RLHF và cách ChatGPT hoạt động
Bài đăng này đã không được cập nhật trong 3 năm
Cũng là một chủ đề liên quan đến ChatGPT, nhưng lần này lại thuần về công nghệ thôi.
Hôm nay thì mình sẽ nói về kỹ thuật giúp cho ChatGPT thành công được như hiện tại, cũng như là một kỹ thuật mới trong việc tạo ra các chatbot có khả năng giao tiếp trơn tru mượt mà như con người, đó là Học Tăng cường từ Phản hồi của người dùng (viết tắt là RLHF). Từ đó giúp cho mọi người có cái nhìn tổng quát về cách chatbot này hoạt động nhé (dựa trên tài liệu công khai của OpenAI, nên yên tâm, uy tín).
Một yêu cầu nhỏ đó là mọi người nên đọc và tìm hiểu trước về Reinforcement Learning trước khi tìm hiều sâu về kĩ thuật này. Ở đây thì mình chỉ ghi ra những từ khoá cần chú ý khi dùng RLHF cho con chatbot này thôi:
- Agent: mô hình ngôn ngữ (LLM) dùng để tạo văn bản cho chatbot.
- Environment: đoạn chat của chatbot.
- Policy: những "chiến lược" giúp chatbot học được cách tạo văn bản sao cho trơn tru mượt mà và giống người nhất.
- Action: ở đây thì các LLM sẽ thực hiện hành động next token prediction.
- Reward: câu trả lời càng chất lượng càng tốt.
Bắt đầu thôi...
1. RLHF là gì?
