Paper reading | Imagen, mô hình sinh ảnh từ văn bản mạnh mẽ
Bài đăng này đã không được cập nhật trong 2 năm
1. Động lực
Các mô hình text-to-image model được nhận nhiều sự quan tâm nhờ khả năng sáng tạo ra những hình ảnh rất thú vị từ đoạn văn bản mô tả cho trước. Những mô hình là công cụ hỗ trợ con người rất nhiều trong việc xây dựng những content hình ảnh và nhiều ứng dụng khác.

2. Đóng góp
Trong bài báo, nhóm tác giả tại Google Research trình bày mô hình Imagen, mô hình sinh hình ảnh từ văn bản với mức độ chân thực đáng kinh ngạc, cộng với khả năng hiểu ngôn ngữ sâu sắc. Mô hình này được xây dựng dựa trên sức mạnh từ các mô hình ngôn ngữ Transformer lớn với mục tiêu hiểu văn bản và khả năng sinh ảnh từ các mô hình diffusion. Khám phá quan trọng của nhóm tác giả là các mô hình ngôn ngữ lớn (ví dụ như T5) pretrained trên kho dữ liệu chỉ có văn bản đạt hiệu suất rất tốt trong việc mã hóa văn bản để tổng hợp hình ảnh. Việc tăng kích thước của mô hình ngôn ngữ trong Imagen giúp tăng cả độ trung thực của mẫu và căn chỉnh hình ảnh - văn bản nhiều hơn so với tăng kích thước của mô hình diffusion hình ảnh.
Nhóm tác giả giới thiệu dynamic thresholding, một kĩ thuật diffusion sampling mới có khả năng tận dụng các weight guidance  và sinh các hình ảnh chi tiết và chân thực hơn so với trước đây. Bên cạnh đó, nhóm tác giả đưa ra một số lựa chọn thiết kế kiến trúc diffusion quan trọng và đề xuất Efficient U-Net là một kiến trúc mới đơn giản hơn, hội tụ nhanh hơn và tối ưu bộ nhớ.
và sinh các hình ảnh chi tiết và chân thực hơn so với trước đây. Bên cạnh đó, nhóm tác giả đưa ra một số lựa chọn thiết kế kiến trúc diffusion quan trọng và đề xuất Efficient U-Net là một kiến trúc mới đơn giản hơn, hội tụ nhanh hơn và tối ưu bộ nhớ.
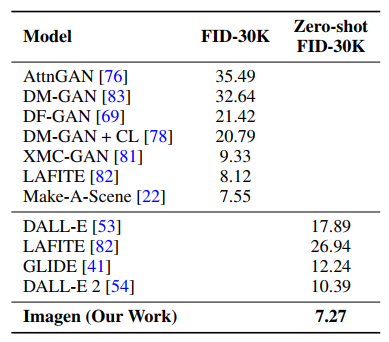
Imagen đạt SOTA với FID score là 7.27 trên tập dữ liệu COCO mặc dù chưa từng được train trên tập COCO. Ngoài ra, những người tham gia đánh giá cho rằng các mẫu được sinh từ Imagen có độ chân thực ngang hàng với tập COCO trong việc căn chỉnh hình ảnh - văn bản.
Mặt khác, để đánh giá các mô hình text-to-image sâu hơn, nhóm tác giả giới thiệu DrawBench, một benchmark cho các mô hình text-to-image. Với DrawBench, nhóm tác giả so sánh Imagen với một số method gần đây như VQ-GAN+CLIP, các Latent Diffusion Model, GLIDE và DALL-E 2. Nhóm tác giả nhận thấy rằng những người tham gia đánh giá đánh giá cao Imagen hơn so với các model trên ở nhiều khía cạnh, đặc biệt là chất lượng mẫu và căn chỉnh hình ảnh - văn bản.
