Paper reading | Neural News Recommendation with Long and Short-term User Representations
Bài đăng này đã không được cập nhật trong 2 năm
1. Động lực
Việc cá nhân hóa trong gợi ý tin bài là rất quan trọng với các nền tảng đọc báo online hiện tại, điều này làm tăng trải nghiệm người dùng lên đáng kể. Một vấn đề cốt lõi của gợi ý tin bài là học chính xác biểu diễn của user để nắm bắt được mối quan tâm của họ. Thường người dùng có sở thích ngắn hạn và dài hạn nhưng các hệ thống gợi ý hiện tại chỉ tập trung vào học biểu diễn đơn lẻ của user, điều này là chưa đủ.
2. Đóng góp
Nhóm tác giả đề xuất hệ thống gợi ý tin bài có thể học cả biểu diễn ngắn và dài hạn của user (long and short-term user representation). Cách tiếp cận của nhóm tác giả là sử dụng một news encoder và user encoder.
-
Trong news encoder, nhóm tác giả học biểu diễn của tin bài từ title, topic và sử dụng mạng attention để chọn ra các từ quan trọng.
-
Nhóm tác giả để xuất học biểu diễn dài hạn của user từ embedding ID của họ. Ngoài ra, bài báo còn đế xuất học biểu diễn ngắn hạn từ lịch sử duyệt tin bài gần đây của user sử dụng GRU network.
-
Bên cạnh đó, nhóm tác giả đề xuất hai phương pháp để kết hợp biểu diễn dài hạn và ngắn hạn của user. Phương pháp đầu tiên là sử dụng biểu diễn dài hạn của user để khởi tạo hidden state của mạng GRU trong biểu diễn ngắn hạn của user. Cách hai là concat cả biểu diễn dài và ngắn hạn của user thành một vector biểu diễn user thống nhất.
3. Phương pháp
Trước hết, ta cần làm rõ tại sao lại là biểu diễn ngắn hạn và dài hạn của user. Thường user có mối quan tâm hoặc sở thích dài hạn về chủ đề nào đó. Ví dụ, một user là fan của Manchester United thì thường sẽ có xu hướng đọc các tin bài về MU trong dài hạn. Ta gọi đó là mối quan tâm dài hạn. Mặt khác, mối quan tâm của user cũng được phát triển theo thời gian và có thể phát sinh một số nhu cầu tạm thời trong một ngữ cảnh cụ thể. Ví dụ, người dùng có thể tìm đọc các bài viết về huấn luyện viên Ten Hag sau khi đọc vài bài về MU mặc dù họ có thể chưa từng đọc về Ten Hag trước đó. Đó là mối quan tâm ngắn hạn. Việc nắm được mối quan tâm dài hạn và ngắn hạn của user là yếu tố quan trọng để hệ thống gợi ý có tính cá nhân hóa.
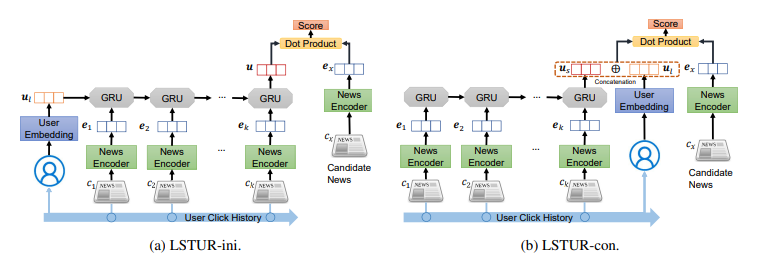
3.1. News Encoder
Module news encoder được dùng để học biểu diễn của tin bài từ các thông tin về title, body và topic của tin bài đó. Kiến trúc của news encoder được mô tả trong hình dưới. Có hai module con trong news encoder đó là một title encoder và một topic encoder.

Đầu tiên là title encoder, dùng để học biểu diễn tin bài từ title. Có 3 layer được sử dụng. Layer đầu tiên là word embedding dùng để chuyển tiêu đề của tin bài từ một chuỗi các từ sang chuỗi dense semantic vector.
Layer thứ 2 là mạng CNN. Local context (ngữ cảnh cục bộ) của các từ là quan trọng trong việc biểu diễn tiêu đề tin bài. Nhóm tác giả sử dụng CNN để học biểu diễn ngữ cảnh của từ bằng cách capture local context của các từ đó. Cách tính context representation của các từ như sau:
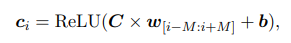
Trong đó:
-
là concat word embedding từ vị trí đến .
-
và là kernal và tham số bias của bộ lọc CNN.
-
là số bộ lọc CNN và là window size.
Layer thứ 3 là một word-level attention network. Mục tiêu của layer này là chọn ra các từ quan trọng trong title. Trọng số attention của từ thứ trong một new title được tính như sau:

Trong đó và là các trainable parameter. Biểu diễn cuối cùng của tiêu đề tin bài là tổng có trọng số của biểu diễn context word.

