Paper Reading | DIT: SELF-SUPERVISED PRE-TRAINING FOR DOCUMENT IMAGE TRANSFORMER
Bài đăng này đã không được cập nhật trong 3 năm
Giới thiệu chung
Các bài toán trích xuất thông tin từ hình ảnh luôn được nhận sự quan tâm vì tính ứng dụng rộng rãi. Đặc biệt trong các bài toán liên quan đến trích xuất thông tin từ ảnh tài liệu. Trong vài năm trở lại đây, Transformer trở thành một game changer, không chỉ đạt những kết quả ấn tượng trong các tác vụ về Natural language processing mà những tác vụ Computer Vision cũng đạt những thành tựu nhất định, cạnh tranh với mô hình CNN truyền thống. Một số kĩ thuật Image Transformer pre-training có thể kể đến như ViT, DeiT (mô hình supervised) hay BEiT, MAE (mô hình self-supervised). Trong paper này, nhóm tác giả đề xuất mô hình Self-supervised pretrain Documents Image Transformer sử dụng tập hình ảnh văn bản quy mô lớn không được gắn nhãn cho các tác vụ Document AI. Mô hình này là cần thiết do sự hạn chế về các tập dữ liệu Image Document được gán nhãn. Nhóm tác giả tận dụng DiT làm backbone trong nhiều tác vụ Document AI, bao gồm phân loại hình ảnh tài liệu (document image classification), phân tích bố cục tài liệu (document layout analysis,), cũng như phát hiện bảng (table detection). Kết quả thực nghiệm đã cho thấy rằng mô hình self-supervised pre-trained DiT đạt được kết quả SOTA với các downstream task, ví dụ: phân loại hình ảnh tài liệu (91.11 → 92.69), phân tích bố cục tài liệu (91.0 → 94.9) và phát hiện bảng (94.23 → 96.55).
Motivation
Kĩ thuật self-supervised pretrain được sử dụng phổ biến trong các tác vụ Document AI trong những năm trở lại đây. Một số cách tiếp cận điển hình bắt đầu bằng vision-based understanding như là OCR hay phân tích tài liệu (document analysis) gặp phải trở ngại lớn là sự phụ thuộc đối với các mô hình backbone supervised, những mô hình này đòi hỏi cần sự gán nhãn dữ liệu thủ công từ con người. Mặc dù cho kết quả tốt trên các tập dữ liệu benchmark nhưng những mô hình này thường gặp vấn đề về hiệu suất khi ứng dụng trong thế giới thực, nguyên nhân là do domain shift và các document ở thế giới thực có form, mẫu khác với tập dữ liệu đào tạo. Mặt khác, bằng thực nghiệm cho thấy rằng Transformer đạt kết quả tốt cho các nhiệm vụ Vision nhưng lại cần nhiều dữ liệu training hơn CNN. Do vậy, động lực đầu tiên có thể kể đến đó là cần một mô hình backbone self-supervised pre-training tạo tiền đề cho các Document AI model trên các domain khác nhau. Và việc sử dụng self-supervised pretrain có thể tận dụng được nguồn dữ liệu ảnh lớn.
Bên cạnh đó, mô hình Transformer không chỉ rất thành công trong các tác vụ NLP mà còn đạt nhiều thành tựu trong cuộc chơi về hình ảnh, với các kết quả cạnh tranh so với những mô hình CNN cùng lượng tham số. Tuy nhiên, trong tác vụ document image understanding không có tập dữ liệu được gán nhãn benchmark phổ biến như ImageNet. Chính vì vậy, việc sử dụng supervised learning ở đây là không thực tế. Mặc dù có những phương pháp supervised "yếu" được sử dụng để tạo Document AI benchmark, nhưng domain của những tập data này thường có chung format/template, điều này khác rất nhiều ở thế giới thực do có rất nhiều hóa đơn, report, tờ khai,... khác nhau (ảnh dưới). Điều đó dẫn đến một kết quả "chưa thật sự thỏa mãn" cho các bài toán Document AI nói chung. Vì vậy, động lực thứ 2 đó là cần mô hình backbone pretrain trên nhiều dữ liệu không được gán nhãn của những domain khác nhau, việc này hỗ trợ đa dạng tác vụ Document AI.

