
Ra mắt mô hình “mã nguồn mở” lên tới 405 tỉ tham số, Meta AI kiếm tiền bằng cách nào?
Bài đăng này đã không được cập nhật trong 2 năm
Mở đầu
Chắc hẳn các bạn vẫn chưa quên màn ra mắt đầy ấn tượng của hệ thống các mô hình thế hệ Llama 3.1 đến từ Meta AI mà chúng ta đã cùng nhau phân tích từ tổng quan đến chi tiết ở bài viết trước, đặc biệt là "ngôi sao" sáng nhất - mô hình 405 tỉ tham số. Để tạo nên một sự kiện “bùng nổ” như vậy, Meta đã có sự chuẩn bị vô cùng kỹ lưỡng. Họ không chỉ tập trung quảng bá rầm rộ cho mô hình có kích thước lớn nhất (lên tới 820GB), mà còn công bố sự hợp tác với một dàn "cộng sự" hùng hậu. Tất cả đã tạo nên một màn chào sân đầy ấn tượng, thu hút sự chú ý của toàn bộ giới công nghệ.
Tuy nhiên, ẩn sau bề nổi hào nhoáng ấy, một câu hỏi được đặt ra: Liệu đây có phải là cách để Meta thu về lợi nhuận cho riêng mình? Phải chăng, việc tập trung vào mô hình “khổng lồ” và hệ sinh thái đối tác chính là chiến lược để Meta "hái ra tiền" từ Llama 3.1?
Cá nhân tôi cho rằng đây là một nước đi thông minh và khôn khéo của Meta. Tuy nhiên, liệu chiến lược này có đủ nhanh và đủ mạnh để "gã khổng lồ" này có thể bắt kịp các đối thủ lớn "close source" khác trên thị trường hay không? Liệu rằng Meta đã tìm ra được hướng đi hiệu quả nhất cho mình, hay đây chỉ là một bước đi liều lĩnh, "đánh cược" vị thế của mình trong cuộc đua đầy khốc liệt này? Hãy cùng tôi phân tích sâu hơn trong bài viết này.

Phần 1: Phân tích thị trường Large Language Model hiện nay
Thị trường Large Language Model (LLM) đang chứng kiến sự tăng trưởng bùng nổ về doanh thu. Minh chứng rõ ràng nhất chính là "gã khổng lồ" OpenAI với dòng sản phẩm GPT model đã và đang thống trị thị trường. Từ con số doanh thu khiêm tốn là 34 triệu USD vào năm 2021, OpenAI đã có bước nhảy vọt đáng kinh ngạc với 200 triệu USD vào năm 2022 và bùng nổ với 1,6 tỉ USD doanh thu trong năm 2023 - một con số đáng mơ ước với bất kỳ công ty công nghệ nào, đặc biệt là khi "đứa con cưng" ChatGPT của họ vướng phải vô số lùm xùm liên quan đến CEO Sam Altman.
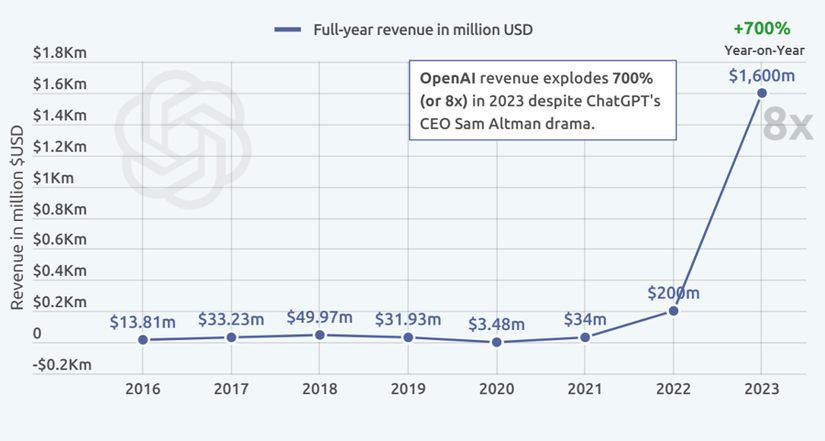
Bước sang năm 2024, dự đoán OpenAI sẽ tiếp tục duy trì tốc độ tăng trưởng ấn tượng. Theo như chia sẻ của chính CEO Sam Altman trong một cuộc họp nội bộ, OpenAI đặt mục tiêu doanh thu 3,4 tỉ USD, trong đó 3,2 tỉ USD đến từ các sản phẩm và dịch vụ (chủ yếu là API và ChatGPT Plus) và 200 triệu USD đến từ việc cung cấp các mô hình AI thông qua Microsoft Azure.
