
SADTALER - XÂY DỰNG BỨC ẢNH BIẾT NÓI
Lời mở đầu
Chắc hẳn bạn đã từng ao ước có thể "thổi hồn" vào những bức ảnh tĩnh, biến chúng trở nên sống động và biết nói? Hay bạn đang tìm kiếm một công cụ đột phá để tạo ra những video độc đáo, thu hút cho các dự án của mình mà không cần đến kỹ năng quay dựng phức tạp? Nếu câu trả lời là có, thì bạn đã tìm đến đúng nơi rồi đấy
Trong thế giới kỹ thuật số không ngừng phát triển, trí tuệ nhân tạo (AI) đang mở ra những cánh cửa sáng tạo không giới hạn. Và hôm nay, chúng ta sẽ cùng nhau khám phá một trong những công cụ AI thú vị và mạnh mẽ nhất trong lĩnh vực này: Sadtalker. Hãy quên đi những tấm hình chân dung vô tri, bởi với Sadtalker, bạn sẽ có khả năng biến bất kỳ bức ảnh nào thành một video "biết nói" một cách đầy biểu cảm và tự nhiên.
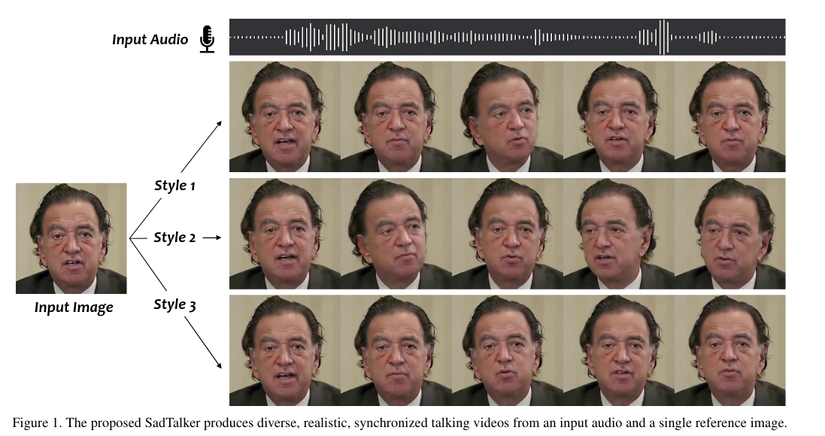
SadTalker có thể làm được gì?
SadTalker được xuất bản tại CVPR 2023, lấy một bức ảnh chân dung và một file âm thanh, sau đó kết hợp chúng để tạo ra một video, trong đó người trong ảnh sẽ nói theo âm thanh đó với chuyển động miệng, đầu và biểu cảm cực kỳ tự nhiên.
Tạo Avatar Biết Nói: Bạn có thể tạo ra một avatar (nhân vật đại diện) từ ảnh vẽ hoặc ảnh AI và để nó trở thành người dẫn chương trình cho kênh YouTube, TikTok của mình mà không cần phải tự xuất hiện trước ống kính.
Podcast có hình (Videocast): Biến các kênh podcast thuần âm thanh trở nên sinh động hơn bằng cách sử dụng một ảnh đại diện của host hoặc khách mời và để họ "nói" theo nội dung audio.
Tạo Giảng Viên Ảo: Các khóa học online có thể sử dụng hình ảnh của một chuyên gia để tạo ra các video bài giảng mà không cần người đó phải tốn thời gian quay phim.
Thời kỳ trước SadTalker (2023)
Giấc mơ biến một bức ảnh tĩnh thành một video biết nói không phải là mới. Trong nhiều năm, các nhà nghiên cứu AI trên khắp thế giới đã nỗ lực để giải quyết bài toán đầy thách thức này. Hãy cùng nhìn lại chặng đường gập ghềnh trước khi SadTalker tạo ra bước đột phá.
Bước Đi Đầu Tiên: Chỉ Là Mấp Máy Môi
Ban đầu, hầu hết các phương pháp chỉ tập trung vào một nhiệm vụ duy nhất và rõ ràng nhất: làm cho đôi môi chuyển động khớp với âm thanh. Điều này khá hợp lý, vì lời nói (audio) và khẩu hình (lip) có mối liên hệ trực tiếp.
Tuy nhiên, kết quả chỉ giống như một con rối chỉ biết cử động miệng. Các video thiếu "hồn" vì một người thật khi nói chuyện còn cử động cả đầu, chớp mắt và có những biểu cảm tinh tế khác.