Document image Transformer
Model Architecture
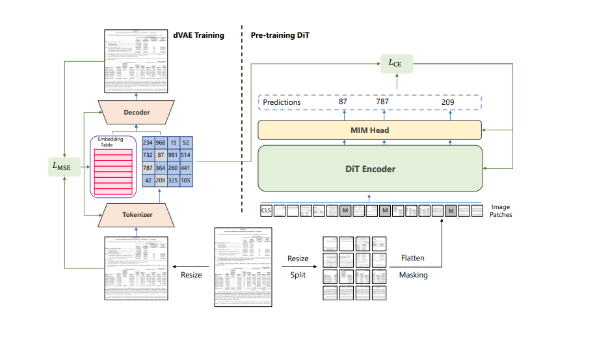
Giống như mô hình ViT. Nhóm tác giả sử dụng kiến trúc Transformer như là một backbone của DiT. Một ảnh tài liệu (document image) ban đầu được resize thành kích thước 224 * 224, sau đó chia thành 16*16 patch không trùng nhau và thu được một chuỗi các patch embedding. Sau khi được cộng với 1d position embedding, những image patch này được đưa vào stack các Transformer block với multi-head attention. Cuối cùng, ta thu được output của Transformer encoder là biểu diễn của các image patch.
Image representation
Image patch
Ảnh được chia thành chuỗi các patch, khi đó Transformer có thế trực tiếp nhận dữ liệu hình ành. Cụ thể ta reshape ành thành patch , trong đó là số lượng kênh, là resolution ành đầu vào, là resolution của mỗi patch. Các patch ảnh được flatten thành các vector và thực hiện phép chiếu tuyến tính (linear projection) tương tự như word embedding trong BERT.
Visual token
Giống như ngôn ngữ tự nhiên, ảnh được biểu diễn bởi một chuối các token được xác định bởi "image tokenizer". Cụ thể tác giả tokenize ảnh thành trong đó Vocabulary bao gồm các chỉ số token rời rạc.
Việc học image tokenizer được thực hiện thông qua dVAE. Có 2 module trong quá trình visual token learning, đó là tokenizer và decoder. Tokenizer map image pixel thành các token rời rạc heo visual codebook (ví dụ như Vocabulary). Decoder học reconstruct input image dựa vào visual token . Reconstruction objective được biểu diễn như sau: . Do visual tokens là các giá trị rời rạc nên model training là không khả vi. Vì vậy, Gumbel-softmax relaxation được sử dụng để đào tạo các tham số mô hình.
MIM
Ta thực hiện mask ngẫu nhiên một lượng image patch và thực hiện predict visual token tương ứng với patch bị mask. Từ một ảnh đầu vào ta chia làm 2 phần, N image patch và tokenize thành N visual token. Ta thực hiện mask ngẫu nhiên một lượng image patch. Sau đó, ta thay patch bị mask bằng một learnable embedding. Sau khi thay ta thu được corrupted image patch và corrupted image patch được đưa vào Transformer. Với mỗi vị trí bị mask, ta sử dụng softmax classifier để dự đoán visual token tương ứng. Pretrain objective là maximize log likelihood của visual token chính xác được cho bởi corrupted image.

Pre-training
Được lấy cảm hứng từ BEiT, nhóm tác giả sử dụng pretrain objective là Masked Image Modeling (MIM). Các hình được biểu diễn theo 2 view đó là image patch và visual token Để pretrain mô hình hiệu quả, nhóm tác giả "che" ngẫu nhiên một tập con input (là chuỗi image patch) bằng một token đặc biệt là [MASK]. Trong quá trình pretrain, DiT sử dụng image patch là đầu vào và dự đoán visual token. Nghĩa là, mô hình học để khám phá ra visual token từ ảnh gốc thay vì là khám phá raw pixel của các patch bị mask.