RLHF là viết tắt của Reinforcement Learning from Human Feedback, nghĩa là Học Tăng cường từ Phản hồi của người dùng. Ý tưởng của kĩ thuật này bắt nguồn từ việc cần phải có một sự cải tiến trong việc đánh giá chất lượng của văn bản được sinh ra từ các mô hình ngôn ngữ.
Theo đó, trước khi kỹ thuật này ra đời, các mô hình ngôn ngữ (ví dụ như các mô hình dịch máy) chủ yếu đánh giá chất lượng của văn bản được tạo ra bằng việc sử dụng các loss function. Sau này người ta sử dụng các kỹ thuật cao cấp hơn, ví dụ như BLEU hoặc ROUGE để đánh giá output của các mô hình với một số sample có sẵn do con người tạo ra bằng những tính toán đơn giản. Tuy nhiên, ngôn ngữ vốn đa dạng và phức tạp, vậy tại sao không sử dụng chính phản hồi của người dùng để đánh giá văn bản do máy tạo ra, và xa hơn thì dùng chính những phản hồi đó để tối ưu mô hình? Ý tưởng của RLHF được ra đời từ đấy.
2. Cách RLHF hoạt động
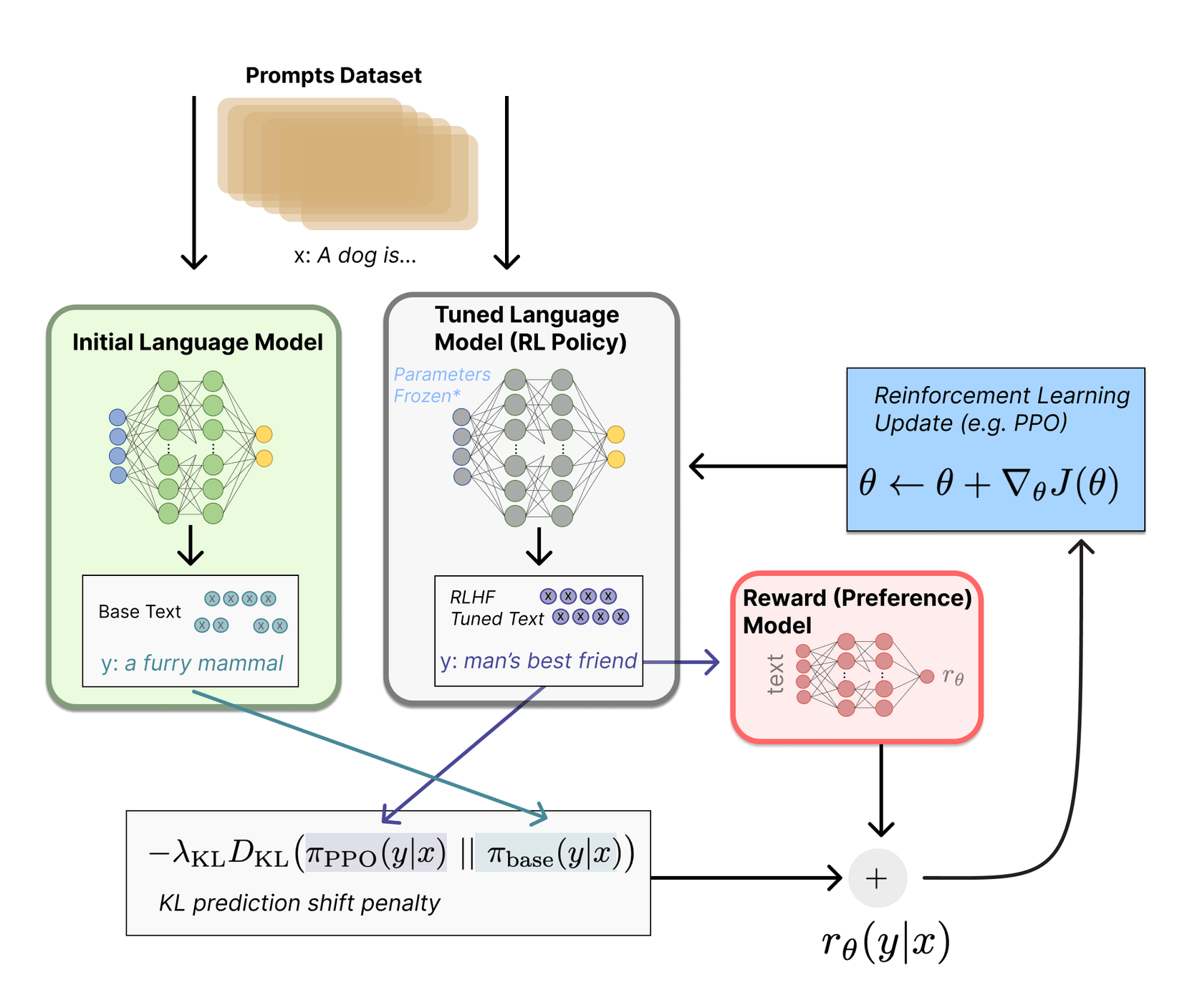
Oke, vào phần chính nhé. Kỹ thuật này khó nha, vì phải dựa vào việc huấn luyện nhiều mô hình cùng một lúc và phải trải qua nhiều tầng triển khai, nhưng mà cũng gồm 3 bước chính:
- Sử dụng một pre-trained Language Model (LM).
- Thu thập dữ liệu và huấn luyện một reward model.
- Fine-tuning LM ở trên bằng reward model vừa được huấn luyện.