Tuy nhiên, OpenAI không phải là “tay chơi” duy nhất trong thị trường béo bở này. Anthropic - công ty được thành lập bởi cựu nhân viên OpenAI - cũng đang cho thấy tiềm năng cạnh tranh mạnh mẽ với dòng sản phẩm Claude model. Theo The Information, Anthropic dự kiến sẽ đạt mức doanh thu hàng năm hơn 850 triệu USD vào cuối năm 2024.
Với tốc độ tăng trưởng chóng mặt như hiện nay, LLM rõ ràng là "miếng bánh" không thể bỏ qua đối với bất kỳ ông lớn công nghệ nào, và Meta AI chắc chắn không phải là ngoại lệ.
Phần 2: Hướng đi phù hợp cho "những kẻ xuất phát sau"
Nhận thấy tiềm năng to lớn của thị trường LLM, nhiều “ông lớn” công nghệ đã nhanh chóng tham gia cuộc đua, trong đó có Google với Bard và Gemini. Mặc dù đạt được những thành công nhất định, nhưng có vẻ như họ vẫn chưa thể bắt kịp hoàn toàn hai "tay đua" dẫn đầu là OpenAI và Anthropic.
Vậy đâu là hướng đi phù hợp cho "những kẻ xuất phát sau" như Meta?
Thay vì "đối đầu trực tiếp" trong cuộc đua tạo ra chatbot thông minh - sân chơi mà OpenAI và Anthropic đang thống trị, Meta đã lựa chọn một hướng đi khác, tận dụng tối đa thế mạnh của mình.
Meta sở hữu lợi thế vô cùng lớn về dữ liệu. Nền tảng Facebook, Instagram và Messenger cung cấp cho họ nguồn dữ liệu khổng lồ, đa dạng và liên tục được cập nhật từ hàng tỷ người dùng trên toàn thế giới. Đây chính là "mỏ vàng" để Meta huấn luyện các mô hình AI mạnh mẽ.
Tuy nhiên, "con dao hai lưỡi" của nguồn dữ liệu khổng lồ này chính là vấn đề bảo mật thông tin. Meta từng vướng phải nhiều lùm xùm liên quan đến việc sử dụng dữ liệu người dùng. Chính vì vậy, việc Meta không thể ra mắt các phiên bản multimodal của Llama tại thị trường EU - nơi có quy định nghiêm ngặt về bảo mật - cũng là điều dễ hiểu. Họ cũng không công bố cụ thể về nguồn dữ liệu được sử dụng để huấn luyện Llama.
Chính vì không phụ thuộc vào việc cung cấp API hay tạo ra chatbot để thu thập dữ liệu người dùng như các đối thủ, Meta hoàn toàn có thể tự tin với hướng đi riêng của mình. Vậy chiến lược của "gã khổng lồ" này là gì? Chúng ta sẽ cùng tìm hiểu trong phần tiếp theo.
Phần 3: Tung ra những mô hình mã nguồn mở, Meta kiếm tiền bằng cách nào?
Với những gì Meta đang có trong tay và bức tranh toàn cảnh thị trường LLM lúc bấy giờ, việc lựa chọn con đường cung cấp mô hình "mã nguồn mở" là một quyết định hết sức hợp lý bởi nhiều lý do:
1. Tiếp cận nhanh chóng cộng đồng chuyên gia: "Mã nguồn mở" như một lời mời gọi đầy hấp dẫn, cho phép Meta AI nhanh chóng tiếp cận cộng đồng đông đảo các nhà phát triển, các chuyên gia AI - những người luôn khát khao khám phá, tìm tòi những công nghệ mới, đồng thời rất coi trọng sự minh bạch và khả năng tùy biến. Việc cung cấp miễn phí mô hình sẽ thúc đẩy cộng đồng sử dụng, tinh chỉnh và đóng góp ngược trở lại cho sự phát triển của Llama, tạo nên một vòng tròn phát triển cộng đồng - một chiến lược đã được chứng minh là rất hiệu quả.
2. Giảm thiểu áp lực cạnh tranh: Thay vì lao vào cuộc chiến khốc liệt trên thị trường chatbot với những "ông lớn" như OpenAI hay Anthropic, Meta đã khôn khéo lựa chọn một hướng đi khác biệt. Thị trường mã nguồn mở ở thời điểm đó vẫn còn sơ khai, chưa có một "ông lớn" nào thực sự thống trị. Việc này cho phép Meta có không gian và thời gian để phát triển, hoàn thiện mô hình của mình mà không phải chịu quá nhiều áp lực cạnh tranh từ những đối thủ sừng sỏ.
