
[paper explain] RCNet: Kiến trúc FPN đỉnh cao cho object detection ?
Bài đăng này đã không được cập nhật trong 3 năm
Giới thiệu chung
Kiến trúc FPN ( feature pyramid network) từ lâu đã được sử dụng trong object detection cho nhiệm vụ tăng cường thông tin của một mức scale bằng cách fusion đặc trưng từ scale trước đó. Sau FPN cũng đã có khá nhiều biến thể của nó được sinh ra, và tất cả chúng đều cho thấy sự cải thiện về hiệu quả một cách đáng kinh ngạc. Một số mô hình khá nổi tiếng có thể kể đến như : Nas-FPN, AugFPN, PAFPN, Bi-FPN, BFP.
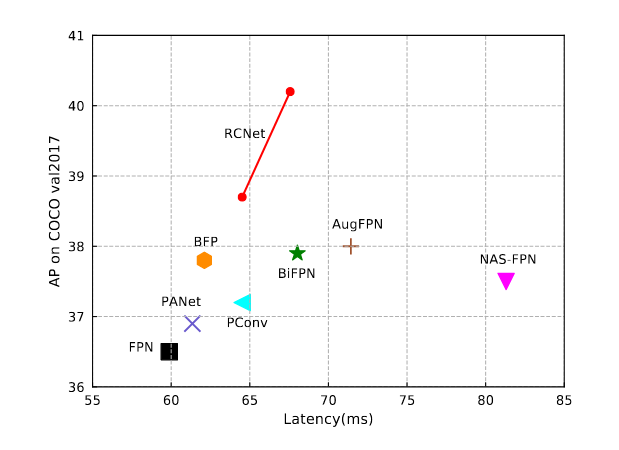
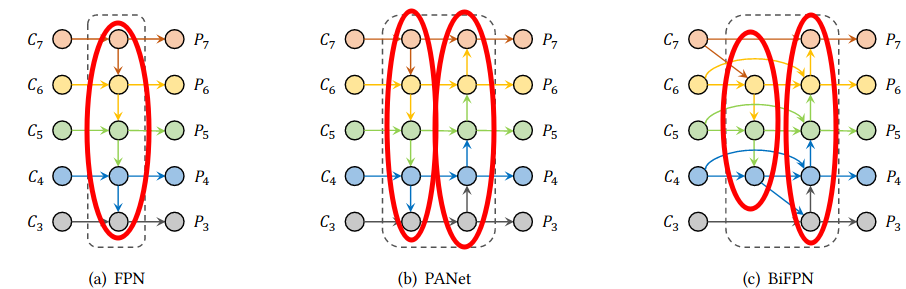
Từ những nghiên cứu của các biến thể nói trên, ta có thể thấy rằng các cách fusion phức tạp kiểu 2 chiều cả bottom-up và top-down như PANet hay Bifpn đều cho kết quả cao, có thể là vì các kiến trúc nói trên đều có feature fusion pipeline dài hơn kiến trúc fpn thông thường.
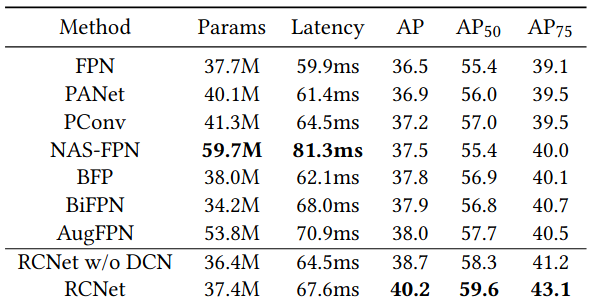
Tuy nhiên, điều này lại làm tăng thời gian training và inference, cụ thể có thể xem ở bảng 1. Từ những quan sát trên thì nhóm tác giả RCNet đã đề xuất một kiểu kiến trúc mới có tên là Reverse Feature Pyramid (RevFP) kèm theo Cross-scale Shift Network (CSN). Mô hình được đề xuất cho kết quả hoàn toàn vượt trội so với baseline fpn và các biến thể khác.
