query),
]);
return {
count,
items,
next_key: generateNextKey(items, ['vocabulary', 'meaning']),
};
Thử lại và các bạn sẽ thấy giá trị biến count giờ đã được cố định.
5. Kết hợp offset pagination và keyset pagination 🛠️
Ở trên mình có nêu ra bất cập của keyset pagination là chúng ta không thể jump để một trang bất kỳ vì cần phải có id của item cuối cùng ở trang trước. Rất may là chúng ta có thể khắc phục vấn đề trên bằng cách kết hợp với offset pagination như sau:
...
export class FlashCardsController {
...
@Get('keyset-pagination')
@ApiQuery({ name: 'last_id', required: false })
@ApiQuery({ name: 'last_vocabulary', required: false })
@ApiQuery({ name: 'search', required: false })
@ApiQuery({ name: 'offset', required: false })
@UseInterceptors(LoggingInterceptor)
async findAllUsingKeyset(
@Query('search') search: string,
@Query('last_id') last_id: string,
@Query('last_vocabulary') last_vocabulary: string,
@Query('limit', ParseIntPipe) limit: number,
@Query('offset') offset: number,
) {
// Nếu user truy cập một trang bất kỳ thay vì next, previous
// thì sẽ gửi lên offset
if (offset) { // ⏪️
const { count, items } = await this.flash_cards_service.findAll(
{ search },
{ offset, limit },
);
return {
count,
items,
next_key: generateNextKey(items, ['vocabulary', 'meaning']),
};
}
return this.flash_cards_service.findAllUsingKeysetPagination(
{ search },
{ last_id, last_vocabulary },
{ limit },
);
}
Kết luận 📝
Vậy là chúng ta đã tìm hiểu qua 2 phương pháp pagination phổ biến thường được sử dụng. Mỗi phương pháp có những ưu và nhược điểm riêng, tùy thuộc vào ứng dụng cụ thể mà bạn có thể lựa chọn phương pháp phù hợp. Các bạn không nên chỉ chọn đi theo một phương pháp mà nên căn cứ vào nhiều điều kiện khác nhau để chọn lựa (áp dụng cụ thể theo từng API chứ không nhất thiết 1 dự án chỉ được chọn 1 cách pagination).
Hy vọng bài viết này sẽ giúp ích cho các bạn trong quá trình học tập cũng như làm việc. Cảm ơn các bạn đã giành thời gian đọc bài viết. Follow mình để chờ đón các bài viết tiếp theo của series nha.
Tài liệu tham khảo 🔍
- https://www.mongodb.com/docs/manual/reference/method/cursor.skip/
- Wanago, M. (2020) API with nestjs #17. offset and keyset pagination with postgresql and typeorm, Marcin Wanago Blog - JavaScript, both frontend and backend. Available at: https://wanago.io/2020/11/09/api-nestjs-offset-keyset-pagination-postgresql-typeorm/ (Accessed: 13 July 2023).
- Mosius (2022) MongoDB pagination, Fast & Consistent, Medium. Available at: https://medium.com/swlh/mongodb-pagination-fast-consistent-ece2a97070f3 (Accessed: 13 July 2023).
- MongoDB $GT/$lt operators with prices stored as strings, Stack Overflow. Available at: https://stackoverflow.com/questions/18039358/mongodb-gt-lt-operators-with-prices-stored-as-strings (Accessed: 13 July 2023).
Change log 📓
- September 05, 2023: Init document
All rights reserved