Cũng giống như text token trong ngôn ngữ tự nhiên, một ảnh có thể được biểu diễn thành một chuỗi discrete token được xác định bởi image tokenizer. BEiT sử dụng discrete variational auto-encoder (dVAE) với DALL-E làm image tokenizer. Tuy nhiên những ảnh được train là những ảnh tự nhiên khác với những ảnh tài liệu, do đó DALL-E tokenizer không tương thích với những ảnh tài liệu. Vì vậy, để có discrete visual token tốt hơn cho ảnh tài liệu, nhóm tác giả đã train dVAE trên tập dữ liệu IIT-CDIP với 42 triệu ảnh tài liệu.
Thực nghiệm
Tasks
Nhóm tác giả đánh giá hiệu suất của mô hình trên 3 Document AI Benchmark:
Thứ nhất là trên tập dữ liệu RVL - CDIP gồm 400.000 ảnh đen trắng với 16 class, mỗi class gồm 25.000 ảnh. Có 320.000 ảnh training, 40.000 ảnh trên tập validation và 40.000 ảnh test. Dataset này sử dụng để đánh giá trên nhiệm vụ phân loại tài liệu.
PubLayNet là tập dữ liệu cho nhiệm vụ phân tích bố cục tài liệu. Model cần nhận diện được các thành phần cơ bản trong tài liệu như: văn bản, danh sách, ảnh, bảng. Metric dùng để đánh giá là Mean Average Precision (mAP).
ICDAR 2019 cTDaR tập dữ liệu cTDaR bao gồm 2 track là table detection và table structure recognition. Trong paper, nhóm tác giả tập trung vào track table detection với ảnh document được gán nhãn cung cấp. Metric dùng để đánh giá mô hình là precision, recall và F1 score. Dựa vào các IoU threshold khác nhau (0.6, 0.7, 0.8, 0.9), nhóm tác giả kết hợp và đưa ra công thức tính weight F1 score:
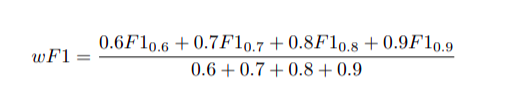
Results
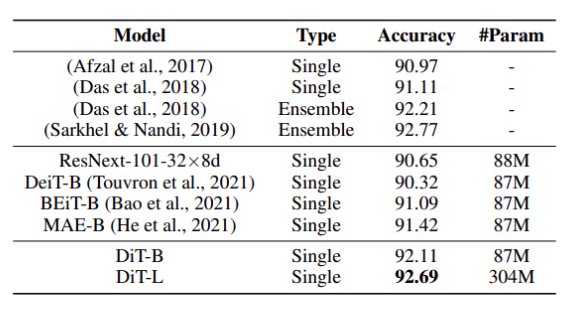
Với bộ dữ liệu RVL-CDIP, nhóm tác giả nhận thấy rằng DiT-B cho kết quả tốt hơn đáng kể so với các single-model baseline. Vì DiT có cấu trúc model gần giống với các model Transformer trên hình ảnh, việc có độ chính xác cao hơn cho thấy rằng sự hiệu quả của chiến lược pretrain trên ảnh tài liệu. Phiên bản lớn hơn là DiT-L có kết quả cạnh tranh so với các SOTA ensemble model.
PubLayNet Kết quả của task Document layout analysis được show trong bảng dưới. Vì task này được train trên tập dữ liệu lớn và yêu cầu phân tích tổng hợp trên các phần tử document phổ biến, điều này chứng minh rõ ràng rằng khả năng học các ảnh khác nhau của Transformer model.