3. Tối ưu hóa lợi thế về dữ liệu: "Mỏ vàng" dữ liệu khổng lồ từ Facebook, Instagram và Messenger chính là chìa khóa để Meta huấn luyện nên những mô hình AI mạnh mẽ. Tuy nhiên, việc sử dụng dữ liệu người dùng luôn là con dao hai lưỡi, đặc biệt là trong bối cảnh những lo ngại về quyền riêng tư ngày càng gia tăng. "Mã nguồn mở" cho phép Meta vừa có thể tận dụng tối đa nguồn dữ liệu này, vừa xây dựng hình ảnh một công ty công nghệ "hướng đến cộng đồng", tôn trọng quyền riêng tư của người dùng, đồng thời khéo léo né tránh những quy định ngặt nghèo về bảo mật thông tin. Việc không công bố rõ ràng nguồn dữ liệu huấn luyện cũng là một cách để Meta bảo vệ "bí mật kinh doanh" của mình.
4. Xây dựng vị thế dẫn đầu: Bằng cách cung cấp miễn phí mô hình "mã nguồn mở", Meta đang từng bước xây dựng vị thế dẫn đầu trong cộng đồng AI. Việc thu hút được đông đảo người dùng, đặc biệt là các chuyên gia, sẽ giúp Meta có được những phản hồi quý giá để cải thiện mô hình, đồng thời tạo dựng một cộng đồng vững mạnh xung quanh Llama.
Tuy nhiên, "mã nguồn mở" của Meta lại có vẻ "lạ" hơn chúng ta nghĩ. Phải chăng Meta đang "chơi chữ" với cộng đồng khi bản chất chiến lược của họ lại là một nước cờ đầy toan tính?
1. "Mã nguồn mở" nhưng không minh bạch? Mặc dù được gắn mác "mã nguồn mở", nhưng thực tế, Meta vẫn chưa công bố rõ ràng về nguồn dữ liệu được sử dụng để huấn luyện các mô hình Llama 3.1. Điều này khiến cho việc đánh giá tính minh bạch và nguồn gốc dữ liệu của mô hình trở nên khó khăn, gây tranh cãi trong cộng đồng về sự "cởi mở" thực sự của Meta.
2. "Miễn phí" nhưng không dễ tiếp cận? Meta đã tạo ra một màn "show of force" ấn tượng khi tập trung quảng bá cho mô hình 405B với kích thước "khủng" lên tới 820GB. Tuy nhiên, đây lại chính là rào cản đối với đại đa số người dùng cá nhân và các tổ chức nhỏ muốn tiếp cận và sử dụng mô hình này. Để có thể chạy được 405B, người dùng cần phải có hệ thống cơ sở hạ tầng với GPU cực "khủng", ví dụ như NVIDIA A100 vốn có giá thành lên tới hàng chục nghìn USD mỗi chiếc. Trong khi đó, chi phí sử dụng API của các mô hình tương đương như GPT-4 của OpenAI hay Claude của Anthropic, mặc dù không hề rẻ, nhưng lại tiếp cận được với nhiều đối tượng người dùng hơn.
