Thuật toán Apriori khai phá luật kết hợp trong Data Mining
Bài đăng này đã không được cập nhật trong 6 năm
Bài toán khai thác tập phổ biến (frequent itemset) là bài toán rất quan trọng trong lĩnh vực data mining. Bài toán khai thác tập phổ biến là bài toán tìm tất cả tập các hạng mục (itemset) S có độ phổ biến (support) thỏa mãn độ phổ biến tối thiểu minsupp: supp(S) \geq minsupp.
Dựa trên tính chất của tập phổ biến, ta có phương pháp tìm kiếm theo chiều rộng (thuật toán Apriori (1994)) hay phương pháp phát triển mẫu (thuật toán FP-Growth (2000)). Trong bài viết này, ta sẽ nói về Apriori cùng với một số ví dụ minh họa khi chạy thuật toán này.
Thuật toán Apriori
Thuật toán Apriori được công bố bởi R. Agrawal và R. Srikant vào năm 1994 vì để tìm các tập phổ biến trong một bộ dữ liệu lớn. Tên của thuật toán là Apriori vì nó sử dụng kiến thức đã có từ trước (prior) về các thuộc tính, vật phẩm thường xuyên xuất hiện trong cơ sở dữ liệu. Để cải thiện hiệu quả của việc lọc các mục thường xuyên theo cấp độ, một thuộc tính quan trọng được sử dụng gọi là thuộc tính Apriori giúp giảm phạm vi tìm kiếm của thuật toán.
Các khái niệm cơ bản
Để minh họa cho các khái niệm, ta lấy ví dụ CSDL với các giao dịch sau. | TID (mã giao dịch) | Itemset (tập các hạng mục) | 1 | A, B, E 2 | B, D 3 | B, C 4 | A, B, D 5 | A, C 6 | B, C 7 | A, C 8 | A, B, C, E 9 | A, B, C
- Hạng mục (item): mặt hàng A = apple, B = bread, C = cereal, D = donuts, E = eggs.
- Tập các hạng mục (itemset): danh sách các hạng mục trong giỏ hàng như {A, B, C, D, E}.
- Giao dịch (transaction): tập các hạng mục được mua trong một giỏ hàng, lưu kèm với mã giao dịch (TID).
- Mẫu phổ biến (frequent item): là mẫu xuất hiện thường xuyên trong tập dữ liệu như {A, C} xuất hiện khá nhiều trong các giao dịch.
- Tập k-hạng mục (k-itemset): ví dụ danh sách sản phẩm (1-itemset) như {A, B, C}, danh sách cặp sản phẩm đi kèm (2-itemset) như {{A, B}, {A, C}}, danh sách 3 sản phẩm đi kèm (3-itemset) như {{A, B, C}, {B, C, E}}.
- Độ phổ biến (support): được tính bằng supp(X) = \frac{count(X)}{|D|}. X = {B, C} là tập các hạng mục, D là cơ sở dữ liệu (CSDL) giao dịch.
- Tập phổ biến (frequent itemset): là tập các hạng mục S (itemset) thỏa mãn độ phổ biến tối thiểu (minsupp – do người dùng xác định như 40% hoặc xuất hiện 5 lần). Nếu supp(S) \geq minsupp thì S là tập phổ biến.
- Tập phổ biến tối đại (max pattern) thỏa supp(X) \geq minsupp không tồn tại |X’| > |X|, với X’ cũng phổ biến
- Tập phổ biến đóng (closed pattern) thỏa supp(S) \geq minsupp không tồn tại |X’| > |X| mà supp(X’) = supp(X)
- Luật kết hợp (association rule): kí hiệu X \rightarrow Y, nghĩa là khi X có mặt thì Y cũng có mặt (với xác suất nào đó). Ví dụ, A \rightarrow B; A,B \rightarrow C; B,D \rightarrow E.
- Độ tin cậy (confidence): được tính bằng conf(X) = \frac{supp(X+Y)}{supp(X)}.
Thuộc tính Apriori
Tất cả các tập hợp con không rỗng của tập thường xuyên cũng phải thường xuyên. Khái niệm chủ chốt này của thuật toán Apriori nhằm chống lại đơn điệu của phương pháp tính theo độ hỗ trợ (surport). Apriori cho rằng:
Tất cả các tập con của một tập hợp thường xuyên phải là thường xuyên (thuộc tính Apriori).Trong một vật phẩm không thường xuyên, tất cả các tập cha của nó sẽ không thường xuyên. Hãy xem xét các tập dữ liệu sau đây và chúng ta sẽ tìm thấy các tập thường xuyên và tạo quy tắc kết hợp cho chúng.
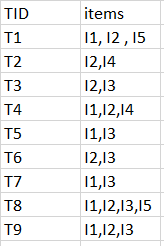
min support là 2 min confidence là 60%
Bước 1: K = 1 (I) Tạo bảng chứa số support của từng mục có trong tập dữ liệu - Được gọi là C1 (tập ứng cử viên)
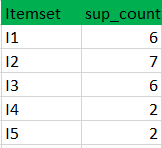
(II) so sánh số support của tập các ứng cử viên với số lượng hỗ trợ tối thiểu (ở đây min_support = 2 nếu support_count của tập ứng cử viên nhỏ hơn min_support sẽ xóa các tập đó). Điều này cung cấp cho chúng ta mục L1.