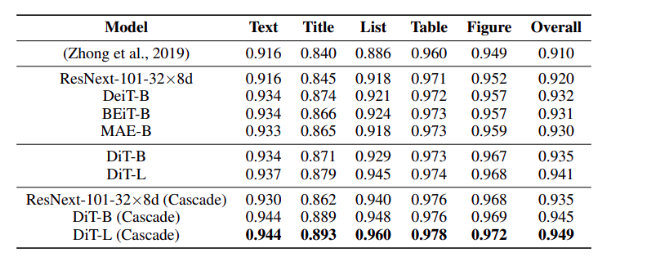
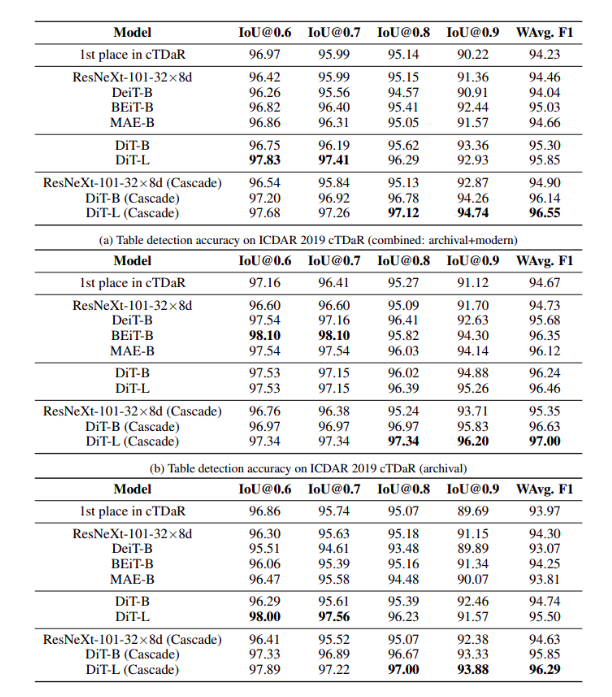
ICDAR 2019 cTDaR Kết quả của task table detection được show trong hình dưới. Kích thước của dataset này tương đối nhỏ, do đó mục đích của nhóm tác giả là đánh giá khả năng few shot learning của model trong tình huống ít tài nguyên để training. Đầu tiên, ta thực hiện phân tích performance trên 2 tập con archival và modern riêng biệt. Trong bảng b, DiT vượt qua tất cả baseline trừ BEiT. Lý do là vì trong pretrain của BEiT sử dụng trực tiếp sử dụng DALL-E dVAE. DALL-E dVAE được train trong với một dataset rất lớn gồm 400M ảnh với các màu khác nhau. Trong đó với DiT, image tokenizer được train trên ảnh trắng đen, điều này không đủ với những tài liệu lịch sử có màu sắc.
Kết luận
Về cơ bản, kiến trúc DiT trong bài báo khá giống với BEiT. Trong tương lai, DiT sẽ được train trên tập dữ liệu lớn hơn để tăng độ chính xác. Tốc độ dự đoán chậm.
Phụ lục
Self-supervised learning
Cho một task có bộ dữ liệu được gán nhãn, gọn gàng sạch đẹp -> ta dễ dàng sử dụng các thuật toán supervised learning và cho kết quả tốt. Tuy nhiên, trên thực tế việc có được bộ dữ liệu được gán nhãn chuẩn chỉ là một điều khó khăn và tốn kém. Ở thế giới thực, dữ liệu không được gán nhãn bạt ngàn và rất phung phí nếu không sử dụng chúng. Khó khăn ở đây là các thuật toán unsupervised learning thường khó cài đặt và hoạt động không hiệu quả bằng supervised learning. Làm thế nào để ta có thể có được nhãn của dữ liệu và train unsupervised dataset theo cách supervised? Ta có thể đạt được điều này bằng cách đóng khung supervised learning task theo một dạng đặc biệt đó là dự đoán tập con của một thông tin nào đó dựa vào phần còn lại. Đó là self-supervised learning.