3. Phương pháp
Imagen gồm 2 thành phần chính:
- Text encoder: Có nhiệm vụ mapping text thành một chuỗi các embedding
- Các mô hình conditional diffusion mapping các embedding trên thành hình ảnh có độ phân giải tăng dần
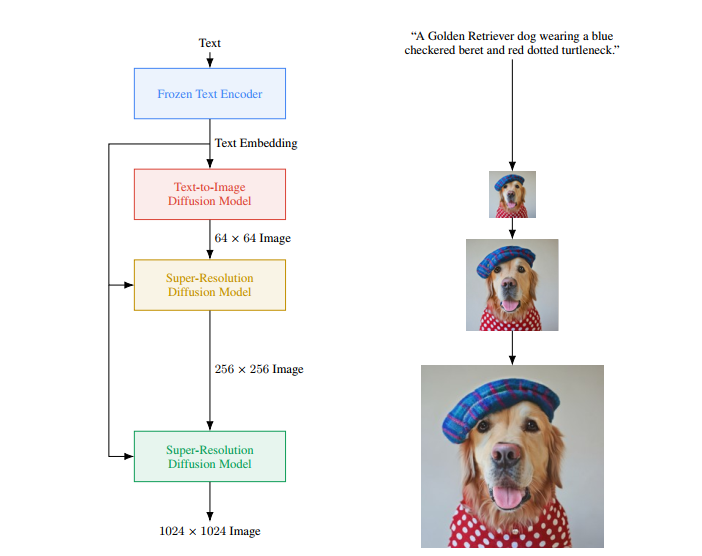
3.1. Pretrained text encoder
Các mô hình text-to-image đều cần bộ text encoder mạnh mẽ để có thể capture được thành phần và độ phức tạp của văn bản ngôn ngữ tự nhiên bất kì. Có 2 lựa chọn cho text encoder ta có thể quan tâm như sau:
- Train text encoder trên dữ liệu image-text theo 2 hướng: Train từ đầu hoặc tận dụng pretrained (ví dụ như CLIP).
- Sử dụng các mô hình ngôn ngữ lớn (ví dụ như BERT, GPT, T5). Các mô hình ngôn ngữ lớn này chỉ được train trên tập dữ liệu văn bản và tất nhiên rằng những tập dữ liệu văn bản này hiện tại lớn hơn rất nhiều dữ liệu cặp image-text. Do đó, những mô hình này có thể capture thông tin văn bản phong phú hơn Những mô hình trên nói chung lớn hơn rất nhiều so với text encoder trong các mô hình image-text (Ví dụ PaLM có 540 tỷ tham số trong khi CoCa có xấp xỉ 1 tỷ tham số trong text encoder)
Nhóm tác giả tận dụng những pretrained mô hình ngôn ngữ lớn (BERT, GPT, T5) làm text encoder cho Imagen, họ thực hiện freeze trọng số của các text encoder này và do đó dẫn đến việc tính toán cũng như sử dụng bộ nhớ không đáng kể trong quá trình train mô hình text-to-image. Nhóm tác giả nhận thấy rằng việc tăng kích thước text encoder làm tăng chất lượng sinh ảnh.
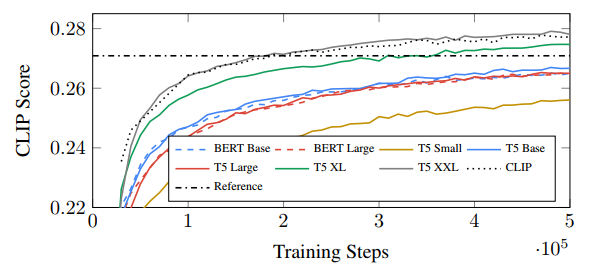
3.2. Các Diffusion model và classifier-free guidance
Trong bài báo nhóm tác giả giới thiệu tóm tắt về diffusion model. Hiểu đơn giản, các mô hình diffusion là một lớp các mô hình sinh chuyển đổi Gaussian noise thành các mẫu từ việc học phân phối dữ liệu thông qua một quá trình denoise lặp đi lặp lại. Các mô hình này có thể có thêm một số điều kiện như bao gồm thêm nhãn, văn bản hoặc trên những ảnh có độ phân giải thấp. Một mô hình được train trên một denoising objective có công thức như sau:
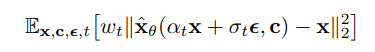
Trong đó:
- là cặp data-conditioning
- là các function của ảnh hưởng tới chất lượng mẫu
Hiểu một cách đơn giản, được train để denoise thành sử dụng squard error loss. Hàm loss này được đánh trọng số để nhấn mạnh các giá trị của .