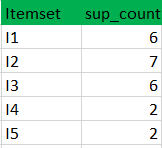
Bước 2: K = 2 Tạo tập ứng viên C2 bằng L1 (đây được gọi là bước kết hợp). Điều kiện để có thể kết hợp Lk-1 với Lk-1 là hai tập cha đó phải có K-2 (trong trường hợp này là 0) yếu tố chung . Duyệt qua các tập cha của C2, nếu tập cha nào không đạt chuẩn thường xuyên thì tập con đó sẽ bị xóa. (Ví dụ tập hợp con của {I1, I2} là {I1}, {I2} để kiểm tra độ thường xuyên thường xuyên. Kiểm tra cho từng mục) Bây giờ tính độ thường xuyên của các tập con mới được tạo.
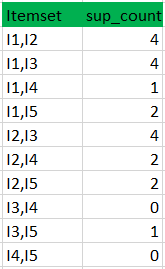
Tiếp tục kiểm tra độ thường xuyên của các tập trong C2, nếu tập nào không thỏa mãn min_support thì xóa đi. Ta sẽ nhận được kết quả là tập L2.
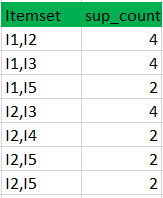
Bước 3: K = 3
- Lặp lại quy trình như bước 2 ta được hai tập.
- C3:
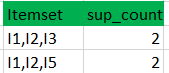
- L3:
Cứ tiếp tục lặp lại đến khi tập Cn không còn phần tử nào nữa.
Từ đó, chúng ta đã phát hiện ra tất cả các tập vật phẩm thường xuyên. Bây giờ tính mạnh mẽ, bền chặt của một tập vật phẩm được chú ý tới. Cho rằng chúng ta cần tính toán sự tự tin của từng tập.
Sự tự tin - Độ tin cậy 60% có nghĩa là 60% khách hàng mà mua sữa và bánh mì cũng sẽ mua bơ.
Confidence(A->B)=Support_count(A∪B)/Support_count(A) Ở đây tôi sẽ lấy ví dụ với các tập thường xuyên ta tìm được ở trên
[I1^I2]=>[I3] //confidence = sup(I1^I2^I3)/sup(I1^I2) = 2/4*100=50%
[I1^I3]=>[I2] //confidence = sup(I1^I2^I3)/sup(I1^I3) = 2/4*100=50%
[I2^I3]=>[I1] //confidence = sup(I1^I2^I3)/sup(I2^I3) = 2/4*100=50%
[I1]=>[I2^I3] //confidence = sup(I1^I2^I3)/sup(I1) = 2/6*100=33%
[I2]=>[I1^I3] //confidence = sup(I1^I2^I3)/sup(I2) = 2/7*100=28%
[I3]=>[I1^I2] //confidence = sup(I1^I2^I3)/sup(I3) = 2/6*100=33%
Với kết quả trên, nếu độ tin cậy tối thiểu là 50%, thì 3 quy tắc đầu tiên có thể được coi là quy tắc kết hợp mạnh mẽ.
Ứng dụng của thuật toán Apriori
Sau khi đã biết thuật toán Apriori hoạt động thế nào, giờ chúng ta sẽ tìm hiểu nó dùng để làm gì và dùng nó như thế nào :3
Dùng để làm gì?
Việc thuật toán Apriori có thể làm là nhìn vào quá khứ và khẳng định rằng nếu một việc gì đó xảy ra thì sẽ có tỉ lệ bao nhiêu phần trăm sự việc tiếp theo sẽ xảy ra. Nó giống như nhìn vào quá khứ để dự đoán tương lại vậy, và việc này rất có ít cho các nhà kinh doanh. Ví dụ một siêu thị muốn nghĩ cách sắp xếp các gian hàng một cách hợp lí nhất, họ có thể nhìn vào lịch sử mua hàng và sắp sếp các tập sản phẩm thường được mua cùng nhau vào một chỗ. Hoặc một trang web tin tức muốn giới thiệu cho người dùng các bài viết liên quan đến nhau nhất, cũng có thể áp dụng quy luật tương tự.
Dùng như thế nào?
Apriori rất tiện dụng, nhưng nó cũng có khá nhiều khuyết điểm:
- Phải duyệt CSDL nhiều lần. Với I = {i_1, i_2, ..., i_{100}}, số lần duyệt CSDL sẽ là 100.
- Số lượng tập ứng viên rất lớn: 2^{100} - 1 = 1.27 * 10^{30}.
- Thực hiện việc tính độ phổ biến nhiều, đơn điệu.
Cải tiến Apriori : ý tưởng chung
- Giảm số lần duyệt CSDL
- Giảm số lượng tập ứng viên
- Qui trình tính độ phổ biến thuận tiện hơn
All rights reserved
