Paper reading | DETRs Beat YOLOs on Real-time Object Detection
Động lực và đóng góp
Real-time object detection là một chủ đề nghiên cứu chưa bao giờ là hết hot do tính ứng dụng thực tiễn cao, một số ứng dụng có thể kể đến đó là object tracking, xe tự hành,... Các mô hình real-time detector hiện tại chủ yếu xây dựng từ kiến trúc CNN có tốc độ inference nhanh nhưng lại là một sự đánh đổi giữa tốc độ và chính xác. Đặc biệt, các mô hình real-time detector này thường yêu cầu sử dụng non-maximum suppression (NMS) cho quá trình post-processing, điều này làm giảm tốc độ inference của detector.
Các mô hình end-to-end transformer-based detectors (DETR) đạt hiệu suất đáng chú ý. Tuy nhiên, vấn đề của các mô hình transformer-based là chi phí tài nguyên tính toán lớn, do đó mặc dù không cần post-processing (ví dụ như NMS) nhưng các model này vẫn khó có thể được sử dụng trong ứng dụng thực tế.
Trong bài báo, nhóm tác giả thực hiện phân tích ảnh hưởng của NMS lên tốc độ inference trong các mô hình real-time object detection hiện đại và tạo một benchmark hoàn chỉnh để đánh giá. Hơn nữa, để hạn chế việc làm chậm tốc độ inference của NMS, bài báo đề xuất mô hình Real-Time DEtection TRansformer (RT-DETR) mà theo nhóm tác giả là mô hình end-to-end object detector đầu tiên (tính tới thời điểm hiện tại)  RT-DETR không chỉ vượt các mô hình SOTA hiện tại về tốc độ và độ chính xác mà còn không yêu cầu post-processing, do đó quá trình inference sẽ không bị delay và duy trì tính ổn định.
RT-DETR không chỉ vượt các mô hình SOTA hiện tại về tốc độ và độ chính xác mà còn không yêu cầu post-processing, do đó quá trình inference sẽ không bị delay và duy trì tính ổn định.
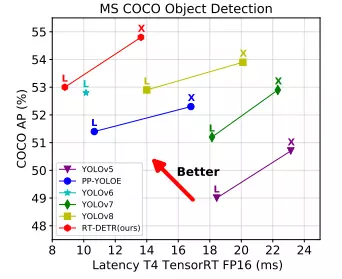
Nhóm tác giả cũng cung cấp giải pháp với mục tiêu detector có thể linh hoạt điều chỉnh model size và tốc độ inference bằng cách thay thế các decoder khác nhau mà không cần phải retraining
Phương pháp
End-to-end Speed of Detectors
NMS
NMS là thuật toán post-processing phổ biến trong các mô hình object detection. Vai trò của NMS là loại bỏ các box dự đoán bị chồng chéo lên nhau. Hai hyperparameter được yêu cầu trong NMS là score threshold và IoU threshold. Cụ thể, ta thực hiện loại bỏ các box dự đoán như sau:
- Các box dự đoán có score nhỏ hơn score threshold sẽ được loại bỏ
- Khi IoU của 2 box dự đoán lớn hơn IoU threshold, box mà có score nhỏ hơn sẽ được loại bỏ.
Quá trình này sẽ thực hiện lặp qua tất cả các box dự đoán. Do đó, thời gian thực thi của NMS phụ thuộc vào số box dự đoán và giá trị của 2 hyperparameter đầu vào.
Để rõ ràng hơn, nhóm tác giả tiến hành thực nghiệm trên 2 model YOLOv5 (anchor-based) và YOLOv8 (anchor-free).
Anchor-based và anchor-free là hai phương pháp phổ biến được sử dụng trong bài toán phát hiện đối tượng (object detection) trong lĩnh vực trí tuệ nhân tạo.
