Rate Limiter in System Design. Phần 2 - Các thuật toán thường được sử dụng
Bài đăng này đã không được cập nhật trong 3 năm
Ở Phần 1 mình đã giới thiệu khái quát ở mức khái niệm. Trong phần 2 này, mình sẽ đề cập đến những thuật toán thường dùng nhất khi xây dựng một hệ thống Rate Limiter. Mỗi thuật toán đều mang ưu điểm và nhược điểm của riêng nó, cùng mình tìm hiểu nhé
Leaky Bucket
Về mặt khái niệm, Leaky Bucket hoạt động như sau. Server sử dụng 1 cái xô (bucket) có kích thước cố định và đáy chứa 1 cái lỗ (output) để đựng một số lượng tokens nhất định. Token ở đây tượng trưng cho những request được gửi đến server.
Token được gởi tới server bởi user (client) và server là tác nhân cho phép token đi vào/đi ra khỏi bucket.
Để dễ hình dung hơn mọi người có thể xem hình minh hoạ bên dưới:
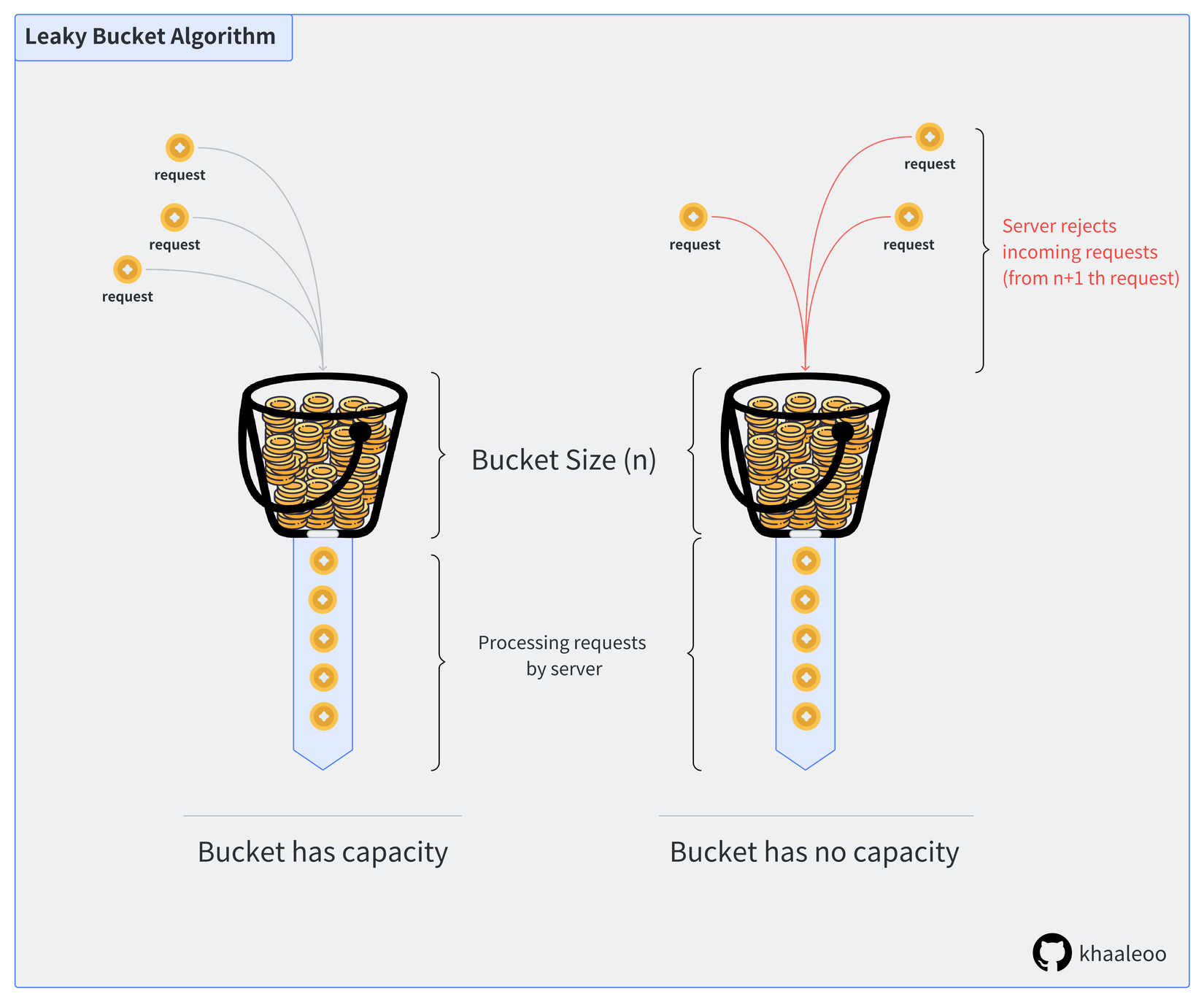
Thuật toán Leaky Bucket không quá phức tạp để triển khai cũng như bảo trì trên một server hay load balancer, việc quản lý bộ nhớ cũng đơn giản vì mọi thứ được cấu hình từ ban đầu. Vì độ chính xác cao trong khi sử dụng tài nguyên hiệu quả, rất nhiều hệ thống lớn sử dụng Leaky Bucket để làm một Rate Limiter, tiêu biểu như NGINX
Mặc dù có nhiều ưu điểm nhưng thuật toán này cũng mang một số nhược điểm sau:
- Burstiness: Một nhược điểm của thuật toán Leaky Bucket là nó không xử lý tốt các tải trọng requests đột ngột hoặc bursty. Khi một số lượng lớn yêu cầu đến cùng một thời điểm, thuật toán sẽ phải xử lý tất cả chúng trong cùng một khoảng thời gian. Điều này có thể dẫn đến quá tải và giảm hiệu suất của hệ thống.
