Paper reading | Real-time Scene Text Detection with Differentiable Binarization
Bài đăng này đã không được cập nhật trong 2 năm
Động lực và đóng góp
Bài toán text detection luôn nhận được quan tâm nghiên cứu do tính ứng dụng thực tiễn của chúng. Mục tiêu là ta sẽ tìm vị trí của text trong văn bản hoặc video. Gần giống với bài toán object detection, ta có thể coi text trong ảnh là một loại 'object', do đó các phương pháp object detection cũng phù hợp với bài text detection. Tuy nhiên, các bài toán text detection thường có một số điểm khó khăn hơn object detection như sau:
- Với các text là scene text (scene text là thuật ngữ được sử dụng để chỉ văn bản xuất hiện trong cảnh quan hình ảnh, chẳng hạn như các biển quảng cáo, bảng chỉ dẫn đường, băng rôn, bìa sách hoặc bất kỳ văn bản nào xuất hiện trong các hình ảnh chụp từ môi trường thực tế) thường mang lại nhiều thách thức cho việc nhận dạng và xử lý do các yếu tố như nhiễu, độ sáng, góc độ, kích thước và kiểu chữ có thể thay đổi đáng kể.
- Các text có thể bị chồng chéo lên nhau
- Khó xác định các đoạn text nào là rời rạc hay liên kết với nhau
Hiện tại có nhiều phương pháp để giải quyết bài toán này, ta có chia theo 2 phương pháp:
- Phương pháp Regression-based
- Phương pháp Segmentation-based
Các phương pháp Segmentation-based thường được lựa chọn hơn do có thể đáp ứng được việc nhận diện được các văn bản có những hình dạng, kích thước khác nhau.
Trong bài báo, nhóm tác giả giới thiệu DBNet với mục tiêu tối ưu thời gian trong quá trình post processing trong các phương pháp segmentation-based mà yêu cầu sử dụng threshold để thực hiện nhị phân hóa (binarization), tức là để phân biệt điểm ảnh nào là background, điểm ảnh nào của text từ bản đồ xác suất (probability map).
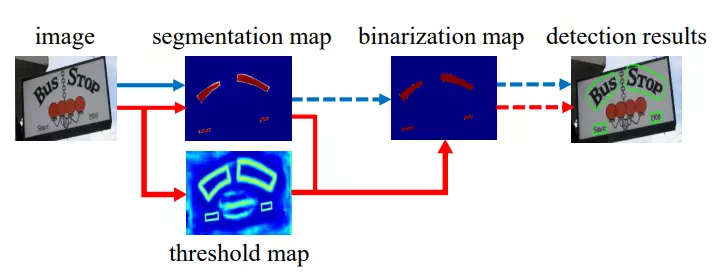
Bài báo đề xuất một learnable threshold và một binarization function để đảm bảo rằng mạng segmentation học được threshold một cách liên tục trong quá trình đào tạo. Việc điều chỉnh tự động threshold không chỉ cải thiện độ chính xác, mà còn đơn giản hóa quá trình post processing và cải thiện hiệu suất của việc phát hiện văn bản.
Phương pháp
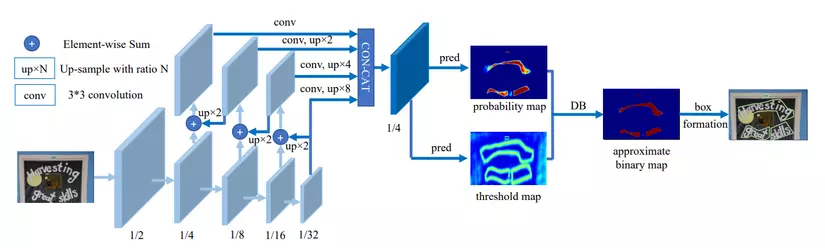
Kiến trúc bài báo đề xuất được thể hiện trong hình trên. Quá trình thực hiện của mô hình được diễn ra như sau:
- Đầu tiên, ảnh input sẽ được đưa vào một mạng feature-pyramid backbone.
- Tiếp theo, các pyramid feature được up-sample để cùng kích thước và concat lại cho ra feature .
- Sau đó, feature được sử dụng để dự đoán probability map () và threshold map (). Cuối cùng, approximate binary map () (dùng để dự đoán vị trí text trong ảnh) sẽ được tính bởi và .
Binarization
Standard binarization
Phương pháp Standard binarization nhận đầu vào là probabilty map được tạo ra từ mạng segmentation, trong đó và là chiều cao và chiều rộng của map. Ta cần chuyển probability map sang binary map trong đó pixel có giá trị 1 là vùng chứa text. Thường thì quá trình binarization được mô tả như sau:
với là một giá trị threshold cố định được định nghĩa trước và là tọa độ điểm trong map.
Differentiable binarization
Với Standard binarization có một nhược điểm là khó tìm ra được một giá trị hợp lý. Để giải quyết vấn đề này, nhóm tác giả đề xuất phương pháp Differentiable binarization và có thể tính toán đạo hàm, do đó tích hợp được vào quá trình training.
Trong đó là approximate binary map; là adaptive threshold map được học từ mô hình; là chỉ số khuếch đại, thường được đặt là 50. Phương pháp này kết hợp sử dụng adaptive threshold không chỉ giúp phát hiện text so với background mà còn giúp tách các vùng text bị ghép liền vào với nhau.