Thêm Chuyển Động, Thêm... Vấn Đề
Nhận thấy điều đó, các mô hình thế hệ tiếp theo đã cố gắng tạo ra các chuyển động phức tạp hơn, đặc biệt là chuyển động của đầu. Họ sử dụng các kỹ thuật như trường chuyển động 2D (2D motion fields) hay các điểm mốc (landmarks) để làm điều này.
Nhưng đây cũng là lúc hàng loạt vấn đề nan giải xuất hiện, khiến chất lượng video vẫn còn rất xa mới đạt đến độ chân thực:
- Hiện tượng "đầu tượng sáp": Khuôn mặt có xu hướng luôn quay về một tư thế mặc định cứng nhắc, thiếu tự nhiên.
- Miệng bị nhòe: Vùng miệng thường bị mờ đi khi chuyển động, trông như một video chất lượng thấp.
- Biến đổi nhân dạng: Đáng báo động nhất, người trong video đôi khi trông không còn giống với người trong ảnh gốc nữa!
Khuôn mặt biến dạng: Nhiều trường hợp khuôn mặt bị méo mó, lệch lạc một cách kỳ dị.
Gốc Rễ Của Vấn Đề: "Mớ Bòng Bong" Của Các Chuyển Động
Tại sao việc thêm chuyển động đầu lại khó đến vậy? Câu trả lời nằm ở chỗ các loại chuyển động trên khuôn mặt có mối liên kết với âm thanh rất khác nhau.
Đầu và đôi mắt có thể hoạt động tự do. Bạn có thể nói cùng một câu trong khi gật đầu, lắc đầu hoặc giữ im. Việc chớp mắt gần như là ngẫu nhiên.
Các mô hình AI cũ không thể "tách bạch" (disentangle) được các loại chuyển động này. Chúng xem mọi thứ là một mớ bòng bong. Vì vậy, khi AI cố gắng tạo ra một chuyển động đầu dựa trên âm thanh, nó vô tình làm ảnh hưởng đến các chuyển động khác, dẫn đến khuôn mặt bị biến dạng.
Dù đã có những gợi ý về việc sử dụng mô hình 3D để tách bạch các chuyển động này, nhưng chưa có phương pháp nào thực sự thành công trong việc tạo ra biểu cảm chính xác và chuỗi chuyển động tự nhiên. Bối cảnh đầy thách thức này chính là mảnh đất màu mỡ để SadTalker ra đời và định nghĩa lại cuộc chơi.
Nỗ lực đầu tiên: Biến Ảnh Tĩnh Thành Video Nói (Audio-driven Single Image)
Đây là mục tiêu chính và cũng là con đường chông gai nhất, nơi các nhà nghiên cứu cố gắng tạo ra video nói chuyện chỉ từ một ảnh tĩnh và một file âm thanh.
Giai đoạn đầu: Tập trung vào khẩu hình
Những nỗ lực sơ khai nhất chỉ tập trung làm một việc: khớp chuyển động của môi với lời nói. Nhưng kết quả còn rất giả, thiếu sức sống.
Bước tiến tiếp theo: Sử dụng "bản thiết kế" trung gian
Các mô hình sau đó (như ATVGnet, MakeItTalk) trở nên thông minh hơn. Thay vì đi thẳng từ âm thanh ra video, chúng tạo ra một "bản thiết kế" trung gian – thường là các điểm mốc trên khuôn mặt (facial landmarks). Từ bản thiết kế này, AI sẽ "vẽ" nên các khung hình video.
Tuy nhiên, cách tiếp cận này đã vấp phải vấn đề "mớ bòng bong":
- Không gian bị "dính liền" (Coupled Space): Các điểm mốc trên khuôn mặt không hoạt động độc lập. Khi bạn nói, không chỉ có môi di chuyển, mà cằm, má, và cả cái đầu cũng chuyển động theo. Các mô hình cũ không thể "tách bạch" (disentangle) được các chuyển động này. Việc cố gắng tạo ra một chuyển động (như lắc đầu) thường vô tình làm hỏng các chuyển động khác (như khẩu hình), dẫn đến khuôn mặt bị biến dạng.
Các nỗ lực "gỡ rối" và thất bại
Nhiều phương pháp tinh vi hơn đã cố gắng "gỡ rối" mớ bòng bong này:
-
PC-AVS: Cố gắng tách riêng chuyển động đầu và biểu cảm. Nhưng kết quả cho ra ảnh chất lượng thấp và oái oăm thay, nó vẫn cần một video khác để lấy tín hiệu điều khiển, đi ngược lại mục tiêu ban đầu.
