Research on association rules
Lời mở đầu
Với sự phát triển của công nghệ thông tin thì khối lượng dữ liệu lưu trữ ngày càng lớn, và giữa những lượng dữ liệu khổng lồ đó lại ẩn chứa một số thông tin được coi là chìa khóa dẫn đến thành công của mọi lĩnh vực từ hoạt động sản xuất đến kinh doanh. Việc khai thác, chiếc lọc thông tin ứng dụng vào cuộc sống của con người không chỉ dừng lại là một kĩ thuật đơn thuần, nó đòi hỏi sự ra đời của ngành khoa học mới: khoa học về phát hiện tri thức và khai phá dữ liệu.

Các kĩ thuật khai phá dữ liệu:
a.Mô tả khái niệm (concept description): thiên về mô tả, tổng hợp và tóm tắt khái niệm.
b.Luật kết hợp (association rules): là dạng luật biểu diễn tri thứ ở dạng khá đơn giản.
c.Phân lớp và dự đoán (classification & prediction): xếp một đối tượng vào một trong những lớp đã biết trước. Như khi phân lớp vùng địa lý theo dữ liệu thời tiết. Hướng tiếp cận này thường sử dụng một số kỹ thuật của machine learning như cây quyết định (decision tree), mạng nơ ron nhân tạo (neural network), .v.v. Người ta còn gọi phân lớp là học có giám sát (học có thầy)
d.Phân cụm (clustering): xếp các đối tượng theo từng cụm (số lượng cũng như tên của cụm chưa được biết trước. Người ta còn gọi phân cụm là học không giám sát (học không thầy).
e.Khai phá chuỗi (sequential/temporal patterns): tương tự như khai phá luật kết hợp nhưng có thêm tính thứ tự và tính thời gian. Hướng tiếp cận này được ứng dụng nhiều trong lĩnh vực tài chính và thị trường chứng khoán vì nó có tính dự báo cáo.
Xác định bài toán
Hiện nay, khai phá dữ liệu trở nên khá phổ biến trong lĩnh vực bán lẻ và là phương pháp phân tích hiệu quả cho phát hiện thông tin hữu ích và chưa biết trong dữ liệu bán lẻ. Việc sắp xếp tổ chức hàng hoá và các hoạt động kinh doanh có liên quan nhằm nâng cao sự hài lòng của khách hàng là một trong những công việc rất quan trọng. Nghiên cứu này sẽ tập trung phân tích, khai phá và tìm ra luật kết hợp dựa trên dữ liệu của quá khứ, từ đó đề xuất một số kiến nghị để hỗ trợ cho hoạt động kinh doanh.
Khi một người đi mua sắm, thường sẽ nghĩ trong đầu 1 vài sản phẩm dự định mua. Và giỏ hàng của mỗi người sẽ khác nhau tùy vào sở thích và nhu cầu sử dụng.
Hẳn ai ban đầu cũng sẽ phải ngạc nhiên khi biết siêu thị Walmart bày trí những quầy bia và quầy bỉm cạnh nhau. Nghe chừng đây có vẻ là ý tưởng hết sức quái đản. Tuy nhiên chiến thuật này lại thực sự thành công và ảnh hưởng mạnh tới doanh số. Bạn hãy tưởng tượng một tình huống thú vị là một ông bố vào siêu thị mua đồ bỉm sữa cho con và rồi quay sang bên cạnh lại đụng món khoái khẩu và trường hợp ngược lại. WalMart tìm được quy luật này dựa trên nghiên cứu dữ liệu hành vi mua hàng của họ "Có 60% đàn ông đi siêu thị vào tối thứ 6, nếu họ mua bỉm cho trẻ em thì sẽ mua cả bia." Từ đó ta có thể nhận thấy rằng chúng ta hoàn toàn có thể tìm ra được mối quan hệ tương quan, kết hợp giữa các đối tượng để tạo ra giá trị cao hơn.
Một tiệm bánh ở Edinburgh muốn tăng số lượng sản phẩm bán của họ bằng cách sắp xếp lại các sản phẩm có khả năng được mua cùng nhau nhiều nhất. Khi một khách hàng A mua bánh mì thì họ có muốn mua thêm trà hay bánh ngọt nữa hay không? Và một khách hàng sẽ không thể biết hết những sản phẩm mà cửa hàng bán và cũng rất tốn thời gian để họ đi hết 1 vòng cửa hàng để xem qua tất cả các loại sản phẩm hiện có Chính vì vậy mà sắp xếp lại gian hàng cũng như lên các chiến lược quảng cáo các sản phẩm mới của cửa hàng là việc hoàn toàn cấp thiết .