RCNet
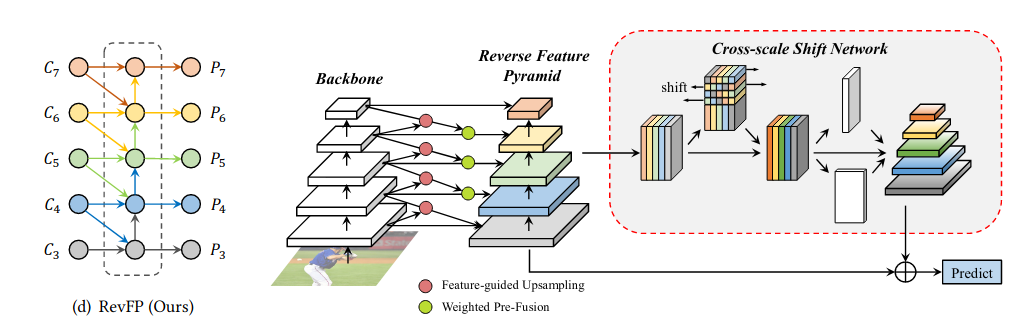
Ngoài ra thì nhóm tác giả có sử dụng phép weighted fusion theo ý tưởng của BiFPN thay vì phép cộng thông thường của FPN. Một vấn đề nữa mà các tác giả nói đến là mối tương quan giữa các feature map ở các mức scale khác nhau: thường thì feature map của 2 mức scale gần nhau sẽ có độ tương quan cao, nhưng mức chênh lệch scale càng cao thì độ tương quan sẽ càng giảm mạnh do phép fusion đặc trưng thường chỉ tập trung vào 2 mức scale ở gần, từ đó khiến các feature map ở xa nhau cho ra những kết quả chênh lệch với nhau làm ảnh hưởng đến hiệu quả của mạng. Để giải quyết vấn đề này, các tác giả có đề xuất mạng con Cross-scale Shift Network (CSN). CSN sẽ dịch đặc trưng theo channel giữa toàn bộ các mức scale cho nhiệm vụ trao đổi thông tin toàn cục từ đó tạo sự cân bằng đặc trưng trong mạng multi-level multi-scale. Một điều đặc biệt là khối này khá nhẹ bởi vì phép dịch không tạo thêm Param hay FLOPs cho mạng.
Reverse Feature Pyramid
Pyramid Pathway
Đầu tiên mình sẽ nhắc lại một chút về kiến trúc của FPN truyền thống. FPN có cách thiết kế theo kiểu top - down, tức là thông tin sẽ đi từ mức đặc trưng sâu nhất (feature map nhỏ nhất) mang nhiều ngữ nghĩa đến các tầng lân cận nông hơn theo hướng từ trên xuống dưới như miêu tả ở hình 2a. Giả sử ảnh đầu vào có kích thước , gọi và là feature map ở mức thứ của backbone và đầu ra của feature pyramid thứ tương ứng với kích thước là . Đầu ra của FPN được tính như sau:
Khối RevFP sẽ không đi theo hướng top-down mà đi theo hướng ngược lại, tức là bottom-up, đồng thời có thêm một nhánh top-down cục bộ giữa hai feature map gần nhau. Điều này sẽ tạo nên flow 2 chiều cho khối, hơn nữa còn có thể tận dụng cùng lúc đặc trưng biểu diễn ở bậc cao và bậc thấp. Phép fusion đặc trưng của RevFP được biểu diễn như sau:
Feature-guided upsampling