-
Audio2Head và các phương pháp tương tự: Lấy cảm hứng từ các kỹ thuật khác, nhưng vẫn thất bại trong việc tạo ra chuyển động đầu sống động, đồng thời vẫn gây ra lỗi biến dạng khuôn mặt và làm sai lệch nhân dạng.
-
Sử dụng mô hình 3DMM: Một số phương pháp đã thử dùng 3DMM làm "bản thiết kế" trung gian vì nó vốn đã tách bạch các thành phần. Tuy nhiên, chúng vẫn gặp phải vấn đề biểu cảm không chính xác và tạo ra các lỗi hình ảnh (artifacts) rất rõ ràng.
Nỗ lực tiếp theo: "Lồng Tiếng" Cho Video Sẵn Có (Audio-driven Video Portrait)
Trường phái này có một mục tiêu khác: không tạo mới, mà là chỉnh sửa một video chân dung có sẵn để khớp với một file âm thanh mới. Bạn có thể hiểu đây là công nghệ "lồng tiếng hình ảnh" (visual dubbing).
Ưu điểm: Vì có sẵn toàn bộ dữ liệu từ video gốc (ánh sáng, bối cảnh, chuyển động tự nhiên của nhân vật), các phương pháp này thường cho ra kết quả rất chất lượng và chân thực trong phạm vi video đó.
Hạn chế: Chúng hoàn toàn phụ thuộc vào người cụ thể trong video. Mô hình được huấn luyện riêng cho video đó và không thể áp dụng cho một bức ảnh của người khác.
Trường phái tiếp theo: "Sao Chép" Chuyển Động Từ Video Khác (Video-Driven)
Đây là trường phái được xem là "dễ hơn" cả. Nhiệm vụ của nó là sao chép chuyển động từ một video nguồn (người A đang nói) và áp lên một ảnh tĩnh (người B).
Tại sao lại dễ hơn? Vì nó xử lý bài toán "video to video". Nguồn điều khiển (video) và kết quả (video) đều thuộc "miền dữ liệu hình ảnh". mô hình AI chỉ cần học cách sao chép các tín hiệu thị giác.
So với SadTalker: Nhiệm vụ của SadTalker khó hơn nhiều vì là bài toán "audio-to video", phải dịch một tín hiệu từ miền hoàn toàn khác.
Điểm đáng chú ý: Dù dễ hơn, trường phái này đã phát triển các kỹ thuật render video rất hiệu quả. SadTalker đã học hỏi chính các kỹ thuật này cho phần render của mình. Tuy nhiên, các phương pháp này không tập trung vào việc tự tạo ra các chuyển động chân thực từ âm thanh, vốn là điểm mạnh của SadTalker.
Kiến trúc bên trong SadTalker
Kiến trúc của SadTalker sẽ bao gồm 3 thành phần chính là Monocular 3D Face Recon, Coefs Generation, 3D-Aware Face Render.
- Monocular 3d Face Recon: Dựng lại mô hình khuôn mặt 3D hoàn chỉnh chỉ từ bức ảnh 2D duy nhất.
- Coeffs Generation: Sinh ra 3D motion coefficients (Facial Expression β, Head Pose ρ) từ file audio
- 3D-Aware Face Render: Các coefficients sử dụng để sinh ra video cuối cùng.
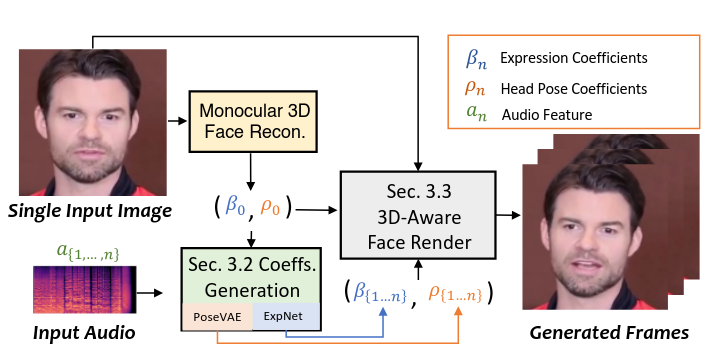
Kiến trúc sơ bộ của 3D Face Model
Để video AI trông chân thực hơn, việc sử dụng thông tin 3D là yếu tố cực kỳ quan trọng. Lý do là vì video ngoài đời thực vốn được quay trong môi trường 3 chiều.