Đứng ở góc độ là một nhà quản lý cửa hàng, nhân viên báng hàng sẽ quan tâm đến một khách hàng là nam / nữ , trẻ / lớn tuổi ,… đến cửa hàng sẽ mua những gì? Tiếp đến sau khi đã có thứ mình cần, họ có mua thêm sản phẩm khác hay không nếu có thì họ đã có sẵn list những gì cần mua hay chưa, hoặc thể nhận thấy cần thiết mua thêm tại thời điểm mua hàng? Và việc phát sinh nhu cầu mới, sản phẩm mới có liên kết gì so với nhu cầu ban đầu khi bước vào cửa hàng? Bên cạnh đó khi nghiên cứu dữ liệu bán hàng còn giúp cho nhân viên có sự chuẩn bị tốt về nguyên vật liệu cũng như số lượng bán phù hợp tránh tình trạng thiếu sản phẩm này hay là dư thừa quá nhiều các sản phẩm không được ưu chuộng.
Phân tích giỏ hàng (Market Basket Analysis)
Là một kỹ thuật phân tích hành vi mua dựa trên lịch sử giao dịch của họ. Kỹ thuật này thường được sử dụng để nắm được thị hiếu, thói quen tiêu dùng của khách hàng. Từ đó đưa ra những chiến lược Marketing một cách hợp lý.
- Thấu hiểu hành vi khách hàng
- Tăng thị phần, tạo ra lợi thế cạnh tranh
- Tối ưu hóa hiệu quả của hoạt động bán hàng
- Tăng trưởng doanh thu
Giới thiệu luật kết hợp và thuật toán Apriori
1. Luật kết hợp:
Được giới thiệu từ năm 1993, bài toán khai phá luật kết hợp nhận được rất nhiều sự quan tâm của nhiều nhà khoa học. Ngày nay việc khai thác các luật như thế vẫn là một trong những phương pháp khai thác mẫu phổ biến nhất trong việc khai phá tri thức và khai phá dữ liệu.
Luật kết hợp là mối quan hệ giữa các tập thuộc tính trong cơ sở dữ liệu, là phương tiện hữu ích để khám phá các mối liên kết trong dữ liệu. Một luật kết hợp là một mệnh đề kéo theo có dạng X → Y, trong đó X, Y ⊆ I, thỏa mãn điều kiện X giao Y =Ø. Tập X gọi là nguyên nhân [ Tiền đề ], tập Y gọi là hệ quả.
Có 3 độ đo quan trọng:
- Độ hỗ trợ ( support): mức độ phổ biến
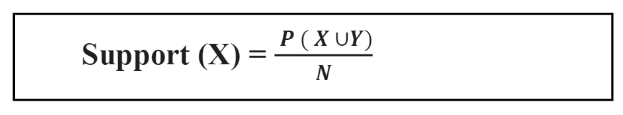
- Độ tin cậy (confidence): Nếu vế trái xảy ra thì có bao nhiêu % vế phải xảy ra theo.
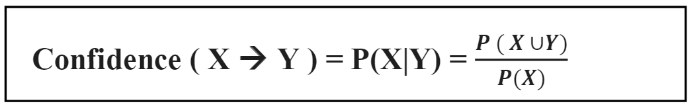
- Lift: đề cập đến sự gia tăng tỷ lệ bán B khi A được bán. Là tỉ số giữa confidence và tỉ lệ trường hợp hiện diện X.

Một số đính nghĩa quan trọng khác:
- Tập mục:
Gọi I = { x1,x2,..,xn } là tập có n mục ( item) . Một tập X ⊆ I được gọi là một tập mục ( itemset).
- Nếu X có k mục (tức |X| = k) thì X được gọi là k–itemset.
Ví dụ: Tập tất cả các mặt hàng thực phẩm trong siêu thị: I = {sữa, trứng, đường, bánh mỳ, mật ong, mứt, bơ, thịt bò, giá, . . . }.
- Giao dịch:
Ký hiệu D = {T1,T2, . . . , Tm} là cơ sở dữ liệu gồm m giao dịch (transaction).
Mỗi giao dịch Ti ∈ D là một tập mục, tức Ti ⊆ I.
Tập mục I là các sản phẩm trong siệu thị, Cơ sở giao dịch là những đơn mua của khách hàng.