Việc sampling có thể sử dụng 1 trong 2 kĩ thuật ancestral sampler từ bài báo 2006.11239.pdf (arxiv.org) hoặc DDIM từ bài báo 2010.02502.pdf (arxiv.org).
Classifier guidance là kĩ thuật nhằm cải thiện chất lượng mẫu đồng thời giảm độ đa dạng trong các conditional diffussion model sử dụng các gradient từ một pretrained model trong suốt quá trình sampling. Để hiểu thêm về Classifier guidance, bạn có thể tìm đọc bài báo https://arxiv.org/abs/2105.05233. Classifier free guidance là một kỹ thuật thay thế để tránh các model pretrained này bằng cách cùng train một mô hình diffusion duy nhất cho các mục tiêu có điều kiện và vô điều kiện thông qua việc giảm ngẫu nhiên trong quá trình đào tạo (ví dụ: với xác suất 10%). Việc lấy mẫu được thực hiện bằng cách sử dụng adjusted -prediction trong đó
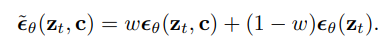
Với và là conditional và unconditional -prediction cho bởi và là guidance weight. Khi đặt sẽ làm mất classifier-free guidance, trong khi tăng sẽ làm tăng mức độ ảnh hưởng của guidance. Imagen phụ thuộc rất nhiều vào classifier-free guidance để điều chỉnh văn bản hiệu quả.
3.3. Large guidance weight samplers
Nhóm tác giả đánh giá các kết quả text-guided diffusion gần đây và nhận thấy rằng tăng classifier-guidance weight cải thiện khả năng image-text alignment nhưng sẽ làm hỏng tính trung thực của ảnh do làm tăng mức độ bão hòa và ảnh không được tự nhiên. Điều này là do tại mỗi training step , prediction phải nằm trong các khoảng giống như training data , ví dụ như trong [-1, 1]. Nhóm tác giả thực nghiệm và nhận thấy rằng các guidance weight càng cao là nguyên nhân làm cho prediction vượt quá đoạn giá trị này. Để giải quyết vấn đề này, nhóm tác giả đề xuất 2 kĩ thuật static thresholding và dynamic thresholding.
Static thresholding: Nhóm tác giả sử dụng elementwise clipping cho prediction về đoạn giá trị [-1, 1]. Kĩ thuật này cần thiết cho quá trình sampling và ngăn việc sinh ra các ảnh trống. Tuy nhiên, static thresholding vẫn trả về kết quả ảnh bão hòa và kém chi tiết nếu như guidance weight tăng thêm. Cài đặt của static thresholding như sau:
def sample():
for t in reversed(range(T)):
# Forward pass to get x0_t from z_t.
x0_t = nn(z_t, t)
# Static thresholding.
x0_t = jnp.clip(x0_t, -1.0, 1.0)
# Sampler step.
z_tm1 = sampler_step(x0_t, z_t, t)
z_t = z_tm1
return x0_t
Dynamic thresholding: Đây là một kĩ thuật mới được nhóm tác giả giới thiệu. Tại mỗi training step , ta đặt là một phân vị nhất định của giá trị tuyệt đối các pixel. Nếu thì ta đặt ngưỡng trong đoạn và chia cho . Dynamic thresholding đẩy các pixel bão hòa (những pixel gần -1 và 1) vào trong, do đó chủ động ngăn các pixel không bị bão hòa ở mỗi bước. Về cách tính phân vị bạn có thể tham khảo tại Phân biệt Trung bình Trung vị Phân vị - Phân tích xử lý dữ liệu (thongke.club) Cài đặt của dynamic thresholding như sau:
def sample(p: float):
for t in reversed(range(T)):