Nào, phân tích từng bước thôi:
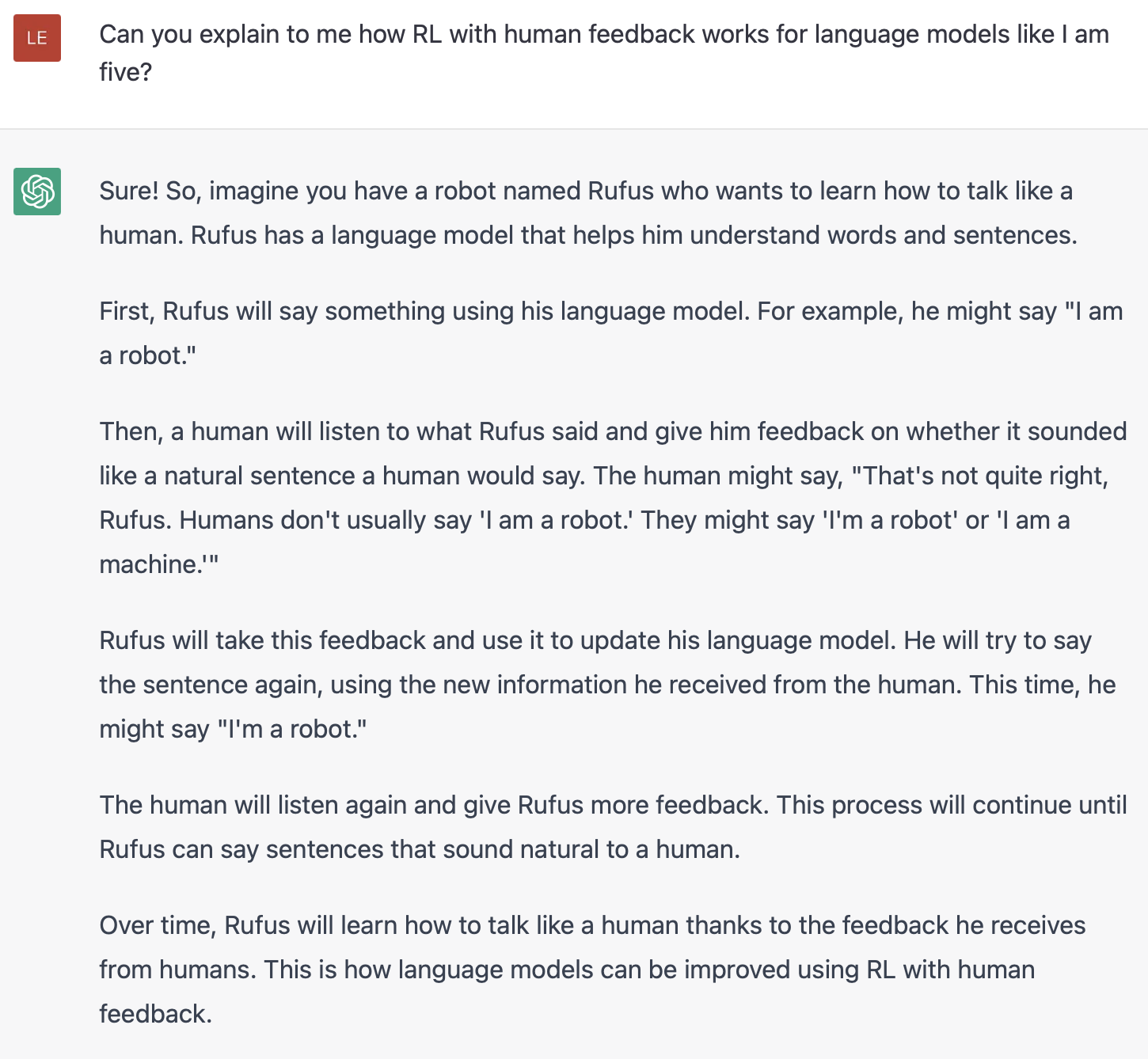
a. Pretraining Language Models
Công đoạn này thì căn bản là vẫn sẽ huấn luyện một LM như bình thường thôi (sử dụng những data có sẵn, những kiến trúc có sẵn cho từng tác vụ, cách tối ưu có sẵn, label có sẵn, blablabla), nói chung là thực hiện như bình thường. Ở đây thì tuỳ từng mục tiêu mà lựa chọn mô hình phù hợp, chứ không có một cái quy chuẩn nào cả. Ví dụ, đối với ChatGPT thì họ sẽ chỉ sử dụng một phần của GPT-3 để fine-tune lại cho nhiệm vụ sinh văn bản. Túm cái quần lại thì công đoạn này chỉ cần chú ý tuỳ chỉnh model của chúng ta cho ổn là được.
Vậy vai trò của cái mô hình này là gì? Thì đơn giản là chỉ sinh văn bản thôi. Quy trình này là một quy trình học có giám sát nên còn được gọi là Supervised Fine-tuned (viết tắt là SFT). Okay, fine-tune xong rồi thì cất tạm cái model này qua một bên, lát nữa dùng tiếp.