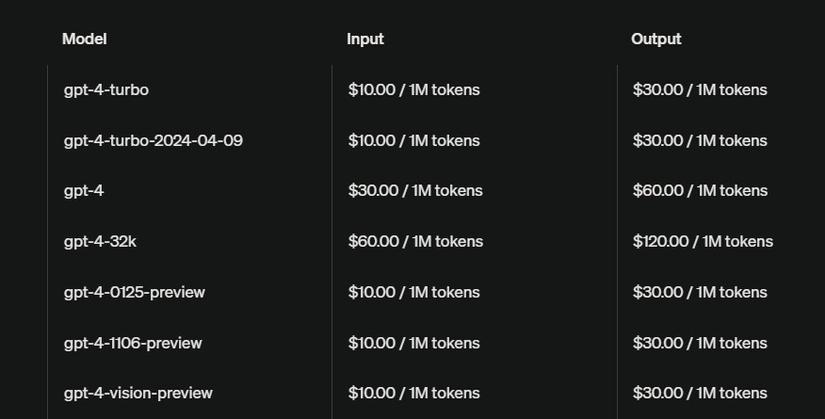
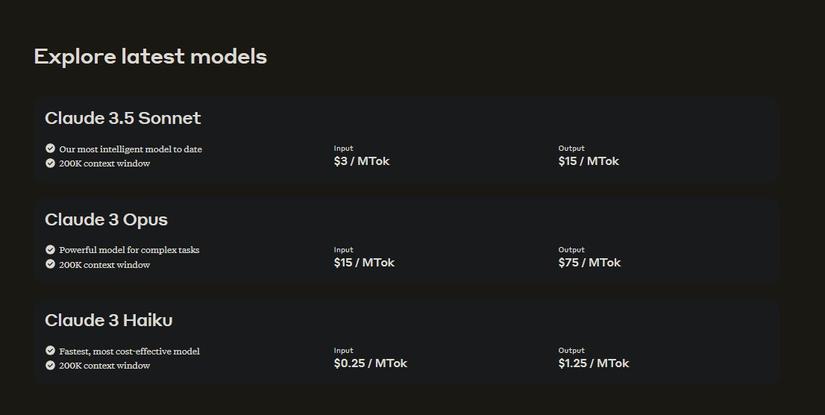
3. "Hợp tác" hay là "kinh doanh"? Nhận thức rõ ràng rào cản về kích thước và hạ tầng của 405B, Meta đã có một nước đi khôn ngoan là bắt tay với các "ông lớn" trong lĩnh vực đám mây như AWS, Azure, Databricks,... để phân phối mô hình này. Bảng giá "sử dụng" 405B được Meta công bố cho thấy rõ chiến lược "Anh em tôi có bát cơm, thì tôi cũng phải được bát cháo" này. Họ không ngần ngại "đặt bàn ăn cùng" với các đối thủ "close source", thậm chí còn tự tin khẳng định mình "vừa rẻ vừa riêng tư hơn".
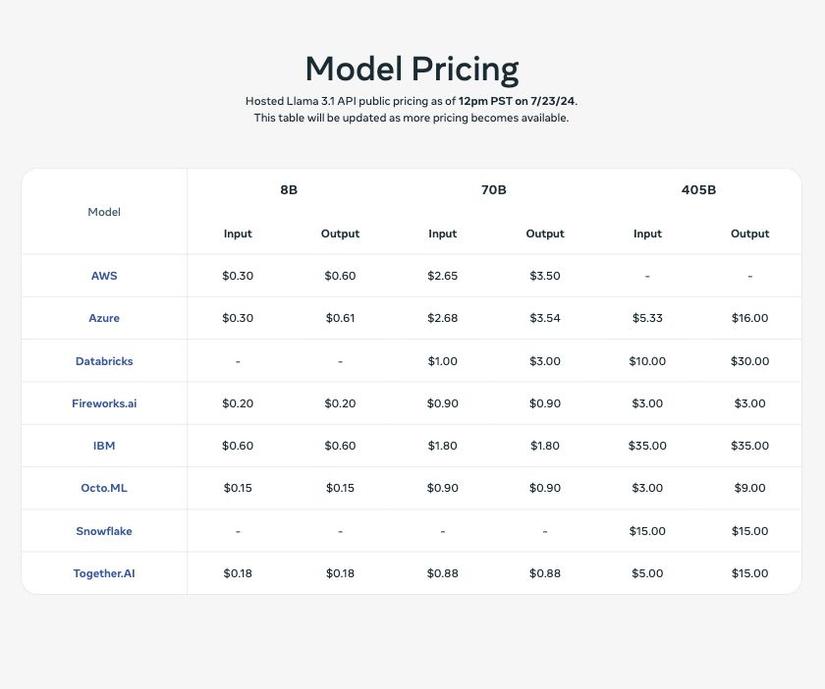
4. "Mã nguồn mở" chỉ là chiêu bài? Bên cạnh việc "phân phối" 405B, Meta cũng đồng thời ra mắt các ứng dụng tích hợp sẵn mô hình này trên chính nền tảng của mình, như chatbot tạo ảnh, xử lý đa phương tiện,... Người dùng có thể dễ dàng trải nghiệm trực tiếp các ứng dụng này trên trang chủ của Meta AI. Đây chính là lúc mà Meta "thu tiền" từ người dùng thông qua hình thức trả phí dịch vụ hoặc quảng cáo.
Rõ ràng, "mã nguồn mở" của Meta không hẳn là "miễn phí" như nhiều người vẫn nghĩ. Ẩn sau chiến lược "mở" này là cả một chiến lược "kinh doanh" bài bản và tinh vi.