Thông thường thì để fuse feature ở 2 mức với nhau, ta sẽ cần upsample feature nhỏ hơn, có độ phân giải thô hơn lên 2 lần trước khi thực hiện các phép fusion phía sau. Các đặc trưng ở mức thấp thường rất giàu thông tin vị trí, trong khi đó đặc trưng ở mức cao lại thiên về thông tin ngữ nghĩa. Từ ý tưởng này, các tác giả đã đề xuất phép upsampling nhưng kết hợp thêm thông tin vị trí đến từ feature ở mức thấp từ đó dẫn dắt quá trình upsampling tạo ra các feature map chính xác hơn. Đầu tiên, feature map sẽ được upsampling lên 2 lần sau đó concat với feature map để tổng hợp thông tin 2 mức feature rồi đưa qua 1 lớp để giảm số channel về 1 rồi thực hiện chuẩn hóa với softmax để tạo weight attention. Weight sẽ được nhân với để quá trình huấn luyện ổn định hơn, trong đó là một hằng số và là số channel của feature map. Cuối cùng weight này sẽ được nhân với feature map ban đầu để có thể tạo attention vào các đặc trưng mang thông tin vị trí
Dynamic Weighted Fusion
Kế thừa ý tưởng của Bi-FPN, RCNet đã cải tiến weighted fusion thành dynamic weighted fusion ứng dụng trong thiết kế kiểu bottom-up của mình. Quá trình dynamic weighted fusion được chia làm 2 giai đoạn : weighted pre-fusion và weighted post-fusion. Nếu như coi là feature map đầu vào ở mức , là feature map bậc cao đã được feature-guided upsampling bằng kích thước với , weighted pre-fusion đầu tiên sẽ áp dụng global average pooling rồi concat 2 feature map lại để bắt được các mối tương quan giữa 2 mức scale. Sau đó và sigmoid được sử dụng để tạo weight động theo level cho và cho . Quá trình trên được biểu diễn như sau:
Trong đó là hàm . Quá trình post-fusion cũng thực hiện tương tự :
CROSS-SCALE SHIFT NETWORK
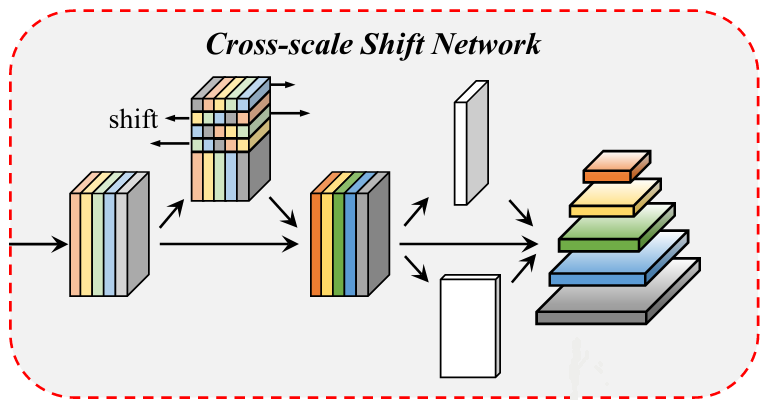
Feature sau khi được tăng cường thông tin qua khối RevFP sẽ đi qua khối CSN. Khối này gồm 2 module : multi-scale shift và dual global context.