Nhưng sinh văn bản từ dataset có sẵn thì...chán lắm, với lại không uy tín nếu nhìn từ góc độ con người. Vậy nếu như chính con người tham gia đánh giá văn bản được sinh ra từ LM thì sao nhỉ? Cùng đến với bước tiếp theo nhé, đó là xây dựng và huấn luyện một reward model.
b. Thu thập dữ liệu và huấn luyện Reward model
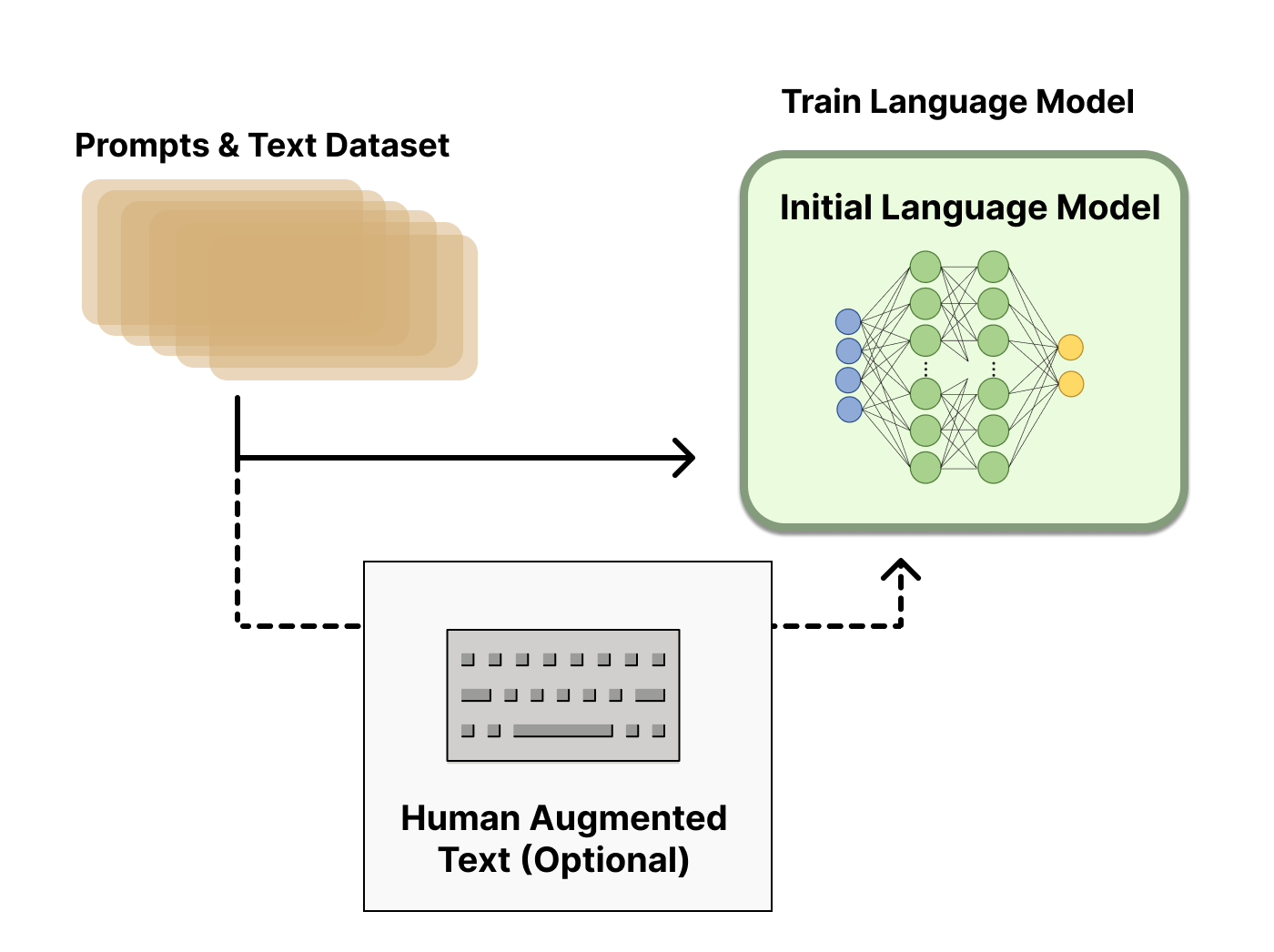
Việc tạo ra một Reward model (RM) (hay còn có tên gọi khác là preference model) được xem như là khởi đầu cho các nghiên cứu sâu hơn về RLHF, và công đoạn này có thể nói là tạo ra sự khác biệt cho RLHF so với các kỹ thuật đánh giá văn bản trước đây. Mục tiêu đó chính là tối ưu reward function trong bài toán RL.