- Chậm trong phản hồi: Thuật toán Leaky Bucket có thể dẫn đến việc chậm trong phản hồi đối với yêu cầu truy cập được thực hiện sau một khoảng thời gian đầy "đứt gãy" (interval), trong đó không có yêu cầu nào được thực hiện. Trong trường hợp này, việc "chảy" (leak) của các yêu cầu trong Bucket chỉ diễn ra khi interval kế tiếp bắt đầu, dẫn đến thời gian chờ lâu hơn để yêu cầu được xử lý.
- Thiếu linh hoạt trong việc xử lý các yêu cầu cần ưu tiên hoặc khẩn cấp.
- Lỗi triển khai thuật toán: nếu lỗi xảy ra và Bucket không được xử lý đúng cách, một số requests có thể được chấp nhận và xử lý mặc dù tỷ lệ requests đã vượt quá giới hạn được thiết lập. Điều này có thể cho phép một số lượng lớn requests tràn vào hệ thống, gây ra quá tải và có thể làm cho server trở nên không ổn định hoặc bị chậm.
Fixed Window Counter
Thuật toán Fixed Window Counter (mình sẽ gọi tắt là FWC) khác với Leaky Bucket (dùng capacity được cấp phát để kiểm soát), mà nó dựa trên thời gian. FWC chia thời gian thành các khoảng bằng nhau, và ở mỗi khoảng thời gian sẽ có một bộ đếm riêng. Khi có một request đến, dựa vào thời gian, request sẽ được phân bổ vào phần mà FWC đã định nghĩa từ trước, và bộ đếm tương ứng sẽ hoạt động (vd: tăng lên 1).
Khi bộ đếm đạt ngưỡng nhất định, request sẽ bị từ chối thực thi, phải chờ hoặc thử lại ở khoảng thời gian tiếp theo.