Multi-scale Shift Module
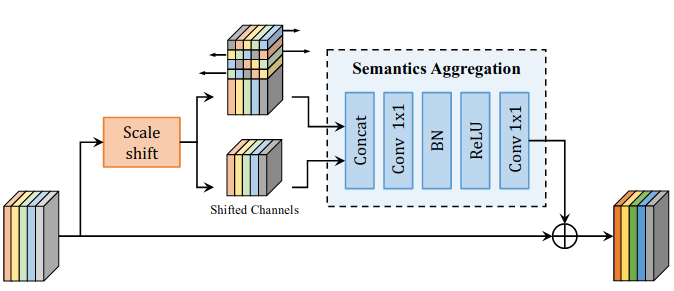
Gọi feature từ RevFP là . Đầu tiên ta sẽ tính bằng cách dịch trái, phải 0, 1, 2 theo mức scale, sau đó nhân với chuỗi trọng số và tính tổng :
Y có thể được chia thành với được tính như sau:
Quá trình này có thể coi là tích chập với kernel 5 và padding theo chiều của scale. Trong đó, người ta sẽ dịch 1 phần của feature channel với tỉ lệ cho kết quả tốt nhất và residual connection để giảm tác động xấu của sự dịch chuyển dữ liệu. Hơn nữa, những kênh dữ liệu đã dịch sẽ được concat lại để lưu giữ thông tin tại những kênh đó. Ngoài ra để tổng hợp thông tin nhiều mức cũng như giảm số kênh thì tác giả có sử dụng
Dual Global Context
Để tạo mối tương quan mạnh hơn cho các khối đặc trưng đã được dịch ở trước đó, nhóm tác giả tiến hành tích hợp khai thác thông tin ngữ cảnh bằng cách thêm vào Dual Global Context Module. Module này gồm 2 nhánh : scale context branch và spatial context branch. Scale branch được tạo bằng cách nén các mức feature lại với phép squeeze sau đó áp dụng để lấy thông tin theo channel của các mức rồi đưa qua Softmax để tạo weight rồi nhân với feature lúc chưa squeeze. Cuối cùng nó được average pooling theo chiều scale và đưa qua . Spatial context branch cũng tương tự như vậy, chỉ khác thứ tự đổi từ spatial pooling, channel context fusion, scale pooling sang scale pooling, channel context fusion, spatial pooling.