Ý tưởng này được sử dụng rộng rãi trong các language model, giống như trong mô hình bag of word hay skip gram dựa vào từ đã có để dự đoán xác suất xuất hiện từ còn lại xung quanh từ đã biết. Hoặc như trong BERT, ta mask một số từ và dựa vào các từ còn lại để dự đoán ra từ bị mask. Điều này giống như ta “giả vờ" không biết để dự đoán chúng. Thường thì các mô hình self-supervised được pretrain nhằm tìm ra những representation tốt cho các downstream task.
Có rất nhiều ý tưởng áp dụng self-supervised learning cho các bài toán về hình ảnh. Workflow phổ biến là train pretext task trên các dữ liệu không gán nhãn sau đó sử dụng lớp feature trung gian để feed vào các layer classifier cuối. Accuracy sẽ cho ta thấy việc học biểu diễn các feature có tốt hay không.
Trong mô hình đã trình bày, ta có self-supervised learning task đó là trích xuất các patch từ một ảnh và yêu cầu model dự đoán mối quan hệ giữa các patch. Pretext task ở đây có thể gọi là dự đoán mối tương quan về vị trí giữa 2 patch ngẫu nhiên từ một ảnh. Mô hình cần hiểu spatial context (bối cảnh không gian) của vật thể để có thể hiểu được mối tương quan vị trí giữa các patch.
MIM
Trong machine learning, masked signal learning làm một cách học mà ta “”che” đi một phần của đầu vào và dựa những phần còn lại để dự đoán phần che. Trong Computer vision task, cách tiếp cận này đạt kết quả cạnh tranh so với contrastive learning. Áp dụng cách tiếp cận này trong Computer vision -> masked image modeling.
Có nhiều chiến lược để mask một ảnh như square shape masking, block-wise masking, random masking,...

MIM giúp cho Transformer và Autoencoders học được dễ dàng chỉ cần thông qua thông tin từ ảnh. Masking giúp Transformer tăng tốc độ thực hiện tác vụ phân loại.
Visual Transformer
Trong CV, visual information được capture theo array các pixel. Các pixel này được xử lý bởi convolution. Tuy đạt một số kết quả tốt nhưng chúng cũng có một số thách thức lớn:
- Không phải pixel nào cũng nên ”dành được sự chú ý” như các pixel khác. Ví dụ trong bài toán classification, ta nên ưu tiên chú ý vật thể chính hơn là background đằng sau.
- Không phải tất cả các bức ảnh đều chung 1 concept. Low-level feature ví dụ như các góc, cạnh xuất hiện ở tất cả các bức ảnh tự nhiên, do vậy áp dụng bộ lọc low-feature convolutional là hợp lý. Tuy nhiên, với high-level feature lại là câu chuyện khác. Ví dụ, hình ảnh một con chó sẽ hiếm khi xuất hiện trong các hình ảnh về giao thông, xe cộ. Vì high-level feature thường xuất hiện trong các bức ảnh cụ thể nên việc thêm high-level convolutional filter trở nên không hiệu quả và tốn kém.
- Hạn chế về mức độ liên quan về không gian. Convolutional filter chỉ áp dụng cho một vùng nhỏ, do đó tính liên kết về mặt cấu trúc vật thể trong hình ảnh là không có.
Tài liệu tham khảo
- DIT: SELF-SUPERVISED PRE-TRAINING FOR DOCUMENT IMAGE TRANSFORMER
- Patch is all you need
- BEIT: BERT Pre-Training of Image Transformers
- SimMIM: A Simple Framework for Masked Image Modeling
- AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
- DISCRETE VARIATIONAL AUTOENCODERS
- Visual Transformers: Token-based Image Representation and Processing for Computer Vision
- Zero-Shot Text-to-Image Generation
- self-supervised learning
- The Gumbel-Softmax Distribution
- Variational inference - Matthew N. Bernstein (mbernste.github.io)
All rights reserved