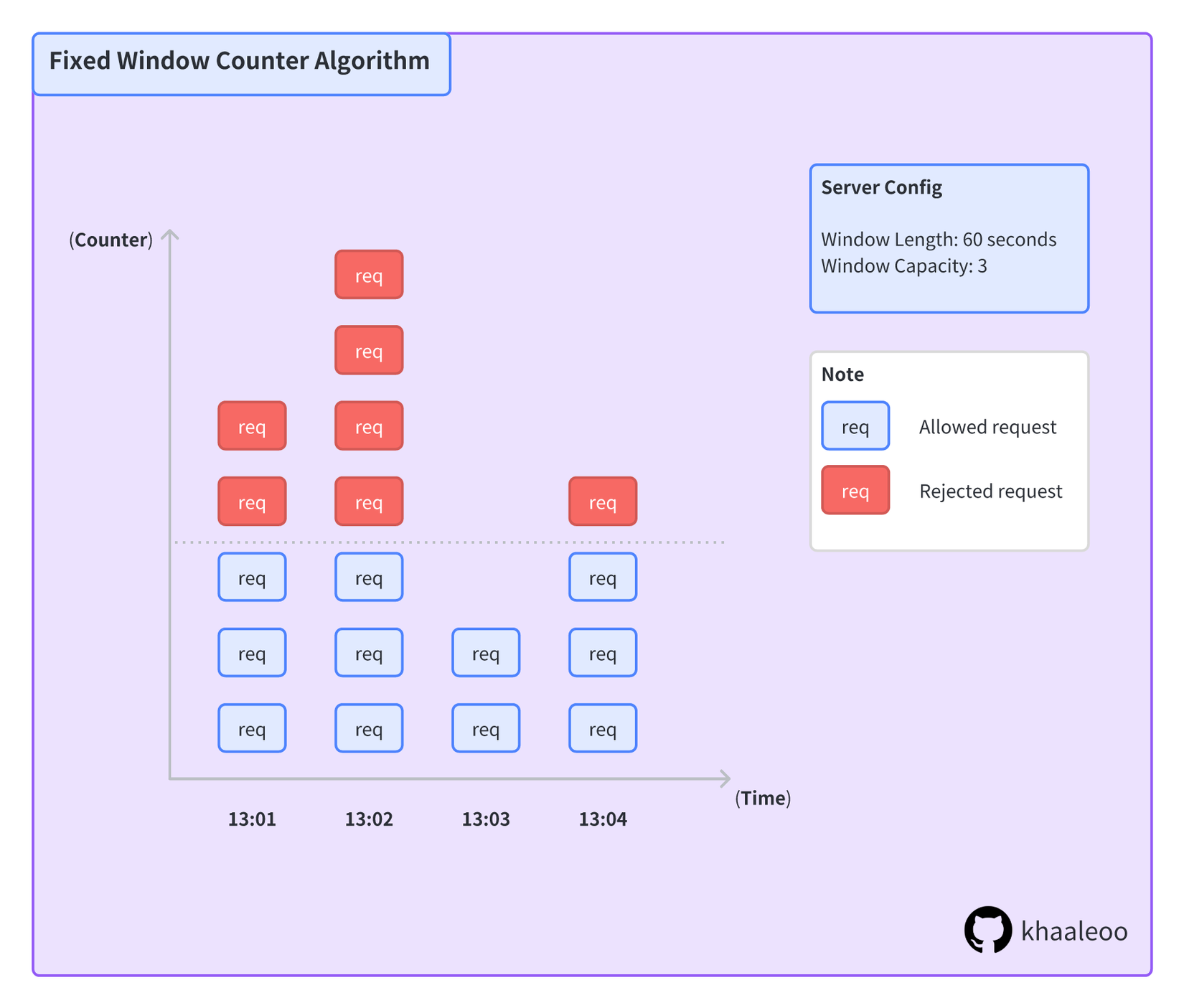
Với thuật toán Fixed Window Counter, ta có độ phức tạp như sau:
- Space Complexity: O(1) dành cho việc lưu trữ counter cho từng Window
- Time Complexity: O(1) thời gian Get và thực hiện toán tử ++ đơn giản
FWC mang lại rất nhiều ưu điểm:
- Dễ dàng triển khai
- Dung lượng bộ nhớ nhỏ hơn, chỉ dùng để lưu trữ bộ đếm Counter
- Có thể tận dụng được các công nghệ built-in concurrency (Redis)
Song vẫn tồn tại khá nhiều nhược điểm:
- Không linh hoạt: chính vì hoạt động theo cấu hình đã được định sẵn, nên sẽ không có khả năng tự scale-up trong trường hợp cần thiết. Developers cần điều chỉnh cấu hình thủ công trước mỗi campaign có lượng requests tăng vọt
- Kế thừa lỗi của Window trước đó: chung quy vẫn là sự linh hoạt, nếu window trước đó có số lượng request vượt ngưỡng quá nhiều, thì những window sau thể tự nhận biết và điều chỉnh phù hợp capacity.