# Forward pass to get x0_t from z_t.
x0_t = nn(z_t, t)
# Dynamic thresholding (ours).
s = jnp.percentile(
jnp.abs(x0_t), p,
axis=tuple(range(1, x0_t.ndim)))
s = jnp.max(s, 1.0)
x0_t = jnp.clip(x0_t, -s, s) / s
# Sampler step.
z_tm1 = sampler_step(x0_t, z_t, t)
z_t = z_tm1
return x0_t
Hình dưới là so sánh chất lượng ảnh khi sử dụng 2 kĩ thuật threshold khác nhau. Dễ dàng nhận thấy là mẫu sử dụng static thresholding có độ bão hòa lớn hơn so với mẫu sử dụng dynamic thresholding, do đó hình ảnh trông có vẻ không được tự nhiên

3.4. Các mô hình diffusion
Mô hình Imagen sử dụng hai text-conditional super-resolution diffusion models và một base model để sinh ra hình ảnh có độ trung thực cao. Noise conditioning augmentation được sử dụng cho cả hai super-resolution models. Gaussian noise được sử dụng như một dạng augment, với augmentation level được chỉ định trong khoảng từ 0 đến 1.
3.5. Kiến trúc Neural network
Base model: Nhóm tác giả sử dụng kiến trúc U-net cho text-to-image diffusion model. Mạng này được đặt condition dựa vào text embedding thông qua pooled embedding vector. Pooled embedding vector được thêm vào diffusion timestep embedding tương tự như class embedding conditioning.
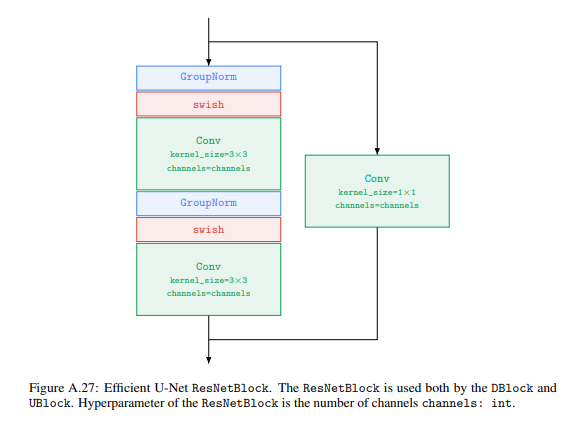

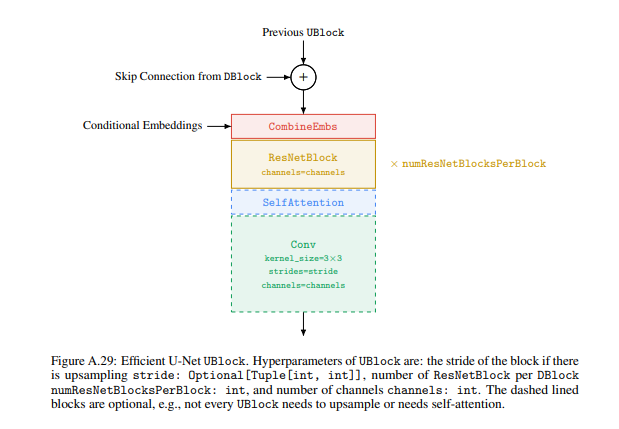
Nhóm tác giả cũng nhận thấy rằng sử dụng Layer Normalization cho text embedding trong attention và pooling layer giúp cải thiện hiệu suất đáng kể.