SadTalker sử dụng "biểu diễn trung gian" cho nhân vật sử dụng 3DMM, tương tự như bộ điều chỉnh khuôn mặt nhân vật chúng ta chơi game 😀.
- Trong Game: Khi tạo nhân vật, chúng ta không kéo từng điểm (vertex) trên khuôn mặt. Thay vào đó, chúng ta kéo các thanh trượt như "Độ rộng cằm", "Độ cao mũi", "Môi dày/mỏng". Mỗi thanh trượt này tương ứng với một hoặc nhiều thông số trong "bộ điều chỉnh" của nhân vật.
- Với 3DMM: Tương tự, 3DMM cũng có các "thanh trượt" kỹ thuật số cho mọi thứ, từ hình dạng xương hàm (identity) cho đến một nụ cười (expression).
Trong 3DMM, hình dạng khuôn mặt 3D được tách thành các phần như sau:
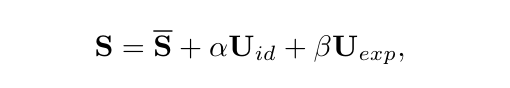
Với:
- S: Hình dạng khuôn mặt được chỉ định
- Giá trị trung bình của hàng triệu khuôn mặt
- : đặc điểm nhận dạng của khuôn mặt
- : biểu cảm trên khuôn mặt
Công thức trên có thể hiểu là, tất cả khuôn mặt đều được tạo từ base , cộng với các tham số có thể điều chỉnh (, ).
Để đảm bảo mô tả được các tư thế khác nhau của nhân vật, tham số:
- r : mô tả sự quay đầu (lắc đầu, gật đầu, nghiêng đầu)
- t : mô tả sự dịch chuyển tịnh tiến của nhân vật (nâng cao, hạ thấp)
Tuy nhiên SadTalker chỉ huấn luyện các tham số {, r, t}, mà ko thay đổi để đảm bảo đặc điểm nhận dạng của nhân vật không bị thay đổi.
Các phần head pose = [r, t] và biểu cảm nhân vật được huấn luyện độc lập từ audio đầu vào.
Sinh chuyển động dựa vào Audio
Các thông số chuyển động 3D bao gồm cả chuyển động của toàn bộ cái đầu (head pose) và biểu cảm trên khuôn mặt (expression). Tuy nhiên, hai loại chuyển động này lại có bản chất rất khác nhau.
- Chuyển động đầu: Là một chuyển động mang tính toàn cục (global). Việc bạn gật đầu, lắc đầu hay nghiêng đầu thường ít liên quan trực tiếp đến âm thanh bạn đang phát ra. Ví dụ, bạn có thể vừa nói vừa gật đầu lia lịa, hoặc giữ nguyên đầu và chỉ nói.
- Biểu cảm: Đặc biệt là cử động môi, lại là một chuyển động mang tính cục bộ (local) và có mối liên hệ cực kỳ chặt chẽ với âm thanh. Từng âm thanh bạn phát ra đều tương ứng với một hình dạng môi nhất định.
Do sự khác biệt này, việc bắt một mô hình AI duy nhất phải học đồng thời cả hai thứ sẽ dẫn đến một mớ hỗn độn. Mạng nơ-ron sẽ bị "bối rối" vì phải cố gắng tìm mối liên hệ giữa âm thanh và chuyển động đầu, trong khi mối liên hệ này thực chất rất yếu. Điều này sẽ làm giảm độ chính xác của các chuyển động quan trọng hơn như cử động môi.
Do đó mô hình ExpNet sẽ tập trung vào việc tạo ra các biểu cảm khuôn mặt một cách chi tiết, trong khi mô hình PoseVAE sẽ chuyên trách tạo ra các chuyển động đầu,
ExpNet
Chúng ta sẽ đi đến mạng đầu tiên là ExpNet, sử dụng để sinh ra biểu cảm 3D dựa vào file audio.
Dưới đây là kiến trúc của mạng ExpNet.