- Không phân biệt được các request ưu tiên hay khẩn cấp để ưu tiên xử lý
Sliding Window Log & Sliding Window Counter
Ở hai thuật toán trên, có thể thấy tuy dễ triển khai, nhưng mỗi một thuật toán vẫn mang cho mình một số khuyết điểm nhất định. Sliding Window Log & Counter được dùng giảm bớt những khó khăn đó.
Thuật toán Sliding Window Log - Counter (SWLC) lưu trữ và hành xử dựa trên tác nhân thực thi, ở đây khi một request được gởi đến server, hệ thống sẽ định danh request dựa vào một số tiêu chí nhất định (token, IP,...)
SWLC thường sử dụng SLA table, nơi sẽ log lại toàn bộ hành động của user, đơn giản là key-value bao gồm key là (token, IP) và value là requested data mà user gửi đến.
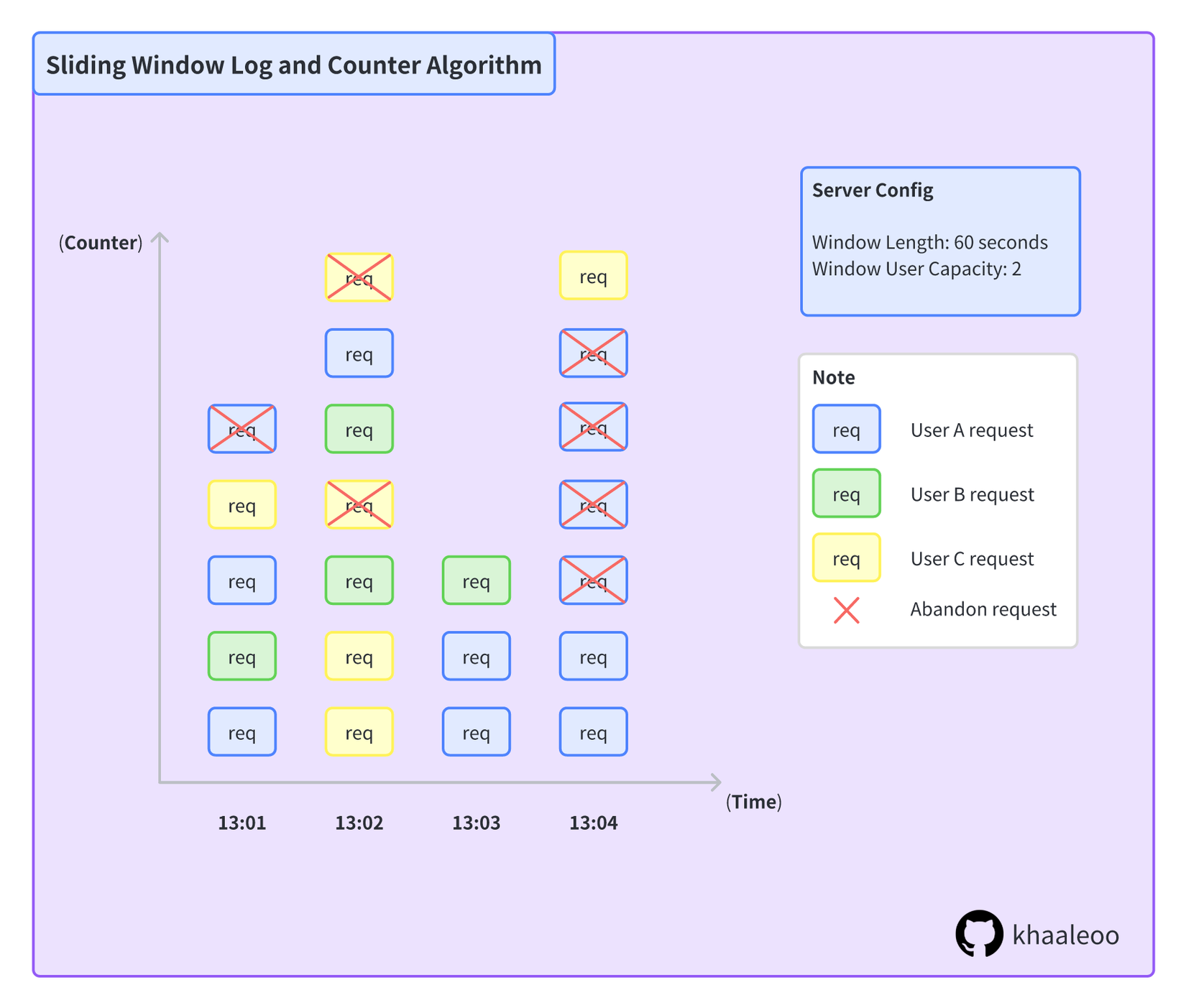
Như hình mô tả về thuạt toán Sliding Window Log & Counter ở trên. Với từng window, luôn luôn có tối đa số lượng request của một user là 2, counter sẽ xác định và từ chối tất cả các request thứ ba của một user trong cùng một khoảng thời gian.
Ở mức độ cơ bản nhất, Sliding Window Log & Counter có độ phức tạp như sau:
