
[Paper Explain] DualStyleGAN: Exemplar-Based High-Resolution Portrait Style Transfer
Bài đăng này đã không được cập nhật trong 4 năm

Introduction
Gần đây, nhiều nghiên cứu chỉ ra rằng StyleGAN có thể thực hiện style transfer chất lượng cao chỉ với một lượng dữ liệu hạn chế bằng một chiến lược fine tuning phù hợp. Paper Pastiche Master: Exemplar-Based High-Resolution Portrait Style Transfer đề xuất một mở rộng của kiến trúc StyleGAN với intrinsic style path và extrinsic style path để mã hóa style của domain gốc và domain cần transfer sang. Paper cũng đề xuất một chiến lược fine tuning theo 3 bước để biến đổi không gian của domain gốc sang domain mới ngay cả với những thay đổi về kiến trúc mạng.
Một số khái niệm
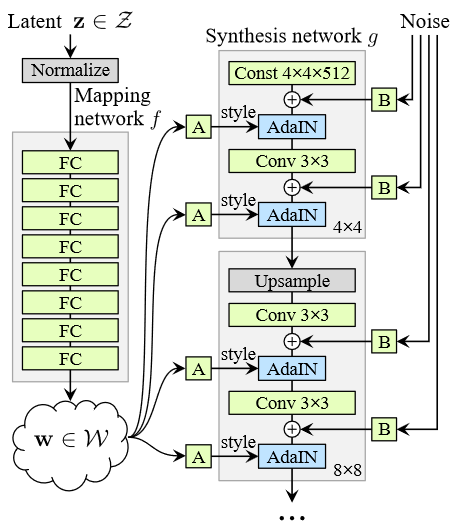
StyleGAN generator
Mạng generator của stylegan có 1 chút khác biệt với các mô hình GAN truyền thống. Thay vì nhận đầu vào trực tiếp là vector latent thì vector sẽ được đưa qua một mạng MLP 8 lớp để tạo ra vector với cùng số chiều. Vector được dùng để kiểm soát style của ảnh thông qua lớp Adaptive Instance Normalization. Một phép biến đối affline (học thông qua một lớp fully connected - ký hiệu A trong hình dưới) được áp dụng lên trước khi đưa vào mạng generator.
GAN inversion
Mạng generator của GAN sẽ tạo ra ảnh từ một vector latent . GAN inversion là quá trình ngược lại, từ ảnh đầu vào tìm vector latent tương ứng của nó.
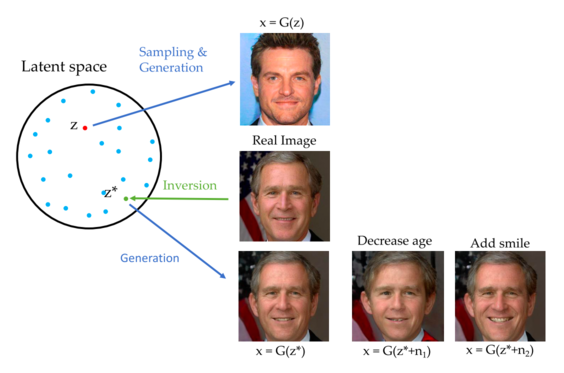
Một số cách tiếp cận cho GAN inversion
- Optimization based: sử dụng gradient descent để tối ưu vector sao cho ảnh khôi phục giống với ảnh thật nhất.
- Encoder based: sử dụng 1 mạng encoder được huấn luyện trên nhiều ảnh được tạo ra bởi mạng generator với các latent vector tương ứng.
Trong paper này tác giả sử dụng encoder based dựa trên model psp
Style mixing
Trong lúc huấn luyện StyleGAN, một phần ảnh trong tập training được tạo ra bằng cách sample 2 latent vector và thay vì một. Trong quá trình forward của mạng generator, ta lựa chọn ngẫu nhiên một điểm trong mạng để chuyển từ vector style sang .
Dual StyleGAN
DualStyleGAN được xây dựng dựa trên một mạng StyleGAN pretrain. Việc finetune lại mô hình unconditional trên một dataset khác sẽ làm dịch chuyển cả không gian sample, dẫn tới mất đa dạng trong các sample sinh ra. Ý tưởng chính của DualStyleGAN tìm kiếm chiến lược finetuning phù hợp để học các style đa dạng bằng cách thêm extrinsic style path để encode style của domain mục tiêu
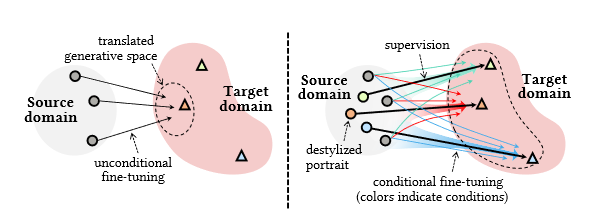
Facial Destylization
Mục tiêu của bước này là khôi phục ảnh người thật từ ảnh style để tạo pair dataset huấn luyện mô hình. Với một ảnh style từ domain mục tiêu, ta cần tìm một khuôn mặt tương ứng phù hợp ở domain gốc. Quá trình này được thực hiện qua 3 bước:
- Khởi tạo: Một ảnh style S đầu tiên sẽ được embed thành 1 vector latent trong domain gốc thông qua quá trình GAN inversion. Cụ thể ở đây tác giả sử dụng mô hình psp kí hiệu là . Thay vì embed ảnh thành vector trong không gian (1 vector sample từ phân phối chuẩn), tác giả sử dụng không gian (18 vector sample từ phân phối chuẩn, stack lên thành ma trận ).
Khuôn mặt sau khi tái tạo trong domain gốc kí hiệu là . Với là generator của mạng StyleGAN gốc và .
- Finetune vector latent: Không gian của một mạng StyleGAN đẫ được finetune trên tập ảnh style (ký hiệu ) được tối ưu để sinh ra ảnh style bằng cách finetune StyleGAN với hàm loss
trong đó
- : là perceptual loss với đặc trưng trích xuất từ VGG19
- : identity loss để bảo toán nhận dạng với là mô hình Arcface.
- : regularization term - độ lệch chuẩn giữa 18 vector trong . Dùng để giảm overfitting
- Image embedding : Vector embedding cuối cùng được cho bằng công thức . Kết quả reconstruct qua 3 bước finetune được cho trong hình (d)