Anchor-based detection là phương pháp dựa trên việc định nghĩa một tập hợp các khu vực (anchors) trên ảnh đầu vào. Mỗi anchor thường được xác định bằng cách sử dụng các thông số như kích thước, tỷ lệ và vị trí trên ảnh. Mô hình sẽ tiến hành dự đoán xem liệu mỗi anchor có chứa một đối tượng nào đó hay không, và nếu có thì sẽ dự đoán các thông tin về đối tượng như kích thước, vị trí và lớp của đối tượng đó. Anchor-based detection thường được sử dụng trong các mô hình như Faster R-CNN, RetinaNet và Mask R-CNN.
Anchor-free detection là phương pháp không sử dụng anchors mà thay vào đó dựa trên các phương pháp phát hiện đối tượng khác để dự đoán kích thước, vị trí và lớp của đối tượng. Các phương pháp này bao gồm CenterNet, CornerNet và FCOS. Với anchor-free detection, mô hình sẽ tiến hành dự đoán một điểm cụ thể trên ảnh là trung tâm của đối tượng và dự đoán các thông tin liên quan đến đối tượng này từ điểm đó.
Các bước tiến hành thực nghiệm của nhóm tác giả như sau:
- Đếm số box dự đoán sau khi được lọc bởi các score threshold khác nhau với cùng một ảnh. Các score threshold có giá trị từ 0.001 đến 0.25.
- Biểu diễn bằng một biểu đồ histogram cho 2 model như hình dưới.
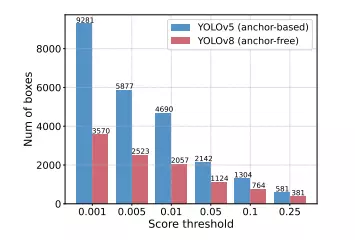
Từ biểu đồ trên ta có thể thấy rằng NMS dễ bị ảnh hưởng từ các hyperparameter (ở đây là score threshold).
Ngoài ra, nhóm tác giả sử dụng YOLOv8 làm ví dụ để đánh giá độ chính xác của mô hình trên tập dữ liệu COCO và thời gian thực thi của NMS với các hyperparameter khác nhau. Kết quả được thể hiện trong bảng dưới.
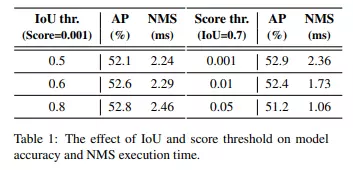
End-to-end Speed Benchmark
Để có thể đưa ra các kết quả so sánh tốc độ inference công bằng hơn, nhóm tác giả xây dựng tập benchmark chuẩn. Bộ dữ liệu được sử dụng là COCO val2017. Kết quả được thể hiện trong bảng dưới đây
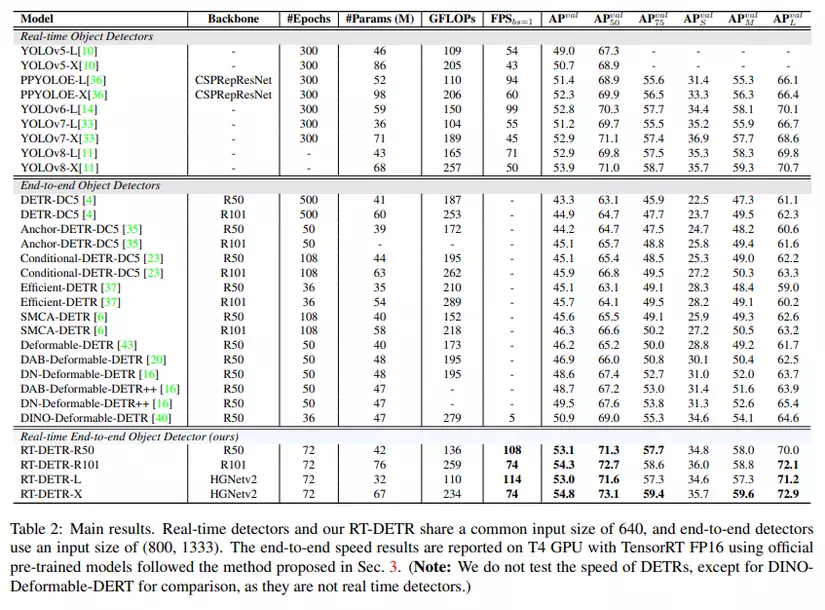
Từ kết quả nhóm tác giả kết luận rằng, với các real-time detector yêu cầu post-processing NMS, việc sử dụng các anchor-free detector cho tốc độ inference nhanh hơn các anchor-based detector với cùng độ chính xác do anchor-free detector có thời gian post-processing ít hơn đáng kể. Lý giải cho điều này là do các anchor-based detector tạo ra nhiều box dự đoán hơn so với các anchor-free detector.