Phần 4: Nước đi đủ thông minh và khôn khéo, nhưng liệu nó có đủ nhanh?
Không thể phủ nhận, Meta đã có một màn "ra quân" vô cùng ấn tượng và bài bản với Llama 3.1. Họ đã khéo léo vạch ra một chiến lược "mã nguồn mở" đầy toan tính, tối ưu hóa lợi thế về dữ liệu và nền tảng người dùng khổng lồ của mình.
Nhìn lại hành trình "bày binh bố trận" của Meta, chúng ta có thể thấy sự chuẩn bị kỹ lưỡng và bài bản của họ. Việc cung cấp miễn phí, "mã nguồn mở" các thế hệ mô hình Llama 1, 2, 3 một cách "âm thầm" nhưng đủ để cộng đồng biết đến và phổ biến chúng, cùng với việc âm thầm hợp tác với các đơn vị khác, chính là bước "dọn đường" hoàn hảo cho "con át chủ bài" 405B.
Tuy nhiên, liệu chiến lược này có đủ "nhanh"?
GPT-4 - mô hình mà Meta lựa chọn để so sánh trực tiếp với "đứa con cưng" 405B của mình, đã được OpenAI ra mắt từ ngày 14/3/2023. Trong khi đó, phải đến cuối tháng 7/2024, 405B mới chính thức được giới thiệu. Khoảng thời gian hơn một năm là quá lâu trong lĩnh vực AI đang phát triển như "vũ bão" như hiện nay. Rõ ràng, Meta đã "thua" OpenAI một bước về thời gian.
Hơn nữa, khi 405B ra đời, GPT-4 không còn là "kẻ thống trị" duy nhất. OpenAI đã âm thầm phát triển và sắp tung ra các phiên bản mạnh mẽ hơn như GPT-4.5 hay thậm chí là GPT-5. "Cuộc chơi" đã sang một trang mới với những "tay chơi" mới, quy luật mới và tốc độ mới.
Vậy liệu Meta có đủ nhanh để thích nghi và bắt kịp? Hay họ sẽ mãi chỉ là "kẻ đến sau" trong cuộc đua không hồi kết này?
Phần 5: Quan điểm - dự đoán cá nhân và kết luận
Không thể phủ nhận, Meta đã có một bước đi đầy toan tính và bài bản khi lựa chọn con đường "mã nguồn mở" cho Llama 3.1. Chiến lược này cho phép họ tối ưu hóa thế mạnh về dữ liệu, tiếp cận cộng đồng lập trình và né tránh được phần nào áp lực cạnh tranh khốc liệt trên thị trường chatbot thời điểm bấy giờ.
Tuy nhiên, tốc độ mới chính là yếu tố quyết định trong cuộc đua "cân não" này. Việc ra mắt 405B muộn hơn các đối thủ đã khiến Meta "lỡ nhịp" trong một thời gian dài. Họ chỉ có thể "vượt mặt" những "đối thủ" trong quá khứ như GPT-4 phiên bản 2023, nhưng lại phải đối mặt với những "kẻ thách thức" mới mạnh mẽ hơn rất nhiều.
Liệu rằng Meta sẽ thu hút được một lượng người dùng đáng kể với chiến lược "riêng tư và rẻ hơn"? Câu trả lời là chưa thực sự rõ ràng. Thực tế cho thấy, LLM là một lĩnh vực mà ở đó, phần lớn người dùng sẵn sàng đánh đổi một chút riêng tư để có được trải nghiệm với những AI thông minh nhất. Họ có thể "khoan dung" cho việc OpenAI thu thập dữ liệu để có được sự tiện lợi và thông minh của ChatGPT.
Có lẽ, Meta sẽ chỉ thực sự thành công trong việc thu hút những khách hàng có yêu cầu cao về bảo mật thông tin, ví dụ như các công ty bảo mật, ngân hàng,... Tuy nhiên, việc một công ty vốn nổi tiếng với những lùm xùm liên quan đến dữ liệu người dùng như Facebook lại đi đầu trong xu hướng bảo vệ quyền riêng tư nghe có vẻ hơi "mâu thuẫn".
"Ván cờ" LLM vẫn chưa ngã ngũ. Hãy cùng chờ xem Meta sẽ làm gì để thực sự trở thành "kẻ thách thức" đáng gờm trong thời gian tới và đón chờ màn phản đòn từ các "ông lớn" như OpenAI hay Anthropic!
All rights reserved