Thế quy trình huấn luyện RM diễn ra như thế nào? Đầu tiên phải thu thâp data bằng cách dùng nhiều LM khác nhau, có thể là pre-traned model hoặc model train-from-scratch. Sau khi có model thì chúng ta sẽ dùng mấy model này để sinh hàng loạt văn bản với cùng một prompt (có thể dịch là chỉ dẫn tạo văn bản). Và thế là....chưa xong. Có được rất nhều văn bản được snh ra rồi, đến đây thì con người lại can thiệp vào quy trình bằng cách đánh giá các văn bản này (tức là label các văn bản này theo thứ tự từ cao nhất (tốt nhất) tới thấp nhất). Sau đó thì số data này lại được sử dụng để huấn luyện cho RM của chúng ta (rất chi là loằng ngoằng). Nói cách khác là chúng ta đang dùng model để tạo data cho một model khác, và labeling là do con người thực hiện.
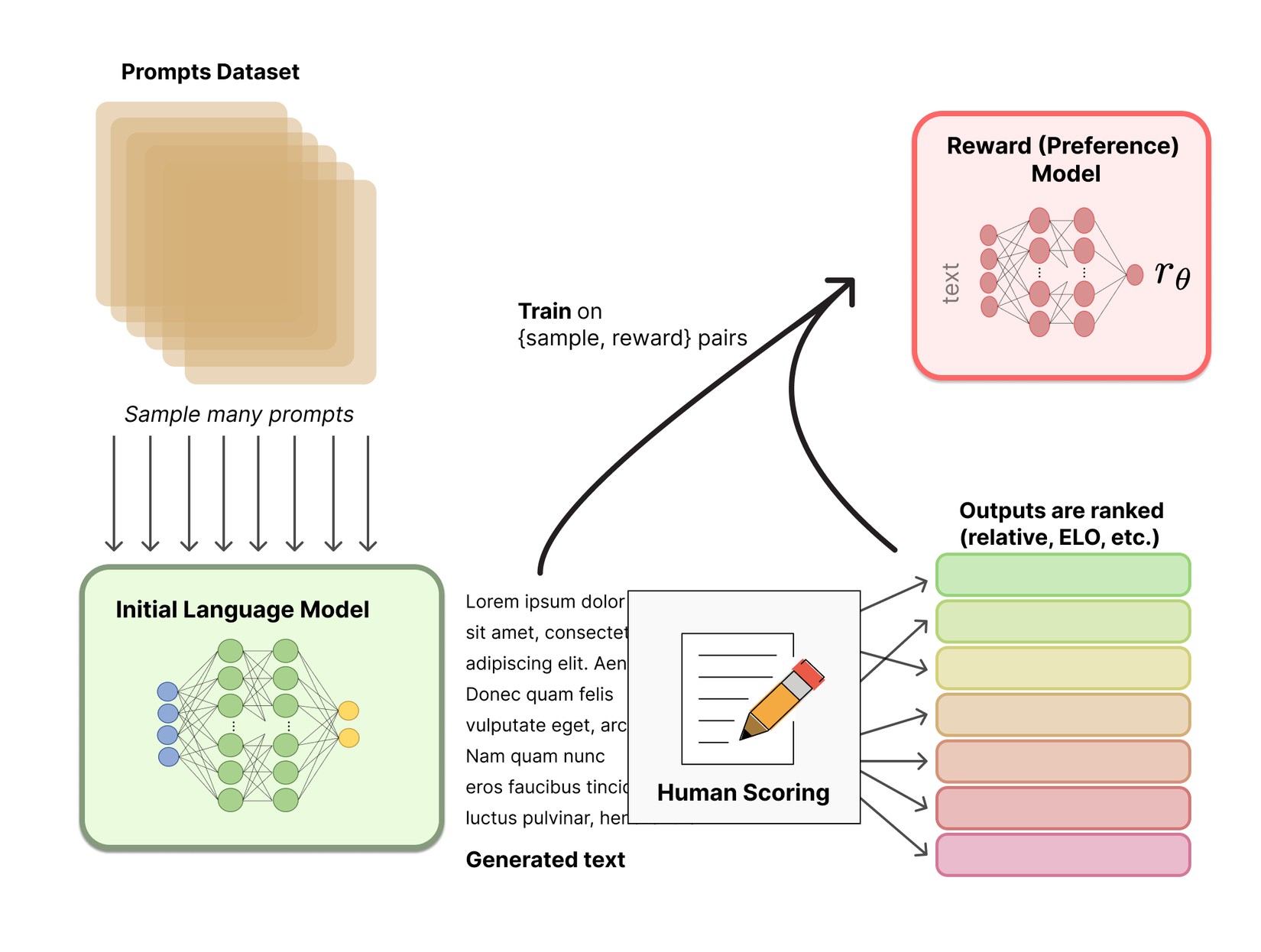
Quy trình huấn luyện Reward Model diễn ra như hình dưới: Nguyên liệu cho RM sẽ bao gồm những thành phần sau:
- Prompt : là chỉ dẫn cho pre-trained model (được đề cập ở phần trên) sinh văn bản. Prompt này sẽ được lấy từ 1 database lớn hơn. Lấy ví dụ ở đây thì có thể là một bài post trên forum Reddit (lấy từ dataset Reddit TL;DR). Từ prompt này ta sẽ có 2 sample và được sinh ra.