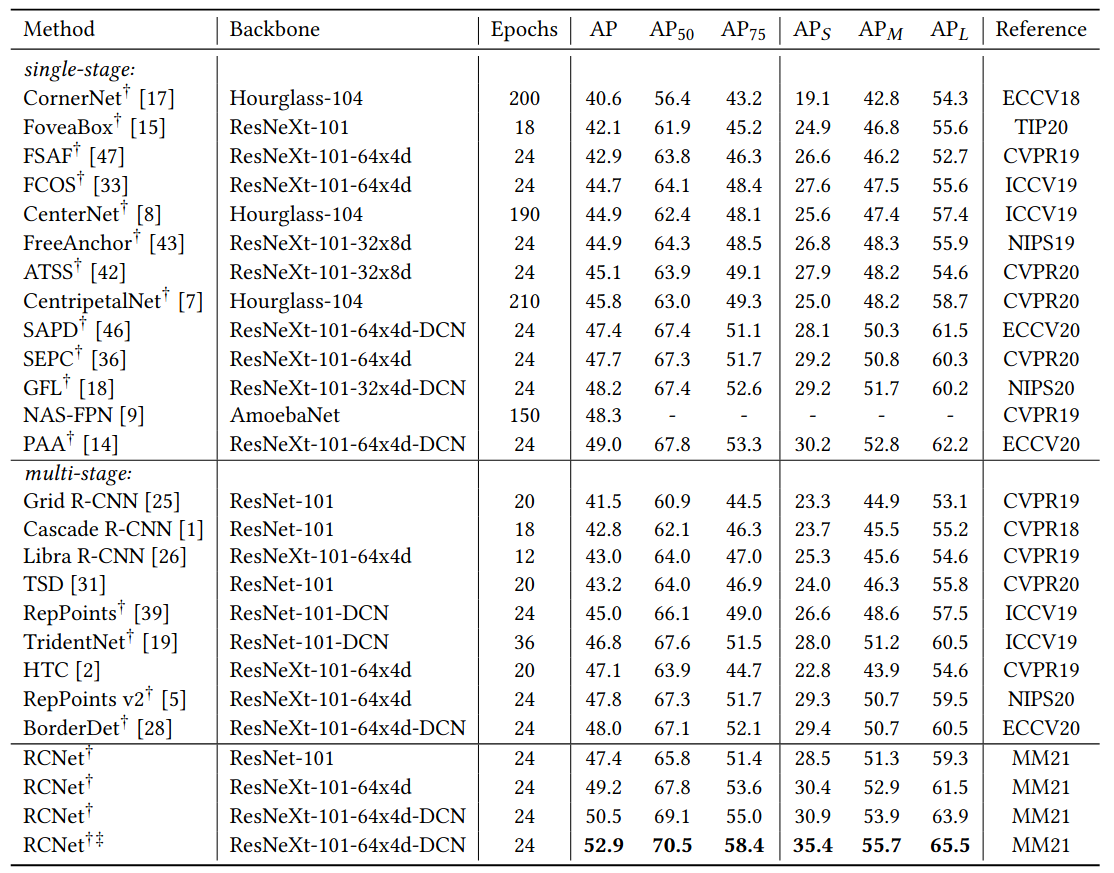
Kết quả
Tác giả sử dụng backbone ResNet-50 cho thí nghiệm 1-stage và 2-stage object detector để kiểm chứng hiệu quả của mô hình. 1-stage detector sử dụng RetinaNet kết hợp với các baseline khá mạnh như: ATSS và GFL
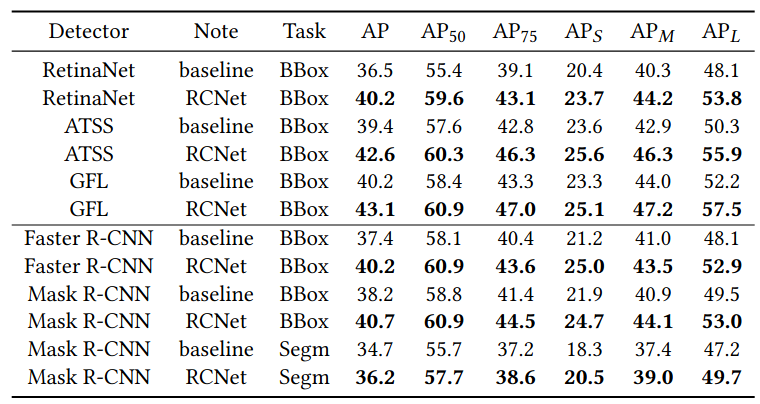
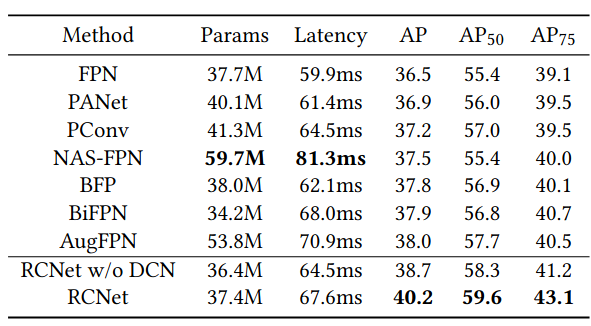
Kết luận
Paper được tác giả viết khá công phu, vẫn còn nhiều điều trong paper mà mình chưa kịp nói đến. Để hiểu rõ hơn thì có lẽ bạn đọc nên tìm hiểu thêm bản gốc của paper được để link ở phần tham khảo. Kết quả cuối cùng cho thấy RCNet có thể đẩy hiệu năng của detection với baseline lên khá cao, thậm chí đạt state-of-the-art mà không làm tăng chi phí tính toán và độ phức tạp thuật toán quá nhiều. Bài viết đến đây cũng đã dài, trong quá trình đọc có thấy sai sót mong mọi người tích cực góp ý để mình cải thiện hơn ở các bài viết sau.
Reference
[1] Zhuofan Zong, Qianggang Cao, Biao Leng:
RCNet: Reverse Feature Pyramid and Cross-scale Shift Network for Object Detection. ACM Multimedia 2021: 5637-5645
https://arxiv.org/pdf/2110.12130.pdf
[2] Tsung-Yi Lin, Piotr Dollár, Ross B. Girshick, Kaiming He, Bharath Hariharan, Serge J. Belongie:
Feature Pyramid Networks for Object Detection. CVPR 2017: 936-944 https://arxiv.org/pdf/1612.03144.pdf
All rights reserved