Real-time DETR
Tổng quan model
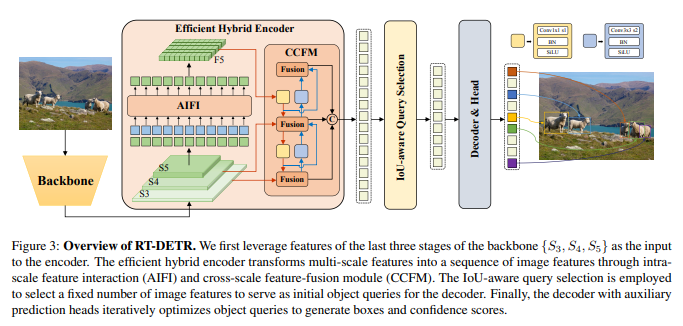
Mô hình RT-DETR được minh họa trong hình trên, bao gồm 3 phần: một backbone, một hybrid encoder và một transformer decoder với các auxiliary prediction head.
Nhóm tác giả sử dụng các output feature của 3 stage cuối cùng trong backbone là đầu vào cho encoder. Hybrid encoder biến đổi các multi-scale feature thành một chuỗi các image feature thông qua intra-scale interaction và cross-scale fusion (sẽ được mô tả rõ hơn trong phần Efficient Hybrid Encoder ). Sau đó, IoU-aware query selection được sử dụng để chọn một lượng cố định các image feature từ chuỗi encoder output (được mô tả rõ hơn trong phần IoU-aware Query Selection ). Cuối cùng, decoder với các auxiliary prediction head thực hiện lặp đi lặp lại việc tối ưu các truy vấn object để tạo các box và confidence score.
Efficient Hybrid Encoder
Computational bottleneck analysis. Trước đây đã có một số cách để tăng khả năng hội tụ và cải thiện hiệu suất mô hình. Một trong số đó là sử dụng các multi-scale feature và ứng dụng cơ chế deformable attention để giảm lượng tính toán. Mặc dù phần nào giảm được lượng tính toán nhưng việc tăng độ dài của chuỗi đầu vào vẫn là nguyên nhân chính ảnh hưởng tới tốc độ của mô hình, điều này làm cho model khó được sử dụng vào các ứng dụng thực tế yêu cầu xử lý realtime.
Để giải quyết vấn đề này, nhóm tác giả thực hiện phân tích sự dư thừa trong tính toán của multi-scale transformer encoder và thiết kế một tập các biến thể khác nhau để chứng minh rằng sự tương tác đồng thời giữa các intra-scale feature và cross-scale feature là không hiệu quả về mặt tính toán
Theo tác giả, vì các high-level feature chứa nhiều thông tin ngữ nghĩa về object bản chất được trích xuất từ các low-level feature, do đó việc sử dụng concat các multi-scale feature là không cần thiết. Để kiếm chứng điều này, nhóm tác giả thiết kế các biến thể encoder khác nhau như hình dưới.