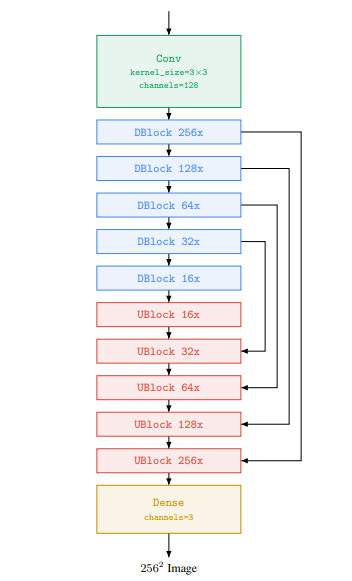
Super-resolution model: Với -> super-resolution, nhóm tác giả sử dụng mạng U-net cải tiến về bộ nhớ, thời gian inference và tốc độ hội tụ. Với -> super-resolution, model được train trên ảnh -> được crop từ ảnh . Để thuận lợi cho việc training này, nhóm tác giả thực hiện xóa các layer self-attention, tuy nhiên vẫn giữ các layer text cross-attention. Trong quá trình inference, model nhận toàn bộ ảnh làm input và upsample trả về ảnh .
3.6. Đánh giá mô hình Text-to-Image
Tập dữ liệu COCO validation là benchmark chuẩn để đánh giá text-to-image model. Metric sử dụng để đánh giá là FID dùng để đo mức độ trung thực của ảnh và CLIP score để đánh giá sự căn chỉnh image-text. Tuy nhiên, 2 metric này đều có những hạn chế, với FID là chất lượng không hoàn toàn phù hợp với nhận thức của con người và CLIP thì không hiệu quả trong việc đếm object trong ảnh. Do đó, nhóm tác giả thực hiện sử dụng con người để đánh chất lượng ảnh và mức độ tương đồng với caption.
Tuy nhiên, để so sánh 2 model trong task này cần có một benchmark mạnh mẽ hơn. Nhóm tác giả giới thiệu DrawBench chứa 11 danh mục promt, kiểm tra các khả năng khác nhau của mô hình như khả năng hiển thị trung thực các màu khác nhau, số lượng đối tượng, quan hệ không gian, văn bản trong cảnh và các tương tác bất thường giữa các đối tượng. Các danh mục cũng bao gồm các promt phức tạp như các văn bản dài, phức tạp, các từ hiếm và cả các promt sai chính tả.
4. Thực nghiệm
Trên MS-COCO FID-30K. Nhóm tác giả sử dụng guidance weight là 1.35 cho model và guidance weight 8.0 cho super-resolution model. Kết quả như sau:
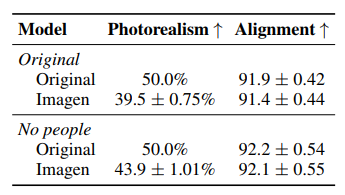
Bảng dưới là đánh giá sử dụng con người trên tập COCO , họ thực hiện so sánh giữa output của model và ảnh gốc.
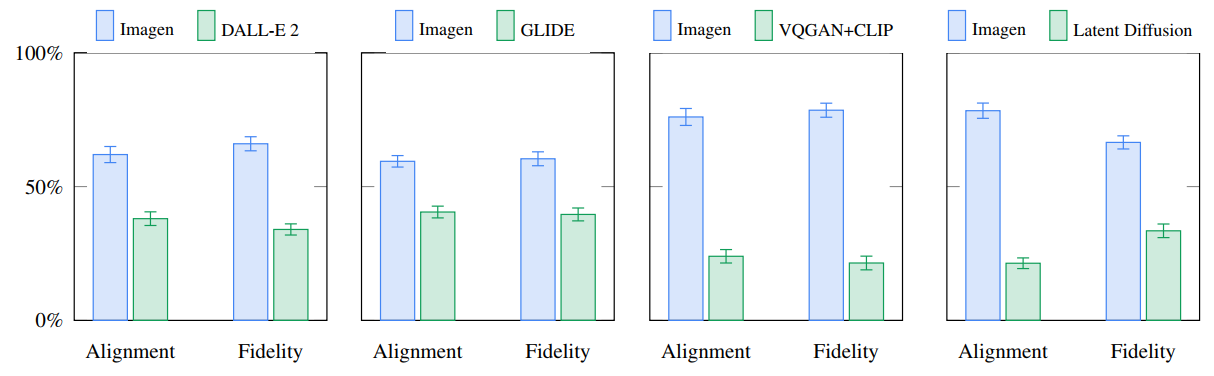
Biểu đồ dưới so sánh Imagen và các mô hình text-to-image khác trên DrawBench.