Kiến trúc mạng
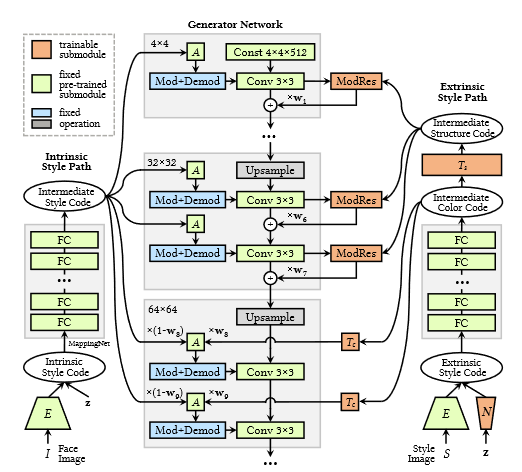
Kiến trúc mạng DualStyleGAN bao gồm 2 phần gồm 2 phần:
- intrinsic style path + generator. Phần này là kiến trúc StyleGAN gốc và được fix cứng trong quá trình finetune.
- Extrinsic style path: gồm 1 mạng MLP giống intrinsic path, các khối color transform và structure transform . Đầu vào của extrinsic path là vector của ảnh style tương ứng.
Color control block: phần này khá giống StyleGAN gốc. Style code từ extrinsic path đi qua một mạng MLP và các khối color transform được mô hình hóa bởi 1 mạng MLP. Các khối này chỉ nằm ở phần có độ phân giải cao ở generator (lớp 8-18). Style code sau khi đi qua sẽ được cộng có trọng số với style code từ intrinsic path trước khi đi qua Adaptive Normalization.
Structure control block: dùng để đặc trưng hóa cấu trúc của ảnh style. Style code sau khi đi qua mạng và structure control block sẽ được cho qua 1 khối ModRes trước khi được cộng với feature map của generator. Các khối này chỉ xuất hiện ở các lớp độ phân giải thấp (lớp 1 - 7). Các trúc của khối ModRes giống hệt các residual block trong Resnet chỉ khác là các lớp Batch normalization được thay thế bằng Adaptive Instance Normalization.
Với một ảnh mặt thật và ảnh style , style transfer được thực hiện bằng với và trọng số để kết hợp giữa style của intrinsic và extrinsic path.
Progressive finetuning
DualStyleGAN sử dụng chiến lược finetuning nhiều bước để từ từ biến đổi không gian sample sang domain mục tiêu. Hai bước đầu có mục đích là để pretrain DualStyleGAN trên data gốc sau đó mới finetune trên data mới trong bước 3.

Bước 1: color transfer
Nhờ vào thiết kế của DualStyleGAN, bước này ta không cần huấn luyện lại mạng mà chỉ cần khởi tạo các khối ở extrinsic path một cách hợp lý.
- Các khối ModRes được khởi tạo gần 0 để loại bỏ các residual feature
- Trọng số các khối color transform được khởi tạo bằng ma trận đơn vị nên style code không thay đổi khi đi vào generator. Có thể thấy màu của ảnh style được transfer khá tốt sang ảnh mặt người chỉ nhờ khởi tạo trong hình trên
Bước 2: structure transfer
Finetune extrinsic path để transfer các đặc trưng về structure
Đầu tiên ta sample 2 vector từ phần phối chuẩn. DualStyleGAN được finetune sao cho . Trong đó, là ma trận với hàng đầu tiên là và hàng cuối là . giàm dần từ 7 xuống 5 trong quá trình finetune. Hàm mục tiêu:
Bước 3: finetune trên domain mục tiêu
Ta cần style code và của một ảnh style S trong domain mục tiêu có thể được tái tạo thông qua DualStyleGAN thông qua perceptual loss. Hàm mục tiêu của bước 3:
trong đó
và lần lượt là context loss và feature matching loss
với là trọng số của các lớp ModRes.
Result
Một số kết quả thí nghiệm


Reference
All rights reserved