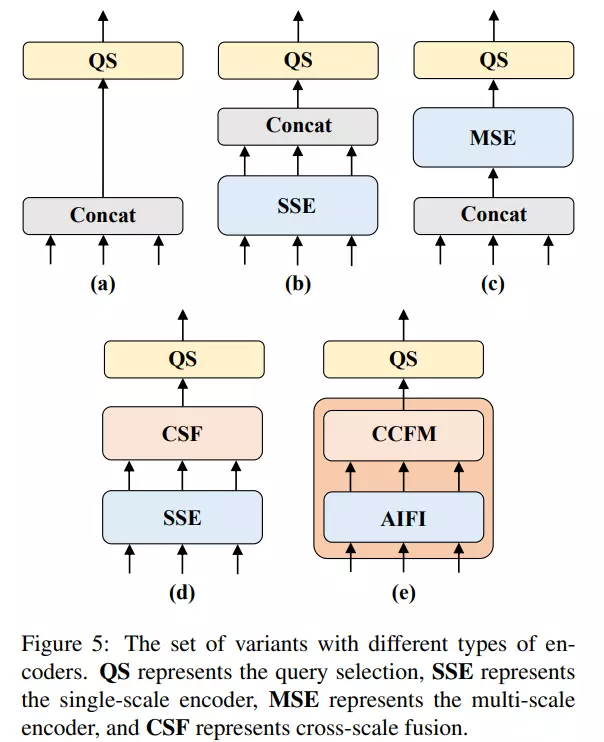
Đầu tiên, ta sẽ chọn encoder trong model DINO-R50 làm baseline A. Các biến thể sau đó lần lượt như sau:
- Biến thể B được bổ sung thêm một single-scale transformer encoder là một transformer block. Các feature được trích xuất tại các scale khác nhau (spatial resolution khác nhau) từ cùng một encoder để học các thông tin tương tác giữa các feature (intra-scale feature interaction). Sau đó, ta sẽ concat các multi-scale feature đầu ra.
- Biển thể C giới thiệu cross-scale feature fusion. Sau đó đưa concat các multi-scale feature vào một encoder để học tương tác giữa các feature. Nếu bạn chưa biết thì cross-scale feature fusion là kĩ thuật được sử dụng để kết hợp thông tin từ các tầng feature ở các tỷ lệ không gian (spatial resolution) khác nhau trong một hệ thống xử lý. Trong quá trình trích xuất feature từ ảnh, thông thường chúng ta sẽ sử dụng các mạng CNN để tạo ra các feature tại các tầng hay layer khác nhau của mạng. Các tầng đầu tiên của mạng CNN thường tạo ra các đặc trưng có phạm vi rộng và thể hiện thông tin tổng quát về hình ảnh, trong khi các tầng sau đó tạo ra các feature chi tiết và phức tạp hơn Cross-scale feature fusion có nhiệm vụ kết hợp các feature từ các tầng khác nhau lại với nhau để tạo ra một biểu diễn tổng thể tốt hơn cho ảnh. Qua quá trình này, thông tin từ các tầng feature ở các tỷ lệ không gian khác nhau được kết hợp lại để tạo ra một biểu diễn đa tỷ lệ (multi-scale representation) của ảnh.
- Biến thể D thay vì concat các multi-scale feature thì tách ra thành 2 phần là intra-scale interaction và cross-scale fusion. Đầu tiên, single-scale transformer encoder được sử dụng để thực hiện intra-scale interaction, sau đó một kiến trúc giống như PANet được khởi tạo để thực hiện cross-scale fusion.
- Biến thể E tối ưu intra-scale interaction và cross-scale fusion của các multi-scale feature, thiết kế một encoder hiệu quả có tên là efficient hybrid encoder.
Hiệu suất của các biến thể được thể hiện trong bảng dưới:
Hybrid design. Dựa vào những phân tích trên, nhóm tác giả đề xuất một cấu trúc encoder hiệu quả hơn có tên Efficient Hybrid Encoder.
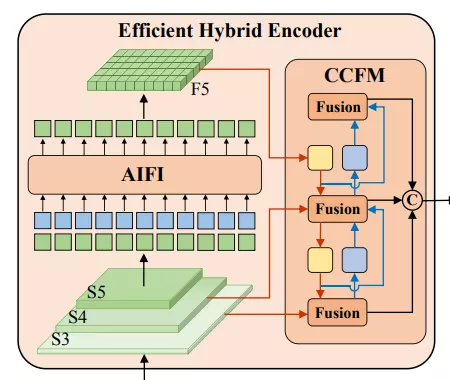
Như hình trên, encoder được đề xuất gồm 2 module:
- Attention-based Intra-scale Feature Interaction (AIFI)
- CNN-based Cross-scale Feature-fusion Module (CCFM)
Có 2 ý quan trọng trong lập luận của nhóm tác giả:
- Thứ nhất, việc sử dụng self-attention cho các high-level feature là hợp lý do có thể capture được nhiều thông tin ngữ nghĩa quan trọng và mối liên hệ giữa các thực thể trong ảnh. Điều này làm tăng hiệu suất của mô hình recognition.