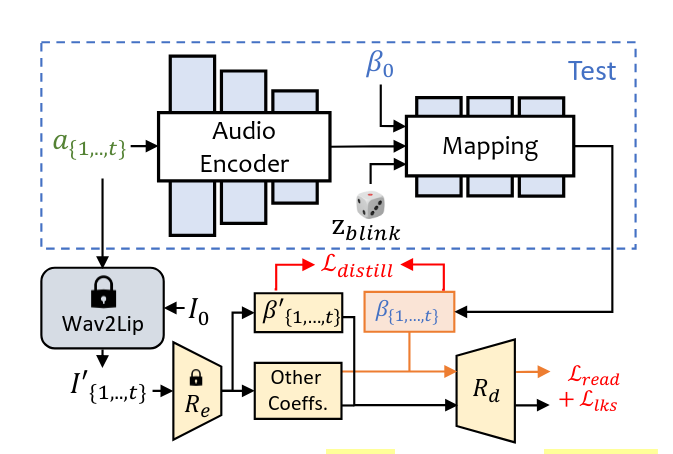
Chúng ta sẽ điểm qua các mục chính:
- AudioEncoder (Mạng Resnet): ExpNet sử dụng Resnet (truyền 'bức tranh' phổ của ảnh) để học được đặc trưng của phổ ảnh.
- Mapping Network: Sử dụng thông tin từ AudioEncoder, hệ số ngẫu nhiên, (được trích xuất từ first frame ) để sinh ra (hệ số biểu cảm ứng với các phổ audio)
- Wav2lip: ExpNet sử dụng pretrained là Wav2lip, kết hợp với (first frame) để sinh ra video chỉ chứa khẩu hình miệng của nhân vật.
- Video chứa khẩu hình miệng của nhân vật này được đi qua lớp (pretrained 3DMM coeficients estimator) để sinh ra
- Hàm loss được sử dụng với và để giúp ExpNet chắt lọc kiến thức từ Wav2lip.
- Other Coefficient: Sử dụng để sinh ra các thông tin về nhân dạng, tư thế của người trong ảnh gốc. (ví dụ như hệ số tư thế - hướng nghiêng đầu, hệ số biểu cảm - cười, buồn, ngạc nhiên..)
PoseVAE
Tiếp theo chúng ta sẽ đến với mạng PoseVAE, được sử dụng để sinh ra chuyển động dựa trên hình ảnh đầu vào và audio đầu vào.
Chúng ta sẽ nhìn qua về kiến trúc của PoseVAE bên dưới.
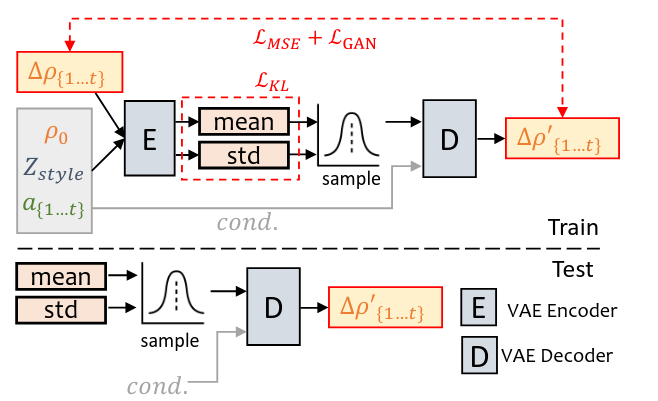
Với các điểm chính:
- E: VAE Encoder
- D: VAE Decoder
- : vector biểu diễn phong cách của nhân vật. (learnable parameters)
- : vector 6 chiều biểu diễn tư thế của nhân vật (3 chiều cho góc xoay biểu diễn độ ngửa/cúi (pitch), nghiêng trái/phải (roll), và quay trái/phải (yaw) của đầu và 3 chiều cho tịnh tiến (Translation): biểu diễn vị trí của đầu trong không gian (x, y, z).
Cụ thể dữ liệu ban đầu giúp biểu diễn, , , sẽ được đi qua VAE Encoder để sinh ra theo phân phối Gauss, tạo ra 2 vector là mean và std, tiếp theo sẽ sample trên phân phối chuẩn đó để đảm bảo các tư thế được sinh ra đa dạng nhưng vẫn dựa trên ảnh gốc.
Sau đó sample vector sẽ được đưa vào VAE Decoder để sinh ra chuỗi các 'cử động' .
Mục tiêu là giúp mô hình sinh ra chuỗi các cử động dựa trên thông tin được () của hình ảnh gốc.
3D-Aware Face Render
Chúng ta đã có ExpNet giúp biểu diễn biểu cảm dựa trên audio.
Chúng ta cũng có PoseVAE biểu diễn chuyển động dựa trên audio và thông tin
Giờ hãy kết hợp các phần đó và đi qua mạng mappingNet để sinh ra video cuối cùng.