- (với {0, 1}) : ground truth label của RM, là đánh giá (sự lựa chọn) của con người với 2 sample và .
Khi đó hàm mất mát cho mô hình RM của chúng ta sẽ có dạng:
Với là điểm số do con người đánh giá với mỗi cặp và chính là hàm sigmoid. Ở đây thì dấu "-" để bảo đảm kết quả của hàm loss luôn dương để dễ tính toán hơn thôi.
c. Fine-tuning RL model với RM model
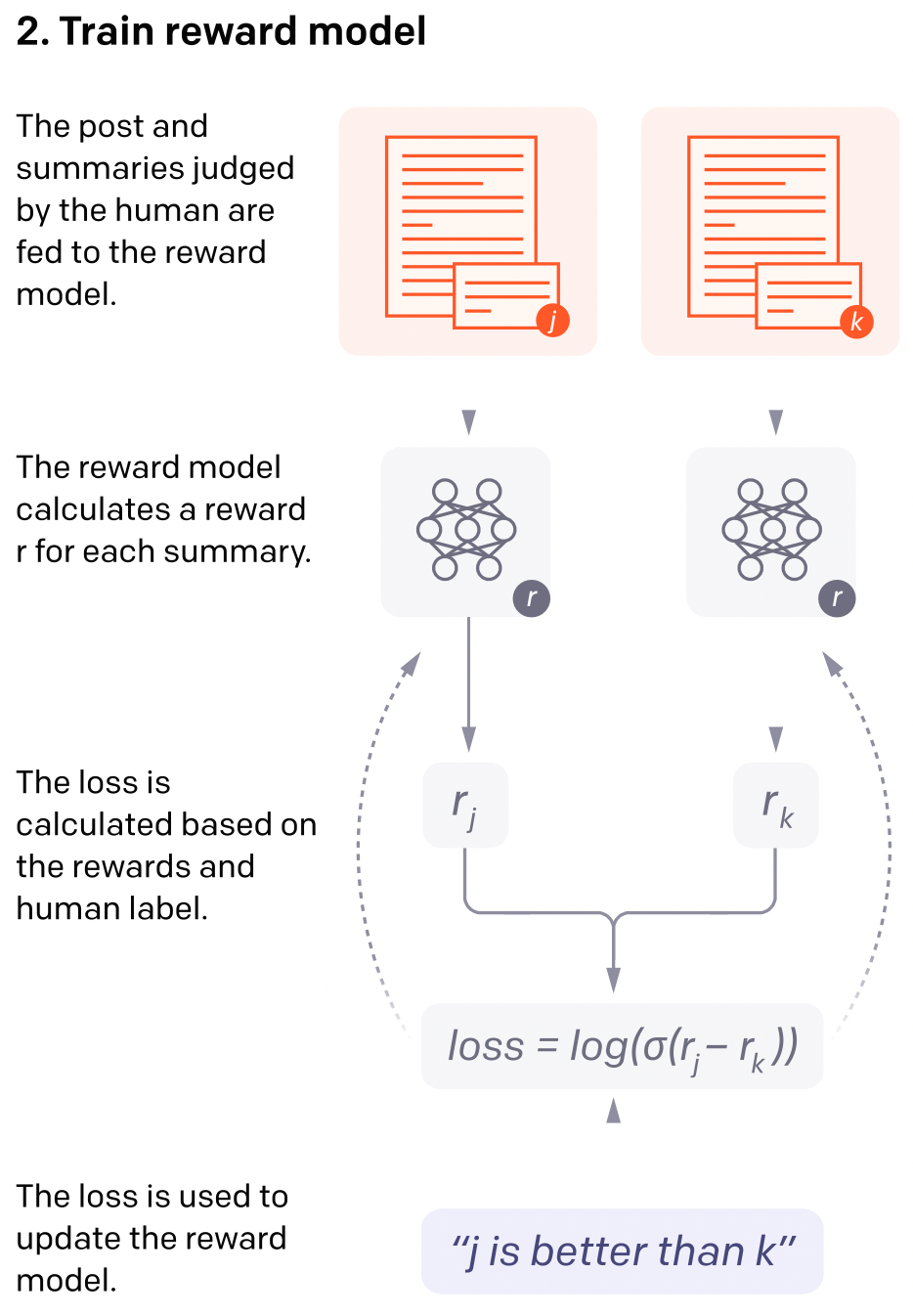
Đến đây, sau khi có RM model để huấn luyện Reward, ta tiến hành huấn luyện RL thôi. Oke, thì chúng ta ở đây cần 2 LM: một cái từ bước a và 1 cái khác. Cái LM "khác" này có đặc điểm, đó là được sử dụng một thuật toán tối ưu policy, được gọi là Proximal Policy Optimization (viết tắt là PPO), vậy nên gọi LM thứ hai này là PPO model đi cho gọn nhé. Quá trình fine-tune RL model được diễn ra như sau:
- Đầu tiên thì một prompt mới được đưa vào làm input cho quá trình.