- Thứ hai, intra-scale interaction cho các low-level feature là không cần thiết do sự thiếu thông tin ngữ nghĩa và mang nhiều rủi ro ảnh hưởng đến tương tác của các high-level feature.
Để chứng minh 2 lập luận trên, ta quan sát lại bảng sau:
Nhận thấy khi thực hiện intra-scale interaction chỉ trên của biến thể D, ta thu được AP và Latency tốt hơn so với biến thể D ban đầu. Đây là một kết luận quan trọng để thiết kế một real-time detector
Module CCFM cũng được tối ưu dựa vào biến thể D. CCFM ở đây là các fusion block được xây dựng từ các lớp Conv (xem hình dưới).
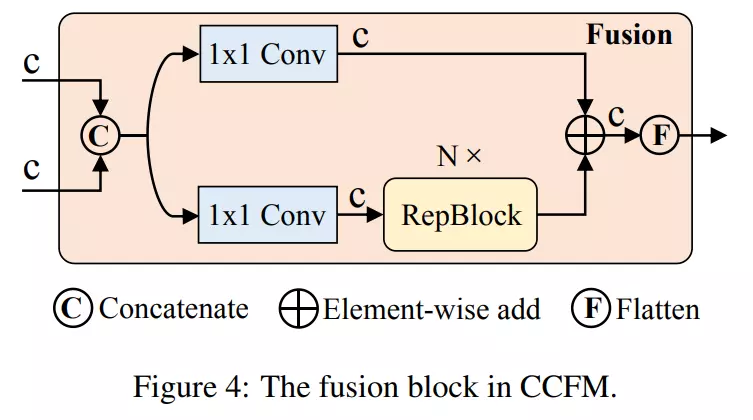
Vai trò của fusion block là hợp nhất các feature kề nhau thành một feature mới. Fusion block bao gồm Repblock và 2 nhánh được cộng element-wise với nhau. Cụ thể, mô tả công thức sẽ như sau:
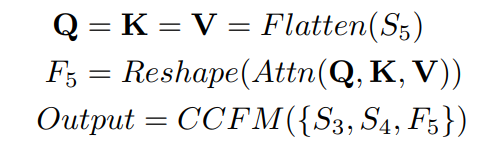
trong đó là multi-head self-attention và đại diện cho việc khôi phục lại kích thước của feature giống như .
IoU-aware Query Selection
Các object query trong DETR là một tập hợp learnable embedding được tối ưu bởi decoder. Các earnable embedding này cũng được map với classification scores và bounding box bởi prediction head. Hạn chế của các object query này là khó khăn trong việc giải thích và tối ưu. Một số vấn đề khác trong các nghiên cứu trước đó là sự không nhất quán trong phân phối giữa classification score và mức độ tự tin trong dự đoán location. Tức là, classification score cao nhưng IoU thấp và classification score thấp nhưng IoU lại cao. Điều này ảnh hưởng tới hiệu suất của mô hình.
Để giải quyết vấn đề này, nhóm tác giả đề xuất phương pháp có tên IoU-aware query selection. Phương pháp này thực hiện ràng buộc mô hình phải tạo classification score cao cho các feature với IoU score cao và classification score thấp cho các feature với IoU score thấp trong quá trình training. Vì vậy, box dự đoán tương ứng với top các encoder feature được chọn bởi mô hình theo classification score sẽ có cả classification score cao và IoU score cao. Cụ thể:
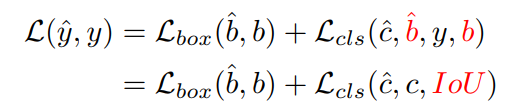
trong đó và lần lượt là giá trị dự đoán và ground truth, và , và lần lượt là category và bounding box. Nhóm tác giả đề xuất IoU score ở nhánh classification để ràng buộc sự nhất quán giữa classification và localization của các positive sample.