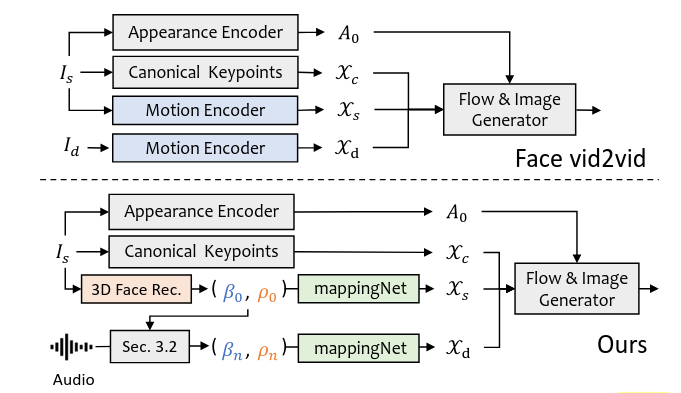
Nhóm phát triển đã lấy cảm hứng từ một phương pháp hoạt hình ảnh rất mạnh mẽ tên là face-vid2vid.
Điểm mạnh của face-vid2vid là khả năng tự học thông tin 3D từ một bức ảnh duy nhất.
Tuy nhiên, face-vid2vid có một nhược điểm lớn: nó bắt buộc phải có một video thật làm tín hiệu điều khiển chuyển động.
Đây chính là nơi SadTalker tạo ra sự khác biệt. Thay vì video, SadTalker sử dụng chính các hệ số 3DMM (biểu cảm và tư thế đầu) để làm tín hiệu điều khiển. Module mappingNet sẽ giải quyết điều đấy
Module Ánh xạ sang Không gian Keypoint 2D (mappingNet)**:
Nhiệm vụ của mappingNet là học cách ánh xạ mối quan hệ giữa các hệ số chuyển động 3DMM tường minh (tức là các con số cụ thể về biểu cảm và tư thế đầu) và các keypoint 3D ẩn không giám sát mà face-vid2vid sử dụng.
Kiến trúc: mappingNet được xây dựng từ một vài lớp tích chập 1D (1D convolutional layers), được thiết kế để xử lý dữ liệu dạng chuỗi theo thời gian.
Module Flow & Image Generator
Đây là module cuối cùng, chịu trách nhiệm kết xuất khung hình video.
Appearance Encoder: Trích xuất một vector đặc trưng ngoại hình bất biến từ ảnh nguồn , mã hóa các thông tin về danh tính, kết cấu bề mặt (texture) và điều kiện chiếu sáng.
Flow & Image Generator: Một mạng nơ-ron dựa trên kỹ thuật warping, thường được xây dựng trên các kiến trúc như FOMM (First Order Motion Model). Nó nhận đầu vào là:
- Vector biểu diễn đặc trưng của ngoại hình
- Các keypoint của ảnh nguồn ().
- Các keypoint điều khiển () được tạo ra bởi mappingNet.
Dựa trên sự chênh lệch giữa và , mạng này sẽ thực hiện tính toán ra "cử động" (motion map), giống như các pixel ở hình ảnh, và các pixel này có thể được kéo, dịch chuyển, từ đó tái tạo lại hình ảnh nguồn với tư thế và biểu cảm mới, tạo thành một khung hình hoàn chỉnh của video đầu ra.
Lời kết: không chỉ là một bức ảnh biết nói
SadTalker không chỉ đơn thuần là một công cụ AI thú vị; nó đại diện cho một bước tiến vượt bậc trong lĩnh vực tổng hợp video và tương tác người-máy. Bằng cách phá vỡ những rào cản kỹ thuật trước đây, SadTalker đã biến điều không thể thành có thể: thổi hồn vào một bức ảnh tĩnh chỉ bằng một file âm thanh.
Công nghệ đằng sau SadTalker mở ra vô vàn tiềm năng ứng dụng, từ việc tạo ra các trợ lý ảo thân thiện, lồng tiếng cho video với chi phí thấp, đến việc cách mạng hóa ngành marketing và giải trí. Nó cho chúng ta thấy một tương lai nơi ranh giới giữa nội dung tĩnh và động ngày càng bị xóa nhòa.
SadTalker không chỉ làm cho một bức ảnh "biết nói". Nó kể cho chúng ta câu chuyện về một tương lai sáng tạo, nơi mọi ý tưởng đều có thể trở nên sống động.
All rights reserved