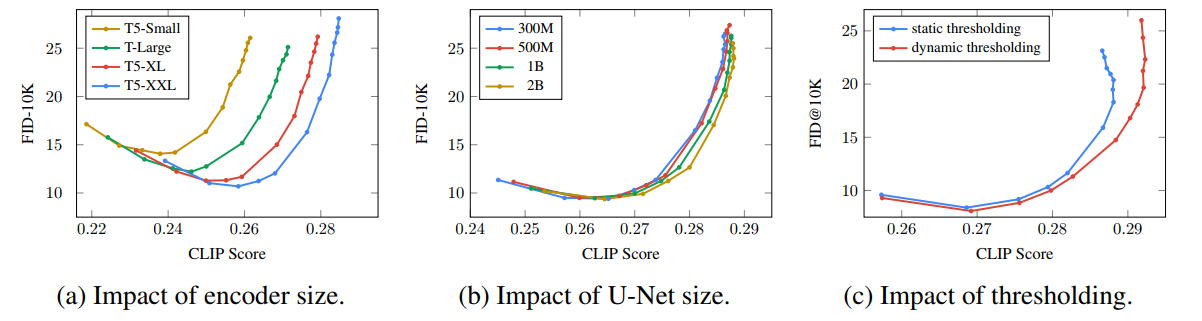
Nhóm tác giả cũng đánh giá tác động của encoder size, U-Net size và thresholding. Kết quả như sau.
5. Kết luận
Imagen cho thấy sự hiệu quả của các pretrained language models được frozen dưới dạng bộ encoder văn bản cho tác vụ text-to-image và kết hợp sử dụng các mô hình diffusion. Qua bài báo ta thấy rằng việc scale kích thước của các mô hình ngôn ngữ này có tác động lớn đáng kể so với việc scale kích thước U-Net đối với việc nâng cao hiệu suất tổng thể của mô hình text-to-image. Điều này sẽ khuyến khích các hướng nghiên cứu trong tương lai về việc khám phá các mô hình ngôn ngữ thậm chí còn lớn hơn dưới dạng bộ encoder văn bản. Hơn nữa, thông qua Imagen, nhóm tác giả nhấn mạnh lại tầm quan trọng của classifier-free guidance và giới thiệu dynamic thresholding, cho phép sử dụng các guidance weight cao hơn nhiều so với các nghiên cứu trước đây. Với các thành phần mới này, Imagen tạo ra các mẫu với hình ảnh chân thực và căn chỉnh với văn bản chất lượng cao.
6. Tham khảo
[1] lucidrains/imagen-pytorch: Implementation of Imagen, Google's Text-to-Image Neural Network, in Pytorch (github.com)
[2] Imagen: Text-to-Image Diffusion Models (research.google)
[3] Denoising Diffusion Probabilistic Models (hojonathanho.github.io)
[4] [2007.13640] Solving Linear Inverse Problems Using the Prior Implicit in a Denoiser (arxiv.org)
[5] [2105.05233] Diffusion Models Beat GANs on Image Synthesis (arxiv.org)
[6] [2207.12598] Classifier-Free Diffusion Guidance (arxiv.org)
[7] [2010.02502] Denoising Diffusion Implicit Models (arxiv.org)
All rights reserved