Hình dưới mô tả sự hiệu quả của phương pháp đề xuất.
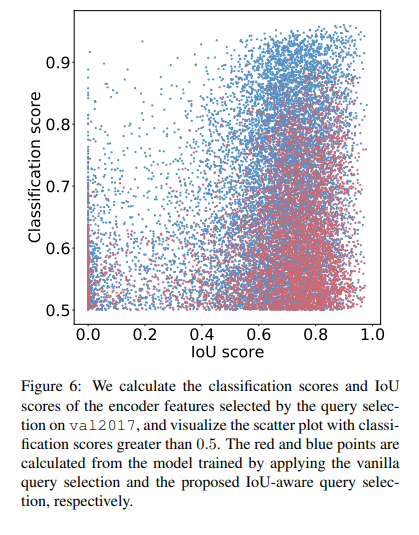
Cách thử nghiệm như sau, nhóm tác giả chọn top ( trong thử nghiệm của tác giả) các encoder feature theo classification score và sau đó visualize các điểm mà có classification score lớn hơn 0.5. Các điểm màu đỏ và xanh là các giá trị lấy từ model được áp dụng vanilla query selection và IoU-aware query selection tương ứng.
Quan sát hình ta thấy rằng đa phần các điểm màu xanh tập trung vào phía trên bên phải của hình. Điều này cho thấy rằng model được train với IoU-aware query selection có thể tạo các encoder feature chất lượng cao.
Nhóm tác giả cũng thực hiện phân tích định lượng đặc điểm phân phối của các điểm xanh và đỏ. Kết quả như sau:
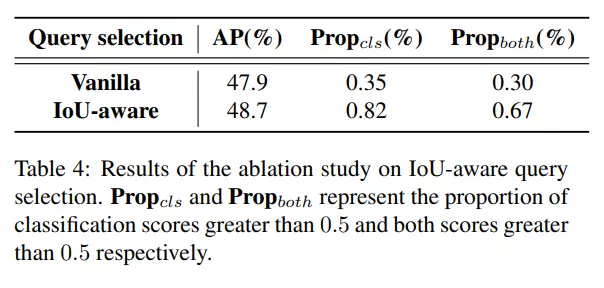
- Số điểm xanh nhiều hơn 138% so với số điểm đỏ, hay số điểm đỏ có classification score nhỏ hơn hoặc bằng 0.5 nhiều hơn. Điều này chứng tỏ mô hình không áp dụng IoU-aware query selection có các feature chất lượng thấp
- Số điểm xanh có IoU lớn hơn 0.5 nhiều hơn 120% so với số điểm đỏ.
Nói chung, việc sử dụng IoU-aware query selection làm tăng classification score và IoU score, dẫn đến tăng độ chính xác của mô hình.
Thực nghiệm
Bảng dưới so sánh kết quả khi có và không áp dụng IoU-aware.
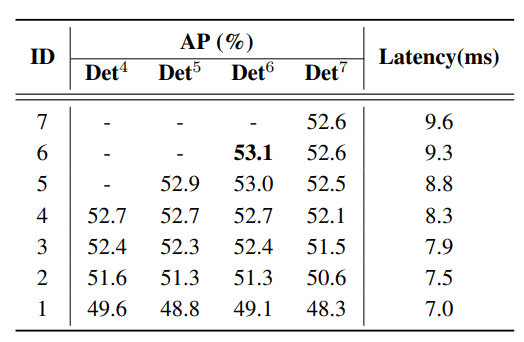
Bảng dưới là kết quả của mô hình tương ứng với số decoder layer khác nhau. Det^ với là số decoder layer. Model được sử dụng là RT-DETR-R50.
Tham khảo
All rights reserved