Tiếp theo là topic encoder được sử dụng để học biểu diễn tin bài từ các topic và subtopic. Trong các nền tảng đọc báo trực tuyến, topic ở đây ví dụ như "thể thao", theo sau đó các subtopic "bóng đá", "bóng rổ",... việc này giúp user tiếp cận tin bài cần đọc dễ dàng hơn. Topic và subtopic đều rất hữu ích để học biểu diễn của tin bài và user. Để kết hợp thông tin topic và subtopic vào biểu diễn tin bài, nhóm tác giả đề xuất học biểu diễn topic và subtopic từ embedding các ID của chúng  Ta kí hiệu và là biểu diễn của topic và subtopic. Khi đó biểu diễn cuối cùng của bài viết sẽ là concat các biểu diễn của title, topic và subtopic
Ta kí hiệu và là biểu diễn của topic và subtopic. Khi đó biểu diễn cuối cùng của bài viết sẽ là concat các biểu diễn của title, topic và subtopic
3.2. User Encoder
User encoder được sử dụng để học biểu diễn của user từ lịch sử duyệt tin bài của họ. User encoder gồm 2 module, short-term user representation model (STUR) để capture mối quan tâm trong thời gian ngắn hiện tại và long-term user representation model (LTUR) để capture mối quan tâm dài hạn của user.
3.2.1. Short-Term User Representation
Nhóm tác giả để xuất sử dụng Gated recurrent networks (GRU) để capture được các pattern của chuỗi tin bài mà người dùng đã đọc. Ta kí hiệu chuỗi các tin bài đã duyệt của user được sắp xếp theo thứ tự thời gian từ gần nhất là trong đó là độ dài của chuỗi. Nhóm tác giả sử dụng news encoder để xác định biểu diễn của các bài viết đã duyệt, kí hiệu là . Short-term user representation được tính như sau:
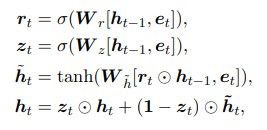
Trong đó
-
là hàm sigmoid
-
là phép nhân element-wise
-
và là các tham số của GRU network.
Short-term user representation là hidden state cuối của the GRU network. Ta kí hiệu .
3.2.2. Long-Term User Representations
Long-term user representation được học từ embedding của user ID được khởi tạo ngẫu nhiên và finetuned trong suốt quá trình training model. Kí hiệu là ID của một user và là look-up table cho long-term user representation. Long-term user representation của user này là .
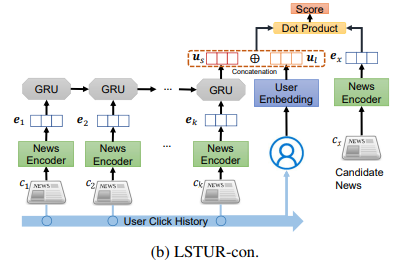
3.2.3. Long- and Short-Term User Representation
Nhóm tác giả đề xuất 2 phương pháp để kết hợp long và short-term user representation.
Phương pháp đầu tiên là sử dụng long-term user representation để khởi tạo hidden state của mạng GRU trong short-term user representation model. Ta kí hiệu phương pháp này là LSTUR-ini. Hidden state cuối của mạng GRU là biểu diễn user cuối cùng.