- Sau đó thì ta tạo policy (còn gọi là , là output của LM, có thể là một phân phối xác suất của các từ vựng của output) bằng cách dùng LM ở phần a (đến lúc dùng lại cái model vừa mới cất qua một bên rồi đấy) từ những input prompt, rồi từ đó sinh văn bản.
- Cùng lúc đó thì PPO Model cũng sẽ sinh văn bản từ prompt mới được đưa vào (tại iteration thứ nhất thì bộ trọng số sẽ được khởi tạo từ SFT ở trên).
- Sau khi đã sinh văn bản rồi thì RM (đã được huấn luyện) sẽ đánh giá cái đoạn văn bản mới sinh ra đấy để cập nhật Reward Function cho PPO Model. Hàm cập nhật cho PPO được xây dựng dựa trên Kullback-Leibler Divergence (KL Divergence) nên sẽ có dạng: . Cụ thể hơn thì:
Trong đó là output của RM, là một hyper-parameter, là policy sẽ được tối ưu bởi PPO và là policy từ model SFT đã đề cập trong các phần trên. Thứ mình càn tối ưu ở đây đó là PPO thôi. Việc sử dụng KL Divergence là nhằm để đảm bảo output được sinh ra không khác biệt quá nhiều (về mặt phân phối) so với những gì mà RM đã được train. Quá trình tối ưu này cứ tiếp tục lặp đi lặp lại như vậy.
Phù, cuối cùng cũng xong, hơi lòng vòng khó hiểu nhỉ. Nhưng mà, nó cũng chính là cách hoạt động của ChatGPT đấy.