T1 = {sữa, trứng, đường, bánh mỳ}
T2 = {sữa, mật ong, mứt, bơ}
T3 = {trứng, mì tôm, thịt bò, giá}
- Tập phổ biến:
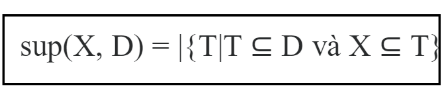
Độ hỗ trợ của X (sup(X, D)): là số lượng giao dịch trong D chứa tập X:
Độ hỗ trợ tương đối của X (rsup(X, D)) : là số phần trăm các giao dịch trong D chứa X:
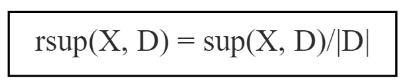
Độ hỗ trợ tối thiểu kí hiệu là minsup là một giá trị cho trước bởi người sử dụng được xác định trước khi sinh ra luật. Nếu tập mục X có sup(X) ≥ minsup thì ta nói X là tập mục phổ biến. Một tập mục phổ biến được sử dụng như một tập đáng quan tâm trong các thuật toán, ngược lại, những tập không phải tập phổ biến là những tập không đáng quan tâm.
Tuy nhiên, không phải bất cứ luật kết hợp nào có mặt trong tập các luật có thể được sinh ra cũng đều có ý nghĩa trên thực tế. Mà các luật đều phải thỏa mãn một ngưỡng hỗ trợ và tin cậy cụ thể. Với một tập các giao dịch D, bài toán phát hiện luật kết hợp là sinh ra tất cả các luật kết hợp mà có conf>minconf và sup > minsup tương ứng do người dùng xác định . Khai phá luật kết hợp được phân thành hai bài toán con:
a. Tìm tất cả các tập mục mà có độ hỗ trợ lớn hơn độ hỗ trợ tối thiểu. Các tập mục thõa mãn được gọi là các tập mục phổ biến.
b. Dùng các tập mục phổ biến để sinh ra các luật mong muốn.
Một số hướng chính tiếp cận sau đây:
a. Luật kết hợp nhị phân (Binary association rule): là hướng nghiên cứu đầu tiên của luật kết hợp. Theo dạng luật kết hợp này thì các items chỉ được quan tâm là có hay không xuất hiện trong cơ sở dữ liệu giao tác (Transaction database) chứ không quan tâm về mức độ hay tần xuất xuất hiện. Thuật toán tiêu biểu nhất của khai phá dạng luật này là thuật toán Apriori.
b. Luật kết hợp có thuộc tính số và thuộc tính hạng mục (Quantitative and categorial association rule): các cơ sở dữ liệu thực tế thường có các thuộc tính đa dạng (như nhị phân, số, mục (categorial),...) chứ không nhất quán ở một dạng nào cả. Vì vậy để khai phá luật kết hợp với các cơ sở dữ liệu này các nhà nghiên cứu đề xuất một số phương pháp rời rạc hóa nhằm chuyển dạng luật này về dạng nhị phân để có thể áp dụng các thuật toán đã có.
c. Luật kết hợp tiếp cận theo hướng tập thô (mining association rule base on rough set): tìm kiếm luật kết hợp dựa trên lí thuyết tập thô.
d. Luật kết hợp nhiều mức (multi-level association ruls): với cách tiếp cận luật kết hợp thế này sẽ tìm kiếm thêm những luật có dạng: mua máy tính PC
→ mua hệ điều hành Window AND mua phần mềm văn phòng Microsoft
Office,…
e. Luật kết hợp mờ (fuzzy association rule): Với những khó khăn gặp phải khi rời rạc hóa các thuộc tính số, các nhà nghiên cứu đề xuất luật kết hợp mờ khắc phục hạn chế đó và chuyển luật kết hợp về một dạng gần gũi hơn.
f. Luật kết hợp với thuộc tính được đánh trọng số (association rules with weighted items): Các thuộc tính trong cơ sở dữ liệu thường không có vai trò như nhau. Có một số thuộc tính quan trọng và được chú trọng hơn các thuộc tính khác. Vì vậy trong quá trình tìm kiếm luật các thuộc tính được đánh trọng số theo mức độ xác định nào đó.
g. Khai thác luật kết hợp song song (parallel mining of association rule): Nhu cầu song song hóa và xử lý phân tán là cần thiết vì kích thước dữ liệu ngày càng lớn nên đòi hỏi tốc độ xử lý phải được đảm bảo.Trên đây là những biến thể của khai phá luật kết hợp cho phép ta tìm kiếm luật kết hợp một cách linh hoạt trong những cơ sở dữ liệu lớn. Bên cạnh đó các nhà nghiên cứu còn chú trọng đề xuất các thuật toán nhằm tăng tốc quá trình tìm kiếm luật kết hợp trong cơ sở dữ liệu.