Lý do DB cải thiện hiệu suất có thể được giải thích bằng quá trình backpropagation. Ta định nghĩa là một DB function trong đó . Khi đó loss cho nhãn positive và cho nhãn negative được biểu diễn như sau:
Đạo hàm của 2 hàm loss trên được tính sử dụng chain rule và cho kết quả sau đây:
Đồ thị hàm số loss và đạo hàm được mô tả trong hình dưới
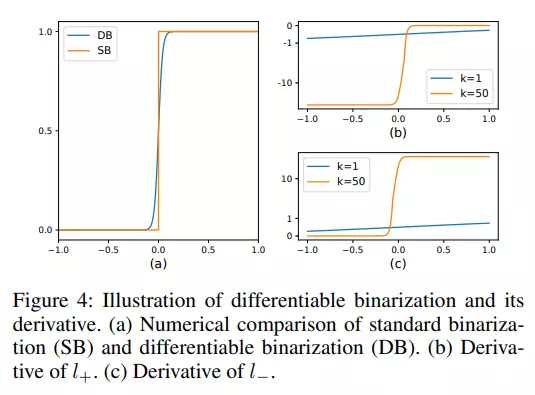
Nhờ có tham số mà ta có thể tối ưu dự đoán, phân biệt được rõ ràng hơn vùng chứa text và background.
Adaptive threshold

Deformable convolution
Deformable convolution được sử dụng do có thể cung cấp receptive field linh hoạt cho model, điều này đặc biệt hữu ích cho các ảnh text có aspect ratio lớn.
Cho những bạn nào chưa biết thì Deformable convolution (tạm dịch là tích chập có khả năng biến đổi) là một phương pháp cải tiến của phép convolution truyền thống trong mạng nơ-ron tích chập (Convolutional Neural Networks - CNNs). Nó được giới thiệu để mở rộng khả năng biểu diễn không gian của phép tích chập thông qua việc điều chỉnh vị trí của các điểm lấy mẫu trong quá trình tích chập.
Trong phép convolution truyền thống, các điểm lấy mẫu được chọn cố định và không thay đổi trong quá trình tính toán. Tuy nhiên, trong deformable convolution, các điểm lấy mẫu được điều chỉnh dựa trên một số thông tin cụ thể từ dữ liệu đầu vào. Điều này cho phép mô hình "thay đổi hình dạng" của phép tích chập để tìm hiểu các biến thể không gian phức tạp hơn, chẳng hạn như đối tượng có dạng cong, biến dạng trong ảnh.
Optimzation
Hàm loss cho model là tổng có trọng số của 3 hàm loss cho probability map , binary map và threshold map :
Giá trị được đặt là 1.0 và là 10.
Nhóm tác giả sử dụng Binary cross-entropy (BCE) loss cho và . Để giải quyết vấn đề mất cân bằng giữa điểm ảnh postive và negative (do số lượng các điểm ảnh không phải chữ thường chiếm rất nhiều trong một ảnh), nhóm tác giả sử dụng hard negative mining trong BCE loss bằng cách lấy các mẫu hard negative (tức là lấy các mẫu mà có phần negative mà model khó nhận diện  thay vì lấy tất cả các mẫu negative).
thay vì lấy tất cả các mẫu negative).
Trong đó là tập lấy mẫu có tỉ lệ positive và negative là 1 : 3.
được tính là tổng khoảng cách giữa dự đoán và label
Trong đó là tập hợp các điểm bên trong vùng text, là label cho threshold map.
Thực nghiệm
Một số kết quả của mô hình trong nhiều trường hợp văn bản có hướng, kích thước, hình dạng khác nhau. Phía phải trên là threshold map và dưới là probability map.

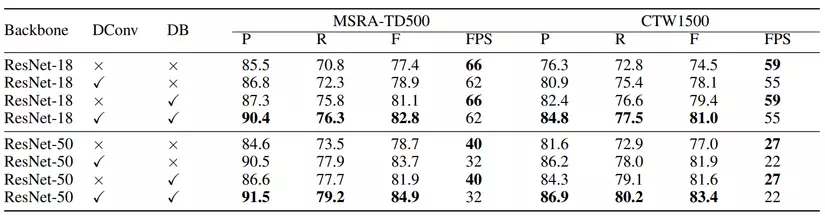
Kết quả dự đoán với các setting khác nhau trên 2 bộ dataset MSRA-TD500 và CTW1500. DConv biểu thị sử dụng deformable convolution. P, R, F lần lượt là precision, recall và f-measure.
Kết luận
Bài báo cung cấp cho chúng ta thêm một hướng mới để xử lý các bài toán phát hiện ảnh văn bản trong nhiều môi trường khác nhau. Tuy mang nhiều ưu điểm như nhanh (có thể sử dụng các mạng backbone nhẹ) mà vẫn đảm bảo độ chính xác nhưng model trong bài báo cũng mang một số nhược điểm là không thể xử lý trường hợp "text trong text" Tùy vào data thực tế cần infer mà ta có thể chọn các phương pháp phù hợp.
Nếu có bất kì câu hỏi nào liên quan đến bài viết, các bạn hãy để lại comment ở bên dưới nhé. Chúng mình sẽ giải đáp nhanh nhất có thể
Tham khảo
[1] Real-time Scene Text Detection with Differentiable Binarization
All rights reserved