- Space Complexity: O(số lượng requests mà server đọc trong 1 window). Để nhận biết request thuộc user/IP nào, chắc chắn server phải thực hiện công việc này.
- Time Complexity (Sliding Window Log): O(số lượng requests mà server đọc trong 1 window)
- Time Complexity (Sliding Window Counter): O(1). Đây cũng là điểm khác biệt giữa Sliding Window Counter (SWC) và Sliding Window Log (SWL). SWC chỉ lưu trữ window hiện tại (khi không có nhu cầu "look-back" ở các window trước)
Ưu điểm của thuật toán này là giải quyết những bất lợi của 2 thuật toán mình nói ở trên, cũng là sự kết hợp của ba yếu tố số lượng, tác nhân, thời gian mà mình nhắc đến ở Phần 1. Vậy nhược điểm của giải thuật này là gì?
- Khó triển khai: việc kết hợp cả 3 chắc chắn không đơn giản
- Tiêu tốn tài nguyên: tiêu tốn khá nhiều bộ nhớ dùng cho việc lưu trữ toàn bộ user trong một window
- Độ phức tạp tăng dựa trên số lượng request
Kết
Trên đây là một số thuật toán thường được sử dụng nhất khi xây dựng một hệ thông Rate Limiter. Còn giải thuật nào khác hay hơn, các bạn cho mình và mọi người biết thêm nhé!
Cảm ơn tất cả mọi người.
Xem thêm
Phần 1: Rate Limiter in System Design. Phần 1 - Khái niệm và ứng dụng
All rights reserved