Phương pháp thứ hai là concat long-term user representation và short-term user representation để cho ra biểu diễn user cuối cùng. Ta kí hiệu phương pháp này là LSTUR-con.
3.3. Model Training
Nhóm tác giả sử dụng tích vô hướng để tính xác suất click vào tin bài của user. Kí hiệu biểu diễn của user là và biểu diễn của một tin bài ứng cử viên là , xác suất user click vào tin bài được tính như sau: .
Ý tưởng model training cũng giống như trong bài báo Neural News Recommendation with Multi-Head Self-Attention và Neural News Recommendation with Attentive Multi-View Learning. Nhóm tác giải sử dụng kĩ thuật negative sampling để huấn liên model. Ý tưởng như sau:
-
Với mỗi tin bài được xem bởi user (positive sample), ta lấy ngẫu nhiên mẫu tin bài cũng được hiển thị cùng lúc nhưng user không click vào (negative sample).
-
Model sẽ dự đoán xác suất click vào positive sample và negative news.
-
Mục tiêu là tối thiểu tổng negative log-likelihood của tất cả positive sample trong quá trình training, công thức như sau
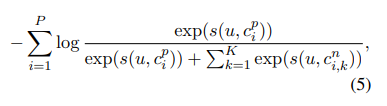
Trong đó, là số positve sample, là negative sample thứ trong cùng một session với positive sample thứ .
Do không phải tất cả user đều có thể kết hợp với tin bài trong quá trình training (có thể có user chưa xem tin bài nào hoặc người dùng mới sau này), vì vậy sẽ là không hợp lý khi ta giả sử rằng tất cả user đều có long-term representation khi đưa ra dự đoán. Để giải quyết vấn đề này, trong giai đoạn training model, nhóm tác giả mask ngẫu nhiên long-term representation của các user với một xác suất . Khi mask long-term representation như vậy thì tất cả dimension được đặt thành 0. Do vậy, long-term user representation trong cách tiếp cận LSTUR được công thức hóa lại như sau:
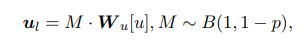
trong đó là phân phối Bernoullo và là biến ngẫu nhiên tuân theo . Nhóm tác giả nhận thấy rằng điều này làm cải thiện hiệu suất của phương pháp LSTUR.
4. Thực nghiệm
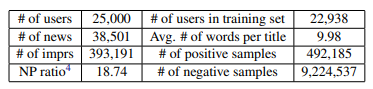
Thông tin của bộ dữ liệu được dùng để thực nghiệm như sau:
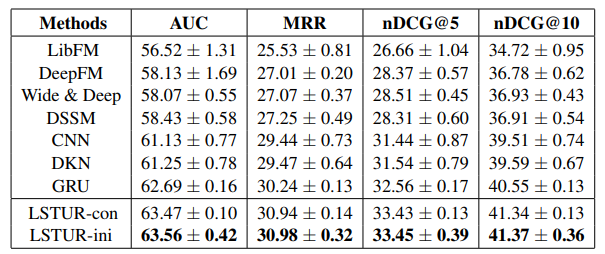
Nhóm tác giả so sánh 2 phương pháp đề xuất với các phương pháp khác. Kết quả cho thấy LSTUR-ini đạt hiệu suất cao nhất.
Hiệu quả kết hợp long-tern user representations (LTUR) và short-term user representations (STUR).
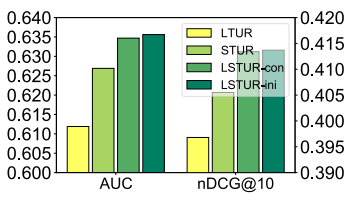
Nhóm tác giả cũng thực hiện so sánh các method khác nhau trong việc học short-term user representations từ các tin bài được xem gần đây.
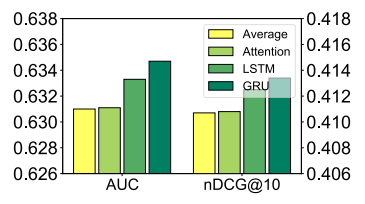
Hình dưới mô tả so sánh các phương pháp khác nhau trong việc học cách biểu diễn title của tin bài và hiệu quả của cơ chế attention trong việc lựa chọn các từ quan trọng.

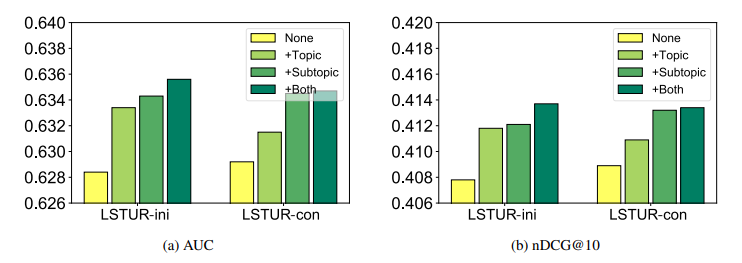
Hiệu quả của việc kết hợp thông tin topic và subtopic cho model recommendation.
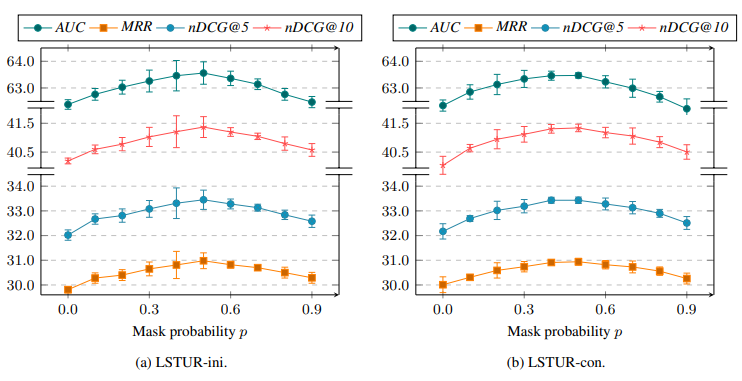
Nhóm tác giả nghiên cứu việc lưu chọn xác suất trong công thức
sao cho tối ưu và kết quả như hình dưới. Kết quả của LSTUR-ini và LSTUR-con có pattern khá tương tự nhau. cho hiệu suất tốt nhất khi đạt giá trị xung quanh 0.5. Giá trị này cân bằng việc học LTUR và STUR.
5. Kết luận
Điểm đáng chú ý của bài báo là khai thác ý tưởng long-term và short-term trong việc đọc tin bài của user. Tuy nhiên, phương pháp này có nhiều phần có thể cải tiến hơn tại các module encoder. Ta hoàn toàn có thể thực nghiệm thêm bằng các model xử lý dạng chuỗi tốt như LSTM, Transformer hoặc sử dụng cách encoder khác sử dụng graph.
6. Tham khảo
[1] Neural News Recommendation with Long and Short-term User Representations
[2] recommenders/lstur_MIND.ipynb at main · microsoft/recommenders (github.com)
All rights reserved