2. Thuật toán Apriori:
Thuật toán Apriori được công bố bởi R. Agrawal và R. Srikant vào năm 1994 vì để tìm các tập phổ biến trong một bộ dữ liệu lớn. Tên của thuật toán là Apriori vì nó sử dụng kiến thức đã có từ trước (prior) về các thuộc tính, vật phẩm thường xuyên xuất hiện trong cơ sở dữ liệu. Để cải thiện hiệu quả của việc lọc các mục thường xuyên theo cấp độ, một thuộc tính quan trọng được sử dụng gọi là thuộc tính Apriori giúp giảm phạm vi tìm kiếm của thuật toán.
Tất cả các tập hợp con không rỗng của tập thường xuyên cũng phải thường xuyên. Khái niệm chủ chốt này của thuật toán Apriori nhằm chống lại đơn điệu của phương pháp tính theo độ hỗ trợ (surport). Apriori cho rằng:
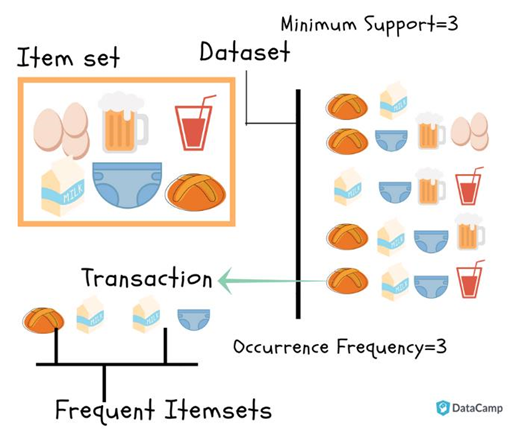
Tất cả các tập con của một tập hợp thường xuyên phải là thường xuyên (thuộc tính Apriori).Trong một vật phẩm không thường xuyên, tất cả các tập cha của nó sẽ không thường xuyên. Hãy xem xét các tập dữ liệu sau đây và chúng ta sẽ tìm thấy các tập thường xuyên và tạo quy tắc kết hợp cho chúng
Mục đích của thuật toán:
Thuật toán giúp tìm ra mối quan hệ giữa các đối tượng trong khối lượng lớn dữ liệu. Việc thuật toán Apriori có thể làm là nhìn vào quá khứ và khẳng định rằng nếu một việc gì đó xảy ra thì sẽ có tỉ lệ bao nhiêu phần trăm sự việc tiếp theo sẽ xảy ra. Nó giống như nhìn vào quá khứ để dự đoán tương lai và việc này rất có ích cho các nhà kinh doanh.
Trình tự:
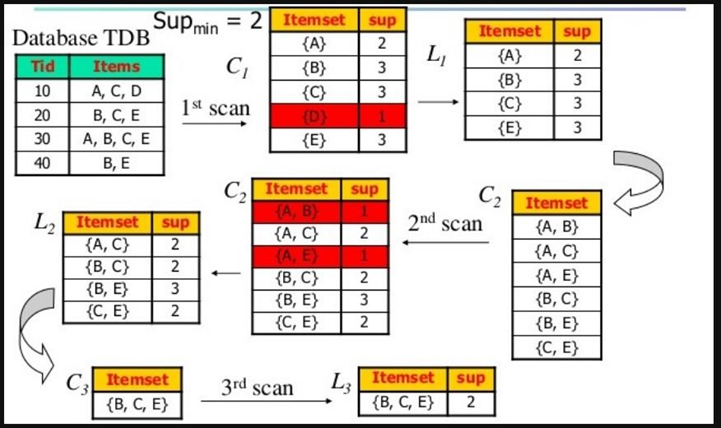
1. Duyệt (Scan) toàn bộ transaction database để có được support S của 1-itemset, so sánh S với min_sup, để có được 1-itemset (L1)
2. Sử dụng Lk-1 nối (join) Lk-1 để sinh ra candidate k-itemset. Loại bỏ các itemsets không phải là frequent itemsets thu được k-itemset
3. Scan transaction database để có được support của mỗi candidate k-itemset, so sánh S với min_sup để thu được frequent k –itemset (Lk)
4. Lặp lại từ bước 2 cho đến khi Candidate set (C) trống (không tìm thấy frequent itemsets)
5. Với mỗi frequent itemset I, sinh tất cả các tập con s không rỗng của I
6. Với mỗi tập con s không rỗng của I, sinh ra các luật s => (I-s) nếu độ tin cậy (Confidence) của nó > =min_conf
Trên đây là bài soạn tự tìm hiểu của em, nếu có gì sai sót mong mọi người bỏ qua và góp ý thêm❤.
NGUỒN THAM KHẢO:
All rights reserved