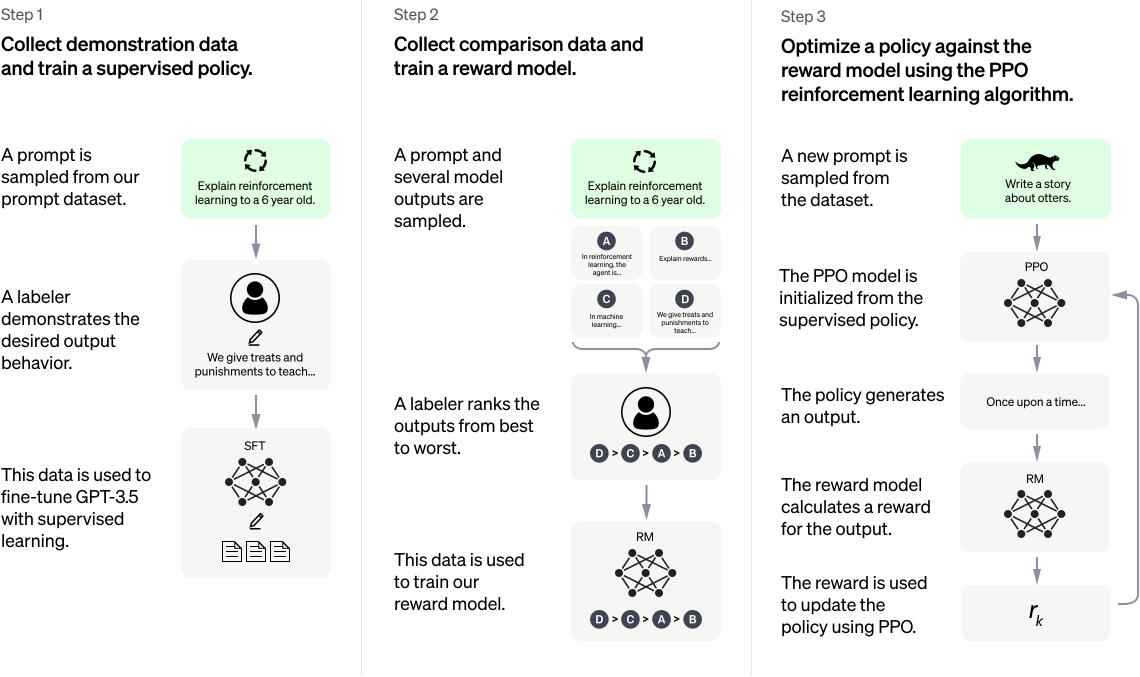
3. Cách ChatGPT hoạt động
Căn bản là...gần y hệt những gì mình viết ở trên luôn. Không tin thì mọi người cứ nhìn vào diagram ở dưới rồi so sánh với những gì mình viết ở trên nhé. Vì dựa trên Human Feedback nên chatbot này có khả năng nói chuyện như một con người. Có thể tóm gọn quy trình này qua 3 bước sau:
- Đầu tiên thì chúng ta sẽ thực hiện fine-tune đối với 1 LLM (ở đây là GPT-3) để tạo ra GPT-3.5, là một model supervised-learning từ bộ data có sẵn (SFT model).
- Sau đó thì hàng loạt sample được tạo ra và con người sẽ đánh giá, chấm điểm từng sample để tạo ra data huấn luyện RM.
- Bước cuối thì khi đã có SFT model và RM, chúng ta thực hiện tối ưu policy bằng thuật toán PPO để output trông "thật" nhất có thể.
Xong, thế là mình đã chia sẻ về RLHF và cách ChatGPT hoạt động. Hơi lòng vòng phức tạp nhưng đây là một phương pháp hay để huấn luyện chatbot sao cho trả lời giống người thật. Mọi người có ý kiến hay chỉnh sửa gì thì cho mình biết nhé. Cheers.
Tài liệu tham khảo
Understanding Reinforcement Learning from Human Feedback (RLHF): Part 1
Illustrating Reinforcement Learning from Human Feedback (RLHF)
All rights reserved
